
Linux fsync和fdatasync系统调用实现分析(Ext4文件系统)
Linux系统中,对文件系统上文件的读写一般是通过页缓存(page cache)进行的(DirectIO除外),这样设计的可以延时磁盘IO的操作,从而可以减少磁盘读写的次数,提升IO性能。但是性能和可靠性在一定程度上往往是矛盾的,虽然内核中设计有一个工作队列执行赃页回写同磁盘文件进行同步,但是在一些极端的情况下还是免不了掉电数据丢失。因此内核提供了sync、fsync、fdatasync和msync系统调用用于同步,其中sync会同步整个系统下的所有文件系统以及块设备,而fsync和fdatasync只针对单独的文件进行同步,msync用于同步经过mmap的文件。
使用这些系统API,用户可以在写完一些重要文件之后,立即执行将新写入的数据回写到磁盘,尽可能的降低数据丢失的概率。本文将介绍fsync和fdatasync的功能和区别,并以Ext4文件系统为例,分析它们是如何将数据同步到磁盘中的。
内核版本:Linux 4.10.1
内核文件:fs/sync.c、fs/ext4/fsync.c、fs/ext4/inode.c、mm/filemap.c
1、概述
当用户在写一个文件时,若在open时没有设置O_SYNC和O_DIRECT,那么新write的数据内容将会暂时保存在页缓存(page cache)中,对应的页成为赃页(dirty page),这些数据并不会立即写回磁盘中。同时内核中设计有一个等待队列bdi_wq以及一些writeback worker,它们在达到一定的条件之后(延迟时间到期(默认5s)、系统内存不足、赃页超过阈值等)就会被唤醒执行赃页(dirty page)的回写操作,文件中新写入的数据在此时才能够写回磁盘。虽然从write操作到writeback之间的窗口时间(Ext4默认启用delay alloc特性,该时间延长到了30s)较短,若在此期间设备掉电或者系统奔溃,那用户的数据将会丢失。因此,对于单个文件来说,如果需要提高可靠性,可以在写入后调用fsync和fdatasync来实现文件(数据)的同步。
fsync系统调用会同步fd表示文件的所有数据,包括数据和元数据,它会一直阻塞等待直到回写结束。fdatasync同fsync类似,但是它不会回写被修改的元数据,除非对于一些对于数据完整性检索有关的场景。例如,若仅是文件的最后一次访问时间(st_atime)或最后一次修改时间(st_mtime)发生变化是不需要同步元数据的,因为它不会影响文件数据块的检索,若是文件的大小改变了(st_isize)则显然是需要同步元数据的,若不同步则可能导致系统崩溃后无法检索修改的数据。鉴于fdatasync的以上区别,可以看出应用程序对一些无需回写文件元数据的场景使用fdatasync可以提升性能。
需要注意,如果物理磁盘的write cache被使能,那么fsync和fdatasync将不能保证回写的数据被完整的写入到磁盘存储介质中(数据可能依然保存在磁盘的cache中没有写入介质),因此可能会出现明明调用了fsync系统调用但是数据在掉电后依然丢失了或者出现文件系统不一致的情况。
最后,关于fsync和fdatasync的详细描述可以参考fsync的manual page。
2、实现分析
关于fsync和fdatasync的实现,其调用处理流程并不复杂,但是其中涉及文件系统日志和block分配管理、内存页回写机制等相关的诸多细节,若要完全掌握则需要具备相关的知识。本文结合Ext4文件系统,从主线调用流程入手进行详细分析,不深入文件系统和其他模块的过多的其他细节。同时我们约定对于Ext4文件系统,使用默认的选项,即使用order类型的日志模型,不启用inline data、加密等特殊选项。首先主要函数调用关系如下图所示:
sys_fsync/sys_datasync
---> do_fsync
---> vfs_fsync
---> vfs_fsync_range
---> mark_inode_dirty_sync
| ---> ext4_dirty_inode
| | ---> ext4_journal_start
| | ---> ext4_mark_inode_dirty
| | ---> ext4_journal_stop
| ---> inode_io_list_move_locked
| ---> wb_wakeup_delayed
---> ext4_sync_file
---> filemap_write_and_wait_range
| ---> __filemap_fdatawrite_range
| ---> do_writepages
| ---> ext4_writepages
| ---> filemap_fdatawait_range
---> jbd2_complete_transaction
---> blkdev_issue_flush
fysnc和fdatasync系统调用按照相同的执行代码路径执行。在do_fsync函数中会根据入参fd找到对应的文件描述符file结构,在vfs_fsync_range函数中fdatasync流程不会执行mark_inode_dirty_sync函数分支,fsync函数会判断当前的文件是否在访问、修改时间上有发生过变化,若发生过变化则会调用mark_inode_dirty_sync分支更新元数据并设置为dirty然后将对应的赃页添加到jbd2日志的对应链表中等待日志提交进程执行回写;随后的ext4_sync_file函数中会调用filemap_write_and_wait_range函数同步文件中的dirty page cache,它会向block层提交bio并等待回写执行结束,然后调用jbd2_complete_transaction函数触发元数据回写(若元数据不为脏则不会回写任何与该文件相关的元数据),最后若Ext4文件系统启用了barrier特性且需要flush write cache,那调用blkdev_issue_flush向底层发送flush指令,这将触发磁盘中的cache写入介质的操作(这样就能保证在正常情况下数据都被落盘了)。
具体的执行流程图如下图所示:
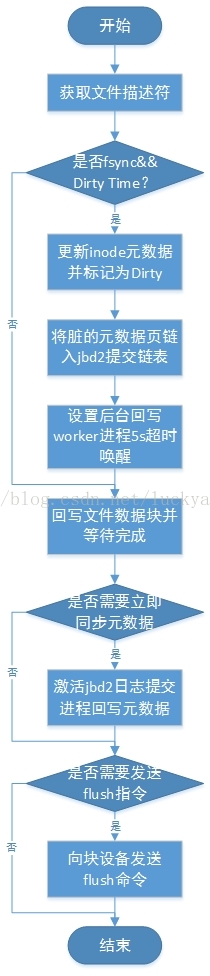
下面跟踪fsync和fdatasync系统调用的源代码具体分析它是如何实现文件数据同步操作的:
SYSCALL_DEFINE1(fsync, unsigned int, fd)
{
return do_fsync(fd, 0);
}
SYSCALL_DEFINE1(fdatasync, unsigned int, fd)
{
return do_fsync(fd, 1);
}
fsync和fdatasync系统调用只有一个入参,即已经打开的文件描述符fd;函数直接调用do_fsync,仅第二个入参datasync标识不同。
static int do_fsync(unsigned int fd, int datasync)
{
struct fd f = fdget(fd);
int ret = -EBADF;
if (f.file) {
ret = vfs_fsync(f.file, datasync);
fdput(f);
}
return ret;
}
do_fsync函数首先调用fdget从当前进程的fdtable中根据fd找到对应的struct fd结构体,真正用到的是它里面的struct file实例(该结构体在open文件时动态生成并和fd绑定后保存在进程task_struct结构体中),然后调用通用函数vfs_fsync。
/**
* vfs_fsync - perform a fsync or fdatasync on a file
* @file: file to sync
* @datasync: only perform a fdatasync operation
*
* Write back data and metadata for @file to disk. If @datasync is
* set only metadata needed to access modified file data is written.
