
Linux内核调试技术——kprobe使用与实现
Linux kprobes调试技术是内核开发者们专门为了便于跟踪内核函数执行状态所设计的一种轻量级内核调试技术。利用kprobes技术,内核开发人员可以在内核的绝大多数指定函数中动态的插入探测点来收集所需的调试状态信息而基本不影响内核原有的执行流程。kprobes技术目前提供了3种探测手段:kprobe、jprobe和kretprobe,其中jprobe和kretprobe是基于kprobe实现的,他们分别应用于不同的探测场景中。本文首先简单描述这3种探测技术的原理与区别,然后主要围绕其中的kprobe技术进行分析并给出一个简单的实例介绍如何利用kprobe进行内核函数探测,最后分析kprobe的实现过程(jprobe和kretprobe会在后续的博文中进行分析)。
内核源码:Linux-4.1.15
实验环境:CentOS(x86_64)、树莓派1b
一、kprobes技术背景
开发人员在内核或者模块的调试过程中,往往会需要要知道其中的一些函数有无被调用、何时被调用、执行是否正确以及函数的入参和返回值是什么等等。比较简单的做法是在内核代码对应的函数中添加日志打印信息,但这种方式往往需要重新编译内核或模块,重新启动设备之类的,操作较为复杂甚至可能会破坏原有的代码执行过程。
而利用kprobes技术,用户可以定义自己的回调函数,然后在内核或者模块中几乎所有的函数中(有些函数是不可探测的,例如kprobes自身的相关实现函数,后文会有详细说明)动态的插入探测点,当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息了,同时内核最后还会回到原本的正常执行流程。如果用户已经收集足够的信息,不再需要继续探测,则同样可以动态的移除探测点。因此kprobes技术具有对内核执行流程影响小和操作方便的优点。
kprobes技术包括的3种探测手段分别时kprobe、jprobe和kretprobe。首先kprobe是最基本的探测方式,是实现后两种的基础,它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以),它提供了探测点的调用前、调用后和内存访问出错3种回调方式,分别是pre_handler、post_handler和fault_handler,其中pre_handler函数将在被探测指令被执行前回调,post_handler会在被探测指令执行完毕后回调(注意不是被探测函数),fault_handler会在内存访问出错时被调用;jprobe基于kprobe实现,它用于获取被探测函数的入参值;最后kretprobe从名字种就可以看出其用途了,它同样基于kprobe实现,用于获取被探测函数的返回值。
kprobes的技术原理并不仅仅包含存软件的实现方案,它也需要硬件架构提供支持。其中涉及硬件架构相关的是CPU的异常处理和单步调试技术,前者用于让程序的执行流程陷入到用户注册的回调函数中去,而后者则用于单步执行被探测点指令,因此并不是所有的架构均支持,目前kprobes技术已经支持多种架构,包括i386、x86_64、ppc64、ia64、sparc64、arm、ppc和mips(有些架构实现可能并不完全,具体可参考内核的Documentation/kprobes.txt)。
kprobes的特点与使用限制:
1、kprobes允许在同一个被被探测位置注册多个kprobe,但是目前jprobe却不可以;同时也不允许以其他的jprobe回掉函数和kprobe的post_handler回调函数作为被探测点。
2、一般情况下,可以探测内核中的任何函数,包括中断处理函数。不过在kernel/kprobes.c和arch/*/kernel/kprobes.c程序中用于实现kprobes自身的函数是不允许被探测的,另外还有do_page_fault和notifier_call_chain;
3、如果以一个内联函数为探测点,则kprobes可能无法保证对该函数的所有实例都注册探测点。由于gcc可能会自动将某些函数优化为内联函数,因此可能无法达到用户预期的探测效果;
4、一个探测点的回调函数可能会修改被探测函数运行的上下文,例如通过修改内核的数据结构或者保存与struct pt_regs结构体中的触发探测之前寄存器信息。因此kprobes可以被用来安装bug修复代码或者注入故障测试代码;
5、kprobes会避免在处理探测点函数时再次调用另一个探测点的回调函数,例如在printk()函数上注册了探测点,则在它的回调函数中可能再次调用printk函数,此时将不再触发printk探测点的回调,仅仅时增加了kprobe结构体中nmissed字段的数值;
6、在kprobes的注册和注销过程中不会使用mutex锁和动态的申请内存;
7、kprobes回调函数的运行期间是关闭内核抢占的,同时也可能在关闭中断的情况下执行,具体要视CPU架构而定。因此不论在何种情况下,在回调函数中不要调用会放弃CPU的函数(如信号量、mutex锁等);
8、kretprobe通过替换返回地址为预定义的trampoline的地址来实现,因此栈回溯和gcc内嵌函数__builtin_return_address()调用将返回trampoline的地址而不是真正的被探测函数的返回地址;
9、如果一个函数的调用此处和返回次数不相等,则在类似这样的函数上注册kretprobe将可能不会达到预期的效果,例如do_exit()函数会存在问题,而do_execve()函数和do_fork()函数不会;
10、如果当在进入和退出一个函数时,CPU运行在非当前任务所有的栈上,那么往该函数上注册kretprobe可能会导致不可预料的后果,因此,kprobes不支持在X86_64的结构下为__switch_to()函数注册kretprobe,将直接返回-EINVAL。
二、kprobe原理
下面来介绍一下kprobe是如何工作的。具体流程见下图:
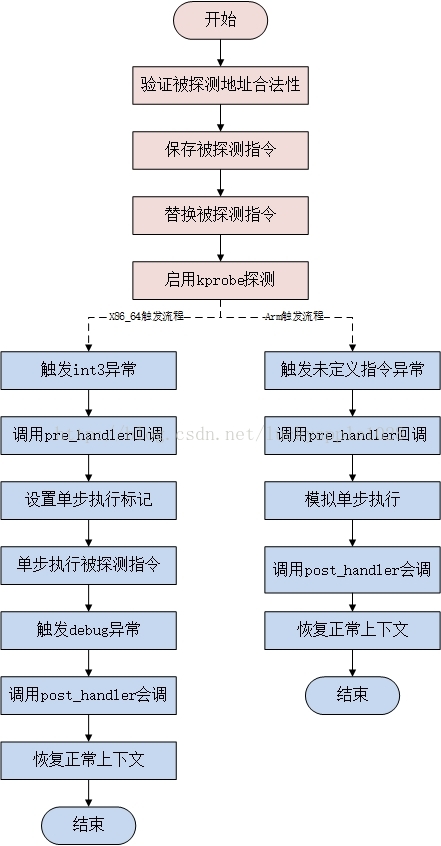
1、当用户注册一个探测点后,kprobe首先备份被探测点的对应指令,然后将原始指令的入口点替换为断点指令,该指令是CPU架构相关的,如i386和x86_64是int3,arm是设置一个未定义指令(目前的x86_64架构支持一种跳转优化方案Jump Optimization,内核需开启CONFIG_OPTPROBES选项,该种方案使用跳转指令来代替断点指令);
2、当CPU流程执行到探测点的断点指令时,就触发了一个trap,在trap处理流程中会保存当前CPU的寄存器信息并调用对应的trap处理函数,该处理函数会设置kprobe的调用状态并调用用户注册的pre_handler回调函数,kprobe会向该函数传递注册的struct kprobe结构地址以及保存的CPU寄存器信息;
3、随后kprobe单步执行前面所拷贝的被探测指令,具体执行方式各个架构不尽相同,arm会在异常处理流程中使用模拟函数执行,而x86_64架构则会设置单步调试flag并回到异常触发前的流程中执行;
4、在单步执行完成后,kprobe执行用户注册的post_handler回调函数;
5、最后,执行流程回到被探测指令之后的正常流程继续执行。
三、kprobe使用实例
在分析kprobe的实现之前先来看一下如何利用kprobe对函数进行探测,以便于让我们对kprobre所完成功能有一个比较清晰的认识。目前,使用kprobe可以通过两种方式,第一种是开发人员自行编写内核模块,向内核注册探测点,探测函数可根据需要自行定制,使用灵活方便;第二种方式是使用kprobes on ftrace,这种方式是kprobe和ftrace结合使用,即可以通过kprobe来优化ftrace来跟踪函数的调用。下面来分别介绍:
1、编写kprobe探测模块
内核提供了一个struct kprobe结构体以及一系列的内核API函数接口,用户可以通过这些接口自行实现探测回调函数并实现struct kprobe结构,然后将它注册到内核的kprobes子系统中来达到探测的目的。同时在内核的samples/kprobes目录下有一个例程kprobe_example.c描述了kprobe模块最简单的编写方式,开发者可以以此为模板编写自己的探测模块。
1.1、kprobe结构体与API介绍
struct kprobe结构体定义如下:
struct kprobe {
struct hlist_node hlist;
/* list of kprobes for multi-handler support */
struct list_head list;
/*count the number of times this probe was temporarily disarmed */
unsigned long nmissed;
/* location of the probe point */
kprobe_opcode_t *addr;
/* Allow user to indicate symbol name of the probe point */
const char *symbol_name;
/* Offset into the symbol */
unsigned int offset;
/* Called before addr is executed. */
kprobe_pre_handler_t pre_handler;
/* Called after addr is executed, unless... */
kprobe_post_handler_t post_handler;
/*
* ... called if executing addr causes a fault (eg. page fault).
* Return 1 if it handled fault, otherwise kernel will see it.
*/
kprobe_fault_handler_t fault_handler;
/*
* ... called if breakpoint trap occurs in probe handler.
* Return 1 if it handled break, otherwise kernel will see it.
*/
kprobe_break_handler_t break_handler;
/* Saved opcode (which has been replaced with breakpoint) */
kprobe_opcode_t opcode;
/* copy of the original instruction */
struct arch_specific_insn ainsn;
/*
* Indicates various status flags.
* Protected by kprobe_mutex after this kprobe is registered.
