
CPU拓扑结构和调度域 调度组
在Linux操作系统中,处理器(CPU)调度是由调度器(Scheduler)负责的,该调度器管理系统中的所有进程,并决定哪个进程在什么时候在哪个CPU上运行。Linux调度器使用了一种称为 Completely Fair Scheduler (CFS) 的调度策略来保证公平性。
为了更有效地管理多处理器(多核心)系统上进程的调度,Linux引入了概念:调度域(Scheduling Domains)和调度组(Scheduling Groups)。
概念简介
调度域和调度组概念
-
调度域(Scheduling Domains):这是一组逻辑上或物理上相关的CPU的集合,它们共享一些硬件资源,如缓存或内存总线。在多核或多处理器系统中,不同的CPU可能有不同的性能特征,调度域帮助调度器了解这些特征,并做出调度决策。一个调度域内的CPU通常更适合于共享负载,因为它们共享某些资源,比如同一物理处理器上的核心共享L2缓存。
-
调度组(Scheduling Groups):这是一个或多个进程的集合。系统中的每个进程都属于某个调度组。调度器使用这些组来组织和平衡系统负载。调度组可以帮助实现某些政策,例如亲和性(affinity)和公平性(fairness)。
调度域和调度组之间的关系在于,调度域包含了若干个调度组,而它们共同构成了系统的调度架构。调度器在进行决策时,首先会根据调度域中的信息考虑CPU之间的调度,然后在每个调度域内部考虑不同调度组中进程的调度。通过这样的层次化结构,调度器可以有效地管理多处理器系统中的进程调度,保证进程公平地使用CPU资源,同时考虑到不同CPU间的差异。
简而言之,调度域提供了一个框架,告诉调度器哪些CPU可以进行负载共享,而调度组则告诉调度器哪些进程应该被考虑在内以共享这些CPU资源。两者共同协作以优化进程的调度和运行性能。
如今CPU的核数从单核,到双核,再到4核、8核、甚至10核。但是我们知道Android使用的多核架构都是分大小核,或者现在最新的,除了大小核以外,还有一个超大核。
区分大小核,是因为它们之间的性能(算力),功耗是不同的,而且它们又以cluster来区分(小核在一个cluster,大核在另一个cluster),而目前由于同cluster内的cpu freq是同步调节的。
所以,在对CPU的任务调度中,需要对其同样进行区分,来确保性能和功耗的平衡。
MC LEVEL和 DIE LEVEL
在Linux性能监控与资源管理中,有时我们会遇到“CPU DIE level”和“MC level”这两个概念,这两个概念与CPU的物理构造和内存控制器有关:
CPU DIE level:
英文中"DIE"一词在半导体行业指的是单个硅晶片,它包含了一个或多个处理器核心(cores)。在多核处理器和多处理器系统中,一个CPU的“DIE”可以理解为是一个单独的物理实体,其中可能包含若干个核心及其相关的缓存等组件。
在Linux系统终端中,我们可以运用例如lstopo这样的工具(属于hwloc包),它会展示CPU的拓扑结构,包括每个CPU DIE的位置和它们包含的核心(core)数目。在Linux中关注CPU DIE level有助于了解CPU的物理布局,这对于性能优化非常重要,尤其是涉及到处理器亲和性(processor affinity)和内存访问策略。
MC level:
MC代表Memory Controller,是一个负责管理内存访问的硬件单元。在现代处理器中,MC通常被集成进CPU中,有时称作集成内存控制器(Integrated Memory Controller,IMC)。在涉及到NUMA(非一致性内存访问)架构的系统上,不同的CPU DIE可能有自己独立的内存控制器,且与一部分物理内存直接连接,这种设计可以大幅度提升内存访问效率。
在Linux系统中,numactl和lstopo等工具可以用来查看及管理NUMA节点和内存控制器与之相对应的CPU DIE信息。通过了解MC level,管理员可以针对NUMA架构优化应用程序和操作系统的行为,尤其是在高性能计算和大型数据库服务器中。
因此,了解和管理CPU DIE level和MC level对于Linux系统的性能调优非常重要。它们帮助我们更好地分配任务到处理器核心,以及更有效地组织内存访问和分配,从而最小化延迟并优化整体系统性能。
因此,针对CPU的拓扑结构,内核中会建立不同的调度域、调度组来体现。如下图,以某8核cpu为例:
在DIE level,cpu 0-7()
在MC level,cpu 0-3在一组,而cpu4-7在另一组
*SMT超线程技术,会在MC level以下,再进行一次区分:01、23、45、67(这里可以暂不考虑,因为当前ARM平台并未支持SMT)

CPU Topology建立
在kernel中,有CPU Topology的相关代码来形成这样的结构,结构的定义在dts文件中,根据不同平台会不同。我当前这个mtk平台的DTS相关信息如下(至于这里为什么没有用qcom平台,因为现在公司暂时貌似只有mtk平台,所以可能略微有点差别):
cpu0: cpu@000 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x000>;
enable-method = "psci";
clock-frequency = <2301000000>;
operating-points-v2 = <&cluster0_opp>;
dynamic-power-coefficient = <275>;
capacity-dmips-mhz = <1024>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu1: cpu@001 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x001>;
enable-method = "psci";
clock-frequency = <2301000000>;
operating-points-v2 = <&cluster0_opp>;
dynamic-power-coefficient = <275>;
capacity-dmips-mhz = <1024>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu2: cpu@002 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x002>;
enable-method = "psci";
clock-frequency = <2301000000>;
operating-points-v2 = <&cluster0_opp>;
dynamic-power-coefficient = <275>;
capacity-dmips-mhz = <1024>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu3: cpu@003 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x003>;
enable-method = "psci";
clock-frequency = <2301000000>;
operating-points-v2 = <&cluster0_opp>;
dynamic-power-coefficient = <275>;