*/
int vfs_fsync(struct file *file, int datasync)
{
return vfs_fsync_range(file, 0, LLONG_MAX, datasync);
}
EXPORT_SYMBOL(vfs_fsync);
vfs_fsync函数直接转调vfs_fsync_range,其中入参二和入参三为需要同步文件数据位置的起始与结束偏移值,以字节为单位,这里传入的分别是0和LLONG_MAX,显然是表明要同步所有的数据了。
/**
* vfs_fsync_range - helper to sync a range of data & metadata to disk
* @file: file to sync
* @start: offset in bytes of the beginning of data range to sync
* @end: offset in bytes of the end of data range (inclusive)
* @datasync: perform only datasync
*
* Write back data in range @start..@end and metadata for @file to disk. If
* @datasync is set only metadata needed to access modified file data is
* written.
*/
int vfs_fsync_range(struct file *file, loff_t start, loff_t end, int datasync)
{
struct inode *inode = file->f_mapping->host;
if (!file->f_op->fsync)
return -EINVAL;
if (!datasync && (inode->i_state & I_DIRTY_TIME)) {
spin_lock(&inode->i_lock);
inode->i_state &= ~I_DIRTY_TIME;
spin_unlock(&inode->i_lock);
mark_inode_dirty_sync(inode);
}
return file->f_op->fsync(file, start, end, datasync);
}
EXPORT_SYMBOL(vfs_fsync_range);
vfs_fsync_range函数首先从file结构体的addess_space中找到文件所属的inode(地址映射address_space结构在open文件时的sys_open->do_dentry_open调用中初始化,里面保存了该文件的所有建立的page cache、底层块设备和对应的操作函数集),然后判断文件系统的file_operation函数集是否实现了fsync接口,如果未实现直接返回EINVAL。
接下来在非datasync(sync)的情况下会对inode的I_DIRTY_TIME标记进行判断,如果置位了该标识(表示该文件的时间戳已经发生了跟新但还没有同步到磁盘上)则清除该标志位并调用mark_inode_dirty_sync设置I_DIRTY_SYNC标识,表示需要进行sync同步操作。该函数会针对当前inode所在的不同state进行区别处理,同时会将inode添加到后台回刷bdi的Dirty list上去(bdi回写任务会遍历该list执行同步操作,当然容易导致误解的是当前的回写流程是不会由bdi write back worker来执行的,而是在本调用流程中就直接一气呵成的)。
static inline void mark_inode_dirty_sync(struct inode *inode)
{
__mark_inode_dirty(inode, I_DIRTY_SYNC);
}
void __mark_inode_dirty(struct inode *inode, int flags)
{
#define I_DIRTY_INODE (I_DIRTY_SYNC | I_DIRTY_DATASYNC)
struct super_block *sb = inode->i_sb;
int dirtytime;
trace_writeback_mark_inode_dirty(inode, flags);
/*
* Don't do this for I_DIRTY_PAGES - that doesn't actually
* dirty the inode itself
*/
if (flags & (I_DIRTY_SYNC | I_DIRTY_DATASYNC | I_DIRTY_TIME)) {
trace_writeback_dirty_inode_start(inode, flags);
if (sb->s_op->dirty_inode)
sb->s_op->dirty_inode(inode, flags);
trace_writeback_dirty_inode(inode, flags);
}
__mark_inode_dirty函数由于当前传入的flag等于I_DIRTY_SYNC(表示inode为脏但是不需要在fdatasync时进行同步,一般用于时间戳i_atime等改变的情况下,定义在include/linux/fs.h中),所以这里会调用文件系统的dirty_inode函数指针,对于ext4文件系统即是ext4_dirty_inode函数。
void ext4_dirty_inode(struct inode *inode, int flags)
{
handle_t *handle;
if (flags == I_DIRTY_TIME)
return;
handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);
if (IS_ERR(handle))
goto out;
ext4_mark_inode_dirty(handle, inode);
ext4_journal_stop(handle);
out:
return;
}
ext4_dirty_inode函数涉及ext4文件系统使用的jbd2日志模块,它将启用一个新的日志handle(日志原子操作)并将应该同步的inode元数据block向日志jbd2模块transaction进行提交(注意不会立即写日志和回写)。其中ext4_journal_start函数会简单判断一下ext4文件系统的日志执行状态最后直接调用jbd2__journal_start来启用日志handle;然后ext4_mark_inode_dirty函数会调用ext4_get_inode_loc获取inode元数据所在的buffer head映射block,按照标准的日志提交流程jbd2_journal_get_write_access(获取写权限)-> 对元数据raw_inode进行更新 -> jbd2_journal_dirty_metadata(设置元数据为脏并添加到日志transaction的对应链表中);最后ext4_journal_stop->jbd2_journal_stop调用流程结束这个handle原子操作。这样后面日志commit进程会对日志的元数据块进行提交(注意,这里并不会立即唤醒日志commit进程启动日志提交动作,启用largefile特性除外)。
回到__mark_inode_dirty函数中继续往下分析:
if (flags & I_DIRTY_INODE)
flags &= ~I_DIRTY_TIME;
dirtytime = flags & I_DIRTY_TIME;
/*
* Paired with smp_mb() in __writeback_single_inode() for the
* following lockless i_state test. See there for details.
