
linux那些事之页迁移(page migratiom)
Page migration
页迁移技术是内核中内存管理的一种比较重要的技术,最早该技术诞生于NUMA系统中(Page migration [LWN.net]),后续由于内存规整以及CMA和COW技术的出现,也需要用到页迁移技术,逐渐称为内核内存子系统中占有比较重要地位。
页迁移在NUMA系统中的应用
NUMA系统中,每个cpu运行的进程申请内存时尽量从该cpu本地节点中内存中(local memory)速度,这样才能够获得最佳内存访问性能,但是由于内核进程调度系统,当进程数量过多时,调度系统会将进程从一个cpu调度到另外一个cpu中,切换之后就会造成在旧cpu节点上申请的内存称为远程内存(remote memory),访问内存时就会造成跨节点访问,性能较差:
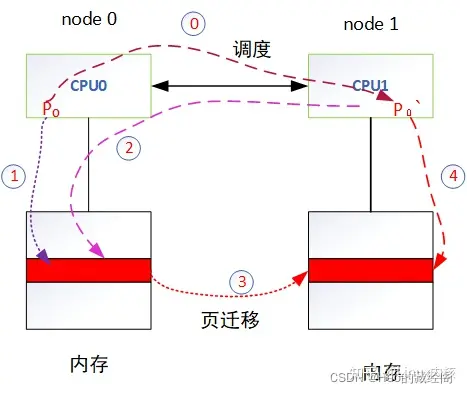
如上图一个NUMA 系统说明:
- CPU0和CPU1为分别分布到node0 和node1两个节点。
- CPU0和CPU1都有各种本地节点local memory内存,各自访问local memory速度最快。
- CPU0和CPU1之间一般在一个NUMA系统中都拥有高速互联技术,将两个节点cpu互联,两者之前可以相互访问。
- CPU0的local memory相对于CPU1来说为CPU1 的remote memory远程内存。
- CPU0和CPU1都可以通过高速互联技术访问remote memory。比如CPU0 访问CPU1的local memory需要通过高速互联通道。
- 针对NUMA系统,访问remote memory速度要比访问remote memory内存慢得多,因为中间需要通过remote memory。
如有一个P0线程,开始是运行在cpu0节点上,后续由于调度系统发生迁移到CPU1上,为提高性能就会发生页迁移动作
- 刚开始时进程P0运行在node 0节点中,此时根据就近原则,申请的内存都位于node 0的local memory。
- 由于内核调度原因,进程P0被调度到CPU1上运行,此时P0访问内存需要通过高速互联通道,才能放问到之前在CPU0上申请的内存,效率变低。
- 由于P0被切换到CPU1上运行不在本节点上,会触发NUMA balance 从而发生页迁移,将CPU0上的属于P0的内存迁移到CPU1的本地节点上。
- 迁移之后,CPU1的P0不再访问远程节点内存,而是访问到本地节点内存。
一般在NUMA系统中由于进程调度造成 正在运行的进程切换节点,由于访问远程节点开销,在NUMA系统中经常会出现一个性能抖动,通过页迁移技术之后,性能又得到恢复,因此在NUMA系统中要尽量避免进程在节点之前进行切换。
页迁移在内存规整中应用
内存规整技术是Mel Gormal开发的解决内存碎片化技术的第二个部分:
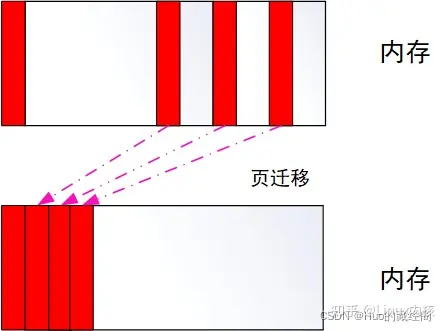
系统在经长期运行之后,会产生比较严重的碎片化,内核采用各种技术对内存碎片化进行优化,启动内存规整技术就是一个比较重要的技术。通过内存规整技术,将不连续的分散使用的物理内存通过页迁移技术将其集合在一起,以便腾出连续空闲物理内存,给大片内存使用。
内核还提供了一种手动启动内存规整方法:
echo 1 >/proc/sys/vm/compact_memory
页迁移在CMA中应用
CMA为解决DMA申请连续物理内存必须做预留造成内存浪费问题,专门划分出一块区域给CMA使用:
