
IP协议
IP协议
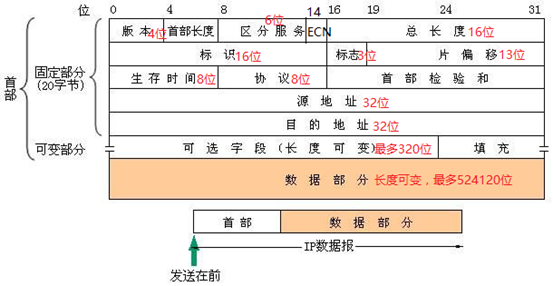
IPv4首部
版本:
包含IP数据报的版本号:ipv4为4,ipv6为6
首部长度:
其中保存的是整个首部中的“32位字”的数量。
这个字段正常的值为:5(假设“可选字段长度为0”)
该字段最大值为:15(可选字段长度全满加上原有字段)
区分服务:

优先级(3位)和数据链路层的QoS机制有关,定义了8个服务级别。当Qos选择了某种服务模型后,优先级越高,字段越优先传输。
D、T、R分别表示延时、吞吐量、可靠性。当这些值都为1时,分别表示低延时、高吞吐量、高可靠性。
ECN:
用于为数据报标记“拥塞标识符”。
当一个带有ECN标记的分组发送后,如果接收端“持续拥塞”且“具有感知ECN的能力”(如TCP),那么接收端会通知发送端降低发送速度。
总长度:
该字段指的是IPv4数据报的总长度(以字节为单位)。
通过该字段和“首部长度”字段,我们可以推测出ip数据报中“数据部分”从哪开始以及长度。
标识、标志、分偏移:
该字段帮助标识由IPv4主机发送的数据报。
这个字段对实现分片很重要,大多数数据链路层不支持过长的ip数据报,所以要把ip数据报分片,每一片都是一个独立的ipv4数据报。
发送主机每次发送数据报都讲一个“内部计数器”加1,然后将数值复制“标识”字段中。
生存时间:
该字段用于设置一个“数据报可经过的路由器数量”的上限。
发送方在初始发送时设定某个值(建议为64,、128或255),每台路由器再转发时都将其减一,当字段达到0时,该数据报被丢弃,并使用一个ICMP消息通知发送方。
协议:
包含一个数字,该数字对应一个“有效载荷部分的数据类型”。比如17代表UDP,6代表TCP。
首部校验和:
该字段“仅计算”IPv4首部。也就是说只“校验”首部。并不检查数据报的“数据部分”。
首先将“首部校验和”设置为0,。
然后对首部(整个首部是一个16位字的“序列”)计算16位二进制反码和。该值被存储在首部校验和字段中。
当接收方接收到数据报后,也对其首部进行校验计算,如果结果与“首部校验和”的值不同,就丢弃收到的数据报。
可选字段:
IP支持很多可选选项。
如果选项存在的话,它在IPv4分组中紧跟在基本IPv4头部之后。
IP转发
主机和路由器都能转发ip,不同之处在于:主机不转发那些不是由它生成的数据报,但路由器会转发。
IP地址可以接收一个数据报。
当IP模块接收到一个数据报时,
首先检查此数据报的目的地址是否为自己的IP地址,
如果不是,且IP层配置为一台路由器,则根据“转发表”转发该数据报。
否则丢弃此数据报,然后返回给源节点一个信息,表明错误。
转发表
IP转发表通常需要包含以下信息。
目的地:
32位字段(用于IPv4),
当目的地为“默认路由”(当路由表中与包的目的地址之间没有匹配的表项时路由器能够做出的选择。如果没有默认路由,那么目的地址在路由表中没有匹配表项的包将被丢弃)时,目的地可设置为0。
对于仅描述一个目的地的主机路由,目的地可设为完整的ip地址。
掩码:
之前讲过了,掩码是和目的地ip组合使用的,将ip地址与子网掩码进行“按位与”运算,就能得出用于路由的“子网标识符”。
下一跳:
下一个IP实体(路由器或主机)的IP地址。
接口:
包含一个网络层使用的标识符,用来确定将数据报发送到下一跳的网络接口。
IP转发行动
当一台主机或路由器需要向下一跳转发数据报时,它首先检查数据报中的IP地址。在算法表中使用该IP地址来执行最长前缀匹配算法。