capacity-dmips-mhz = <1024>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu4: cpu@100 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x100>;
enable-method = "psci";
clock-frequency = <1800000000>;
operating-points-v2 = <&cluster1_opp>;
dynamic-power-coefficient = <85>;
capacity-dmips-mhz = <801>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu5: cpu@101 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x101>;
enable-method = "psci";
clock-frequency = <1800000000>;
operating-points-v2 = <&cluster1_opp>;
dynamic-power-coefficient = <85>;
capacity-dmips-mhz = <801>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu6: cpu@102 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x102>;
enable-method = "psci";
clock-frequency = <1800000000>;
operating-points-v2 = <&cluster1_opp>;
dynamic-power-coefficient = <85>;
capacity-dmips-mhz = <801>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu7: cpu@103 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x103>;
enable-method = "psci";
clock-frequency = <1800000000>;
operating-points-v2 = <&cluster1_opp>;
dynamic-power-coefficient = <85>;
capacity-dmips-mhz = <801>;
cpu-idle-states = <&STANDBY &MCDI_CPU &MCDI_CLUSTER>,
<&SODI &SODI3 &DPIDLE &SUSPEND>;
};
cpu-map {
cluster0 {
core0 {
cpu = <&cpu0>;
};
core1 {
cpu = <&cpu1>;
};
core2 {
cpu = <&cpu2>;
};
core3 {
cpu = <&cpu3>;
};
};
cluster1 {
core0 {
cpu = <&cpu4>;
};
core1 {
cpu = <&cpu5>;
};
core2 {
cpu = <&cpu6>;
};
core3 {
cpu = <&cpu7>;
};
};
};
代码路径:drivers/base/arch_topology.c、arch/arm64/kernel/topology.c,本文代码以CAF Kernel msm-5.4为例。
第一部分,这里解析DTS,并保存cpu_topology的package_id,core_id,cpu_sclae(cpu_capacity_orig)
kernel_init()
-> kernel_init_freeable()
-> smp_prepare_cpus()
-> init_cpu_topology()
-> parse_dt_topology()
针对dts中,依次解析"cpus"节点,以及其中的"cpu-map"节点;
先解析了其中cluster节点的内容结构。
在对cpu capacity进行归一化
static int __init parse_dt_topology(void)
{
struct device_node *cn, *map;
int ret = 0;
int cpu;
cn = of_find_node_by_path("/cpus"); //查找dts中 /cpus的节点
if (!cn) {
pr_err("No CPU information found in DT\n");
return 0;
}
/*
* When topology is provided cpu-map is essentially a root
* cluster with restricted subnodes.
*/
map = of_get_child_by_name(cn, "cpu-map"); //查找/cpus节点下,cpu-map节点
if (!map)
goto out;
ret = parse_cluster(map, 0); //(1)解析cluster结构
if (ret != 0)
goto out_map;
topology_normalize_cpu_scale(); //(2)将cpu capacity归一化
/*
* Check that all cores are in the topology; the SMP code will
* only mark cores described in the DT as possible.
*/
for_each_possible_cpu(cpu)
if (cpu_topology[cpu].package_id == -1)
ret = -EINVAL;
out_map:
of_node_put(map);
out:
of_node_put(cn);
return ret;
}
(1)解析cluster结构
通过第一个do-while循环,进行"cluster+序号"节点的解析:当前平台分别解析cluster0、1。然后仍然调用自身函数,这样代码复用,进一步解析其中的“core”结构
在进一步解析core结构时,同样通过第二个do-while循环,进行"core+序号"节点的解析:当前平台支持core0,1...7,共8个核,通过parse_core函数进一步解析
所以实际解析执行顺序应该是:cluster0,core0,1,2,3;cluster1,core4,5,6,7。
最后在每个cluster中的所有core都解析完,跳出其do-while循环时,package_id就是递增。说明package_id就对应了cluster的id
static int __init parse_cluster(struct device_node *cluster, int depth)
{
char name[20];
bool leaf = true;
bool has_cores = false;
struct device_node *c;
static int package_id __initdata;
int core_id = 0;
int i, ret;
/*
* First check for child clusters; we currently ignore any
* information about the nesting of clusters and present the
* scheduler with a flat list of them.
