Zookeeper的使用场景
- 数据发布/订阅(配置管理)
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master 选举
- 分布式锁
- 分布式队列
多个开源项目中都应用到了 ZooKeeper,例如 HBase, Spark, Flink, Storm, Kafka, Dubbo 等等。
1.发布/订阅模式(配置管理)
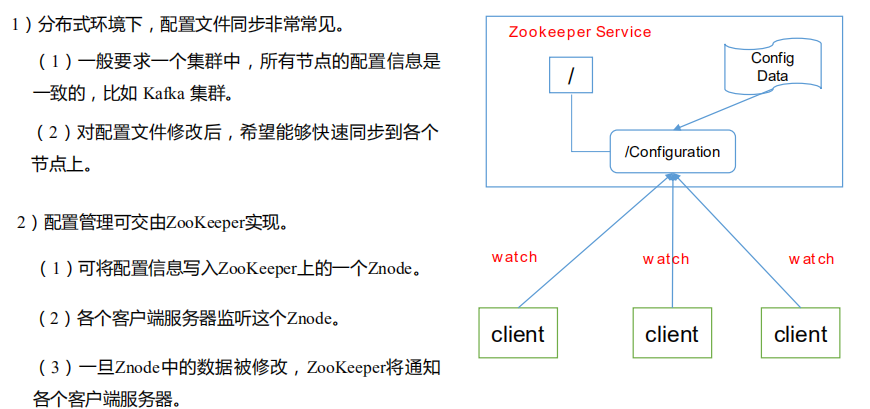
ZooKeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架。发布者把数据发布到 ZooKeeper 的一个或一系列的节点上,供订阅者进行数据订阅,达到动态获取数据的目的。
配置信息一般有几个特点:
- 数据量小的KV
- 数据内容在运行时会发生动态变化
- 集群机器共享,配置一致
ZooKeeper 采用的是推拉结合的方式。
- 推: 服务端会推给注册了监控节点的客户端 Wathcer 事件通知
- 拉: 客户端获得通知后,然后主动到服务端拉取最新的数据
流程思路:
- 把配置信息写到一个 Znode 上,例如
/Configuration - 客户端启动初始化阶段读取服务端节点的数据,并且注册一个数据变更的 Watcher
- 配置变更只需要对 Znode 数据进行 set 操作,数据变更的通知会发送到客户端,客户端重新获取新数据,完成配置动态修改
2.2 负载均衡
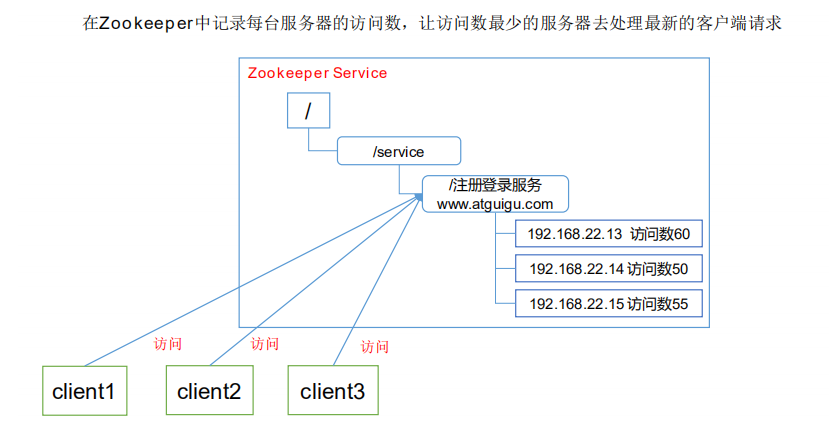
实现的思路:
- 首先建立 Servers 节点,并建立监听器监视 Servers 子节点的状态(用于在服务器增添时及时同步当前集群中服务器列表)
- 在每个服务器启动时,在 Servers 节点下建立临时子节点 Worker Server,并在对应的字节点下存入服务器的相关信息,包括服务的地址,IP,端口等等
- 可以自定义一个负载均衡算法,在每个请求过来时从 ZooKeeper 服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求
2.3 命名服务

命名服务就是提供名称的服务。ZooKeeper 的命名服务有两个应用方面。
- 提供类 JNDI 功能,可以把系统中各种服务的名称、地址以及目录信息存放在 ZooKeeper,需要的时候去 ZooKeeper 中读取
- 制作分布式的序列号生成器
利用 ZooKeeper 顺序节点的特性,制作分布式的序列号生成器,或者叫 id 生成器。(分布式环境下使用作为数据库 id,另外一种是 UUID(缺点:没有规律)),ZooKeeper 可以生成有顺序的容易理解的同时支持分布式环境的编号。