*/
smp_mb();
if (((inode->i_state & flags) == flags) ||
(dirtytime && (inode->i_state & I_DIRTY_INODE)))
return;
下面如果inode当前的state同要设置的标识完全相同或者在设置dirtytime的情况下inode已经为脏了那就直接退出,无需再设置标识了和添加Dirty list了。
if (unlikely(block_dump))
block_dump___mark_inode_dirty(inode);
spin_lock(&inode->i_lock);
if (dirtytime && (inode->i_state & I_DIRTY_INODE))
goto out_unlock_inode;
if ((inode->i_state & flags) != flags) {
const int was_dirty = inode->i_state & I_DIRTY;
inode_attach_wb(inode, NULL);
if (flags & I_DIRTY_INODE)
inode->i_state &= ~I_DIRTY_TIME;
inode->i_state |= flags;
/*
* If the inode is being synced, just update its dirty state.
* The unlocker will place the inode on the appropriate
* superblock list, based upon its state.
*/
if (inode->i_state & I_SYNC)
goto out_unlock_inode;
/*
* Only add valid (hashed) inodes to the superblock's
* dirty list. Add blockdev inodes as well.
*/
if (!S_ISBLK(inode->i_mode)) {
if (inode_unhashed(inode))
goto out_unlock_inode;
}
if (inode->i_state & I_FREEING)
goto out_unlock_inode;
首先为了便于调试,在设置了block_dump时会有调试信息的打印,会调用block_dump___mark_inode_dirty函数将该dirty inode的inode号、文件名和设备名打印出来。
然后对inode上锁并进行最后的处理,先设置i_state添加flag标记,当前置位的flag为I_DIRTY_SYNC,执行到此处inode的状态标识就设置完了;随后判断该inode是否已经正在进行sync同步(设置I_SYNC标识,在执行回写worker的writeback_sb_inodes函数调用中会设置该标识)或者inode已经在销毁释放的过程中了,若是则直接退出,不再继续回写。
/*
* If the inode was already on b_dirty/b_io/b_more_io, don't
* reposition it (that would break b_dirty time-ordering).
*/
if (!was_dirty) {
struct bdi_writeback *wb;
struct list_head *dirty_list;
bool wakeup_bdi = false;
wb = locked_inode_to_wb_and_lock_list(inode);
WARN(bdi_cap_writeback_dirty(wb->bdi) &&
!test_bit(WB_registered, &wb->state),
"bdi-%s not registered\n", wb->bdi->name);
inode->dirtied_when = jiffies;
if (dirtytime)
inode->dirtied_time_when = jiffies;
if (inode->i_state & (I_DIRTY_INODE | I_DIRTY_PAGES))
dirty_list = &wb->b_dirty;
else
dirty_list = &wb->b_dirty_time;
wakeup_bdi = inode_io_list_move_locked(inode, wb,
dirty_list);
spin_unlock(&wb->list_lock);
trace_writeback_dirty_inode_enqueue(inode);
/*
* If this is the first dirty inode for this bdi,
* we have to wake-up the corresponding bdi thread
* to make sure background write-back happens
* later.
*/
if (bdi_cap_writeback_dirty(wb->bdi) && wakeup_bdi)
wb_wakeup_delayed(wb);
return;
}
}
out_unlock_inode:
spin_unlock(&inode->i_lock);
#undef I_DIRTY_INODE
}
最后针对当前的inode尚未Dirty的情况,设置inode的Dirty time并将它添加到它回写bdi_writeback对应的Dirty list中去(当前上下文添加的是wb->b_dirty链表),然后判断该bdi是否没有正在处理的dirty io操作(需判断dirty list、io list和io_more list是否都为空)且支持回写操作,就调用wb_wakeup_delayed函数往后台回写工作队列添加延时回写任务,延时的时间由dirty_writeback_interval全局变量设定,默认值为5s时间。
当然了,虽然这里会让writeback回写进程在5s以后唤醒执行回写,但是在当前fsync的调用流程中是绝对不会等5s以后由writeback回写进程来执行回写的(这部分涉及后台bdi赃页回写机制)。
回到vfs_fsync_range函数中,代码流程执行到这里,从针对!datasync && (inode->i_state & I_DIRTY_TIME)这个条件的分支处理中就可以看到fsync和fdatasync系统调用的不同之处了:fsync系统调用针对时间戳变化的inode会设置inode为Dirty,这将导致后面的执行流程对文件的元数据进行回写,而fdatasync则不会。
继续往下分析,vfs_fsync_range函数最后调用file_operation函数集里的fsync注册函数,ext4文件系统调用的是ext4_sync_file,将由ext4文件系统执行文件数据和元数据的同步操作。
/*
* akpm: A new design for ext4_sync_file().
*
* This is only called from sys_fsync(), sys_fdatasync() and sys_msync().
* There cannot be a transaction open by this task.
* Another task could have dirtied this inode. Its data can be in any
* state in the journalling system.
*
* What we do is just kick off a commit and wait on it. This will snapshot the
* inode to disk.