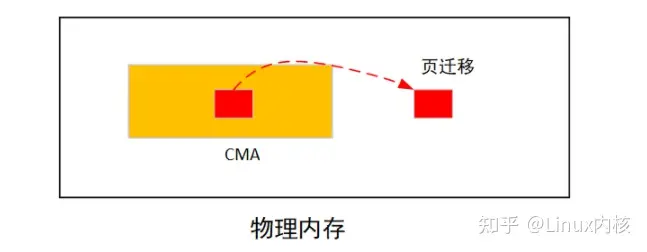
当位于CMA are中的内存被MOVE类型申请占有之后,如果调用dma_alloc_contiguous申请连续物理内存之后,发现cma are内内存被占有,会启动页迁移功能将将move类型内存迁移到are之外,以腾出连续可用物理内存。
以上是三个比较经常使用到的page migrate 场景,当然还有其他场景也会使用到例如cow、透明巨页等场景。
migrate_pages 系统调用
页迁移不仅仅是内核自动触发进行迁移,还提供了系统调用,供用户层进行根据情况使用:
#include <numaif.h>
long migrate_pages(int pid, unsigned long maxnode,
const unsigned long *old_nodes,
const unsigned long *new_nodes);
系统调用是尝试将指定old_nodes节点上属于进程pid的所有物理页迁移到new_nodes新节点上。
入参:
- int pid:所要迁移的进程id。
- unsigned long maxnode:在mask中最大节点 number。
- const unsigned long *old_nodes:采用bit 位方式,表示旧节点。
- const unsigned long *new_nodes:新节点,同意采用bit mask形式。
特别需要说明的是 使用该系统调用需要链接numa库-lnuma。
整个页迁移组成大概如下:
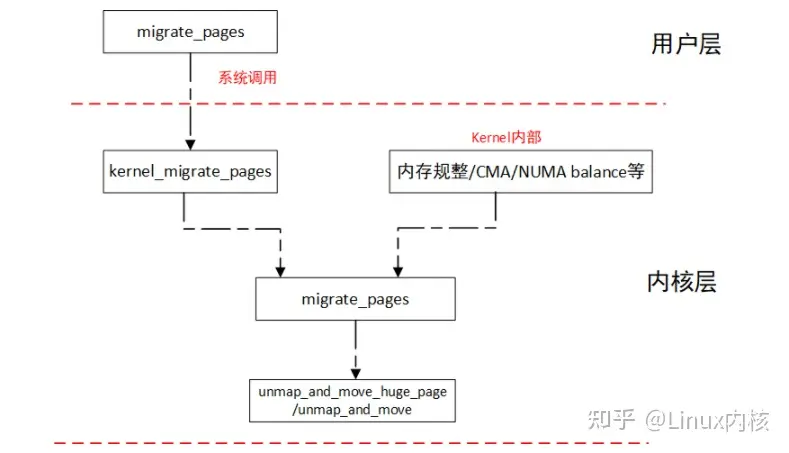
系统调用migrate_pages通过中断陷入内核中调用kernel_migrate_pages,最终调用内核函数migrate_pages实施页迁移。
内核migrate_pages函数如果是huge pge则调用unmap_move_huge_page将旧的huge page 对应所有进程pte 接触,然后申请新的huge page 并将old huge page内存copy到new page中,最后并刷新映射。
如果是normal page则调用unmap_and_move处理类似同样 接触旧page所有进程映射,申请新page 并同步page内存以及迁移页表。
触发页迁移主要函数梳理
以下是整理会触发page migration主要一些情况:
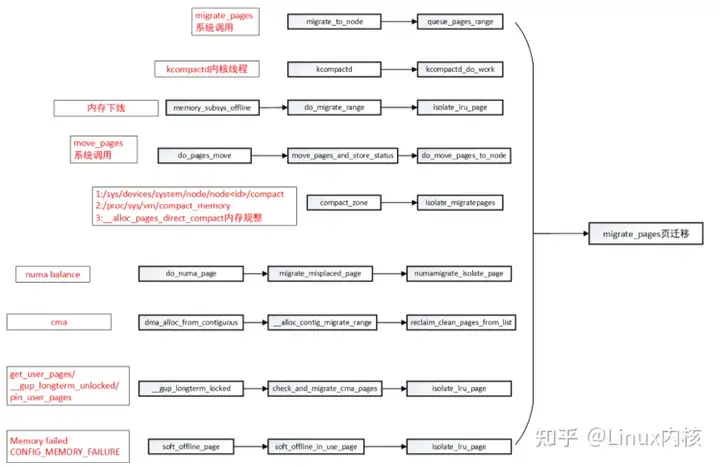
-
可以看到所有触发页迁移之后,都需要将要迁移的page 都isolate出去,防止触发swap等并发分配或者是否要迁移page 场景。
-
migrate_pages系统调用可以由用户根据情况进行页迁移
-
kcompact内核线程:每个内存节点都会创建一个kcompactd内核线程,名称为kcompactd
,每个节点都由一个kcompactd线程用于内存规整 -
内存热插拔:内存下线时,需要将该内存迁移到另外一个节点 防止数据丢失。
-
move_pages:为另外一个系统调用,用于将指定进程的页面迁移到新节点。
-
系统长时间运行之后,可以通过sys和proc进行手动规整:
- /proc/sys/vm/compact_memory:用于对当前系统所有进程的内存进行规整
- sys/devices/system/node/node
/compact: 用于手动指定单个节点进行内存规整。