*/
u32 flags;
};
其中各个字段的含义如下:
struct hlist_node hlist:被用于kprobe全局hash,索引值为被探测点的地址;
struct list_head list:用于链接同一被探测点的不同探测kprobe;
kprobe_opcode_t *addr:被探测点的地址;
const char *symbol_name:被探测函数的名字;
unsigned int offset:被探测点在函数内部的偏移,用于探测函数内部的指令,如果该值为0表示函数的入口;
kprobe_pre_handler_t pre_handler:在被探测点指令执行之前调用的回调函数;
kprobe_post_handler_t post_handler:在被探测指令执行之后调用的回调函数;
kprobe_fault_handler_t fault_handler:在执行pre_handler、post_handler或单步执行被探测指令时出现内存异常则会调用该回调函数;
kprobe_break_handler_t break_handler:在执行某一kprobe过程中触发了断点指令后会调用该函数,用于实现jprobe;
kprobe_opcode_t opcode:保存的被探测点原始指令;
struct arch_specific_insn ainsn:被复制的被探测点的原始指令,用于单步执行,架构强相关(可能包含指令模拟函数);
u32 flags:状态标记。
涉及的API函数接口如下:
int register_kprobe(struct kprobe *kp) //向内核注册kprobe探测点
void unregister_kprobe(struct kprobe *kp) //卸载kprobe探测点
int register_kprobes(struct kprobe **kps, int num) //注册探测函数向量,包含多个探测点
void unregister_kprobes(struct kprobe **kps, int num) //卸载探测函数向量,包含多个探测点
int disable_kprobe(struct kprobe *kp) //临时暂停指定探测点的探测
int enable_kprobe(struct kprobe *kp) //恢复指定探测点的探测
1.2、用例kprobe_example.c分析与演示
该用例函数非常简单,它实现了内核函数do_fork的探测,该函数会在fork系统调用或者内核kernel_thread函数创建进程时被调用,触发也十分的频繁。下面来分析一下用例代码:
/* For each probe you need to allocate a kprobe structure */
static struct kprobe kp = {
.symbol_name = "do_fork",
};
static int __init kprobe_init(void)
{
int ret;
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
kp.fault_handler = handler_fault;
ret = register_kprobe(&kp);
if (ret < 0) {
printk(KERN_INFO "register_kprobe failed, returned %d\n", ret);
return ret;
}
printk(KERN_INFO "Planted kprobe at %p\n", kp.addr);
return 0;
}
static void __exit kprobe_exit(void)
{
unregister_kprobe(&kp);
printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr);
}
module_init(kprobe_init)
module_exit(kprobe_exit)
MODULE_LICENSE("GPL");
程序中定义了一个struct kprobe结构实例kp并初始化其中的symbol_name字段为“do_fork”,表明它将要探测do_fork函数。在模块的初始化函数中,注册了pre_handler、post_handler和fault_handler这3个回调函数分别为handler_pre、handler_post和handler_fault,最后调用register_kprobe注册。在模块的卸载函数中调用unregister_kprobe函数卸载kp探测点。
static int handler_pre(struct kprobe *p, struct pt_regs *regs)
{
#ifdef CONFIG_X86
printk(KERN_INFO "pre_handler: p->addr = 0x%p, ip = %lx,"
" flags = 0x%lx\n",
p->addr, regs->ip, regs->flags);
#endif
#ifdef CONFIG_PPC
printk(KERN_INFO "pre_handler: p->addr = 0x%p, nip = 0x%lx,"
" msr = 0x%lx\n",
p->addr, regs->nip, regs->msr);
#endif
#ifdef CONFIG_MIPS
printk(KERN_INFO "pre_handler: p->addr = 0x%p, epc = 0x%lx,"
" status = 0x%lx\n",
p->addr, regs->cp0_epc, regs->cp0_status);
#endif
#ifdef CONFIG_TILEGX
printk(KERN_INFO "pre_handler: p->addr = 0x%p, pc = 0x%lx,"
" ex1 = 0x%lx\n",
p->addr, regs->pc, regs->ex1);
#endif
/* A dump_stack() here will give a stack backtrace */
return 0;
}
handler_pre回调函数的第一个入参是注册的struct kprobe探测实例,第二个参数是保存的触发断点前的寄存器状态,它在do_fork函数被调用之前被调用,该函数仅仅是打印了被探测点的地址,保存的个别寄存器参数。由于受CPU架构影响,这里对不同的架构进行了宏区分(虽然没有实现arm架构的,但是支持的,可以自行添加);
/* kprobe post_handler: called after the probed instruction is executed */
static void handler_post(struct kprobe *p, struct pt_regs *regs,
unsigned long flags)
{
#ifdef CONFIG_X86
printk(KERN_INFO "post_handler: p->addr = 0x%p, flags = 0x%lx\n",
p->addr, regs->flags);
#endif
#ifdef CONFIG_PPC
printk(KERN_INFO "post_handler: p->addr = 0x%p, msr = 0x%lx\n",
p->addr, regs->msr);
#endif
#ifdef CONFIG_MIPS
printk(KERN_INFO "post_handler: p->addr = 0x%p, status = 0x%lx\n",
p->addr, regs->cp0_status);
#endif
#ifdef CONFIG_TILEGX
printk(KERN_INFO "post_handler: p->addr = 0x%p, ex1 = 0x%lx\n",
p->addr, regs->ex1);
#endif
}
handler_post回调函数的前两个入参同handler_pre,第三个参数目前尚未使用,全部为0;该函数在do_fork函数调用之后被调用,这里打印的内容同handler_pre类似。
/*
* fault_handler: this is called if an exception is generated for any
* instruction within the pre- or post-handler, or when Kprobes
* single-steps the probed instruction.
*/
static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr)
{
printk(KERN_INFO "fault_handler: p->addr = 0x%p, trap #%dn",
p->addr, trapnr);
/* Return 0 because we don't handle the fault. */
return 0;
}
handler_fault回调函数会在执行handler_pre、handler_post或单步执行do_fork时出现错误时调用,这里第三个参数时具体发生错误的trap number,与架构相关,例如i386的page fault为14。
下面将它编译成模块在我的x86(CentOS 3.10)环境下进行演示,首先确保架构和内核已经支持kprobes,开启以下选项(一般都是默认开启的):
Symbol: KPROBES [=y]
Type : boolean
Prompt: Kprobes
Location:
(3) -> General setup
Defined at arch/Kconfig:37
Depends on: MODULES [=y] && HAVE_KPROBES [=y]
Selects: KALLSYMS [=y]
Symbol: HAVE_KPROBES [=y]
Type : boolean
Defined at arch/Kconfig:174
Selected by: X86 [=y]
然后使用以下Makefile单独编译kprobe_example.ko模块:
obj-m := kprobe_example.o
CROSS_COMPILE=''
KDIR := /lib/modules/$(shell uname -r)/build
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm -f *.ko *.o *.mod.o *.mod.c .*.cmd *.symvers modul*
加载到内核中后,随便在终端上敲一个命令,可以看到dmesg中打印如下信息:
<6>pre_handler: p->addr = 0xc0439cc0, ip = c0439cc1, flags = 0x246
<6>post_handler: p->addr = 0xc0439cc0, flags = 0x246
<6>pre_handler: p->addr = 0xc0439cc0, ip = c0439cc1, flags = 0x246
<6>post_handler: p->addr = 0xc0439cc0, flags = 0x246
<6>pre_handler: p->addr = 0xc0439cc0, ip = c0439cc1, flags = 0x246
<6>post_handler: p->addr = 0xc0439cc0, flags = 0x246
可以看到被探测点的地址为0xc0439cc0,用以下命令确定这个地址就是do_fork的入口地址。
[root@apple kprobes]# cat /proc/kallsyms | grep do_fork
c0439cc0 T do_fork
2、使用kprobe on ftrace来跟踪函数和调用栈
这种方式用户通过/sys/kernel/debug/tracing/目录下的trace等属性文件来探测用户指定的函数,用户可添加kprobe支持的任意函数并设置探测格式与过滤条件,无需再编写内核模块,使用更为简便,但需要内核的debugfs和ftrace功能的支持。
首先,在使用前需要保证开启以下内核选项:
Symbol: FTRACE [=y]
Type : boolean
Prompt: Tracers
Location:
(5) -> Kernel hacking
Defined at kernel/trace/Kconfig:132
Depends on: TRACING_SUPPORT [=y]
Symbol: KPROBE_EVENT [=y]
Type : boolean
Prompt: Enable kprobes-based dynamic events
Location:
-> Kernel hacking
(1) -> Tracers (FTRACE [=y])
Defined at kernel/trace/Kconfig:405
Depends on: TRACING_SUPPORT [=y] && FTRACE [=y] && KPROBES [=y] && HAVE_REGS_AND_STACK_ACCESS_API [=y]
Selects: TRACING [=y] && PROBE_EVENTS [=y]
Symbol: HAVE_KPROBES_ON_FTRACE [=y]
Type : boolean
Defined at arch/Kconfig:183
Selected by: X86 [=y]
Symbol: KPROBES_ON_FTRACE [=y]
Type : boolean
Defined at arch/Kconfig:79
Depends on: KPROBES [=y] && HAVE_KPROBES_ON_FTRACE [=y] && DYNAMIC_FTRACE_WITH_REGS [=y]
然后需要将debugfs文件系统挂在到/sys/kernel/debug/目录下:
# mount -t debugfs nodev /sys/kernel/debug/
此时/sys/kernel/debug/tracing目录下就出现了若干个文件和目录用于用户设置要跟踪的函数以及过滤条件等等,这里我主要关注以下几个文件:
1、配置属性文件:kprobe_events
2、查询属性文件:trace和trace_pipe
3、使能属性文件:events/kprobes/
4、过滤属性文件:events/kprobes/
5、格式查询属性文件:events/kprobes/
6、事件统计属性文件:kprobe_profile
其中配置属性文件用于用户配置要探测的函数以及探测的方式与参数,在配置完成后,会在events/kprobes/目录下生成对应的目录;其中会生成enabled、format、filter和id这4个文件,其中的enable属性文件用于控制探测的开启或关闭,filter用于设置过滤条件,format可以查看当前的输出格式,最后id可以查看当前probe event的ID号。然后若被探测函数被执行流程触发调用,用户可以通过trace属性文件进行查看。最后通过kprobe_profile属性文件可以查看探测命中次数和丢失次数(probe hits and probe miss-hits)。
下面来看看各个属性文件的常用操作方式(其中具体格式和参数方面的细节可以查看内核的Documentation/trace/kprobetrace.txt文件,描述非常详细):
1、kprobe_events
该属性文件支持3中格式的输入:
p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS]——设置一个probe探测点
r[:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] ——设置一个return probe探测点
-:[GRP/]EVENT ——删除一个探测点
各个字段的含义如下:
GRP : Group name. If omitted, use "kprobes" for it. ——指定后会在events/kprobes目录下生成对应名字的目录,一般不设
EVENT : Event name. If omitted, the event name is generated based on SYM+offs or MEMADDR. ——指定后会在events/kprobes/
MOD : Module name which has given SYM. ——模块名,一般不设
SYM[+offs] : Symbol+offset where the probe is inserted. ——指定被探测函数和偏移
MEMADDR : Address where the probe is inserted. ——指定被探测的内存绝对地址
FETCHARGS : Arguments. Each probe can have up to 128 args. ——指定要获取的参数信息
%REG : Fetch register REG ——获取指定寄存器值
@ADDR : Fetch memory at ADDR (ADDR should be in kernel) ——获取指定内存地址的值
@SYM[+|-offs] : Fetch memory at SYM +|- offs (SYM should be a data symbol) ——获取全局变量的值
$stackN : Fetch Nth entry of stack (N >= 0) ——获取指定栈空间值,即sp寄存器+N后的位置值
$stack : Fetch stack address. ——获取sp寄存器值
$retval : Fetch return value.(*) ——获取返回值,仅用于return probe
+|-offs(FETCHARG) : Fetch memory at FETCHARG +|- offs address.(**) ——以下可以由于获取指定地址的结构体参数内容,可以设定具体的参数名和偏移地址
NAME=FETCHARG : Set NAME as the argument name of FETCHARG.
