
slab为什么要进行着色处理
大概的简述一下,及cpu读取内存里的东西时,并不会直接去内存去读取,这样会导致读取的数据很慢。cpu会到一级缓存读取所需要的数据,而一级缓存则会去内存里面读取数据,读取的方式是通过缓存行(cache line)的形式来进行读取。当一级缓存内的数据需要置换时,则会将缓存内的数据置换到二级缓存内,然后依次类推到内存中。
假设我们的缓存行为64字节,512行(一共32K)。那么32K的大小怎么进行对几百M或者几G的内存进行映射呢?
高速缓存读物理内存的位置不是任意的,而是固定的。那么就根据高速缓存的大小进行映射,这里是32K一组大小进行映射:
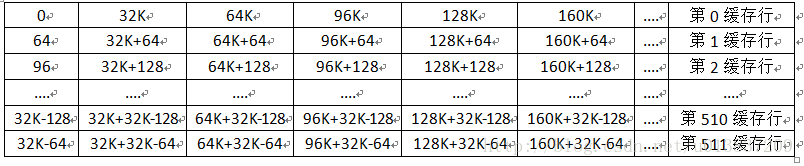
再假设: 我们读取数据的内存物理地址是0x1000000,
则第0缓存行就会固定的读取0x10000000x1000040这64个字节大小(即缓存行大小),并且第0缓存行并不能读取0x10000400x1000080的数据,这个地址只能是第1缓存行进行读取的。第0缓存行读取的下一个地址只能是0x1008000~0x1008040的数据,然后以此类推。
那么现在已经可以解释slab为啥要进行着色了:
比如cpu正在对0x10000008地址进行读写操作,突然有一个地址指针指向了0x10008008,并且需要读取0x10008008内存处的地址,cpu检测到冲突,因为此时位于第0根缓存行上的64个字节数据有效地址空间是0x100000000x10000040,而另一个地址段下的物理内存也需要使用第0根缓存行,cpu执行写回操作,将现在第0根缓存行上的64字节数据块传输到物理内存0x100000000x10000040上,之后将0x10008000~0x10008040物理内存段上的64字节数据,块传输到第0缓存行,这样就完成了冲突之后的一次切换。
如果我们需要进行对这两块上面的数据分别交叉的读取1000次,那么我们需要进行对高速缓存的不断移除更新,而且读取内存的速度远远的大于读取缓存的速度,那么将会造成大量的时间消耗。
解决办法就是将第二块读取的数据前加一个偏移,让它移到第1块缓存行上面,两块数据分别可以在缓存行的0和1行上面进行读取,那么我们读取数据的时候就不会造成不必要的数据交换。
着色即为添加偏移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号