-
当系统物理内存处于较低min watermark时,会通过__alloc_pages_direct_compact直接触发内存规整。
-
当进程在numa节点中发生迁移,会触发numa balance,将物理内存迁移到对应节点中。
-
当cma are中内存被move 类型内存占有,进行cma申请连续物理内存是会触发物理页迁移。
-
get_user_pages类似函数申请内存是,对cma are进行检查有可能会触发物理页迁移。
-
当内核配置CONFIG_MEMORY_FAILURE,内存处理过程中如果出现memory failed会进行页迁移
migrate_pages
函数定义说明
内核migrate_pages函数为实施页迁移函数入口,函数定义如下:
int migrate_pages(struct list_head *from, new_page_t get_new_page,
free_page_t put_new_page, unsigned long private,
enum migrate_mode mode, int reason)
参数:
- struct list_head *from:所要迁移的物理page(使用page->lru双向链表,故传递给的page都被isolate出来,既不属于buddy也不属于lru,可以防止其他进程在迁移过程中对该page进行swap out或者规整动作或者释放)。
- new_page_t get_new_page:申请新page 钩子函数。
- free_page_t put_new_page:释放page钩子函数。
- unsigned long private:私有数据
- enum migrate_mode mode:迁移模式
- int reason:迁移原因。
migrate_mode
migrate_mode迁移模式主要有以下几个:
- MIGRATE_ASYNC //异步迁移,过程中不会发生阻塞。
- MIGRATE_SYNC_LIGHT //轻度同步迁移,允许大部分的阻塞操作,唯独不允许脏页的回写操作。
- MIGRATE_SYNC //同步迁移,迁移过程会发生阻塞,若需要迁移的某个page正在writeback或被locked会等待它完成
- MIGRATE_SYNC_NO_COPY //同步迁移,但不等待页面的拷贝过程。页面的拷贝通过回调migratepage(),过程可能会涉及DMA
migrate reason
用于说明迁移原因:
- MR_COMPACTION //内存规整导致的迁移
- MR_MEMORY_FAILURE //当内存出现硬件问题(ECC校验失败等)时触发的页面迁移。 参考memory-failure.c
- MR_MEMORY_HOTPLUG //内存热插拔导致的迁移
- MR_SYSCALL //应用层主动调用migrate_pages()或move_pages()触发的迁移。
- MR_MEMPOLICY_MBIND //调用mbind系统调用设置memory policy时触发的迁移
- MR_NUMA_MISPLACED //numa balance触发的页面迁移(node之间)
- MR_CONTIG_RANGE //调用alloc_contig_range()为CMA或HugeTLB分配连续内存时触发的迁移(和compact相关)。