*/
i = 0;
do {
snprintf(name, sizeof(name), "cluster%d", i); //依次解析cluster0,1... 当前平台只有cluster0/1
c = of_get_child_by_name(cluster, name); //检查cpu-map下,是否有cluster结构
if (c) {
leaf = false;
ret = parse_cluster(c, depth + 1); //如果有cluster结构,会继续解析更深层次的core结构。(这里通过代码复用,接着解析core结构)
of_node_put(c);
if (ret != 0)
return ret;
}
i++;
} while (c);
/* Now check for cores */
i = 0;
do {
snprintf(name, sizeof(name), "core%d", i); //依次解析core0,1... 当前平台有8个core
c = of_get_child_by_name(cluster, name); //检查cluster下,是否有core结构
if (c) {
has_cores = true;
if (depth == 0) { //这里要注意,是因为上面depth+1的调用才会走下去
pr_err("%pOF: cpu-map children should be clusters\n", //如果cpu-map下没有cluster结构的(depth==0),就会报错
c);
of_node_put(c);
return -EINVAL;
}
if (leaf) { //在depth+1的情况下,leaf == true,说明是core level了
ret = parse_core(c, package_id, core_id++); //(1-1)解析core结构
} else {
pr_err("%pOF: Non-leaf cluster with core %s\n",
cluster, name);
ret = -EINVAL;
}
of_node_put(c);
if (ret != 0)
return ret;
}
i++;
} while (c);
if (leaf && !has_cores)
pr_warn("%pOF: empty cluster\n", cluster);
if (leaf) //在core level遍历完成:说明1个cluster解析完成,要解析下一个cluster了,package id要递增了
package_id++; //所以package id就对应了cluster id
return 0;
}
(1-1)解析core结构
因为当前平台不支持超线程,所以core+序号节点下面,没有thread+序号的节点了
解析cpu节点中的所有信息
更新cpu_topology[cpu].package_id、core_id,分别对应了哪个cluster的哪个core
static int __init parse_core(struct device_node *core, int package_id,
int core_id)
{
char name[20];
bool leaf = true;
int i = 0;
int cpu;
struct device_node *t;
do {
snprintf(name, sizeof(name), "thread%d", i); //不支持SMT,所以dts没有在core下面配置超线程
t = of_get_child_by_name(core, name);
if (t) {
leaf = false;
cpu = get_cpu_for_node(t);
if (cpu >= 0) {
cpu_topology[cpu].package_id = package_id;
cpu_topology[cpu].core_id = core_id;
cpu_topology[cpu].thread_id = i;
} else {
pr_err("%pOF: Can't get CPU for thread\n",
t);
of_node_put(t);
return -EINVAL;
}
of_node_put(t);
}
i++;
} while (t);
cpu = get_cpu_for_node(core); //(1-1-1)从core中解析cpu节点
if (cpu >= 0) {
if (!leaf) {
pr_err("%pOF: Core has both threads and CPU\n",
core);
return -EINVAL;
}
cpu_topology[cpu].package_id = package_id; //保存package id(cluster id)到cpu_topology结构体的数组
cpu_topology[cpu].core_id = core_id; //保存core id到cpu_topology结构体的数组; core id对应cpu号:0,1...7
} else if (leaf) {
pr_err("%pOF: Can't get CPU for leaf core\n", core);
return -EINVAL;
}
return 0;
}
(1-1-1)从core中解析cpu节点
从core节点中查找cpu节点,并对应好cpu id
再解析cpu core的capacity
static int __init get_cpu_for_node(struct device_node *node)
{
struct device_node *cpu_node;
int cpu;
cpu_node = of_parse_phandle(node, "cpu", 0); //获取core节点中cpu节点信息
if (!cpu_node)
return -1;
cpu = of_cpu_node_to_id(cpu_node); //获取cpu节点对应的cpu core id:cpu-0,1...
if (cpu >= 0)
topology_parse_cpu_capacity(cpu_node, cpu); //(1-1-1-1)解析每个cpu core的capacity
else
pr_crit("Unable to find CPU node for %pOF\n", cpu_node);
of_node_put(cpu_node);
return cpu;
}
(1-1-1-1)解析每个cpu core的capacity
- 从core节点中查找cpu节点,并对应好cpu id
- 再解析cpu core的capacity
static int __init get_cpu_for_node(struct device_node *node)
{
struct device_node *cpu_node;
int cpu;
cpu_node = of_parse_phandle(node, "cpu", 0); //获取core节点中cpu节点信息
if (!cpu_node)
return -1;
cpu = of_cpu_node_to_id(cpu_node); //获取cpu节点对应的cpu core id:cpu-0,1...
if (cpu >= 0)
topology_parse_cpu_capacity(cpu_node, cpu); //(1-1-1-1)解析每个cpu core的capacity
else
pr_crit("Unable to find CPU node for %pOF\n", cpu_node);
of_node_put(cpu_node);
return cpu;
}
1-1-1-1)解析每个cpu core的capacity
- 先解析capacity-dmips-mhz值作为cpu raw_capacity,这个参数就是对应了cpu的算力,数字越大,算力越强(可以对照上面mtk平台dts,明显是大小核架构;但不同的是,它cpu0-3都是大核,cpu4-7是小核,这个与一般的配置不太一样,一般qcom平台是反过来,cpu0-3是小核,4-7是大核)
- 当前raw_capcity是cpu 0-3:1024,cpu4-7:801
bool __init topology_parse_cpu_capacity(struct device_node *cpu_node, int cpu)
{
static bool cap_parsing_failed;
int ret;
u32 cpu_capacity;
if (cap_parsing_failed)
return false;
ret = of_property_read_u32(cpu_node, "capacity-dmips-mhz", //解析cpu core算力,kernel4.19后配置该参数
&cpu_capacity);
if (!ret) {
if (!raw_capacity) {
raw_capacity = kcalloc(num_possible_cpus(), //为所有cpu raw_capacity变量都申请空间
sizeof(*raw_capacity),
GFP_KERNEL);
if (!raw_capacity) {
cap_parsing_failed = true;
return false;
}
}
capacity_scale = max(cpu_capacity, capacity_scale); //记录最大cpu capacity值作为scale
raw_capacity[cpu] = cpu_capacity; //raw capacity就是dts中dmips值
pr_debug("cpu_capacity: %pOF cpu_capacity=%u (raw)\n",
cpu_node, raw_capacity[cpu]);
} else {
if (raw_capacity) {
pr_err("cpu_capacity: missing %pOF raw capacity\n",
cpu_node);
pr_err("cpu_capacity: partial information: fallback to 1024 for all CPUs\n");
}
cap_parsing_failed = true;
free_raw_capacity();
}
return !ret;
}
(2)将cpu raw_capacity进行归一化
- 遍历每个cpu core进行归一化,其实就是将最大值映射为1024,小的值,按照原先比例n,归一化为n*1024。
- 归一化步骤:将当前raw_capacity *1024 /capacity_scale,capacity_scale其实就是raw_capacity的最大值,其实就是1024
- 将cpu raw capacity保存到per_cpu变量:cpu_scale中,在内核调度中经常使用的cpu_capacity_orig、cpu_capacity参数的计算都依赖它。
void topology_normalize_cpu_scale(void)
{
u64 capacity;
int cpu;
if (!raw_capacity)
return;
pr_debug("cpu_capacity: capacity_scale=%u\n", capacity_scale);
for_each_possible_cpu(cpu) {