FETCHARG:TYPE : Set TYPE as the type of FETCHARG. Currently, basic types ——设置参数的类型,可以支持字符串和比特类型
(u8/u16/u32/u64/s8/s16/s32/s64), "string" and bitfield
are supported.
2、events/kprobes/
开启探测:echo 1 > events/kprobes/
暂停探测:echo 0 > events/kprobes/
3、events/kprobes/
该属性文件用于设置过滤条件,可以减少trace中输出的信息,它支持的格式和c语言的表达式类似,支持 ==,!=,>,<,>=,<=判断,并且支持与&&,或||,还有()。
下面还是以do_fork()函数为例来举例看一下具体如何使用(实验环境:树莓派1b):
1、设置配置属性
首先添加配置探测点:
root@apple:~# echo 'p:myprobe do_fork clone_flags=%r0 stack_start=%r1 stack_size=%r2 parent_tidptr=%r3 child_tidptr=+0($stack)' > /sys/kernel/debug/tracing/kprobe_events
root@apple:~# echo 'r:myretprobe do_fork $retval' >> /sys/kernel/debug/tracing/kprobe_events
这里注册probe和retprobe,其中probe中设定了获取do_fork()函数的入参值(注意这里的参数信息根据不同CPU架构的函数参数传递规则强相关,根据ARM遵守的ATPCS规则,函数入参14通过r0r3寄存器传递,多余的参数通过栈传递),由于入参为5个,所以前4个通过寄存器获取,最后一个通过栈获取。
现可通过format文件查看探测的输出格式:
root@apple:/sys/kernel/debug/tracing# cat events/kprobes/myprobe/format
name: myprobe
ID: 1211
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long __probe_ip; offset:8; size:4; signed:0;
field:u32 clone_flags; offset:12; size:4; signed:0;
field:u32 stack_start; offset:16; size:4; signed:0;
field:u32 stack_size; offset:20; size:4; signed:0;
field:u32 parent_tidptr; offset:24; size:4; signed:0;
field:u32 child_tidptr; offset:28; size:4; signed:0;
print fmt: "(%lx) clone_flags=0x%x stack_start=0x%x stack_size=0x%x parent_tidptr=0x%x child_tidptr=0x%x", REC->__probe_ip, REC->clone_flags, REC->stack_start, REC->stack_size, REC->parent_tidptr, REC->child_tidptr
root@apple:/sys/kernel/debug/tracing# cat events/kprobes/myretprobe/format
name: myretprobe
ID: 1212
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long __probe_func; offset:8; size:4; signed:0;
field:unsigned long __probe_ret_ip; offset:12; size:4; signed:0;
field:u32 arg1; offset:16; size:4; signed:0;
print fmt: "(%lx <- %lx) arg1=0x%x", REC->__probe_func, REC->__probe_ret_ip, REC->arg1
2、开启探测并触发函数调用
往对应的enable函数中写入1用以开启探测功能:
root@apple:/sys/kernel/debug/tracing# echo 1 > events/kprobes/myprobe/enable
root@apple:/sys/kernel/debug/tracing# echo 1 > events/kprobes/myretprobe/enable
然后在终端上敲几条命令和建立一个ssh链接触发进程创建do_fork函数调用,并通过trace属性文件获取函数调用时的探测情况
root@apple:/sys/kernel/debug/tracing# cat trace
# tracer: nop
......
bash-513 [000] d... 15726.746135: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6f43278
bash-513 [000] d... 15726.746691: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x226
bash-513 [000] d... 15727.296153: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6f43278
bash-513 [000] d... 15727.296713: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x227
bash-513 [000] d... 15728.356149: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6f43278
bash-513 [000] d... 15728.356705: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x228
bash-513 [000] d... 15731.596195: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6f43278
bash-513 [000] d... 15731.596756: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x229
sshd-520 [000] d... 17755.999223: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6fac068
sshd-520 [000] d... 17755.999943: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x22d
从输出中可以看到do_fork函数由bash(PID=513) 和sshd(PID=520)进程调用,同时执行的CPU为0,调用do_fork函数是入参值分别是stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xbxxxxxxx,同时输出函数返回上层SyS_clone系统调用的nr值。
如果输出太多了,想要清除就向trace中写0即可
root@apple:/sys/kernel/debug/tracing# echo 0 > trace
3、使用filter进行过滤
例如想要把前面列出的PID为513调用信息的给过滤掉,则向filter中写入如下的命令即可:
root@apple:/sys/kernel/debug/tracing# echo common_pid!=513 > events/kprobes/myprobe/filter
root@apple:/sys/kernel/debug/tracing# cat trace
# tracer: nop
......
bash-513 [000] d... 24456.536804: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x245
kthreadd-2 [000] d... 24598.655935: myprobe: (do_fork+0x0/0x380) clone_flags=0x800711 stack_start=0xc003d69c stack_size=0xc58982a0 parent_tidptr=0x0 child_tidptr=0x0
kthreadd-2 [000] d... 24598.656133: myretprobe: (kernel_thread+0x38/0x40 <- do_fork) arg1=0x246
bash-513 [000] d... 24667.676717: myretprobe: (SyS_clone+0x2c/0x34 <- do_fork) arg1=0x247
如此就不会在打印PID为513的进程调用信息了,这里的参数可以参考前面的format中输出的,例如想指定输出特定clone_flags值,则可以输入clone_flags=xxx即可。
最后补充一点,若此时需要查看函数调用的栈信息(stacktrace),可以使用如下命令激活stacktrace输出:
root@apple:/sys/kernel/debug/tracing# echo stacktrace > trace_options
root@apple:/sys/kernel/debug/tracing# cat trace
......
bash-508 [000] d... 449.276093: myprobe: (do_fork+0x0/0x380) clone_flags=0x1200011 stack_start=0x0 stack_size=0x0 parent_tidptr=0x0 child_tidptr=0xb6f86278
bash-508 [000] d... 449.276126: <stack trace>
=> do_fork
四、kprobe实现源码分析
在了解了kprobe的基本原理和使用后,现在从源码的角度来详细分析它是如何实现的。主要包括kprobes的初始化、注册kprobe和触发kprobe(包括arm结构和x86_64架构的回调函数和single-step单步执行)。
1、kprobes初始化
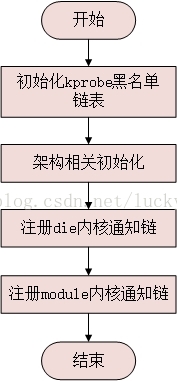
kprobes作为一个模块,其初始化函数为init_kprobes,代码路径kernel/kprobes.c
接下来调用populate_kprobe_blacklist函数将kprobe实现相关的代码函数保存到kprobe_blacklist这个链表中去,用于后面注册探测点时判断使用,注意这里的__start_kprobe_blacklist和__stop_kprobe_blacklist定义在arch/arm/kernel/vmlinux.lds.h中的.init.rodata段中,其中保存了_kprobe_blacklist段信息:
#define KPROBE_BLACKLIST() . = ALIGN(8); \
VMLINUX_SYMBOL(__start_kprobe_blacklist) = .; \
*(_kprobe_blacklist) \
VMLINUX_SYMBOL(__stop_kprobe_blacklist) = .;
#define INIT_DATA \
*(.init.data) \
......
*(.init.rodata) \
......
KPROBE_BLACKLIST() \
......
例如其中的get_kprobe函数:
struct kprobe *get_kprobe(void *addr)
{
......
}
NOKPROBE_SYMBOL(get_kprobe);
回到init_kprobes函数中继续分析,接下来的片段是kretprobe相关的代码,用来核对kretprobe_blacklist中定义的函数是否存在,这里kretprobe_blacklist_size变量默认为0;接下来初始化3个全局变量,kprobes_all_disarmed用于表示是否启用kprobe机制,这里默认设置为启用;随后调用arch_init_kprobes进行架构相关的初始化,x86架构的实现为空,arm架构的实现如下:
int __init arch_init_kprobes()
{
arm_probes_decode_init();
#ifdef CONFIG_THUMB2_KERNEL
register_undef_hook(&kprobes_thumb16_break_hook);
register_undef_hook(&kprobes_thumb32_break_hook);
#else
register_undef_hook(&kprobes_arm_break_hook);
#endif
return 0;
}
由于没有启用THUMB2模式,这里arm_probes_decode_init主要是获取PC和当前执行地址偏移值(ARM的流水线机制一般为8)以及设置相关寄存器值获取方式等代码;而register_undef_hook函数向全局undef_hook链表注册了一个未定义指令异常处理的钩子,相关的结构体如下:
static struct undef_hook kprobes_arm_break_hook = {
.instr_mask = 0x0fffffff,
.instr_val = KPROBE_ARM_BREAKPOINT_INSTRUCTION,
.cpsr_mask = MODE_MASK,
.cpsr_val = SVC_MODE,
.fn = kprobe_trap_handler,
};
这样在触发未定义指令KPROBE_ARM_BREAKPOINT_INSTRUCTION(机器码0x07f001f8)时将会调用到这里的kprobe_trap_handler函数。
再次回到init_kprobes函数,接下来分别注册die和module的内核通知链kprobe_exceptions_nb和kprobe_module_nb:
static struct notifier_block kprobe_exceptions_nb = {
.notifier_call = kprobe_exceptions_notify,
.priority = 0x7fffffff /* we need to be notified first */
};
static struct notifier_block kprobe_module_nb = {
.notifier_call = kprobes_module_callback,
.priority = 0
};
其中kprobe_exceptions_nb的优先级很高,如此在执行回调函数和单步执行被探测指令期间若发生了内存异常,将优先调用kprobe_exceptions_notify函数处理(架构相关,x86会调用kprobe的fault回调函数,而arm则为空);注册module notify回调kprobes_module_callback函数的作用是若当某个内核模块发生卸载操作时有必要检测并移除注册到该模块函数的探测点。
最后init_kprobes函数置位kprobes_initialized标识,初始化完成。
2、注册一个kprobe实例
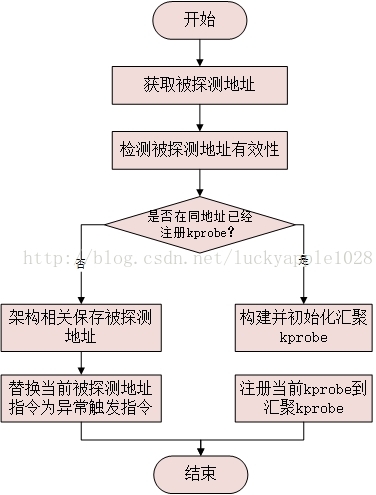
kprobe探测模块调用register_kprobe向kprobe子系统注册一个kprobe探测点实例,代码路径kernel/kprobes.c
int register_kprobe(struct kprobe *p)
{
int ret;
struct kprobe *old_p;
struct module *probed_mod;
kprobe_opcode_t *addr;
/* Adjust probe address from symbol */
addr = kprobe_addr(p);
if (IS_ERR(addr))
return PTR_ERR(addr);
p->addr = addr;
ret = check_kprobe_rereg(p);
if (ret)
return ret;
/* User can pass only KPROBE_FLAG_DISABLED to register_kprobe */
p->flags &= KPROBE_FLAG_DISABLED;
p->nmissed = 0;
INIT_LIST_HEAD(&p->list);
ret = check_kprobe_address_safe(p, &probed_mod);
if (ret)
return ret;
mutex_lock(&kprobe_mutex);
old_p = get_kprobe(p->addr);
if (old_p) {
/* Since this may unoptimize old_p, locking text_mutex. */
ret = register_aggr_kprobe(old_p, p);
goto out;
}
mutex_lock(&text_mutex); /* Avoiding text modification */
ret = prepare_kprobe(p);
mutex_unlock(&text_mutex);
if (ret)
goto out;
INIT_HLIST_NODE(&p->hlist);
hlist_add_head_rcu(&p->hlist,
&kprobe_table[hash_ptr(p->addr, KPROBE_HASH_BITS)]);
if (!kprobes_all_disarmed && !kprobe_disabled(p))
arm_kprobe(p);
/* Try to optimize kprobe */
try_to_optimize_kprobe(p);
out:
mutex_unlock(&kprobe_mutex);
if (probed_mod)
module_put(probed_mod);
return ret;
}
EXPORT_SYMBOL_GPL(register_kprobe);
函数首先调用kprobe_addr函数初始化被探测点的地址p->addr。因为一般的探测模块并不会指定想要探测的addr地址,同kprobe_example例程一样通过传入函数名来指定要探测的函数,kprobe_addr函数的作用就是将函数名转换为最终的被探测地址:
再来看一下arm架构的实现方式(已去除CONFIG_THUMB2_KERNEL相关部分的代码):
int __kprobes arch_prepare_kprobe(struct kprobe *p)
{
kprobe_opcode_t insn;
kprobe_opcode_t tmp_insn[MAX_INSN_SIZE];
unsigned long addr = (unsigned long)p->addr;
bool thumb;
kprobe_decode_insn_t *decode_insn;
const union decode_action *actions;
int is;
const struct decode_checker **checkers;
if (in_exception_text(addr))
return -EINVAL;
#ifdef CONFIG_THUMB2_KERNEL
......