在创建节点时,如果设置节点是有序的,则 ZooKeeper 会自动在你的节点名后面加上序号,上面说容易理解,是比如说这样,你要获得订单的 id,你可以在创建节点时指定节点名为 order_[日期]_xxxxxx,这样一看就大概知道是什么时候的订单。
2.4 分布式协调/通知
一种典型的分布式系统机器间的通信方式是心跳。心跳检测是指分布式环境中,不同机器之间需要检测彼此是否正常运行。传统的方法是通过主机之间相互 PING 来实现,又或者是建立长连接,通过 TCP 连接固有的心跳检测机制来实现上层机器的心跳检测。
如果使用 ZooKeeper,可以基于其临时节点的特性,不同机器在 ZooKeeper 的一个指定节点下创建临时子节点,不同机器之间可以根据这个临时节点来判断客户端机器是否存活。
好处就是检测系统和被检系统不需要直接相关联,而是通过 ZooKeeper 节点来关联,大大减少系统的耦合。
2.5 集群管理

集群管理主要指集群监控和集群控制两个方面。前者侧重于集群运行时的状态的收集,后者则是对集群进行操作与控制。开发和运维中,面对集群,经常有如下需求:
- 希望知道集群中究竟有多少机器在工作
- 对集群中的每台机器的运行时状态进行数据收集
- 对集群中机器进行上下线的操作
分布式集群管理体系中有一种传统的基于 Agent 的方式,就是在集群每台机器部署 Agent 来收集机器的 CPU、内存等指标。但是如果需要深入到业务状态进行监控,比如一个分布式消息中间件中,希望监控每个消费者对消息的消费状态,或者一个分布式任务调度系统中,需要对每个机器删的任务执行情况进行监控。对于这些业务紧密耦合的监控需求,统一的 Agent 是不太合适的。
利用 ZooKeeper 实现集群管理监控组件的思路:
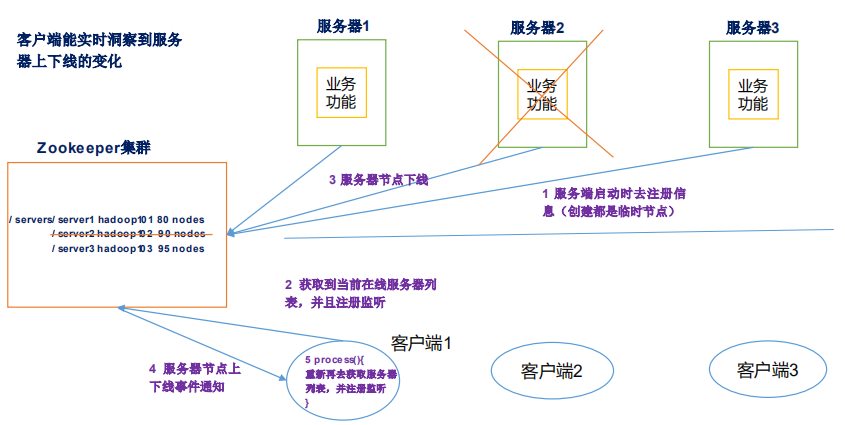
在管理机器上线/下线的场景中,为了实现自动化的线上运维,我们必须对机器的上/下线情况有一个全局的监控。通常在新增机器的时候,需要首先将指定的 Agent 部署到这些机器上去。Agent 部署启动之后,会首先向 ZooKeeper 的指定节点进行注册,具体的做法就是在机器列表节点下面创建一个临时子节点,例如 /machine/[Hostname](下文我们以“主机节点”代表这个节点)
当 Agent 在 ZooKeeper 上创建完这个临时子节点后,对 /machines 节点关注的监控中心就会接收到“子节点变更”事件,即上线通知,于是就可以对这个新加入的机器开启相应的后台管理逻辑。另一方面,监控中心同样可以获取到机器下线的通知,这样便实现了对机器上/下线的检测,同时能够很容易的获取到在线的机器列表,对于大规模的扩容和容量评估都有很大的帮助。
2.6 Master 选举
分布式系统中 Master 是用来协调集群中其他系统单元,具有对分布式系统状态更改的决定权。比如一些读写分离的应用场景,客户端写请求往往是 Master 来处理的。