pr_debug("cpu_capacity: cpu=%d raw_capacity=%u\n",
cpu, raw_capacity[cpu]);
capacity = (raw_capacity[cpu] << SCHED_CAPACITY_SHIFT) //就是按照max cpu capacity的100% = 1024的方式归一化capacity
/ capacity_scale;
topology_set_cpu_scale(cpu, capacity); //更新per_cpu变量cpu_scale(cpu_capacity_orig)为各自的cpu raw capacity
pr_debug("cpu_capacity: CPU%d cpu_capacity=%lu\n",
cpu, topology_get_cpu_scale(cpu));
}
}
第二部分更新sibling_mask
cpu0的调用路径如下:
kernel_init
-> kernel_init_freeable
-> smp_prepare_cpus
-> store_cpu_topology
cpu1-7的调用路径如下:
secondary_start_kernel
-> store_cpu_topology
void store_cpu_topology(unsigned int cpuid)
{
struct cpu_topology *cpuid_topo = &cpu_topology[cpuid];
u64 mpidr;
if (cpuid_topo->package_id != -1) //这里因为已经解析过package_id了,所以直接就不会走读协处理器寄存器等相关步骤了
goto topology_populated;
mpidr = read_cpuid_mpidr();
/* Uniprocessor systems can rely on default topology values */
if (mpidr & MPIDR_UP_BITMASK)
return;
/*
* This would be the place to create cpu topology based on MPIDR.
*
* However, it cannot be trusted to depict the actual topology; some
* pieces of the architecture enforce an artificial cap on Aff0 values
* (e.g. GICv3's ICC_SGI1R_EL1 limits it to 15), leading to an
* artificial cycling of Aff1, Aff2 and Aff3 values. IOW, these end up
* having absolutely no relationship to the actual underlying system
* topology, and cannot be reasonably used as core / package ID.
*
* If the MT bit is set, Aff0 *could* be used to define a thread ID, but
* we still wouldn't be able to obtain a sane core ID. This means we
* need to entirely ignore MPIDR for any topology deduction.
*/
cpuid_topo->thread_id = -1;
cpuid_topo->core_id = cpuid;
cpuid_topo->package_id = cpu_to_node(cpuid);
pr_debug("CPU%u: cluster %d core %d thread %d mpidr %#016llx\n",
cpuid, cpuid_topo->package_id, cpuid_topo->core_id,
cpuid_topo->thread_id, mpidr);
topology_populated:
update_siblings_masks(cpuid); //(1)更新当前cpu的sibling_mask
}
(1)更新当前cpu的sibling_mask
- 匹配规则就是如果是同一个package id(同一个cluster内),那么就互为sibling,并设置core_sibling的mask
- 当前平台不支持超线程,所以没有thread_sibling
void update_siblings_masks(unsigned int cpuid)
{
struct cpu_topology *cpu_topo, *cpuid_topo = &cpu_topology[cpuid];
int cpu;
/* update core and thread sibling masks */
for_each_online_cpu(cpu) {
cpu_topo = &cpu_topology[cpu];
if (cpuid_topo->llc_id == cpu_topo->llc_id) { //当前平台不支持acpi,所以所有cpu的llc_id都是-1。这里都会满足
cpumask_set_cpu(cpu, &cpuid_topo->llc_sibling);
cpumask_set_cpu(cpuid, &cpu_topo->llc_sibling);
}
if (cpuid_topo->package_id != cpu_topo->package_id) //只有当在同一个cluster内时,才可能成为core_sibling/thread_sibling(当前平台不支持线程sibling)
continue;
cpumask_set_cpu(cpuid, &cpu_topo->core_sibling); //互相设置各自cpu topo结构体的core_sibling mask中添加对方的cpu bit
cpumask_set_cpu(cpu, &cpuid_topo->core_sibling);
if (cpuid_topo->core_id != cpu_topo->core_id) //只有在同一个core内时,才有可能成为thread_sibling
continue;
cpumask_set_cpu(cpuid, &cpu_topo->thread_sibling); //互相设置thread_sibling mask中的thread bit
cpumask_set_cpu(cpu, &cpuid_topo->thread_sibling);
}
}
最终我们可以通过adb查看cpu相关节点信息来确认上面的cpu topology信息:
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # ls
core_id core_siblings core_siblings_list physical_package_id thread_siblings thread_siblings_list
cpu0:
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat core_id
0
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat core_siblings
0f
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat core_siblings_list
0-3
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat physical_package_id
0
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat thread_siblings
01
TECNO-KF6p:/sys/devices/system/cpu/cpu0/topology # cat thread_siblings_list
0
cpu1:
TECNO-KF6p:/sys/devices/system/cpu/cpu1/topology # cat *
1
0f
0-3
0
02 //thread_siblings
1 //thread_siblings_list
cpu7:
TECNO-KF6p:/sys/devices/system/cpu/cpu7/topology # cat *
3 //core_id(cpu4-7的core id分别为0,1,2,3。相当于另一个cluster内重新开始计数)
f0 //core_siblings
4-7 //core_siblings_list(兄弟姐妹core列表)
1 //physical_package_id(就是cluster id)
80 //thread_siblings
7 //thread_siblings_list
以上就是CPU topology建立的相关流程了,还是比较清晰的。
sd调度域和sg调度组建立
CPU MASK
* cpu_possible_mask- has bit 'cpu' set iff cpu is populatable //系统所有cpu
* cpu_present_mask - has bit 'cpu' set iff cpu is populated //存在的所有cpu,根据hotplug变化, <= possible
* cpu_online_mask - has bit 'cpu' set iff cpu available to scheduler //处于online的cpu,即active cpu + idle cpu
* cpu_active_mask - has bit 'cpu' set iff cpu available to migration //处于active的cpu,区别与idle cpu
* cpu_isolated_mask- has bit 'cpu' set iff cpu isolated //处于isolate的cpu,隔离的cpu不会被分配task运行,但是没有下电
*
1、如果没有CONFIG_HOTPLUG_CPU,那么 present == possible, active == online。
2、配置了cpu hotplug的情况下,present会根据hotplug状态,动态变化。
调度域和调度组是在kernel初始化时开始建立的,调用路径如下:
kernel_init()
-> kernel_init_freeable()
-> sched_init_smp()
-> sched_init_domains()
传入的cpu_map是cpu_active_mask,即活动状态的cpu,建立调度域:
/* Current sched domains: */
static cpumask_var_t *doms_cur;
/* Number of sched domains in 'doms_cur': */
static int ndoms_cur;
/*
* Set up scheduler domains and groups. For now this just excludes isolated
* CPUs, but could be used to exclude other special cases in the future.