#else /* !CONFIG_THUMB2_KERNEL */
thumb = false;
if (addr & 0x3)
return -EINVAL;
insn = __mem_to_opcode_arm(*p->addr);
decode_insn = arm_probes_decode_insn;
actions = kprobes_arm_actions;
checkers = kprobes_arm_checkers;
#endif
p->opcode = insn;
p->ainsn.insn = tmp_insn;
switch ((*decode_insn)(insn, &p->ainsn, true, actions, checkers)) {
case INSN_REJECTED: /* not supported */
return -EINVAL;
case INSN_GOOD: /* instruction uses slot */
p->ainsn.insn = get_insn_slot();
if (!p->ainsn.insn)
return -ENOMEM;
for (is = 0; is < MAX_INSN_SIZE; ++is)
p->ainsn.insn[is] = tmp_insn[is];
flush_insns(p->ainsn.insn,
sizeof(p->ainsn.insn[0]) * MAX_INSN_SIZE);
p->ainsn.insn_fn = (probes_insn_fn_t *)
((uintptr_t)p->ainsn.insn | thumb);
break;
case INSN_GOOD_NO_SLOT: /* instruction doesn't need insn slot */
p->ainsn.insn = NULL;
break;
}
/*
* Never instrument insn like 'str r0, [sp, +/-r1]'. Also, insn likes
* 'str r0, [sp, #-68]' should also be prohibited.
* See __und_svc.
*/
if ((p->ainsn.stack_space < 0) ||
(p->ainsn.stack_space > MAX_STACK_SIZE))
return -EINVAL;
return 0;
}
首先检测被探测地址不能在异常代码段中并且地址必须是4字节对齐的,随后取出被探测点的指令保存在kprobe->opcode中,并调用arm_probes_decode_insn函数来判断被探测的指令是什么类型的:
/* Return:
* INSN_REJECTED If instruction is one not allowed to kprobe,
* INSN_GOOD If instruction is supported and uses instruction slot,
* INSN_GOOD_NO_SLOT If instruction is supported but doesn't use its slot.
*
* For instructions we don't want to kprobe (INSN_REJECTED return result):
* These are generally ones that modify the processor state making
* them "hard" to simulate such as switches processor modes or
* make accesses in alternate modes. Any of these could be simulated
* if the work was put into it, but low return considering they
* should also be very rare.
*/
enum probes_insn __kprobes
arm_probes_decode_insn(probes_opcode_t insn, struct arch_probes_insn *asi,
bool emulate, const union decode_action *actions,
const struct decode_checker *checkers[])
{
asi->insn_singlestep = arm_singlestep;
asi->insn_check_cc = probes_condition_checks[insn>>28];
return probes_decode_insn(insn, asi, probes_decode_arm_table, false,
emulate, actions, checkers);
}
该arm_probes_decode_insn调用流程会对kprobe->ainsn结构进行初始化(该结构架构相关),其中函数指针insn_singlestep初始化为arm_singlestep,它用于kprobe触发后的单步执行,而函数insn_check_cc初始化为probes_condition_checks[insn>>28],它是一个函数指针数组,以指令的高4位为索引,用于kprobe触发后进行条件异常检测。
probes_check_cc * const probes_condition_checks[16] = {
&__check_eq, &__check_ne, &__check_cs, &__check_cc,
&__check_mi, &__check_pl, &__check_vs, &__check_vc,
&__check_hi, &__check_ls, &__check_ge, &__check_lt,
&__check_gt, &__check_le, &__check_al, &__check_al
};
现以do_fork函数为例,来看一下这里的insn_check_cc函数指针初始化为那个函数了:
反汇编vmlinux后找到do_fork,对应的入口地址为0xc0022798,汇编指令为mov,机器码为e1a0c00d,计算后值为0xe=15,因此选中的条件异常检测处理函数为__check_al;
c0022798 <do_fork>:
do_fork():
c0022798: e1a0c00d mov ip, sp
如果用户探测的并不是函数的入口地址,而是函数内部的某一条指令,则可能会选中其他的检测函数,例如movne指令选中的就是__check_ne,moveq指令选中的就是__check_eq等等。
回到arm_probes_decode_insn函数中,然后调用probes_decode_insn函数判断指令的类型并初始化单步执行函数指针insn_handler,最后返回INSN_REJECTED、INSN_GOOD和INSN_GOOD_NO_SLOT这三种类型(如果是INSN_GOOD还会拷贝指令填充ainsn.insn字段)。该函数的注释中对其描述的已经比较详细了,对于诸如某些会修改处理器工作状态的指令会返回INSN_REJECTED表示不支持,另外INSN_GOOD是需要slot的指令,INSN_GOOD_NO_SLOT是不需要slot的指令。
回到arch_prepare_kprobe函数中,会对返回的指令类型做不同的处理,若是INSN_GOOD类型则同x86类似,调用get_insn_slot申请内存空间并将前面存放在tmp_insn中的指令拷贝到kprobe->ainsn.insn中,然后flush icache。
如此被探测点指令就被拷贝保存起来了。架构相关的初始化完成以后,接下来register_kprobe函数初始化kprobe的hlist字段并将它添加到全局的hash表中。然后判断如果kprobes_all_disarmed为false并且kprobe没有被disable(在kprobe的初始化函数中该kprobes_all_disarmed值默认为false),则调用arm_kprobe函数,它会把触发trap的指令写到被探测点处替换原始指令。
static void arm_kprobe(struct kprobe *kp)
{
if (unlikely(kprobe_ftrace(kp))) {
arm_kprobe_ftrace(kp);
return;
}
/*
* Here, since __arm_kprobe() doesn't use stop_machine(),
* this doesn't cause deadlock on text_mutex. So, we don't
* need get_online_cpus().
*/
mutex_lock(&text_mutex);
__arm_kprobe(kp);
mutex_unlock(&text_mutex);
}
这里假设不适用ftrace和optimize kprobe特性,将直接调用架构相关的函数arch_arm_kprobe,其中x86的实现如下:
void arch_arm_kprobe(struct kprobe *p)
{
text_poke(p->addr, ((unsigned char []){BREAKPOINT_INSTRUCTION}), 1);
}
直接调用text_poke函数将addr地址处的指令替换为BREAKPOINT_INSTRUCTION指令(机器码是0xCC),当正常执行流程执行到这条指令后就会触发int3中断,进而进入探测回调流程。再看一下arm的实现流程:
void __kprobes arch_arm_kprobe(struct kprobe *p)
{
unsigned int brkp;
void *addr;
if (IS_ENABLED(CONFIG_THUMB2_KERNEL)) {
......
} else {
kprobe_opcode_t insn = p->opcode;
addr = p->addr;
brkp = KPROBE_ARM_BREAKPOINT_INSTRUCTION;
if (insn >= 0xe0000000)
brkp |= 0xe0000000; /* Unconditional instruction */
else
brkp |= insn & 0xf0000000; /* Copy condition from insn */
}
patch_text(addr, brkp);
}
arm架构的实现中替换的指令为KPROBE_ARM_BREAKPOINT_INSTRUCTION(机器码是0x07f001f8),然后还会根据被替换指令做一定的调整,最后调用patch_text函数执行替换动作。继续以kprobe_example例程中的do_fork函数为例,从前文中反汇编可知,地址0xc0022798处的“mov ip, sp”指令被替换KPROBE_ARM_BREAKPOINT_INSTRUCTION指令,可从pre_handler回调函数中打印的地址得到印证:
<6>[ 57.386132] [do_fork] pre_handler: p->addr = 0xc0022798, pc = 0xc0022798, cpsr = 0x80000013
<6>[ 57.386167] [do_fork] post_handler: p->addr = 0xc0022798, cpsr = 0x80000013
前文中看到KPROBE_ARM_BREAKPOINT_INSTRUCTION指令在init_kprobes函数的执行流程中已经为它注册了一个异常处理函数kprobe_trap_handler,因此当正常执行流程执行到KPROBE_ARM_BREAKPOINT_INSTRUCTION指令后将触发异常,进而调用kprobe_trap_handler开始回调流程。
至此kprobe的注册流程分析完毕,再回头分析对一个已经被注册过kprobe的探测点注册新的kprobe的执行流程,即register_aggr_kprobe函数:
/*
* This is the second or subsequent kprobe at the address - handle
* the intricacies
*/
static int register_aggr_kprobe(struct kprobe *orig_p, struct kprobe *p)
{
int ret = 0;
struct kprobe *ap = orig_p;
/* For preparing optimization, jump_label_text_reserved() is called */
jump_label_lock();
/*
* Get online CPUs to avoid text_mutex deadlock.with stop machine,
* which is invoked by unoptimize_kprobe() in add_new_kprobe()
*/
get_online_cpus();
mutex_lock(&text_mutex);
if (!kprobe_aggrprobe(orig_p)) {
/* If orig_p is not an aggr_kprobe, create new aggr_kprobe. */
ap = alloc_aggr_kprobe(orig_p);
if (!ap) {
ret = -ENOMEM;
goto out;
}
init_aggr_kprobe(ap, orig_p);
} else if (kprobe_unused(ap))
/* This probe is going to die. Rescue it */
reuse_unused_kprobe(ap);
if (kprobe_gone(ap)) {
/*
* Attempting to insert new probe at the same location that
* had a probe in the module vaddr area which already
* freed. So, the instruction slot has already been
* released. We need a new slot for the new probe.