*/
int ext4_sync_file(struct file *file, loff_t start, loff_t end, int datasync)
{
struct inode *inode = file->f_mapping->host;
struct ext4_inode_info *ei = EXT4_I(inode);
journal_t *journal = EXT4_SB(inode->i_sb)->s_journal;
int ret = 0, err;
tid_t commit_tid;
bool needs_barrier = false;
J_ASSERT(ext4_journal_current_handle() == NULL);
trace_ext4_sync_file_enter(file, datasync);
if (inode->i_sb->s_flags & MS_RDONLY) {
/* Make sure that we read updated s_mount_flags value */
smp_rmb();
if (EXT4_SB(inode->i_sb)->s_mount_flags & EXT4_MF_FS_ABORTED)
ret = -EROFS;
goto out;
}
分段来分析ext4_sync_file函数,首先明确几个局部变量:
1、commit_tid是日志提交事物的transaction id,用来区分不同的事物(transaction);
2、needs_barrier用于表示是否需要对所在的块设备发送cache刷写命令,是一种用于保护数据一致性的手段。这几个局部变量后面会看到是如何使用的,这里先关注一下。
ext4_sync_file函数首先判断文件系统只读的情况,对于一般以只读方式挂载的文件系统由于不会写入文件,所以不需要执行fsync/fdatasync操作,立即返回success即可。但是文件系统只读也可能是发生了错误导致的,因此这里会做一个判断,如果文件系统abort(出现致命错误),就需要返回EROFS而不是success,这样做是为了避免应用程序误认为文件已经同步成功了。
if (!journal) {
ret = __generic_file_fsync(file, start, end, datasync);
if (!ret)
ret = ext4_sync_parent(inode);
if (test_opt(inode->i_sb, BARRIER))
goto issue_flush;
goto out;
}
接下来处理未开启日志的情况,这种情况下将调用通用函数__generic_file_fsync进行文件同步,随后调用ext4_sync_parent对文件所在的父目录进行同步。之所以要同步父目录是因为在未开启日志的情况下,若同步的是一个新创建的文件,那么待到父目录的目录项通过writeback后台回写之间将有一个巨大的时间窗口,在这段时间内掉电或者系统崩溃就会导致数据的丢失,所以这里及时同步父目录项将该时间窗大大的缩短,也就提高了数据的安全性。ext4_sync_parent函数会对它的父目录进行递归,若是新创建的目录都将进行同步。
由于在默认情况下是启用日志的(jbd2日志模块journal在mount文件系统时的ext4_fill_super->ext4_load_journal调用流程中初始化),所以这个分支暂不详细分析,回到ext4_sync_file中分析默认开启日志的情况。
ret = filemap_write_and_wait_range(inode->i_mapping, start, end);
if (ret)
return ret;
接下来调用filemap_write_and_wait_range回写从start到end的dirty文件数据块并等待回写完成。
/**
* filemap_write_and_wait_range - write out & wait on a file range
* @mapping: the address_space for the pages
* @lstart: offset in bytes where the range starts
* @lend: offset in bytes where the range ends (inclusive)
*
* Write out and wait upon file offsets lstart->lend, inclusive.
*
* Note that `lend' is inclusive (describes the last byte to be written) so
* that this function can be used to write to the very end-of-file (end = -1).
*/
int filemap_write_and_wait_range(struct address_space *mapping,
loff_t lstart, loff_t lend)
{
int err = 0;
if ((!dax_mapping(mapping) && mapping->nrpages) ||
(dax_mapping(mapping) && mapping->nrexceptional)) {
err = __filemap_fdatawrite_range(mapping, lstart, lend,
WB_SYNC_ALL);
/* See comment of filemap_write_and_wait() */
if (err != -EIO) {
int err2 = filemap_fdatawait_range(mapping,
lstart, lend);
if (!err)
err = err2;
}
} else {
err = filemap_check_errors(mapping);
}
return err;
}
EXPORT_SYMBOL(filemap_write_and_wait_range);
filemap_check_errors函数主要检测地址空间的AS_EIO和AS_ENOSPC标识,前者表示发生IO错误,后者表示空间不足(它们定义在include/linux/pagemap.h中),只需要对这两种异常标记进行清除即可。
若有页缓存需要回写,则调用__filemap_fdatawrite_range执行回写,注意最后一个入参是WB_SYNC_ALL,这表示将会等待回写结束:
/**
* __filemap_fdatawrite_range - start writeback on mapping dirty pages in range
* @mapping: address space structure to write
* @start: offset in bytes where the range starts
* @end: offset in bytes where the range ends (inclusive)
* @sync_mode: enable synchronous operation
*
* Start writeback against all of a mapping's dirty pages that lie
* within the byte offsets <start, end> inclusive.
*
* If sync_mode is WB_SYNC_ALL then this is a "data integrity" operation, as
* opposed to a regular memory cleansing writeback. The difference between
* these two operations is that if a dirty page/buffer is encountered, it must
* be waited upon, and not just skipped over.