*/
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology(); //(1)填充cpu_core_map数组
ndoms_cur = 1; //记录调度域数量的变量,当前初始化为1
doms_cur = alloc_sched_domains(ndoms_cur); //alloc调度域相关结构体内存空间
if (!doms_cur)
doms_cur = &fallback_doms;
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN)); //这里会从cpu_map中挑选没有isolate的cpu,初始化时没有isolate cpu?
err = build_sched_domains(doms_cur[0], NULL); //(2)根据提供的一组cpu,建立调度域
register_sched_domain_sysctl(); //(3)注册proc/sys/kernel/sched_domain目录,并完善其中相关sysctl控制参数
return err;
}
(1)用cpu_possiable_mask填充cpu_core_map数组
int arch_update_cpu_topology(void)
{
unsigned int cpu;
for_each_possible_cpu(cpu) //遍历每个cpu
cpu_core_map[cpu] = cpu_coregroup_map(cpu); //利用cpu_possiable_mask,也就是物理上所有的cpu core
return 0;
}
(2)根据提供的可用cpu(active的cpu中去掉isolate cpu),建立调度域
- (2-1)根据配置的default topology建立其CPU拓扑结构(MC、DIE);alloc sched_domain以及per_cpu私有变量;alloc root domain空间并初始化
- (2-2)判断当前平台类型:大小核;获取拥有不同cpu capacity的最浅level:DIE
- (2-3)根据平台cpu和topology结构,申请MC、DIE level调度域,并建立其child-parent关系;初始化调度域flag和load balance参数;使能MC、DIE的idle balance
- (2-4)申请sched group并初始化cpu mask以及capacity,建立sg在MC、DIE上的内部环形链表关系;建立sd、sg、sgc的关联;
- (2-5)针对出现一些错误(sa_sd_storage)的情况下,防止正在使用的sd_data在(2-8)中被free
- (2-6)更新MC level下每个sg(其实就是每个cpu)的cpu_orig_capacity/cpu_capacity等,再更新DIE level下每个sg(其实就是每个cluster内所有cpu)的cpu_orig_capacity/cpu_capacity
- 遍历cpu_map中每个cpu,
- 找到拥有最大/最小 cpu_orig_capacity(即cpu_scale)的cpu,并保存到walt root domain结构体中
- 将新建立的MC level的sd、root domain、cpu_rq三者绑定起来
- (2-7)将每个新的MC level的sd与对应cpu rq绑定,将每个新的rd与cpu rq绑定;旧的sd、旧的rd都进行销毁
- 遍历cpu_map,找到cpu_orig_capacity的中间值(适用于有3种不同cpu core类型的情况,当前平台只有大小核,没有超大核,所以这里不用考虑);上一步中找到的最大/最小 cpu_orig_capacity(即cpu_scale)以及其对应的cpu,都将更新到rd中
- 使用static-key机制来修改当前调度域是否有不同cpu capacity的代码路径;
- 根据上述建立cpu拓扑、申请root domain的正常/异常情况,进行错误处理(释放必要结构体等)
/*
* Build sched domains for a given set of CPUs and attach the sched domains
* to the individual CPUs
*/
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
int i, ret = -ENOMEM;
struct sched_domain_topology_level *tl_asym;
bool has_asym = false;
if (WARN_ON(cpumask_empty(cpu_map))) //过滤cpu_map为空的情况
goto error;
alloc_state = __visit_domain_allocation_hell(&d, cpu_map); //(2-1)建立MC、DIE的拓扑结构;初始化root domain
if (alloc_state != sa_rootdomain)
goto error;
tl_asym = asym_cpu_capacity_level(cpu_map); //(2-2)获取包含max cpu capacity的最浅level:DIE level
/* Set up domains for CPUs specified by the cpu_map: */ //根据cpu map建立调度域
for_each_cpu(i, cpu_map) { //遍历每个cpu map中的cpu:0-7
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) { //遍历MC、DIE level
int dflags = 0;
if (tl == tl_asym) { //DIE level会带有:SD_ASYM_CPUCAPACITY flag,并设has_asym = true
dflags |= SD_ASYM_CPUCAPACITY;
has_asym = true;
}
if (WARN_ON(!topology_span_sane(tl, cpu_map, i)))
goto error;
sd = build_sched_domain(tl, cpu_map, attr, sd, dflags, i); //(2-3)建立MC、DIE level的调度域
if (tl == sched_domain_topology) //将最低层级的sd保存到s_data.sd的per_cpu变量中,当前平台为MC level的sd
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP) //判断是否sd有重叠,当前平台没有重叠
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd))) //判断cpu map和当前sd->span是否一致,一致则表示当前cpu_map中的所有cpu都在这个sd->span内。就会停止下一层tl的sd建立,可能用当前这一层的sd就已经足够了?