*/
ret = arch_prepare_kprobe(ap);
if (ret)
/*
* Even if fail to allocate new slot, don't need to
* free aggr_probe. It will be used next time, or
* freed by unregister_kprobe.
*/
goto out;
/* Prepare optimized instructions if possible. */
prepare_optimized_kprobe(ap);
/*
* Clear gone flag to prevent allocating new slot again, and
* set disabled flag because it is not armed yet.
*/
ap->flags = (ap->flags & ~KPROBE_FLAG_GONE)
| KPROBE_FLAG_DISABLED;
}
/* Copy ap's insn slot to p */
copy_kprobe(ap, p);
ret = add_new_kprobe(ap, p);
out:
mutex_unlock(&text_mutex);
put_online_cpus();
jump_label_unlock();
if (ret == 0 && kprobe_disabled(ap) && !kprobe_disabled(p)) {
ap->flags &= ~KPROBE_FLAG_DISABLED;
if (!kprobes_all_disarmed)
/* Arm the breakpoint again. */
arm_kprobe(ap);
}
return ret;
}
在前文中看到,该函数会在对同一个被探测地址注册多个kprobe实例时会被调用到,该函数会引入一个kprobe aggregator的概念,即由一个统一的kprobe实例接管所有注册到该地址的kprobe。这个函数的注释非常详细,并不难理解,来简单分析一下:
函数的第一个入参orig_p是在全局hash表中找到的已经注册的kprobe实例,第二个入参是本次需要注册的kprobe实例。首先在完成了必要的上锁操作后就调用kprobe_aggrprobe函数检查orig_p是否是一个aggregator。
/* Return true if the kprobe is an aggregator */
static inline int kprobe_aggrprobe(struct kprobe *p)
{
return p->pre_handler == aggr_pre_handler;
}
它通过kprobe的pre_handler回调判断,如果是aggregator则它的pre_handler回调函数会被替换成aggr_pre_handler函数。一般对于第二次注册kprobe的情况显然是不会满足条件的,会调用alloc_aggr_kprobe函数创建一个,对于没有开启CONFIG_OPTPROBES选项的情况,alloc_aggr_kprobe仅仅是分配了一块内存空间,然后调用init_aggr_kprobe函数初始化这个aggr kprobe。
/*
* Fill in the required fields of the "manager kprobe". Replace the
* earlier kprobe in the hlist with the manager kprobe
*/
static void init_aggr_kprobe(struct kprobe *ap, struct kprobe *p)
{
/* Copy p's insn slot to ap */
copy_kprobe(p, ap);
flush_insn_slot(ap);
ap->addr = p->addr;
ap->flags = p->flags & ~KPROBE_FLAG_OPTIMIZED;
ap->pre_handler = aggr_pre_handler;
ap->fault_handler = aggr_fault_handler;
/* We don't care the kprobe which has gone. */
if (p->post_handler && !kprobe_gone(p))
ap->post_handler = aggr_post_handler;
if (p->break_handler && !kprobe_gone(p))
ap->break_handler = aggr_break_handler;
INIT_LIST_HEAD(&ap->list);
INIT_HLIST_NODE(&ap->hlist);
list_add_rcu(&p->list, &ap->list);
hlist_replace_rcu(&p->hlist, &ap->hlist);
}
可以看到,这个aggr kprobe中的各个字段基本就是从orig_p中拷贝过来的,包括opcode和ainsn这两个备份指令的字段以及addr和flags字段,但是其中的4个回调函数会被初始化为aggr kprobe所特有的addr_xxx_handler,这几个函数后面会具体分析。接下来函数会初始化aggr kprobe的两个链表头,然后将自己添加到链表中去,并替换掉orig_p。
回到register_aggr_kprobe函数中,如果本次是第二次以上向同一地址注册kprobe实例,则此时的orig_p已经是aggr kprobe了,则会调用kprobe_unused函数判断该kprobe是否为被使用,若是则调用reuse_unused_kprobe函数重新启用,但是对于没有开启CONFIG_OPTPROBES选项的情况,逻辑上是不存在这种情况的,因此reuse_unused_kprobe函数的实现仅仅是一段打印后就立即触发BUG_ON。
/* There should be no unused kprobes can be reused without optimization */
static void reuse_unused_kprobe(struct kprobe *ap)
{
printk(KERN_ERR "Error: There should be no unused kprobe here.\n");
BUG_ON(kprobe_unused(ap));
}
继续往下分析,下面来讨论aggr kprobe被kill掉的情况,显然只有在第三次及以上注册同一地址可能会出现这样的情况。针对这一种情况,这里同初次注册kprobe的调用流程类似,首先调用arch_prepare_kprobe做架构相关初始化,保存被探测地址的机器指令,然后调用prepare_optimized_kprobe启用optimized_kprobe,最后清除KPROBE_FLAG_GONE的标记。
接下来调用再次copy_kprobe将aggr kprobe中保存的指令opcode和ainsn字段拷贝到本次要注册的kprobe的对应字段中,然后调用add_new_kprobe函数将新注册的kprobe链入到aggr kprobe的list链表中:
/*
* Add the new probe to ap->list. Fail if this is the
* second jprobe at the address - two jprobes can't coexist
*/
static int add_new_kprobe(struct kprobe *ap, struct kprobe *p)
{
BUG_ON(kprobe_gone(ap) || kprobe_gone(p));
if (p->break_handler || p->post_handler)
unoptimize_kprobe(ap, true); /* Fall back to normal kprobe */
if (p->break_handler) {
if (ap->break_handler)
return -EEXIST;
list_add_tail_rcu(&p->list, &ap->list);
ap->break_handler = aggr_break_handler;
} else
list_add_rcu(&p->list, &ap->list);
if (p->post_handler && !ap->post_handler)
ap->post_handler = aggr_post_handler;
return 0;
}
注意最主要的就是add list,只是如果新注册的kprobe设定了break_handler回调函数,会将其插入链表的末尾并为aggr kprobe设定break handler回调函数aggr_break_handler;与此同时若新注册的kprobe设定了post_handler,也同样为aggr kprobe设定post handler回调函数aggr_post_handler。
回到register_aggr_kprobe函数,在out标号处继续执行,下面会进入if条件判断,启用aggr kprobe,然后调用前文中分析过的arm_kprobe函数替换被探测地址的机器指令为BREAKPOINT_INSTRUCTION指令。
至此整个kprobe注册流程分析结束,下面来分析以上注册的探测回调函数是如何被执行的以及被探测指令是如何被单步执行的。
3、触发kprobe探测和回调
前文中,从register_kprobe函数注册kprobe的流程已经看到,用户指定的被探测函数入口地址处的指令已经被替换成架构相关的BREAKPOINT_INSTRUCTION指令,若是正常的代码流程执行到该指令,将会触发异常,进入架构相关的异常处理函数,kprobe注册的回调函数及被探测函数的单步执行流程均在该流程中执行。由于不同架构实现存在差别,下面分别来分析,首先先分析arm架构的执行流程:
3.1、arm架构实现
前文中已经分析了内核已经为KPROBE_ARM_BREAKPOINT_INSTRUCTION指令注册了异常处理回调函数kprobe_trap_handler,因此在执行这条指令时会触发以下调用流程:__und_svc->__und_svc_fault->__und_fault->do_undefinstr()->call_undef_hook():
static int __kprobes kprobe_trap_handler(struct pt_regs *regs, unsigned int instr)
{
unsigned long flags;
local_irq_save(flags);
kprobe_handler(regs);
local_irq_restore(flags);
return 0;
}
call_undef_hook()调用未定义指令的回调函数,对于KPROBE_ARM_BREAKPOINT_INSTRUCTION指令即调用到kprobe_trap_handler函数,其中入参struct pt_regs *regs保存的时执行异常指令时的寄存器信息,同时该函数在处理kprobe的流程时会禁用掉本地CPU的中断。
kprobe_handler函数的实现比较长,分段来看:
/*
* Called with IRQs disabled. IRQs must remain disabled from that point
* all the way until processing this kprobe is complete. The current
* kprobes implementation cannot process more than one nested level of
* kprobe, and that level is reserved for user kprobe handlers, so we can't
* risk encountering a new kprobe in an interrupt handler.
*/
void __kprobes kprobe_handler(struct pt_regs *regs)
{
struct kprobe *p, *cur;
struct kprobe_ctlblk *kcb;
kcb = get_kprobe_ctlblk();
cur = kprobe_running();
#ifdef CONFIG_THUMB2_KERNEL
......