*/
int __filemap_fdatawrite_range(struct address_space *mapping, loff_t start,
loff_t end, int sync_mode)
{
int ret;
struct writeback_control wbc = {
.sync_mode = sync_mode,
.nr_to_write = LONG_MAX,
.range_start = start,
.range_end = end,
};
if (!mapping_cap_writeback_dirty(mapping))
return 0;
wbc_attach_fdatawrite_inode(&wbc, mapping->host);
ret = do_writepages(mapping, &wbc);
wbc_detach_inode(&wbc);
return ret;
}
从函数的注释中可以看出,__filemap_fdatawrite_range函数会将<start, end>位置的dirty page回写。它首先构造一个struct writeback_control实例并初始化相应的字段,该结构体用于控制writeback回写操作,其中sync_mode表示同步模式,一共有WB_SYNC_NONE和WB_SYNC_ALL两种可选,前一种不会等待回写结束,一般用于周期性回写,后一种会等待回写结束,用于sync之类的强制回写;nr_to_write表示要回写的页数;range_start和range_end表示要会写的偏移起始和结束的位置,以字节为单位。
接下来调用mapping_cap_writeback_dirty函数判断文件所在的bdi是否支持回写动作,若不支持则直接返回0(表示写回的数量为0);然后调用wbc_attach_fdatawrite_inode函数将wbc和inode的bdi进行绑定(需启用blk_cgroup内核属性,否则为空操作);然后调用do_writepages执行回写动作,回写完毕后调用wbc_detach_inode函数将wbc和inode解除绑定。
int do_writepages(struct address_space *mapping, struct writeback_control *wbc)
{
int ret;
if (wbc->nr_to_write <= 0)
return 0;
if (mapping->a_ops->writepages)
ret = mapping->a_ops->writepages(mapping, wbc);
else
ret = generic_writepages(mapping, wbc);
return ret;
}
do_writepages函数将优先调用地址空间a_ops函数集中的writepages注册函数,ext4文件系统实现为ext4_writepages,若没有实现则调用通用函数generic_writepages(该函数在后台赃页回刷进程wb_workfn函数调用流程中也会被调用来执行回写操作)。
下面来简单分析ext4_writepages是如何执行页回写的(函数较长,分段来看):
static int ext4_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
pgoff_t writeback_index = 0;
long nr_to_write = wbc->nr_to_write;
int range_whole = 0;
int cycled = 1;
handle_t *handle = NULL;
struct mpage_da_data mpd;
struct inode *inode = mapping->host;
int needed_blocks, rsv_blocks = 0, ret = 0;
struct ext4_sb_info *sbi = EXT4_SB(mapping->host->i_sb);
bool done;
struct blk_plug plug;
bool give_up_on_write = false;
percpu_down_read(&sbi->s_journal_flag_rwsem);
trace_ext4_writepages(inode, wbc);
if (dax_mapping(mapping)) {
ret = dax_writeback_mapping_range(mapping, inode->i_sb->s_bdev,
wbc);
goto out_writepages;
}
/*
* No pages to write? This is mainly a kludge to avoid starting
* a transaction for special inodes like journal inode on last iput()
* because that could violate lock ordering on umount
*/
if (!mapping->nrpages || !mapping_tagged(mapping, PAGECACHE_TAG_DIRTY))
goto out_writepages;
if (ext4_should_journal_data(inode)) {
struct blk_plug plug;
blk_start_plug(&plug);
ret = write_cache_pages(mapping, wbc, __writepage, mapping);
blk_finish_plug(&plug);
goto out_writepages;
}
ext4_writepages函数首先针对dax_mapping的分支,数据页的回写交由dax_writeback_mapping_range处理;接下来判断是否有页需要回写,如果地址空间中没有映射页或者radix tree中没有设置PAGECACHE_TAG_DIRTY标识(即无脏页,该标识会在__set_page_dirty函数中对脏的数据块设置),那就直接退出即可。
然后判断当前文件系统的日志模式,如果是journal模式(数据块和元数据块都需要写jbd2日志),将交由write_cache_pages函数执行回写,由于默认使用的是order日志模式,所以略过,继续往下分析。
/*
* If the filesystem has aborted, it is read-only, so return
* right away instead of dumping stack traces later on that
* will obscure the real source of the problem. We test
* EXT4_MF_FS_ABORTED instead of sb->s_flag's MS_RDONLY because
* the latter could be true if the filesystem is mounted
* read-only, and in that case, ext4_writepages should
* *never* be called, so if that ever happens, we would want
* the stack trace.
*/
if (unlikely(sbi->s_mount_flags & EXT4_MF_FS_ABORTED)) {
ret = -EROFS;
goto out_writepages;
}
if (ext4_should_dioread_nolock(inode)) {
/*
* We may need to convert up to one extent per block in
* the page and we may dirty the inode.
*/
rsv_blocks = 1 + (PAGE_SIZE >> inode->i_blkbits);
}
接下处理dioread_nolock特性, 该特性会在文件写buffer前分配未初始化的extent,等待写IO完成后才会对extent进行初始化,以此可以免去加解inode mutext锁,从而来达到加速写操作的目的。该特性只对启用了extent属性的文件有用,且不支持journal日志模式。若启用了该特性则需要在日志中设置保留块,默认文件系统的块大小为4KB,那这里将指定保留块为2个。
/*
* If we have inline data and arrive here, it means that
* we will soon create the block for the 1st page, so
* we'd better clear the inline data here.
*/
if (ext4_has_inline_data(inode)) {
/* Just inode will be modified... */
handle = ext4_journal_start(inode, EXT4_HT_INODE, 1);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
goto out_writepages;
}
BUG_ON(ext4_test_inode_state(inode,
EXT4_STATE_MAY_INLINE_DATA));
ext4_destroy_inline_data(handle, inode);
ext4_journal_stop(handle);
}
接下来处理inline data特性,该特性是对于小文件的,它的数据内容足以保存在inode block中,这里也同样先略过该特性的处理。
if (wbc->range_start == 0 && wbc->range_end == LLONG_MAX)
range_whole = 1;
if (wbc->range_cyclic) {
writeback_index = mapping->writeback_index;
if (writeback_index)
cycled = 0;
mpd.first_page = writeback_index;
mpd.last_page = -1;
} else {
mpd.first_page = wbc->range_start >> PAGE_SHIFT;
mpd.last_page = wbc->range_end >> PAGE_SHIFT;
}
mpd.inode = inode;
mpd.wbc = wbc;
ext4_io_submit_init(&mpd.io_submit, wbc);
接下来进行一些标识位的判断,其中range_whole置位表示写整个文件;然后初始化struct mpage_da_data mpd结构体,在当前的非周期写的情况下设置需要写的first_page和last_page,然后初始化mpd结构体的inode、wbc和io_submit这三个字段,然后跳转到retry标号处开始执行。
retry:
if (wbc->sync_mode == WB_SYNC_ALL || wbc->tagged_writepages)
tag_pages_for_writeback(mapping, mpd.first_page, mpd.last_page);
done = false;
blk_start_plug(&plug);
这里的tag_pages_for_writeback函数需要关注一下,它将address_mapping的radix tree中已经设置了PAGECACHE_TAG_DIRTY标识的节点设置上PAGECACHE_TAG_TOWRITE标识,表示开始回写,后文中的等待结束__filemap_fdatawrite_range函数会判断该标识。接下来进入一个大循环,逐一处理需要回写的数据页。
while (!done && mpd.first_page <= mpd.last_page) {
/* For each extent of pages we use new io_end */
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
if (!mpd.io_submit.io_end) {
ret = -ENOMEM;
break;
}
/*
* We have two constraints: We find one extent to map and we
* must always write out whole page (makes a difference when
* blocksize < pagesize) so that we don't block on IO when we
* try to write out the rest of the page. Journalled mode is
* not supported by delalloc.