break;
}
}
/* Build the groups for the domains */
for_each_cpu(i, cpu_map) { //遍历cpu_map中每个cpu
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) { //从cpu的最低层级sd开始向上遍历,当前平台遍历顺序是:MC->DIE
sd->span_weight = cpumask_weight(sched_domain_span(sd)); //获取当前sd范围内的cpu数量
if (sd->flags & SD_OVERLAP) { //根据是否有重叠的sd,建立调度组sg(NUMA架构才会有这个flag)
if (build_overlap_sched_groups(sd, i)) //重叠sd情况下,建立sg(非当前平台,暂不展开)
goto error;
} else {
if (build_sched_groups(sd, i)) //(2-4)因为当前平台没有重叠sd,所以走这里建立调度组sg
goto error;
}
}
}
/* Calculate CPU capacity for physical packages and nodes */
for (i = nr_cpumask_bits-1; i >= 0; i--) { //遍历所有cpu,当前平台遍历顺序是cpu7,6...0
if (!cpumask_test_cpu(i, cpu_map)) //如果cpu不在cpu map中,应该是hotplug的情况
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) { //依次遍历MC level和DIE level
claim_allocations(i, sd); //(2-5)将用于建立sd、sg的per_cpu指针(sdd),防止随后的__free_domain_allocs()将其free
init_sched_groups_capacity(i, sd); //(2-6)初始化sg的cpu_capacity
}
}
/* Attach the domains */
rcu_read_lock();
for_each_cpu(i, cpu_map) { //遍历cpu map中所有cpu
#ifdef CONFIG_SCHED_WALT
int max_cpu = READ_ONCE(d.rd->wrd.max_cap_orig_cpu); //获取walt_root_domain中保存最大orig_capacity cpu的变量
int min_cpu = READ_ONCE(d.rd->wrd.min_cap_orig_cpu); //获取walt_root_domain中保存最小orig_capacity cpu的变量
#endif
sd = *per_cpu_ptr(d.sd, i); //最低层级的sd在上面的流程中被保存到per_cpu变量中,当前平台为MC level
#ifdef CONFIG_SCHED_WALT //通过遍历循环,找除最大和最小orig_capacity的cpu
if ((max_cpu < 0) || (arch_scale_cpu_capacity(i) >
arch_scale_cpu_capacity(max_cpu)))
WRITE_ONCE(d.rd->wrd.max_cap_orig_cpu, i);
if ((min_cpu < 0) || (arch_scale_cpu_capacity(i) <
arch_scale_cpu_capacity(min_cpu)))
WRITE_ONCE(d.rd->wrd.min_cap_orig_cpu, i);
#endif
cpu_attach_domain(sd, d.rd, i); //(2-7)将sd、rd与cpu rq绑定起来
}
#ifdef CONFIG_SCHED_WALT
/* set the mid capacity cpu (assumes only 3 capacities) */
for_each_cpu(i, cpu_map) {
int max_cpu = READ_ONCE(d.rd->wrd.max_cap_orig_cpu); //获取拥有最大orig cpu capacity的第一个cpu
int min_cpu = READ_ONCE(d.rd->wrd.min_cap_orig_cpu); //获取拥有最小orig cpu capacity的第一个cpu
if ((arch_scale_cpu_capacity(i) //找到orig cpu capacity在最大和最小之间的cpu
!= arch_scale_cpu_capacity(min_cpu)) &&
(arch_scale_cpu_capacity(i)
!= arch_scale_cpu_capacity(max_cpu))) {
WRITE_ONCE(d.rd->wrd.mid_cap_orig_cpu, i); //当前平台只有2个值orig cpu capacity,所以这里找不到mid值的cpu
break;
}
}
/*
* The max_cpu_capacity reflect the original capacity which does not
* change dynamically. So update the max cap CPU and its capacity
* here.
*/
if (d.rd->wrd.max_cap_orig_cpu != -1) {
d.rd->max_cpu_capacity.cpu = d.rd->wrd.max_cap_orig_cpu; //更新rd中的拥有最大orig cpu capacity的cpu(注意变量与max_cap_orig_cpu不同)
d.rd->max_cpu_capacity.val = arch_scale_cpu_capacity( //并更新该cpu的orig cpu capacity值
d.rd->wrd.max_cap_orig_cpu);
}
#endif
rcu_read_unlock();
if (has_asym) //当前平台为大小核架构,所以为true
static_branch_inc_cpuslocked(&sched_asym_cpucapacity); //针对sched_asym_cpucapacity的变量判断分支做更改(static key机制用来优化指令预取,类似likely/unlikely)
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map); //(2-8)根据函数最上面建立拓扑、以及申请root domain结果,释放相应的空间
return ret;
}
(2-1)建立MC、DIE的拓扑结构;初始化root domain
static enum s_alloc
__visit_domain_allocation_hell(struct s_data *d, const struct cpumask *cpu_map)
{
memset(d, 0, sizeof(*d));
if (__sdt_alloc(cpu_map)) //(2-1-1)初始化MC、DIE的拓扑结构
return sa_sd_storage;
d->sd = alloc_percpu(struct sched_domain *); //申请d->sd空间
if (!d->sd)
return sa_sd_storage;
d->rd = alloc_rootdomain(); //(2-1-2)申请root domain并初始化
if (!d->rd)
return sa_sd;
return sa_rootdomain;
}
(2-1-1)初始化MC、DIE的拓扑结构
CPU topology结构如下,因为当前平台不支持SMT,所以从下到上,分别是MC level、DIE level。在sdt_alloc()中的循环中会使用到。
/*
* Topology list, bottom-up.