#else /* ! CONFIG_THUMB2_KERNEL */
p = get_kprobe((kprobe_opcode_t *)regs->ARM_pc);
#endif
注释中说明了当前arm架构的kprobe实现不支持在中断中多层kprobe重入,因此为了防止在处理一个kprobe期间由于中断可能会导致多次触发kprobe的情况,所以需要禁用中断。函数首先调用get_kprobe_ctlblk函数获取本cpu的per_cpu结构体变量kprobe_ctlblk,该结构体是架构相关的,arm的定义如下:
/* per-cpu kprobe control block */
struct kprobe_ctlblk {
unsigned int kprobe_status;
struct prev_kprobe prev_kprobe;
struct pt_regs jprobe_saved_regs;
char jprobes_stack[MAX_STACK_SIZE];
};
其中保存了kprobe的一些状态信息以及jpboe用到的字段,目前需要关注的是其中的kprobe_status和prev_kprobe字段,其中kprobe_status代表了当前kprobe的处理状态,一共包括以下几种:
#define KPROBE_HIT_ACTIVE 0x00000001 //开始处理kprobe
#define KPROBE_HIT_SS 0x00000002 //kprobe单步执行阶段
#define KPROBE_REENTER 0x00000004 //重复触发kprobe
#define KPROBE_HIT_SSDONE 0x00000008 //kprobe单步执行阶段结束
而prev_kprobe则是用于在kprobe重入情况下保存当前正在处理的kprobe实例和状态的。内核为每个cpu都定义了一个该类型全局变量。然后调用kprobe_running函数获取当前cpu上正在处理的kprobe:
/* kprobe_running() will just return the current_kprobe on this CPU */
static inline struct kprobe *kprobe_running(void)
{
return (__this_cpu_read(current_kprobe));
}
这里的current_kprobe也是一个per_cpu变量,其中保存了当前cpu正在处理的kprobe实例,若没有正在处理的则为NULL。下面调用get_kprobe函数获取本次要处理的kprobe,入参是regs->ARM_pc,即触发异常指令所在的地址,也就是被探测点的地址,利用它就可以在全局hash表中找到注册的kprobe实例了。接下来根据cur和p的存在情况进行多分支处理:
1、p和cur的kprobe实例同时存在
/* Kprobe is pending, so we're recursing. */
switch (kcb->kprobe_status) {
case KPROBE_HIT_ACTIVE:
case KPROBE_HIT_SSDONE:
/* A pre- or post-handler probe got us here. */
kprobes_inc_nmissed_count(p);
save_previous_kprobe(kcb);
set_current_kprobe(p);
kcb->kprobe_status = KPROBE_REENTER;
singlestep(p, regs, kcb);
restore_previous_kprobe(kcb);
break;
default:
/* impossible cases */
BUG();
}
这种情况属于kprobe重入的情况,即在运行kprobe回调函数或单步执行被探测指令时又一次触发了kprobe。对于重入,目前流程只能处理在前一kprobe执行回调函数时引发的kprobe重入,对于在单步执行阶段引发的重入就直接报BUG。具体的处理流程为:首先调用kprobes_inc_nmissed_count递增当前要处理kprobe的nmissed值(如果是aggr kprobe则会遍历链表将注册到同地址的所有kprobe的nmissed值都加1);然后调用save_previous_kprobe函数将当前时刻已经在处理的kprobe(cur)及状态保存到kcb->prev_kprobe字段中去;
static void __kprobes save_previous_kprobe(struct kprobe_ctlblk *kcb)
{
kcb->prev_kprobe.kp = kprobe_running();
kcb->prev_kprobe.status = kcb->kprobe_status;
}
然后调用set_current_kprobe函数将本次需要处理的kprobe(p)设置到current_kprobe的per_cpu变量中去,并且更新kprobe_status状态为KPROBE_REENTER,表示存在重入情况;接下来调用singlestep函数启动单步执行,这个函数稍后再看;最后调用restore_previous_kprobe函数恢复前面所保存的kprobe。
static void __kprobes save_previous_kprobe(struct kprobe_ctlblk *kcb)
{
kcb->prev_kprobe.kp = kprobe_running();
kcb->prev_kprobe.status = kcb->kprobe_status;
}
注意,以上重入的处理流程仅仅是单步执行了被探测的函数,并不会调用kprobe的pre_handle回调函数(递增nmissed字段的原因就在此),因此用户并不会感知到kprobe被实际触发了。
2、p存在但cur不存在
} else if (p->ainsn.insn_check_cc(regs->ARM_cpsr)) {
/* Probe hit and conditional execution check ok. */
set_current_kprobe(p);
kcb->kprobe_status = KPROBE_HIT_ACTIVE;
/*
* If we have no pre-handler or it returned 0, we
* continue with normal processing. If we have a
* pre-handler and it returned non-zero, it prepped
* for calling the break_handler below on re-entry,
* so get out doing nothing more here.
*/
if (!p->pre_handler || !p->pre_handler(p, regs)) {
kcb->kprobe_status = KPROBE_HIT_SS;
singlestep(p, regs, kcb);
if (p->post_handler) {
kcb->kprobe_status = KPROBE_HIT_SSDONE;
p->post_handler(p, regs, 0);
}
reset_current_kprobe();
}
} else {
/*
* Probe hit but conditional execution check failed,
* so just skip the instruction and continue as if
* nothing had happened.
*/
singlestep_skip(p, regs);
}
这种情况就是最为一般的情况,即当前kprobe是首次触发,前面并没有其他的kprobe流程正在处理。这里会首先调用p->ainsn.insn_check_cc注册函数来进行条件异常检测,这个函数在前文注册kprobe的流程中已经看到根据不同的被探测指令被注册成不同的函数了,入参是触发异常时的cpsr程序状态寄存器值。
对于前文中看到的do_fork函数入口汇编指令mov设置的__check_al检测函数来说,它将永远返回true,而movne指令的__check_ne检测函数则会对cpsr进行判断:
static unsigned long __kprobes __check_ne(unsigned long cpsr)
{
return (~cpsr) & PSR_Z_BIT;
}
(1)如果条件异常检测通过,那也同样调用set_current_kprobe函数设置当前正在处理的kprobe并更新kprobe状态标识为KPROBE_HIT_ACTIVE,表明开始处理该kprobe。接下来就到关键的回调和单步执行流程了,首先判断kprobe的pre_handler函数是否被注册,在注册的情况下调用它。对于单kprobe注册的情况很简单了,直接调用注册函数即可(这样前面kprobe_example中handler_pre函数就在此调用),但是对于前文中分析的多kprobe注册的情况(aggr kprobe),则会调用到aggr_pre_handler函数:
/*
* Aggregate handlers for multiple kprobes support - these handlers
* take care of invoking the individual kprobe handlers on p->list
*/
static int aggr_pre_handler(struct kprobe *p, struct pt_regs *regs)
{
struct kprobe *kp;
list_for_each_entry_rcu(kp, &p->list, list) {
if (kp->pre_handler && likely(!kprobe_disabled(kp))) {
set_kprobe_instance(kp);
if (kp->pre_handler(kp, regs))
return 1;
}
reset_kprobe_instance();
}
return 0;
}
NOKPROBE_SYMBOL(aggr_pre_handler);
该函数的功能很直观,即遍历aggr_kprobe->list链表中的各个同注册地址的kprobe实例,然后调用它们自己的pre_handler回调函数,这里的aggr_kprobe仅仅起到了一个管理分配的作用。其中set_kprobe_instance和reset_kprobe_instance函数的作用是设置和恢复kprobe_instance这个per_cpu变量,这个变量在aggr_fault_handler和aggr_break_handler回调函数中会用到,应为发生异常时,需要定位到当前正在处理哪一个kprobe。
/* We have preemption disabled.. so it is safe to use __ versions */
static inline void set_kprobe_instance(struct kprobe *kp)
{
__this_cpu_write(kprobe_instance, kp);
}
static inline void reset_kprobe_instance(void)
{
__this_cpu_write(kprobe_instance, NULL);
}
回到kprobe_handler函数继续往下分析,如果pre_handler执行成功或者不存在pre_handler回调函数则将kprobe当前处理状态设置为KPROBE_HIT_SS,表示开始进入单步执行阶段。随后 调用singlestep函数单步执行”原始被探测指令“,完毕后继续判断post_handler回调函数是否存在,若存在则设置当前状态为KPROBE_HIT_SSDONE,表示单步执行阶段执行结束,然后 调用post_handler回调函数(前文kprobe_example总的handler_post就在此调用)。post_handler同pre_handler一样,对与aggr kprobe会调用aggr_post_handler函数,由于实现类似,这里就不再赘述了。在执行完所有的回调后,最后调用reset_current_kprobe函数恢复current_kprobe变量。
这里可能会存在这样的疑问,为什么kcb->kprobe_status = KPROBE_HIT_SSDONE;这条状态赋值语句会放在条件判断内部,而不是在单步执行完以后?其实对于当前的上下文逻辑来看效果是一样的,因为若没有注册post_handler,就会立即执行reset_current_kprobe函数解除kprobe的绑定,因此不会对逻辑产生影响。
(2)如果条件异常检测不通过则调用singlestep_skip函数跳过当前的指令,继续执行后面的指令,就像什么都没有发生过一样
static void __kprobes
singlestep_skip(struct kprobe *p, struct pt_regs *regs)
{
#ifdef CONFIG_THUMB2_KERNEL
......
#else
regs->ARM_pc += 4;
#endif
}
该函数仅仅修改了regs结构中的PC值,在kprobe处理结束后将从被探测指令之后的指令继续执行。 这里就有一个疑问,如果不执行被探测点的原始指令,直接执行之后的指令难道不会出问题吗?
3、p不存在但cur存在
} else if (cur) {
/* We probably hit a jprobe. Call its break handler. */
if (cur->break_handler && cur->break_handler(cur, regs)) {
kcb->kprobe_status = KPROBE_HIT_SS;
singlestep(cur, regs, kcb);
if (cur->post_handler) {
kcb->kprobe_status = KPROBE_HIT_SSDONE;
cur->post_handler(cur, regs, 0);
}
}
reset_current_kprobe();
这种情况一般用于jprobe实现,函数调用cur kprobe的break_handler回调函数且在break_handler返回非0的情况下启动单步执行和执行post_handler回调,最后一样调用reset_current_kprobe函数解除cur kprobe绑定。该流程先不做详细推演分析,后面分析jprobe实现时再细细分析。
4、p和cur都不存在
} else {
/*
* The probe was removed and a race is in progress.
* There is nothing we can do about it. Let's restart
* the instruction. By the time we can restart, the
* real instruction will be there.
*/
}
这种情况表示当前kprobe已经被注销了,但是可能在注销的过程中(注销的过程并不是原子操作)可能被其他执行流程抢占进而触发该kprobe,对于这种情况什么都不需要做,直接返回即可。
至此arm架构的kprobe触发及处理整体流程就分析完了。下面分析x86_64架构的实现,总体大同小异,其中的相同之处就不再分析了。
3.2、x86_64架构实现
/* May run on IST stack. */
dotraplinkage void notrace do_int3(struct pt_regs *regs, long error_code)
{
......
#ifdef CONFIG_KPROBES
if (kprobe_int3_handler(regs))
goto exit;
#endif
......
}
NOKPROBE_SYMBOL(do_int3);
x86_64架构下,执行到前文中替换的BREAKPOINT_INSTRUCTION指令后将触发INT3中断,进而调用到do_int3函数。do_init3函数做的事情比较多,但是和kprobe相关的仅代码中列出的这1处,下面来看kprobe_int3_handler函数,这个函数同arm结构的kprobe_handler函数很像,依然分段来分析:
/*
* Interrupts are disabled on entry as trap3 is an interrupt gate and they
* remain disabled throughout this function.
*/
int kprobe_int3_handler(struct pt_regs *regs)
{
kprobe_opcode_t *addr;
struct kprobe *p;
struct kprobe_ctlblk *kcb;
if (user_mode(regs))
return 0;
addr = (kprobe_opcode_t *)(regs->ip - sizeof(kprobe_opcode_t));
/*
* We don't want to be preempted for the entire
* duration of kprobe processing. We conditionally
* re-enable preemption at the end of this function,
* and also in reenter_kprobe() and setup_singlestep().
