


2020软件工程实践寒假第二次作业
声明
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SpringW |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SpringW/homework/10281 |
| 这个作业的目标 | <开发疫情统计程序> |
| 作业正文 | https://www.cnblogs.com/linjieblog/p/12325644.html |
| 其他参考文献 | ... |
Github仓库地址
主仓库地址:https://github.com/numb-men/InfectStatistic-main
我的仓库地址:https://github.com/linjieok/InfectStatistic-main
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| Estimate | 估计这个任务需要多少时间 | 800 | 480 |
| Development | 开发 | 600 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 100 | 120 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 600 | 560 |
| Code Review | 代码复审 | 30 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 120 | 180 |
| Test Report | 测试报告 | 120 | 180 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 15 |
| 合计 | 2070 | 1700 |
解题思路
需求
假设有一家统计网站每天都会提供一个对应的日志文本,记录国内各省前一天的感染情况,如它2020-01-23发布的日志文本可能长这样:
福建 新增 感染患者 23人
福建 新增 疑似患者 2人
浙江 感染患者 流入 福建 12人
湖北 疑似患者 流入 福建 2人
安徽 死亡 2人
新疆 治愈 3人
福建 疑似患者 确诊感染 2人
新疆 排除 疑似患者 5人
// 该文档并非真实数据,仅供测试使用
该日志中出现以下几种情况:
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
PS:
日志中各种情况的出现顺序不定,省出现的顺序不定,出现哪些省不定,省出现几次不定。
该日志文件的命名遵守对应的规范: 年-月-日.log.txt ,如2020-01-22.log.txt。
文件日期并不一定连续,若某天的日志缺失,默认为该天的情况没有变化。认为日志提供的最早一天的前一天不存在任何感染情况。如只提供2020-01-23,2020-01-25则可认为2020-01-24增长变化都为0。-date不会提供在日志最晚一天后的日期,若提供应给与日期超出范围错误提示。
命令行(win+r cmd)cd到项目src下,之后输入命令:
$ java InfectStatistic list -date 2020-01-22 -log D:/log/ -out D:/output.txt
会读取D:/log/下的所有日志,然后处理日志和命令,在D盘下生成ouput.txt文件列出2020-01-22全国和所有省的情况(全国总是排第一个,别的省按拼音先后排序)
全国 感染患者22人 疑似患者25人 治愈10人 死亡2人
福建 感染患者2人 疑似患者5人 治愈0人 死亡0人
浙江 感染患者3人 疑似患者5人 治愈2人 死亡1人
// 该文档并非真实数据,仅供测试使用
list命令 支持以下命令行参数:
-log 指定日志目录的位置,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-out 指定输出文件路径和文件名,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-date 指定日期,不设置则默认为所提供日志最新的一天。你需要确保你处理了指定日期之前的所有log文件
-type 可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如 -type ip 表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。
-province 指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江
注:java InfectStatistic表示执行主类InfectStatistic,list为命令,-date代表该命令附带的参数,-date后边跟着具体的参数值,如2020-01-22。-type 的多个参数值会用空格分离,每个命令参数都在上方给出了描述,每个命令都会携带一到多个命令参数
思路

首先从命令行获取命令,读取命令行输入的参数,进行参数的分析处理,根据不同的参数进行不同的函数处理,最后在指定的位置输出成要求的规范内容。

设计命令类,从命令行读入参数。首先判断参数是否正确,是否list,不是则报错。如果是,进行参数的识别和保存。遍历参数表,找到相关命令并保存。
根据参数,从指定路径读取日志,按照date处理日志。通过正则表达式处理日志数据,保存成规范模式。
保存的数据根据参数输出到指定位置。
关键代码
保存命令中的province和type类型,方便识别

获取命令中的各个参数

读取-log 后路径下的所有文件名,并进行处理
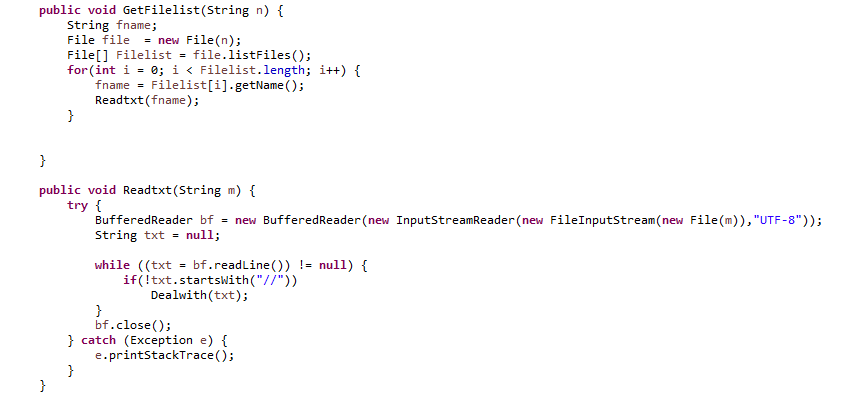
对日志内容进行正则匹配,通过bool类型确定属于哪一种类型,分类处理

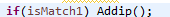
未完待续
心路历程和收获
本次作业相对较复杂,用到了许多之前没有学过的东西。首先是Github的使用和Git命令,学习基础Git命令、Github Desktop使用。接着是使用java编程
由于之前的学习不够,对java的掌握较差,算法和语言都不太熟悉,做作业时遇到了很多困难和问题。最后是整个作业的规划,因为没有好好规划时间导致
没有按时完成,以及遗留很多错误。
本次收获:
1.在需要时要学会求助周围的同学和助教,通过自己很难完成所有的任务
2.要提高自学能力,使用网络和资源进行学习,很多未知的知识需要靠自己学习和掌握,并在错误和尝试中不断学习。
3.要做好规划和计划,才能及时完成作业。
代码规范
https://github.com/linjieok/InfectStatistic-main/blob/master/221701132/codestyle.md