*/
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
- 首先建立MC level
- alloc了sd_data结构体(&tl->data)的4个指针:sdd->sd,sdd->sds,sdd->sg,sdd->sgc;
- 在遍历CPU时,从cpu0-7,分别创建了每个per_cpu变量保存:sd、sds、sg、sgc
- 再建立DIE level
- alloc了sd_data结构体(&tl->data)的4个指针:sdd->sd,sdd->sds,sdd->sg,sdd->sgc;
- 在遍历CPU时,从cpu0-7,分别创建了每个per_cpu变量保存:sd、sds、sg、sgc
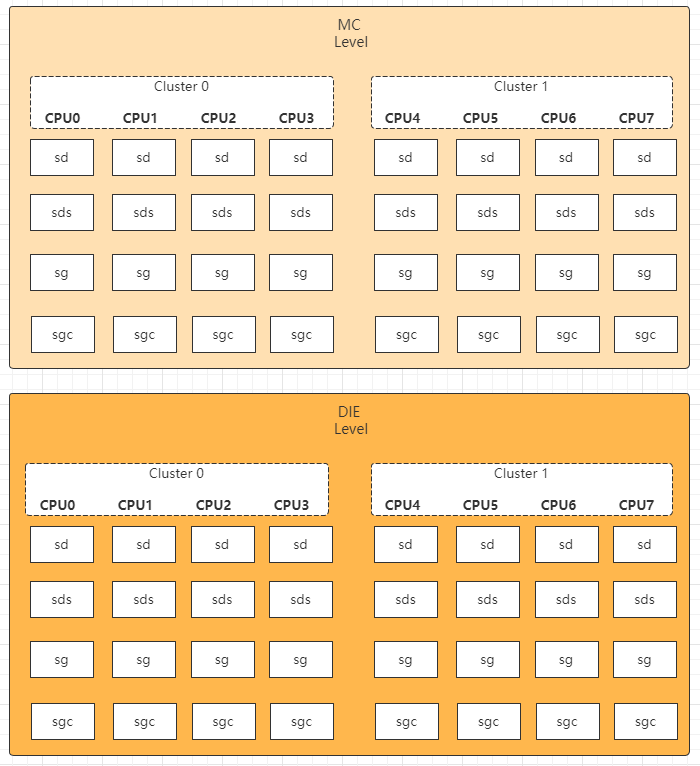
static int __sdt_alloc(const struct cpumask *cpu_map)
{
struct sched_domain_topology_level *tl;
int j;
for_each_sd_topology(tl) { //依次遍历MC、DIE结构
struct sd_data *sdd = &tl->data; //如下是为MC、DIE level的percpu变量sd_data,申请空间
sdd->sd = alloc_percpu(struct sched_domain *); //sched_domain
if (!sdd->sd)
return -ENOMEM;
sdd->sds = alloc_percpu(struct sched_domain_shared *); //sched_domain_shared
if (!sdd->sds)
return -ENOMEM;
sdd->sg = alloc_percpu(struct sched_group *); //sched_group
if (!sdd->sg)
return -ENOMEM;
sdd->sgc = alloc_percpu(struct sched_group_capacity *); //sched_group_capacity
if (!sdd->sgc)
return -ENOMEM;
for_each_cpu(j, cpu_map) { //遍历了cpu_map中所有cpu,当前平台为8核:cpu0-7
struct sched_domain *sd;
struct sched_domain_shared *sds;
struct sched_group *sg;
struct sched_group_capacity *sgc;
sd = kzalloc_node(sizeof(struct sched_domain) + cpumask_size(), //申请sd + cpumask的空间
GFP_KERNEL, cpu_to_node(j)); //cpu_to_node应该是选择cpu所在本地的内存node,UMA架构仅有一个node
if (!sd)
return -ENOMEM;
*per_cpu_ptr(sdd->sd, j) = sd; //将cpu[j]的调度域sd绑定到sdd->sd上
sds = kzalloc_node(sizeof(struct sched_domain_shared), //类似申请sds空间,并绑定到sdd->sds
GFP_KERNEL, cpu_to_node(j));
if (!sds)
return -ENOMEM;
*per_cpu_ptr(sdd->sds, j) = sds;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(), //类似申请sg + cpumask空间,并绑定到sdd->sg
GFP_KERNEL, cpu_to_node(j));
if (!sg)
return -ENOMEM;
sg->next = sg; //初始化时,sg的链表并未真正建立
*per_cpu_ptr(sdd->sg, j) = sg;
sgc = kzalloc_node(sizeof(struct sched_group_capacity) + cpumask_size(),//类似申请sgc + cpumask空间,并绑定到sdd->sgc
GFP_KERNEL, cpu_to_node(j));
if (!sgc)
return -ENOMEM;
#ifdef CONFIG_SCHED_DEBUG
sgc->id = j; //将cpu编号绑定到sgc->id
#endif
*per_cpu_ptr(sdd->sgc, j) = sgc;
}
}
return 0;
}
(2-1-2) 申请root domain并初始化
static struct root_domain *alloc_rootdomain(void)
{
struct root_domain *rd;
rd = kzalloc(sizeof(*rd), GFP_KERNEL);
if (!rd)
return NULL;
if (init_rootdomain(rd) != 0) { //(2-1-2-1)初始化root domain
kfree(rd);
return NULL;
}
return rd;
}
(2-1-2-1)初始化root domain
static int init_rootdomain(struct root_domain *rd)
{
if (!zalloc_cpumask_var(&rd->span, GFP_KERNEL)) //申请4个cpu mask的空间
goto out;
if (!zalloc_cpumask_var(&rd->online, GFP_KERNEL))
goto free_span;
if (!zalloc_cpumask_var(&rd->dlo_mask, GFP_KERNEL))
goto free_online;
if (!zalloc_cpumask_var(&rd->rto_mask, GFP_KERNEL))
goto free_dlo_mask;
#ifdef HAVE_RT_PUSH_IPI
rd->rto_cpu = -1; //初始化rto相关参数和队列,针对IPI pull的请求,在rto_mask中loop,暂时没理解?