内核migrate_pages处理相对来说比较复杂,内核文档(Page migration — The Linux Kernel documentation)中给出了 迁移过程说明:

migrate_pages分析
该上述过程分散穿插到代码过程中,migrate_pages(mm\migrate.c文件中):
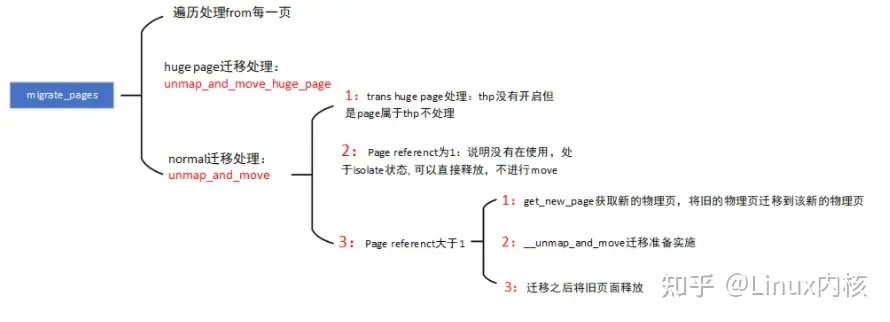
- migrate_pages:遍历from中的每一个page进程处理(特别需要注意的是该page都为isolate,不属于任何LRU)。
- page 如果是huge page则调用unmap_and_move_huge_page进行去映射和物理页迁移。
- page如果是normal page则调用unmap_and_move,进行去映射和物理页迁移,两者处理思路一样,就以unmap_and_move为准进行说明。
- thp如果没有开启,但是该page属于trans huge page,不进行任何处理及不进行迁移。
- page reference 为1时,说明该物理页已经没有进程在使用,可以直接是否(等于1是因为isolate page占有一个计数)。
- page reference大于1时,需要进行物理页迁移,迁移过程主要由三个步骤:
- 调用get_new_page申请新的page,为迁移做准备。
- 调用__unmap_and_move,准备将旧的page 迁移到新page中,并且将旧page中的所有反向映射中的进程对应pte都进行刷新migrate type,防止在迁移过程中有进程在继续访问旧page.,page迁移完成之后,再通过反向映射将pte都刷新成新的page
- page迁移完成之后,将旧page 释放掉,如果计数为0,则释放到buddy中。
__unmap_and_move
__unmap_and_move为实施页迁移具体函数,整个处理过程思路如下:
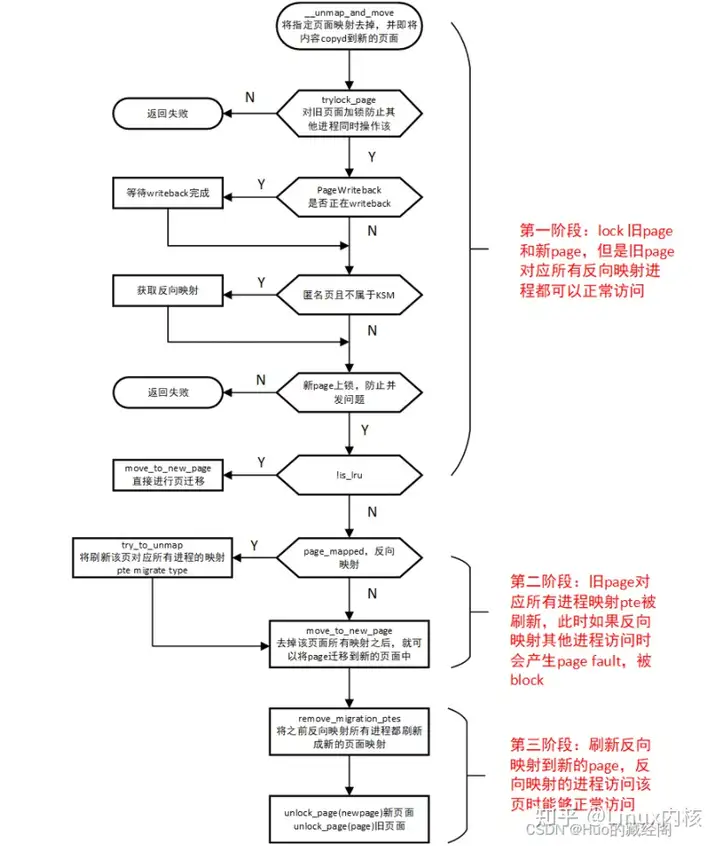
比较几个关键处理:
- 第一阶段:trylock_page对old page和new page都上锁,防止有其他进程在操作该页,此时旧page还是可以正常访问。
- 第二阶段:move_to_new_page:进行页 迁移,此时先将旧page中对应所有进程pte都刷新成migrate type,这样有其他进程访问该旧
- 第三阶段:remove_migration_ptes:进行页表迁移,通过反向映射将pte都刷新成对应新page,后续访问通过page table转换就可以访问到新page.
最后将旧page和新page 都解锁unlock_page。
__unmap_and_move代码如下:
static int __unmap_and_move(struct page *page, struct page *newpage,
int force, enum migrate_mode mode)
{
int rc = -EAGAIN;
int page_was_mapped = 0;
struct anon_vma *anon_vma = NULL;
bool is_lru = !__PageMovable(page);
if (!trylock_page(page)) {
if (!force || mode == MIGRATE_ASYNC)
goto out;
/*
* It's not safe for direct compaction to call lock_page.