*/
preempt_disable();
kcb = get_kprobe_ctlblk();
p = get_kprobe(addr);
本地中断在处理kprobe期间依然被禁止,同时调用user_mode函数确保本处理函数处理的int3中断是在内核态执行流程期间被触发的(因为kprobe不会从用户态触发),这里之所以要做这么一个判断是因为同arm定义特殊未处理指令回调函数不同,这里的do_int3要通用的多,并不是单独为kprobe所设计的。然后获取被探测指令的地址保存到addr中(对于int3中断,其被Intel定义为trap,那么异常发生时EIP寄存器内指向的为异常指令的后一条指令),同时会禁用内核抢占,注释中说明在reenter_kprobe和单步执行时会有选择的重新开启内核抢占。接下来下面同arm一样获取当前cpu的kprobe_ctlblk控制结构体和本次要处理的kprobe实例p,然后根据不同的情况进行不同分支的处理。在继续分析前先来看一下x86_64架构kprobe_ctlblk结构体的定义
/* per-cpu kprobe control block */
struct kprobe_ctlblk {
unsigned long kprobe_status;
unsigned long kprobe_old_flags;
unsigned long kprobe_saved_flags;
unsigned long *jprobe_saved_sp;
struct pt_regs jprobe_saved_regs;
kprobe_opcode_t jprobes_stack[MAX_STACK_SIZE];
struct prev_kprobe prev_kprobe;
};
该定义比arm结构的多一些字段,其中kprobe_status字段不变,kprobe_old_flags和kprobe_saved_flags字段用于保存寄存器pt_regs的flag标识。
下面回到函数中根据不同的情况分别分析:
1、p存在且curent_kprobe存在
对于kprobe重入的情况,调用reenter_kprobe函数单独处理:
if (kprobe_running()) {
if (reenter_kprobe(p, regs, kcb))
return 1;
/*
* We have reentered the kprobe_handler(), since another probe was hit while
* within the handler. We save the original kprobes variables and just single
* step on the instruction of the new probe without calling any user handlers.
*/
static int reenter_kprobe(struct kprobe *p, struct pt_regs *regs,
struct kprobe_ctlblk *kcb)
{
switch (kcb->kprobe_status) {
case KPROBE_HIT_SSDONE:
case KPROBE_HIT_ACTIVE:
case KPROBE_HIT_SS:
kprobes_inc_nmissed_count(p);
setup_singlestep(p, regs, kcb, 1);
break;
case KPROBE_REENTER:
/* A probe has been hit in the codepath leading up to, or just
* after, single-stepping of a probed instruction. This entire
* codepath should strictly reside in .kprobes.text section.
* Raise a BUG or we'll continue in an endless reentering loop
* and eventually a stack overflow.
*/
printk(KERN_WARNING "Unrecoverable kprobe detected at %p.\n",
p->addr);
dump_kprobe(p);
BUG();
default:
/* impossible cases */
WARN_ON(1);
return 0;
}
return 1;
}
NOKPROBE_SYMBOL(reenter_kprobe);
这个流程同arm实现的很像,只不过对于KPROBE_HIT_SS阶段不会报BUG,也同KPROBE_HIT_SSDONE和KPROBE_HIT_ACTIVE一样,递增nmissed值并调用setup_singlestep函数进入单步处理流程(该函数最后一个入参此时设置为1,针对reenter的情况会将kprobe_status状态设置为KPROBE_REENTER并调用save_previous_kprobe执行保存当前kprobe的操作)。对于KPROBE_REENTER阶段还是直接报BUG。注意最后函数会返回1,do_int3也会直接返回,表示该中断已被kprobe截取并处理,无需再处理其他分支。
2、p存在但curent_kprobe不存在
} else {
set_current_kprobe(p, regs, kcb);
kcb->kprobe_status = KPROBE_HIT_ACTIVE;
/*
* If we have no pre-handler or it returned 0, we
* continue with normal processing. If we have a
* pre-handler and it returned non-zero, it prepped
* for calling the break_handler below on re-entry
* for jprobe processing, so get out doing nothing
* more here.
*/
if (!p->pre_handler || !p->pre_handler(p, regs))
setup_singlestep(p, regs, kcb, 0);
return 1;
}
这是一般最通用的kprobe执行流程,首先调用set_current_kprobe绑定p为当前正在处理的kprobe:
static nokprobe_inline void
set_current_kprobe(struct kprobe *p, struct pt_regs *regs,
struct kprobe_ctlblk *kcb)
{
__this_cpu_write(current_kprobe, p);
kcb->kprobe_saved_flags = kcb->kprobe_old_flags
= (regs->flags & (X86_EFLAGS_TF | X86_EFLAGS_IF));
if (p->ainsn.if_modifier)
kcb->kprobe_saved_flags &= ~X86_EFLAGS_IF;
}
这里在设置current_kprobe全局变量的同时,还会同时设置kprobe_saved_flags和kprobe_old_flags的flag值,它们用于具体的架构指令相关处理。接下来处理pre_handler回调函数,有注册的话就调用执行,然后调用setup_singlestep启动单步执行。在调试完成后直接返回1,注意这里并没有向arm实现那样直接调用post_handler回调函数并解除kprobe绑定,因为x86_64架构的post_handler采用另一种方式调用,后文会讲到。
3、p不存在且被探测地址的指令也不是BREAKPOINT_INSTRUCTION
} else if (*addr != BREAKPOINT_INSTRUCTION) {
/*
* The breakpoint instruction was removed right
* after we hit it. Another cpu has removed
* either a probepoint or a debugger breakpoint
* at this address. In either case, no further
* handling of this interrupt is appropriate.
* Back up over the (now missing) int3 and run
* the original instruction.
*/
regs->ip = (unsigned long)addr;
preempt_enable_no_resched();
return 1;
这种情况表示kprobe可能已经被其他CPU注销了,则让他执行原始指令即可,因此这里设置regs->ip值为addr并重新开启内核抢占返回1。
4、p不存在但curent_kprobe存在
} else if (kprobe_running()) {
p = __this_cpu_read(current_kprobe);
if (p->break_handler && p->break_handler(p, regs)) {
if (!skip_singlestep(p, regs, kcb))
setup_singlestep(p, regs, kcb, 0);
return 1;
}
这种情况一般用于实现jprobe,因此会调用curent_kprobe的break_handler回调函数,然后在break_handler返回非0的情况下执行单步执行,最后返回1。具体在jprobe实现中再详细分析。
以上x86_64架构的kprobe触发及回调整体流程分析完毕,可以看到基本的触发条件和处理流程和arm架构的实现还是差不多的,和架构相关的一些细节有所不同。同时也并没有看到post_handle的回调流程和kprobe的解绑定流程,由于实现同arm不同,以上遗留的两点会在后文分析。接下来分析被探测指令的单步执行过程。
4、单步执行
单步执行其实就是执行被探测点的原始指令,涉及的主要函数即前文中分析kprobe触发及处理流程时遗留的singlestep函数(arm)和setup_singlestep函数(x86),它们的实现原理完全不同,其中会涉及许多cpu架构相关的知识,因此会比较晦涩。下面从原理角度逐一分析,并不涉及太多架构相关的细节:
4.1、arm架构实现
arm架构单步执行的原理并不非常复杂(但是实现非常复杂),它本质上所做的就是执行被探测点的被替换前的“原始指令”,但是当前的上下文已经是kprobe的执行上下文了,不再是原始指令所处的上下文,所以单步执行流程无法直接执行原始指令,而是会调用其他函数来模拟实现原始指令以达到相同的效果,因此涉及的函数很多,基本每条不同的汇编指令都有不同的模拟函数。
static inline void __kprobes
singlestep(struct kprobe *p, struct pt_regs *regs, struct kprobe_ctlblk *kcb)
{
p->ainsn.insn_singlestep(p->opcode, &p->ainsn, regs);
}
singlestep函数直接调用保存在arch_probes_insn结构中的insn_singlestep函数指针(该指针在注册kprobe时由arm_probes_decode_insn函数负责初始化),即arm_singlestep函数。入参为保存的被探测点指令、arch_probes_insn结构地址及寄存器参数。
static void __kprobes arm_singlestep(probes_opcode_t insn,
struct arch_probes_insn *asi, struct pt_regs *regs)
{
regs->ARM_pc += 4;
asi->insn_handler(insn, asi, regs);
}
首先让寄存器参数中的PC加4,表示kprobe处理完成后将跳过触发kprobe时的KPROBE_ARM_BREAKPOINT_INSTRUCTION指令继续执行。然后调用insn_handler函数指针中设置的注册函数,该函数指针由probes_decode_insn函数根据不同的原始指令被设置为不同的处理函数,它们被定义在kprobes_arm_actions数组中:
const union decode_action kprobes_arm_actions[NUM_PROBES_ARM_ACTIONS] = {
[PROBES_PRELOAD_IMM] = {.handler = probes_simulate_nop},
[PROBES_PRELOAD_REG] = {.handler = probes_simulate_nop},
[PROBES_BRANCH_IMM] = {.handler = simulate_blx1},
[PROBES_MRS] = {.handler = simulate_mrs},
[PROBES_BRANCH_REG] = {.handler = simulate_blx2bx},
[PROBES_CLZ] = {.handler = emulate_rd12rm0_noflags_nopc},
[PROBES_SATURATING_ARITHMETIC] = {
.handler = emulate_rd12rn16rm0_rwflags_nopc},
[PROBES_MUL1] = {.handler = emulate_rdlo12rdhi16rn0rm8_rwflags_nopc},
[PROBES_MUL2] = {.handler = emulate_rd16rn12rm0rs8_rwflags_nopc},
[PROBES_SWP] = {.handler = emulate_rd12rn16rm0_rwflags_nopc},
[PROBES_LDRSTRD] = {.handler = emulate_ldrdstrd},
......
}
这里的函数众多就不一一分析了,现仍然以do_fork函数的入口指令“mov ip, sp”为例,调用的函数为simulate_mov_ipsp:
void __kprobes simulate_mov_ipsp(probes_opcode_t insn,
struct arch_probes_insn *asi, struct pt_regs *regs)
{
regs->uregs[12] = regs->uregs[13];
}
这里的uregs[12]即ARM_ip,uregs[13]即ARM_sp,可见simulate_mov_ipsp函数仅仅是模拟实现“mov ip, sp”指令而已,对触发kprobe前的寄存器状态进行处理。当然这只是其中一个简单的例子,对于其他一些复杂的多周期指令其模拟函数会实现的比较复杂,甚至有一些无法模拟的指令在注册时probes_decode_insn函数就会返回INSN_REJECTED了。
以上arm架构下实现同原始指令同样效果的单步执行就分析完了,在kprobe流程执行完成后,恢复到regs中保存的上下文后就会从ARM_pc处继续取指执行了。这里虽然只分析了mov指令的单步执行,但其他的指令的处理流程类似,若想要了解个中细节可以通过ftrace工具进行跟踪。
4.2、x86_64架构实现
x86_64架构的单步执行函数与arm架构的原理不同,其主要原理是:当程序执行到某条想要单独执行CPU指令时,在执行之前产生一次CPU异常,此时把异常返回时的CPU的EFLAGS寄存器的TF(调试位)位置为1,把IF(中断屏蔽位)标志位置为0,然后把EIP指向单步执行的指令。当单步指令执行完成后,CPU会自动产生一次调试异常(由于TF被置位)。此时,Kprobes会利用debug异常,执行post_handler()。下面来简单看一下:
static void setup_singlestep(struct kprobe *p, struct pt_regs *regs,
struct kprobe_ctlblk *kcb, int reenter)
{
if (setup_detour_execution(p, regs, reenter))
return;
......
if (reenter) {
save_previous_kprobe(kcb);
set_current_kprobe(p, regs, kcb);
kcb->kprobe_status = KPROBE_REENTER;
} else
kcb->kprobe_status = KPROBE_HIT_SS;
/* Prepare real single stepping */
clear_btf();
regs->flags |= X86_EFLAGS_TF;
regs->flags &= ~X86_EFLAGS_IF;
/* single step inline if the instruction is an int3 */
if (p->opcode == BREAKPOINT_INSTRUCTION)
regs->ip = (unsigned long)p->addr;
else
regs->ip = (unsigned long)p->ainsn.insn;
}
首先在前文中已经介绍了,函数的最后一个入参reenter表示是否重入,对于重入的情况那就调用save_previous_kprobe函数保存当前正在运行的kprobe,然后绑定p和current_kprobe并设置kprobe_status为KPROBE_REENTER;对于非重入的情况则设置kprobe_status为KPROBE_HIT_SS。
接下来考试准备单步执行,首先设置regs->flags中的TF位并清空IF位,同时把int3异常返回的指令寄存器地址改为前面保存的被探测指令,当int3异常返回时这些设置就会生效,即立即执行保存的原始指令(注意这里是在触发int3之前原来的上下文中执行,因此直接执行原始指令即可,无需特别的模拟操作)。该函数返回后do_int3函数立即返回,由于cpu的标识寄存器被设置,在单步执行完被探测指令后立即触发debug异常,进入debug异常处理函数do_debug。
dotraplinkage void do_debug(struct pt_regs *regs, long error_code)
{
......