*/
BUG_ON(ext4_should_journal_data(inode));
needed_blocks = ext4_da_writepages_trans_blocks(inode);
/* start a new transaction */
handle = ext4_journal_start_with_reserve(inode,
EXT4_HT_WRITE_PAGE, needed_blocks, rsv_blocks);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
ext4_msg(inode->i_sb, KERN_CRIT, "%s: jbd2_start: "
"%ld pages, ino %lu; err %d", __func__,
wbc->nr_to_write, inode->i_ino, ret);
/* Release allocated io_end */
ext4_put_io_end(mpd.io_submit.io_end);
break;
}
trace_ext4_da_write_pages(inode, mpd.first_page, mpd.wbc);
ret = mpage_prepare_extent_to_map(&mpd);
if (!ret) {
if (mpd.map.m_len)
ret = mpage_map_and_submit_extent(handle, &mpd,
&give_up_on_write);
else {
/*
* We scanned the whole range (or exhausted
* nr_to_write), submitted what was mapped and
* didn't find anything needing mapping. We are
* done.
*/
done = true;
}
}
/*
* Caution: If the handle is synchronous,
* ext4_journal_stop() can wait for transaction commit
* to finish which may depend on writeback of pages to
* complete or on page lock to be released. In that
* case, we have to wait until after after we have
* submitted all the IO, released page locks we hold,
* and dropped io_end reference (for extent conversion
* to be able to complete) before stopping the handle.
*/
if (!ext4_handle_valid(handle) || handle->h_sync == 0) {
ext4_journal_stop(handle);
handle = NULL;
}
/* Submit prepared bio */
ext4_io_submit(&mpd.io_submit);
/* Unlock pages we didn't use */
mpage_release_unused_pages(&mpd, give_up_on_write);
/*
* Drop our io_end reference we got from init. We have
* to be careful and use deferred io_end finishing if
* we are still holding the transaction as we can
* release the last reference to io_end which may end
* up doing unwritten extent conversion.
*/
if (handle) {
ext4_put_io_end_defer(mpd.io_submit.io_end);
ext4_journal_stop(handle);
} else
ext4_put_io_end(mpd.io_submit.io_end);
if (ret == -ENOSPC && sbi->s_journal) {
/*
* Commit the transaction which would
* free blocks released in the transaction
* and try again
*/
jbd2_journal_force_commit_nested(sbi->s_journal);
ret = 0;
continue;
}
/* Fatal error - ENOMEM, EIO... */
if (ret)
break;
}
这里的tag_pages_for_writeback函数需要关注一下,它将address_mapping的radix tree中已经设置了PAGECACHE_TAG_DIRTY标识的节点设置上PAGECACHE_TAG_TOWRITE标识,表示开始回写,后文中的等待结束__filemap_fdatawrite_range函数会判断该标识。接下来进入一个大循环,逐一处理需要回写的数据页。
while (!done && mpd.first_page <= mpd.last_page) {
/* For each extent of pages we use new io_end */
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
if (!mpd.io_submit.io_end) {
ret = -ENOMEM;
break;
}
/*
* We have two constraints: We find one extent to map and we
* must always write out whole page (makes a difference when
* blocksize < pagesize) so that we don't block on IO when we
* try to write out the rest of the page. Journalled mode is
* not supported by delalloc.
*/
BUG_ON(ext4_should_journal_data(inode));
needed_blocks = ext4_da_writepages_trans_blocks(inode);
/* start a new transaction */
handle = ext4_journal_start_with_reserve(inode,
EXT4_HT_WRITE_PAGE, needed_blocks, rsv_blocks);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
ext4_msg(inode->i_sb, KERN_CRIT, "%s: jbd2_start: "
"%ld pages, ino %lu; err %d", __func__,
wbc->nr_to_write, inode->i_ino, ret);
/* Release allocated io_end */
ext4_put_io_end(mpd.io_submit.io_end);
break;
}
trace_ext4_da_write_pages(inode, mpd.first_page, mpd.wbc);
ret = mpage_prepare_extent_to_map(&mpd);
if (!ret) {
if (mpd.map.m_len)
ret = mpage_map_and_submit_extent(handle, &mpd,
&give_up_on_write);
else {
/*
* We scanned the whole range (or exhausted
* nr_to_write), submitted what was mapped and
* didn't find anything needing mapping. We are
* done.
*/
done = true;
}
}
/*
* Caution: If the handle is synchronous,
* ext4_journal_stop() can wait for transaction commit
* to finish which may depend on writeback of pages to
* complete or on page lock to be released. In that
* case, we have to wait until after after we have
* submitted all the IO, released page locks we hold,
* and dropped io_end reference (for extent conversion
* to be able to complete) before stopping the handle.
*/
if (!ext4_handle_valid(handle) || handle->h_sync == 0) {
ext4_journal_stop(handle);
handle = NULL;
}
/* Submit prepared bio */
ext4_io_submit(&mpd.io_submit);
/* Unlock pages we didn't use */
mpage_release_unused_pages(&mpd, give_up_on_write);
/*
* Drop our io_end reference we got from init. We have
* to be careful and use deferred io_end finishing if
* we are still holding the transaction as we can
* release the last reference to io_end which may end
* up doing unwritten extent conversion.