* For example, during page readahead pages are added locked
* to the LRU. Later, when the IO completes the pages are
* marked uptodate and unlocked. However, the queueing
* could be merging multiple pages for one bio (e.g.
* mpage_readahead). If an allocation happens for the
* second or third page, the process can end up locking
* the same page twice and deadlocking. Rather than
* trying to be clever about what pages can be locked,
* avoid the use of lock_page for direct compaction
* altogether.
*/
if (current->flags & PF_MEMALLOC)
goto out;
lock_page(page);
}
if (PageWriteback(page)) {
/*
* Only in the case of a full synchronous migration is it
* necessary to wait for PageWriteback. In the async case,
* the retry loop is too short and in the sync-light case,
* the overhead of stalling is too much
*/
switch (mode) {
case MIGRATE_SYNC:
case MIGRATE_SYNC_NO_COPY:
break;
default:
rc = -EBUSY;
goto out_unlock;
}
if (!force)
goto out_unlock;
wait_on_page_writeback(page);
}
/*
* By try_to_unmap(), page->mapcount goes down to 0 here. In this case,
* we cannot notice that anon_vma is freed while we migrates a page.
* This get_anon_vma() delays freeing anon_vma pointer until the end
* of migration. File cache pages are no problem because of page_lock()
* File Caches may use write_page() or lock_page() in migration, then,
* just care Anon page here.
*
* Only page_get_anon_vma() understands the subtleties of
* getting a hold on an anon_vma from outside one of its mms.
* But if we cannot get anon_vma, then we won't need it anyway,
* because that implies that the anon page is no longer mapped
* (and cannot be remapped so long as we hold the page lock).
*/
if (PageAnon(page) && !PageKsm(page))
anon_vma = page_get_anon_vma(page);
/*
* Block others from accessing the new page when we get around to
* establishing additional references. We are usually the only one
* holding a reference to newpage at this point. We used to have a BUG
* here if trylock_page(newpage) fails, but would like to allow for
* cases where there might be a race with the previous use of newpage.
* This is much like races on refcount of oldpage: just don't BUG().
*/
if (unlikely(!trylock_page(newpage)))
goto out_unlock;
if (unlikely(!is_lru)) {
rc = move_to_new_page(newpage, page, mode);
goto out_unlock_both;
}
/*
* Corner case handling:
* 1. When a new swap-cache page is read into, it is added to the LRU
* and treated as swapcache but it has no rmap yet.
* Calling try_to_unmap() against a page->mapping==NULL page will
* trigger a BUG. So handle it here.
* 2. An orphaned page (see truncate_complete_page) might have
* fs-private metadata. The page can be picked up due to memory
* offlining. Everywhere else except page reclaim, the page is
* invisible to the vm, so the page can not be migrated. So try to
* free the metadata, so the page can be freed.
*/
if (!page->mapping) {
VM_BUG_ON_PAGE(PageAnon(page), page);
if (page_has_private(page)) {
try_to_free_buffers(page);
goto out_unlock_both;
}
} else if (page_mapped(page)) {
/* Establish migration ptes */
VM_BUG_ON_PAGE(PageAnon(page) && !PageKsm(page) && !anon_vma,
page);
try_to_unmap(page,
TTU_MIGRATION|TTU_IGNORE_MLOCK|TTU_IGNORE_ACCESS);
page_was_mapped = 1;
}
if (!page_mapped(page))
rc = move_to_new_page(newpage, page, mode);
if (page_was_mapped)
remove_migration_ptes(page,
rc == MIGRATEPAGE_SUCCESS ? newpage : page, false);
out_unlock_both:
unlock_page(newpage);
out_unlock:
/* Drop an anon_vma reference if we took one */
if (anon_vma)
put_anon_vma(anon_vma);
unlock_page(page);
out:
/*
* If migration is successful, decrease refcount of the newpage
* which will not free the page because new page owner increased
* refcounter. As well, if it is LRU page, add the page to LRU
* list in here. Use the old state of the isolated source page to
* determine if we migrated a LRU page. newpage was already unlocked
* and possibly modified by its owner - don't rely on the page
* state.
*/
if (rc == MIGRATEPAGE_SUCCESS) {
if (unlikely(!is_lru))
put_page(newpage);
else
putback_lru_page(newpage);
}
return rc;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号