#ifdef CONFIG_KPROBES
if (kprobe_debug_handler(regs))
goto exit;
#endif
......
exit:
ist_exit(regs, prev_state);
}
/*
* Interrupts are disabled on entry as trap1 is an interrupt gate and they
* remain disabled throughout this function.
*/
int kprobe_debug_handler(struct pt_regs *regs)
{
struct kprobe *cur = kprobe_running();
struct kprobe_ctlblk *kcb = get_kprobe_ctlblk();
if (!cur)
return 0;
resume_execution(cur, regs, kcb);
regs->flags |= kcb->kprobe_saved_flags;
if ((kcb->kprobe_status != KPROBE_REENTER) && cur->post_handler) {
kcb->kprobe_status = KPROBE_HIT_SSDONE;
cur->post_handler(cur, regs, 0);
}
/* Restore back the original saved kprobes variables and continue. */
if (kcb->kprobe_status == KPROBE_REENTER) {
restore_previous_kprobe(kcb);
goto out;
}
reset_current_kprobe();
out:
preempt_enable_no_resched();
/*
* if somebody else is singlestepping across a probe point, flags
* will have TF set, in which case, continue the remaining processing
* of do_debug, as if this is not a probe hit.
*/
if (regs->flags & X86_EFLAGS_TF)
return 0;
return 1;
}
NOKPROBE_SYMBOL(kprobe_debug_handler);
首先调用resume_execution函数将debug异常返回的下一条指令设置为被探测之后的指令,这样异常返回后程序的流程就会按正常的流程继续执行;然后恢复kprobe执行前保存的flags标识;接下来如果kprobe不是重入的并且设置了post_handler回调函数,就设置kprobe_status状态为KPROBE_HIT_SSDONE并调用post_handler函数;如果是重入的kprobe则调用restore_previous_kprobe函数恢复之前保存的kprobe。最后调用reset_current_kprobe函数解除本kprobe和current_kprobe的绑定,如果本kprobe由单步执行触发,则说明do_debug异常处理还有其他流程带处理,返回0,否则返回1。
以上x86_64的单步执行和post_handler回调分析完毕,简单总结一下和arm架构的实现区别:arm结构的单步执行被探测指令是在异常处理上下文中进行的,因此需要使用单独的函数来模拟实现原始命令所操作的流程,而x86_64架构则利用了cpu提供的单步调试技术,使得原始指令在正常的原上下文中执行,而两个回调函数则分别在int3和debug两次异常处理流程中执行。
至此,kprobe的一般处理流程就分析完了,最后分析一下剩下的最后一个回调函数fault_handler。
5、出错回调
出错会调函数fault_handler会在执行pre_handler、single_step和post_handler期间触发内存异常时被调用,对应的调用函数为kprobe_fault_handler,它同样时架构相关的,分别来看一下:
5.1、arm调用流程
do_page_fault->notify_page_fault
static inline int notify_page_fault(struct pt_regs *regs, unsigned int fsr)
{
int ret = 0;
if (!user_mode(regs)) {
/* kprobe_running() needs smp_processor_id() */
preempt_disable();
if (kprobe_running() && kprobe_fault_handler(regs, fsr))
ret = 1;
preempt_enable();
}
return ret;
}
可见在触发缺页异常之后,若当前正在处理kprobe流程期间,会调用kprobe_fault_handler进行处理。
int __kprobes kprobe_fault_handler(struct pt_regs *regs, unsigned int fsr)
{
struct kprobe *cur = kprobe_running();
struct kprobe_ctlblk *kcb = get_kprobe_ctlblk();
switch (kcb->kprobe_status) {
case KPROBE_HIT_SS:
case KPROBE_REENTER:
/*
* We are here because the instruction being single
* stepped caused a page fault. We reset the current
* kprobe and the PC to point back to the probe address
* and allow the page fault handler to continue as a
* normal page fault.
*/
regs->ARM_pc = (long)cur->addr;
if (kcb->kprobe_status == KPROBE_REENTER) {
restore_previous_kprobe(kcb);
} else {
reset_current_kprobe();
}
break;
case KPROBE_HIT_ACTIVE:
case KPROBE_HIT_SSDONE:
/*
* We increment the nmissed count for accounting,
* we can also use npre/npostfault count for accounting
* these specific fault cases.
*/
kprobes_inc_nmissed_count(cur);
/*
* We come here because instructions in the pre/post
* handler caused the page_fault, this could happen
* if handler tries to access user space by
* copy_from_user(), get_user() etc. Let the
* user-specified handler try to fix it.
*/
if (cur->fault_handler && cur->fault_handler(cur, regs, fsr))
return 1;
break;
default:
break;
}
return 0;
}
kprobe_fault_handler函数会找到当前正在处理的kprobe,然后根据处理状态的不同本别处理。首先若是单步执行或是重入的情况,则说明单步执行是发生了内存错误,则复位当前正在处理的kprobe,同时设置PC指针为异常触发指令地址,就好像它是一个普通的缺页异常,由内核后续的处理流程处理;若是执行pre_handler和post_handler回调函数期间出错,则递增kprobe的nmiss字段值,然后调用fault_handler回调函数执行用户指定的操作,如果fault_handler函数返回0则会由内核继续处理page fault,否则表示fault_handler函数已经执行了修复操作,do_page_fault会直接返回。
5.2、x86_64调用流程
1、do_page_fault->__do_page_fault->kprobes_fault
static nokprobe_inline int kprobes_fault(struct pt_regs *regs)
{
int ret = 0;
/* kprobe_running() needs smp_processor_id() */
if (kprobes_built_in() && !user_mode(regs)) {
preempt_disable();
if (kprobe_running() && kprobe_fault_handler(regs, 14))
ret = 1;
preempt_enable();
}
return ret;
}
这个缺页异常的调用流程同arm实现的几乎完全一样,就不赘述了。
2、do_general_protection->notify_die->kprobe_exceptions_notify
int kprobe_exceptions_notify(struct notifier_block *self, unsigned long val,
void *data)
{
struct die_args *args = data;
int ret = NOTIFY_DONE;
if (args->regs && user_mode(args->regs))
return ret;
if (val == DIE_GPF) {
/*
* To be potentially processing a kprobe fault and to
* trust the result from kprobe_running(), we have
* be non-preemptible.
*/
if (!preemptible() && kprobe_running() &&
kprobe_fault_handler(args->regs, args->trapnr))
ret = NOTIFY_STOP;
}
return ret;
}
前文中init_kprobes初始化时会注册die内核通知链kprobe_exceptions_nb,它的回调函数为kprobe_exceptions_notify,在内核触发DIE_GPF类型的notify_die时,该函数会调用kprobe_fault_handler进行处理。下面来简单看一下x86_64架构的kprobe_fault_handler函数实现:
int kprobe_fault_handler(struct pt_regs *regs, int trapnr)
{
struct kprobe *cur = kprobe_running();
struct kprobe_ctlblk *kcb = get_kprobe_ctlblk();
if (unlikely(regs->ip == (unsigned long)cur->ainsn.insn)) {
/* This must happen on single-stepping */
WARN_ON(kcb->kprobe_status != KPROBE_HIT_SS &&
kcb->kprobe_status != KPROBE_REENTER);
/*
* We are here because the instruction being single
* stepped caused a page fault. We reset the current
* kprobe and the ip points back to the probe address
* and allow the page fault handler to continue as a
* normal page fault.
*/
regs->ip = (unsigned long)cur->addr;
regs->flags |= kcb->kprobe_old_flags;
if (kcb->kprobe_status == KPROBE_REENTER)
restore_previous_kprobe(kcb);
else
reset_current_kprobe();
preempt_enable_no_resched();
} else if (kcb->kprobe_status == KPROBE_HIT_ACTIVE ||
kcb->kprobe_status == KPROBE_HIT_SSDONE) {
/*
* We increment the nmissed count for accounting,
* we can also use npre/npostfault count for accounting
* these specific fault cases.
*/
kprobes_inc_nmissed_count(cur);
/*
* We come here because instructions in the pre/post
* handler caused the page_fault, this could happen
* if handler tries to access user space by
* copy_from_user(), get_user() etc. Let the
* user-specified handler try to fix it first.
*/
if (cur->fault_handler && cur->fault_handler(cur, regs, trapnr))
return 1;
/*
* In case the user-specified fault handler returned
* zero, try to fix up.
*/
if (fixup_exception(regs))
return 1;
/*
* fixup routine could not handle it,
* Let do_page_fault() fix it.
*/
}
return 0;
}
流程基本同arm实现的完全一致,唯一不同之处在于如果fault_handler函数返回0,即没有修复内存异常,则会直接调用fixup_exception函数尝试修复。
以上fault_handler回调函数分析完毕。
五、总结
kprobes内核探测技术作为一种内核代码的跟踪及调试手段,开发人员可以动态的跟踪内核函数的执行,相较与传统的添加内核日志等调试手段,它具有操作简单,使用灵活,对原始代码破坏小等多方面优势。本文首先介绍了kprobes的技术背景,然后介绍了其中kprobe技术使用方法并且通过源代码详细分析了arm架构和x86_64架构的原理和实现方式。下一篇博文将介绍基于kprobe实现的jprobe内核跟踪技术。
参考文献:
1、http://blog.chinaunix.net/uid-20662820-id-3795534.html
2、http://blog.csdn.net/panfengyun12345/article/details/19480567
3、Documentation/kprobes.txt
4、Documentation/trace/kprobetrace.txt