*/
if (handle) {
ext4_put_io_end_defer(mpd.io_submit.io_end);
ext4_journal_stop(handle);
} else
ext4_put_io_end(mpd.io_submit.io_end);
if (ret == -ENOSPC && sbi->s_journal) {
/*
* Commit the transaction which would
* free blocks released in the transaction
* and try again
*/
jbd2_journal_force_commit_nested(sbi->s_journal);
ret = 0;
continue;
}
/* Fatal error - ENOMEM, EIO... */
if (ret)
break;
}
该循环中的调用流程非常复杂,这里简单描述一下:首先调用ext4_da_writepages_trans_blocks计算extext所需要使用的block数量,然后调用ext4_journal_start_with_reserve启动一个新的日志handle,需要的block数量和保留block数量通过needed_blocks和rsv_blocks给出;然后调用mpage_prepare_extent_to_map和mpage_map_and_submit_extent函数,它将遍历查找wbc中的PAGECACHE_TAG_TOWRITE为标记的节点,对其中已经映射的赃页直接下发IO,对没有映射的则计算需要映射的页要使用的extent并进行映射;随后调用ext4_io_submit下发bio,最后调用ext4_journal_stop结束本次handle。
回到filemap_write_and_wait_range函数中,如果__filemap_fdatawrite_range函数返回不是IO错误,那将调用filemap_fdatawait_range等待回写结束。
int filemap_fdatawait_range(struct address_space *mapping, loff_t start_byte,
loff_t end_byte)
{
int ret, ret2;
ret = __filemap_fdatawait_range(mapping, start_byte, end_byte);
ret2 = filemap_check_errors(mapping);
if (!ret)
ret = ret2;
return ret;
}
EXPORT_SYMBOL(filemap_fdatawait_range);
filemap_fdatawait_range函数一共做了两件事,第一件事就是调用__filemap_fdatawait_range等待<start_byte, end_byte>回写完毕,第二件事是调用filemap_check_errors进行错误处理。
static int __filemap_fdatawait_range(struct address_space *mapping,
loff_t start_byte, loff_t end_byte)
{
pgoff_t index = start_byte >> PAGE_SHIFT;
pgoff_t end = end_byte >> PAGE_SHIFT;
struct pagevec pvec;
int nr_pages;
int ret = 0;
if (end_byte < start_byte)
goto out;
pagevec_init(&pvec, 0);
while ((index <= end) &&
(nr_pages = pagevec_lookup_tag(&pvec, mapping, &index,
PAGECACHE_TAG_WRITEBACK,
min(end - index, (pgoff_t)PAGEVEC_SIZE-1) + 1)) != 0) {
unsigned i;
for (i = 0; i < nr_pages; i++) {
struct page *page = pvec.pages[i];
/* until radix tree lookup accepts end_index */
if (page->index > end)
continue;
wait_on_page_writeback(page);
if (TestClearPageError(page))
ret = -EIO;
}
pagevec_release(&pvec);
cond_resched();
}
out:
return ret;
}
__filemap_fdatawait_range函数是一个大循环,在循环中会调用pagevec_lookup_tag函数找到radix tree中设置了PAGECACHE_TAG_WRITEBACK标记的节点(对应前文中的标记位置),然后调用wait_on_page_writeback函数设置等待队列等待对应page的PG_writeback标记被清除(表示回写结束),这里的等待会让进程进入D状态,最后如果发生了错误会返回-EIO,进而触发filemap_fdatawait_range->filemap_check_errors错误检查调用。
通过以上filemap_write_and_wait_range调用可以看出,文件的回写动作并没有通过由后台bdi回写进程来执行,这里的fsync和fdatasync系统调用就在当前调用进程中执行回写的。
至此,文件的数据回写就完成了,而元数据尚在日志事物中等待提交,接下来回到最外层的ext4_sync_file函数,提交最后的元数据块。
/*
* data=writeback,ordered:
* The caller's filemap_fdatawrite()/wait will sync the data.
* Metadata is in the journal, we wait for proper transaction to
* commit here.
*
* data=journal:
* filemap_fdatawrite won't do anything (the buffers are clean).
* ext4_force_commit will write the file data into the journal and
* will wait on that.
* filemap_fdatawait() will encounter a ton of newly-dirtied pages
* (they were dirtied by commit). But that's OK - the blocks are
* safe in-journal, which is all fsync() needs to ensure.
*/
if (ext4_should_journal_data(inode)) {
ret = ext4_force_commit(inode->i_sb);
goto out;
}
commit_tid = datasync ? ei->i_datasync_tid : ei->i_sync_tid;
if (journal->j_flags & JBD2_BARRIER &&
!jbd2_trans_will_send_data_barrier(journal, commit_tid))
needs_barrier = true;
ret = jbd2_complete_transaction(journal, commit_tid);
if (needs_barrier) {
issue_flush:
err = blkdev_issue_flush(inode->i_sb->s_bdev, GFP_KERNEL, NULL);
if (!ret)
ret = err;
}
out:
trace_ext4_sync_file_exit(inode, ret);
return ret;
}
参考注释中的说明,对于默认的ordered模式,前面的filemap_write_and_wait_range函数已经同步了文件的数据块,而元数据块可能仍然在日志journal里,接下来的流程会找到一个合适的事物来进行日志的提交。
首先做一个判断,如果启用了文件系统的barrier特性,这里会调用jbd2_trans_will_send_data_barrier函数判断是否需要向块设备发送flush指令,需要注意的是commit_tid参数,如果是fdatasync调用,那它使用ei->i_datasync_tid,否则使用ei->i_sync_tid,用以表示包含我们关注文件元数据所在当前的事物id。
int jbd2_trans_will_send_data_barrier(journal_t *journal, tid_t tid)
{
int ret = 0;
transaction_t *commit_trans;
if (!(journal->j_flags & JBD2_BARRIER))
return 0;
read_lock(&journal->j_state_lock);
/* Transaction already committed? */
if (tid_geq(journal->j_commit_sequence, tid))
goto out;
commit_trans = journal->j_committing_transaction;
if (!commit_trans || commit_trans->t_tid != tid) {
ret = 1;
goto out;
}
/*
* Transaction is being committed and we already proceeded to
* submitting a flush to fs partition?