最长前缀匹配算法:
举个例子,现在路由器中有两个路由表(转发表)其目的地为:192.168.2.0/24和192.168.0.0/16
假设现在路由器接收到了一条数据报,其目标地址为192.168.2.3
那么实际上这两个路由表都匹配,但路由器会选择192.168.2.0/24作为该数据报的下一跳,
因为192.168.2.0/24这个ip地址“前缀更长”,匹配成功的部分更多。
IP分片
链路层通常对可传输的每一个帧的最大长度都有上限。为了使超过此上限的ip数据报能够正常传输,
IP引入了“分片”和“重组”。
当IP层接收到要发送的IP数据报时,通过查找“转发表”,会判断该数据报应该从那个本地“接口”发送以及MTU(最大传输单元,指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位))是多少。
不同的网络类型,其MTU都不相同,如以太网中MTU为1518字节,FDDI为4500字节。
如果IP数据报超过MTU值,则进行分片。IPv4的分片可以在原始发送方主机和端到端路径上的任何中间路由器上进行,即:一个分片在到达接收主机的路径中,还可能被继续分片。(而IPv6只允许源主机进行分片)
当一个IP数据报被分片后,直到它到达最终目的地才会被重组。(因为同一个数据报的不同分片,可能经由不同的路径到达相同的最终目的地,所以中途有可能无法重组)
之前提到过,ip分组后,每一个分片都是一个完整的ip数据报。
其中首部里的“总长度”字段,是该分片的总长度。
分片技术与ip首部中以下三个字段有关:

标识符:
主机将数据报分片后,在发送前,会给每一个分片数据报一个ID值,放在16位的标识符字段中。
这个ID值可以用来识别哪些分片是属于同一个数据报的,方便重组。
标志:
标志字段在IP报头中占3位,
第1位作为保留,置0;
第2位,分段,有两个不同的取值:该位置0,表示可以分段;该位置1,表示不能分段;
第3位,更多分段,同样有两个取值:该位置0,表示这是数据流中的最后一个分段,该位置1,表示数据流未完,后续还有分段,当一个数据报没有分段时,则该位置0,表示这是唯一的一个分段。
当目的主机接收到一个IP数据报时,会首先查看该数据报的标识符,并且检查标志位的第3位是置0或置1,以确定是否还有更多的分段,如果还有后续报文,接收主机则将接收到的报文放在缓存直到接收完所有具有相同标识符的数据报,然后再进行重组。
偏移量:
就像之前说过的,各个IP分片数据报在发送到目的主机时可能是无序的,所以就需要“偏移量”字段来指明“该分片在原数据报中的位置顺序”。
发送主机对第一个数据报的偏移量置为0,而后续的分片数据报的偏移量则以网络的MTU大小赋值。
如:
假设:网络接口MTU大小为1400字节,要传输的数据报为3800字节。
那么,将要传输的数据报分为3片即可(3800=1400+1400+1000)
偏移量的计算方法为:已经“装载”好的分片字节数/8(偏移量就是某片在原分组的相对位置,所以8个字节作为偏移单位。)
分片1偏移量为:0(0=0/8,因为该偏移量之前没有装载过任何分片,自然也就是0除以8了)
分片2偏移量为:175(175=1400/8,由于分片1已经装载好了1400字节,所以此分片的位置就在1400字节之后,也就用1400除以8了)
分片3偏移量为:350(350=2800/8,目前已经装好了两个分片也就是2800字节已经装载完了,那么分片3自然就跟在2800字节之后了,也就是用2800除以8)