利用常见关系型数据库中的主键特性来实现也是可以的,集群中所有机器都向数据库中插入一条相同主键 ID 的记录,数据库会帮助我们自动进行主键冲突检查,可以保证只有一台机器能够成功。
但是有一个问题,如果插入成功的和护短机器成为 Master 后挂了的话,如何通知集群重新选举 Master?
利用 ZooKeeper 创建节点 API 接口,提供了强一致性,能够很好保证在分布式高并发情况下节点的创建一定是全局唯一性。
集群机器都尝试创建节点,创建成功的客户端机器就会成为 Master,失败的客户端机器就在该节点上注册一个 Watcher 用于监控当前 Master 机器是否存活,一旦发现 Master 挂了,其余客户端就可以进行选举了。
2.7 分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,一般需要通过一些互斥的手段来防止彼此之间的干扰,以保证一致性。
2.7.1 排他锁
如果事务 T1 对数据对象 O1 加上了排他锁,那么加锁期间,只允许事务 T1 对 O1 进行读取和更新操作。核心是保证当前有且仅有一个事务获得锁,并且锁释放后,所有正在等待获取锁的事务都能够被通知到。
通过 ZooKeeper 上的 Znode 可以表示一个锁,/x_lock/lock。
- 获取锁 所有客户端都会通过调用
create()接口尝试在/x_lock创建临时子节点/x_lock/lock。最终只有一个客户端创建成功,那么该客户端就获取了锁。同时没有获取到锁的其他客户端,注册一个子节点变更的 Watcher 监听。 - 释放锁 获取锁的客户端发生宕机或者正常完成业务逻辑后,就会把临时节点删除。临时子节点删除后,其他客户端又开始新的一轮获取锁的过程。
2.7.1 共享锁
如果事务 T1 对数据对象 O1 加上了共享锁,那么当前事务 T1 只能对 O1 进行读取操作,其他事务也只能对这个数据对象加共享锁,直到数据对象上的所有共享锁都被释放。
2.8 分布式队列
2.8.1 FIFO
使用 ZooKeeper 实现 FIFO 队列,入队操作就是在 queue_fifo 下创建自增序的子节点,并把数据(队列大小)放入节点内。出队操作就是先找到 queue_fifo 下序号最下的那个节点,取出数据,然后删除此节点。
创建完节点后,根据以下步骤确定执行顺序:
- 通过
get_children()接口获取/queue_fifo节点下所有子节点 - 通过自己的节点序号在所有子节点中的顺序
- 如果不是最小的子节点,那么进入等待,同时向比自己序号小的最后一个子节点注册 Watcher 监听
- 接收到 Watcher 通知后重复 1
转载自:https://zhuanlan.zhihu.com/p/59669985

 浙公网安备 33010602011771号
浙公网安备 33010602011771号