*/
if (journal->j_fs_dev != journal->j_dev) {
if (!commit_trans->t_need_data_flush ||
commit_trans->t_state >= T_COMMIT_DFLUSH)
goto out;
} else {
if (commit_trans->t_state >= T_COMMIT_JFLUSH)
goto out;
}
ret = 1;
out:
read_unlock(&journal->j_state_lock);
return ret;
}
jbd2_trans_will_send_data_barrier函数会对当前日志的状态进行一系列判断,返回1表示当前的transaction还没有被提交,所以不发送flush指令,返回0表示当前的事物可能已经被提交了,因此需要发送flush。具体如下:
(1)文件系统日志模式不支持barrier,这里返回0会触发flush(这一点不是很理解,判断同ext4_sync_file刚好矛盾);
(2)当前的事物id号和journal->j_commit_sequence进行比较,如果j_commit_sequence大于该id号表示这里关注的事物已经被提交了,返回0;
(3)如果正在提交的事物不存在或者正在体骄傲的事物不是所当前的事物,表示当前的事物被日志提交进程所处理,返回1;
(4)如果当前的事物正在提交中且提交已经进行到T_COMMIT_JFLUSH,表明元数据日志已经写回完毕了,返回0;
(5)最后如果当前的事物正在提交中但是还没有将元数据日志写回,返回1。
回到ext4_sync_file函数中,接下来jbd2_complete_transaction函数执行日志的提交工作:
int jbd2_complete_transaction(journal_t *journal, tid_t tid)
{
int need_to_wait = 1;
read_lock(&journal->j_state_lock);
if (journal->j_running_transaction &&
journal->j_running_transaction->t_tid == tid) {
if (journal->j_commit_request != tid) {
/* transaction not yet started, so request it */
read_unlock(&journal->j_state_lock);
jbd2_log_start_commit(journal, tid);
goto wait_commit;
}
} else if (!(journal->j_committing_transaction &&
journal->j_committing_transaction->t_tid == tid))
need_to_wait = 0;
read_unlock(&journal->j_state_lock);
if (!need_to_wait)
return 0;
wait_commit:
return jbd2_log_wait_commit(journal, tid);
}
首先如果当前正在运行的日志事物(尚有日志原子操作handle正在进行或者日志提交进程还没触发提交动作)且正是当前的事物,那么立即调用jbd2_log_start_commit函数唤醒日志回写进程回写待提交的元数据,然后调用jbd2_log_wait_commit函数等待元数据日志回写完毕(注意:并不保证元数据自身回写完毕,但是由于日志回写完毕后即使此刻系统崩溃,文件的元数据也能够得到恢复,因此文中其他地方不再对此详细区分),这也是正常情况下一般的流程;但是如果当前的事物已经在回写中了,那只需要等待即可;最后如果是没有正在提交的事物或提交的事物不为等待的事物id,表示事物已经写回了,所以直接退出即可。
回到ext4_sync_file函数中,最后根据前面的判断结果,如果需要下发flush指令,则调用blkdev_issue_flush函数向块设备下发flush命令,该命令最终会向物理磁盘发送一条flush cache的SCSI指令,磁盘会回刷磁盘写cache,这样数据才会真正的落盘,真正的安全了。(此处有一个疑问,为什么是否需要下发flush的判断会放在jbd2_complete_transaction之前,在jbd2_complete_transaction之后判断岂不是更好?因为jbd2_complete_transaction之后是能够保证当前的事物提交完毕,所以只需要判断journal是否支持barrier就可以了。现在这样处理岂不是会漏掉前文中的3和5两种情况不下发flush指令?)
最后我们回头看一下对commit_tid参数赋值的ei->i_datasync_tid和ei->i_sync_tid值从何而来,这也是fsync和fdatasync是否会回写元数据的关键。
其实这两个值会在ext4_mark_iloc_dirty->ext4_do_update_inode->ext4_update_inode_fsync_trans的调用流程里设置和修改
static int ext4_do_update_inode(handle_t *handle,
struct inode *inode,
struct ext4_iloc *iloc)
{
...
if (ei->i_disksize != ext4_isize(raw_inode)) {
ext4_isize_set(raw_inode, ei->i_disksize);
need_datasync = 1;
}
...
ext4_update_inode_fsync_trans(handle, inode, need_datasync);
...
}
static inline void ext4_update_inode_fsync_trans(handle_t *handle,
struct inode *inode,
int datasync)
{
struct ext4_inode_info *ei = EXT4_I(inode);
if (ext4_handle_valid(handle)) {
ei->i_sync_tid = handle->h_transaction->t_tid;
if (datasync)
ei->i_datasync_tid = handle->h_transaction->t_tid;
}
}
由此调用关系可以看出只有在inode元数据变脏时才会更新i_sync_tid值,才会使得前文中ext4_sync_file最后的触发日志事物的提交和元数据的回写,如果元数据在调用fsync时不为脏,那也就不需要执行元数据回写操作了(后面可以看到不会触发日志回写)。另外,如果元数据变为脏时,它的大小也改变了,那么它还会跟新i_datasync_tid值,以至于fdatasync调用会触发元数据的回写,这一点同本文概述中描述的一致。
简单总结一下:在执行fsync和fdatasync调用时,若元数据不为脏则不会回写元数据;若元数据为脏但是size值不变,则fdatasync不会回写元数据,而fsync会回写;最后若元数据为脏且size值变化则fdatasync和fsync都会回写元数据。
至此,fsync和fdatasync的调用流程执行结束。
3、总结
fsync和fdatasync系统调用用于实现对某一特定文件数据和元数据的dirty page cache的同步功能,将data写回磁盘,对于减少重要数据丢失有着重要的意义。本文描述了fsync和fdatasync的作用和区别,同时结合Ext4文件系统分析它们在Linux内核中的实现,但由于涉及较多模块较多,整个逻辑也较为复杂,所以仍有许多待分析和考虑的地方。