raw_spin_lock_init(&rd->rto_lock);
init_irq_work(&rd->rto_push_work, rto_push_irq_work_func);
#endif
init_dl_bw(&rd->dl_bw); //初始化deadline bandwidth
if (cpudl_init(&rd->cpudl) != 0) //初始化cpudl结构体
goto free_rto_mask;
if (cpupri_init(&rd->cpupri) != 0) //初始化cpupri结构体
goto free_cpudl;
#ifdef CONFIG_SCHED_WALT
rd->wrd.max_cap_orig_cpu = rd->wrd.min_cap_orig_cpu = -1; //初始化walt_root_domain
rd->wrd.mid_cap_orig_cpu = -1;
#endif
init_max_cpu_capacity(&rd->max_cpu_capacity); //初始化max_cpu_capacity ->val=0、->cpu=-1
return 0;
free_cpudl:
cpudl_cleanup(&rd->cpudl);
free_rto_mask:
free_cpumask_var(rd->rto_mask);
free_dlo_mask:
free_cpumask_var(rd->dlo_mask);
free_online:
free_cpumask_var(rd->online);
free_span:
free_cpumask_var(rd->span);
out:
return -ENOMEM;
}
(2-2)获取包含max cpu capacity的最浅level:DIE level
- 判断当前是否是大小核架构:
- 遍历cpu map和cpu toplology,找到最大cpu capacity
- 找到有不同cpu capacity的level:DIE level
/*
* Find the sched_domain_topology_level where all CPU capacities are visible
* for all CPUs.
*/
static struct sched_domain_topology_level
*asym_cpu_capacity_level(const struct cpumask *cpu_map)
{
int i, j, asym_level = 0;
bool asym = false;
struct sched_domain_topology_level *tl, *asym_tl = NULL;
unsigned long cap;
/* Is there any asymmetry? */
cap = arch_scale_cpu_capacity(cpumask_first(cpu_map)); //获取cpu_map中第一个cpu,cpu0的capacity
for_each_cpu(i, cpu_map) { //判断是否有不同capacity的cpu,决定是否是大小核架构
if (arch_scale_cpu_capacity(i) != cap) { //当前平台是大小核有不同capacity
asym = true;
break;
}
}
if (!asym)
return NULL;
/*
* Examine topology from all CPU's point of views to detect the lowest
* sched_domain_topology_level where a highest capacity CPU is visible
* to everyone.
*/
for_each_cpu(i, cpu_map) { //遍历cpu map中的每个cpu,cpu 0-7
unsigned long max_capacity = arch_scale_cpu_capacity(i);
int tl_id = 0;
for_each_sd_topology(tl) { //依次遍历MC、DIE level
if (tl_id < asym_level)
goto next_level;
for_each_cpu_and(j, tl->mask(i), cpu_map) { //(2-2-1)在MC level时分别遍历cpu0-3、cpu4-7;DIE level时遍历cpu0-7
unsigned long capacity;
capacity = arch_scale_cpu_capacity(j); //获取cpu_capacity_orig
if (capacity <= max_capacity)
continue;
max_capacity = capacity; //在所有cpu中找到最大的cpu capacity
asym_level = tl_id; //记录level id:1
asym_tl = tl; //记录有不同cpu capacity的cpu topology level: DIE
}
next_level:
tl_id++;
}
}
return asym_tl;
}
(2-2-1)单独分析下tl->mask(i)
- 因为tl实际就是default_topology的指针,所以tl->mask:在MC level下,就是cpu_coregroup_mask;在DIE level下,就是cpu_cpu_mask
- 所以MC level下,获取的mask就是core_siblings mask;DIE level下,获取的就是所有物理cpu的mask
const struct cpumask *cpu_coregroup_mask(int cpu)
{
const cpumask_t *core_mask = cpumask_of_node(cpu_to_node(cpu));
/* Find the smaller of NUMA, core or LLC siblings */
if (cpumask_subset(&cpu_topology[cpu].core_sibling, core_mask)) {
/* not numa in package, lets use the package siblings */
core_mask = &cpu_topology[cpu].core_sibling;
}
if (cpu_topology[cpu].llc_id != -1) {
if (cpumask_subset(&cpu_topology[cpu].llc_sibling, core_mask))
core_mask = &cpu_topology[cpu].llc_sibling;
}
return core_mask;
}
static inline const struct cpumask *cpu_cpu_mask(int cpu)
{
return cpumask_of_node(cpu_to_node(cpu));
}
/* Returns a pointer to the cpumask of CPUs on Node 'node'. */
static inline const struct cpumask *cpumask_of_node(int node)
{
if (node == NUMA_NO_NODE) //当前平台是UMA架构,非NUMA结构,所以只有一个node
return cpu_all_mask;
return node_to_cpumask_map[node];
}
(2-3)建立MC、DIE level的调度域

