MySQL两阶段提交串讲
MySQL两阶段提交
一、吹个牛#
面试官的一句:“了解MySQL的两阶段提交吗?” 不知道问凉了多少人!
这篇文章白日梦就和大家分享什么是MySQL的两阶提交到底是怎么回事!不管你原来晓不晓得两阶段提交,相信我!这篇文章中你一定能get到新的知识!
在说两阶段提交之前,白日梦用了大量的篇幅再讲undo-log、redo-log、binlog。
先了解它们,才能更好的理解什么是两阶段提交,如果你如果还没有看,推荐你去翻一翻前面的文章。
二、事务及它的特性#
在说两阶段提交事物之前,我们先来说说事务。
一般当我们的功能函数中有批量的增删改时,我们会添加一个事物包裹这一系列的操作,要么这一组操作全部执行成功,只要有一条SQL执行失败了我们就全部回滚。相信你一定听说过这个比较经典的转账的Case。有一定工作经验的同学都知道,这么做其实是保护我们的数据库中不出现脏数据。整体数据会变的可控。
对MySQL来说你可以通过下面的命令显示的开启、提交、回滚事务
# 开启事务
begin;
# 或者下面这条命令
start transaction;
# 提交
commit;
# 回滚
rollback;
但是日常开发中大家普遍使用编程语言操作数据库。比如Java、Golang... 在使用这种具体编程语言持久层的框架时,它们一般都支持事务操作,比如:在Spring中你可以对一个方法添加注解@Transctional显示的开启事务。Golang的beego中也提供了让你可以显示的开启事务的函数。
有一点不太好的地方是:大家在享受这种编程框架带来的便利的同时,它也屏蔽了你对MySQL事务认知。让人们懒得去往细了看事务
你可以往看我下面这个很简单的Case。
我有一张数据表
CREATE TABLE `test_backup` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后我往这个表中insert几条数据
mysql> insert into test_backup values(1,'tom');
mysql> insert into test_backup values(2,'jerry');
mysql> insert into test_backup values(1,'herry');
再去查看binlog。
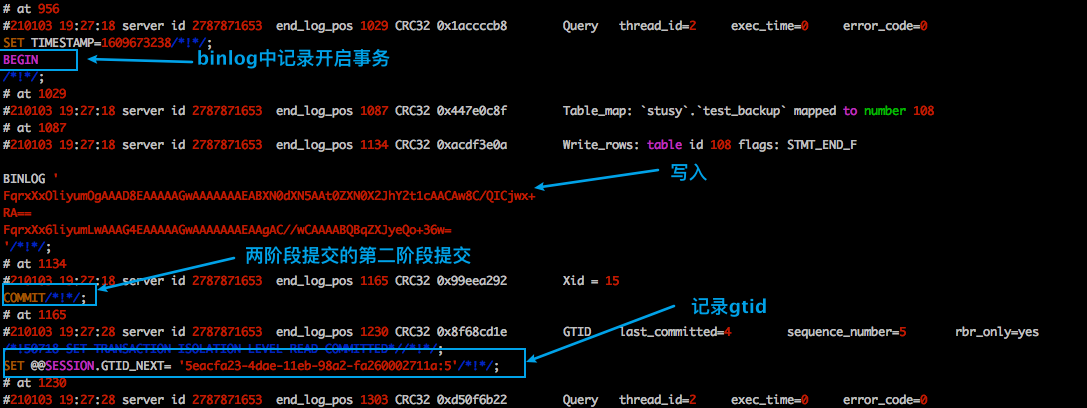
你会不会诧异?我上面明明没有显示的添加begin、commit命令,但是MySQL实际执行我的SQL时,竟然为我添加上了!
原因很简单:跟大家分享一个参数如下:

一般大家的线上库都会将这个参数置为ON,你的SQL会自动的开启一个事物,并且MySQL会自动的帮你把它提交。
也就是说: 当这个参数为ON时,你使用的DAO持久层框架发送给数据库的SQL其实都会被放在一个事物中执行,然后这个事物被自动提交,而我们对这个过程是无感知的。 具体一点,比如你使用某框架的@Transctional注解,或者在golang中可以像下面的方式获得一个事物:
db := mysql.Client
ops := &sql.TxOptions{
Isolation: 0,
ReadOnly: false,
}
tx, err := db.BeginTx(ctx, ops)
// todo with tx
然后你所有的操作都放在这个事物中执行。
这时你使用的持久层框架肯定会向MySQL发送一条命令:`begin;`或者是`start transcation;`来保证你这一组SQL中执行一条SQL后,开启的事物不会被MySQL自动帮你提交了。
其实还是推荐将这个参数设置成ON的,当然你也可以像下面这样将它关闭
mysql> set autocommit = 0;
但是关闭它之后,MySQL不会帮你自动提交事物,全靠研发同学自己来维护就容易会出现长事物,在内存中产生一个极其长的undo log链条。坏处多多。
todo 关于长事物,你可以看白日梦的这篇笔记:
三、简单看下两阶段提交的流程#
放一个整体流程的参考对照图
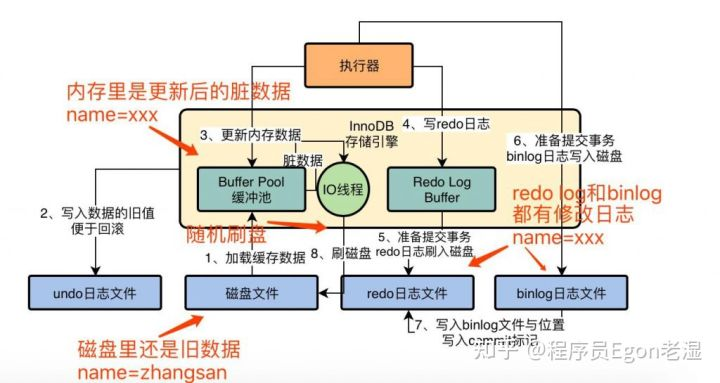
了解了什么是事物,再来看下什么是两阶段提交。其实所谓的两阶段就是把一个事物分成两个阶段来提交。就像下图这样。
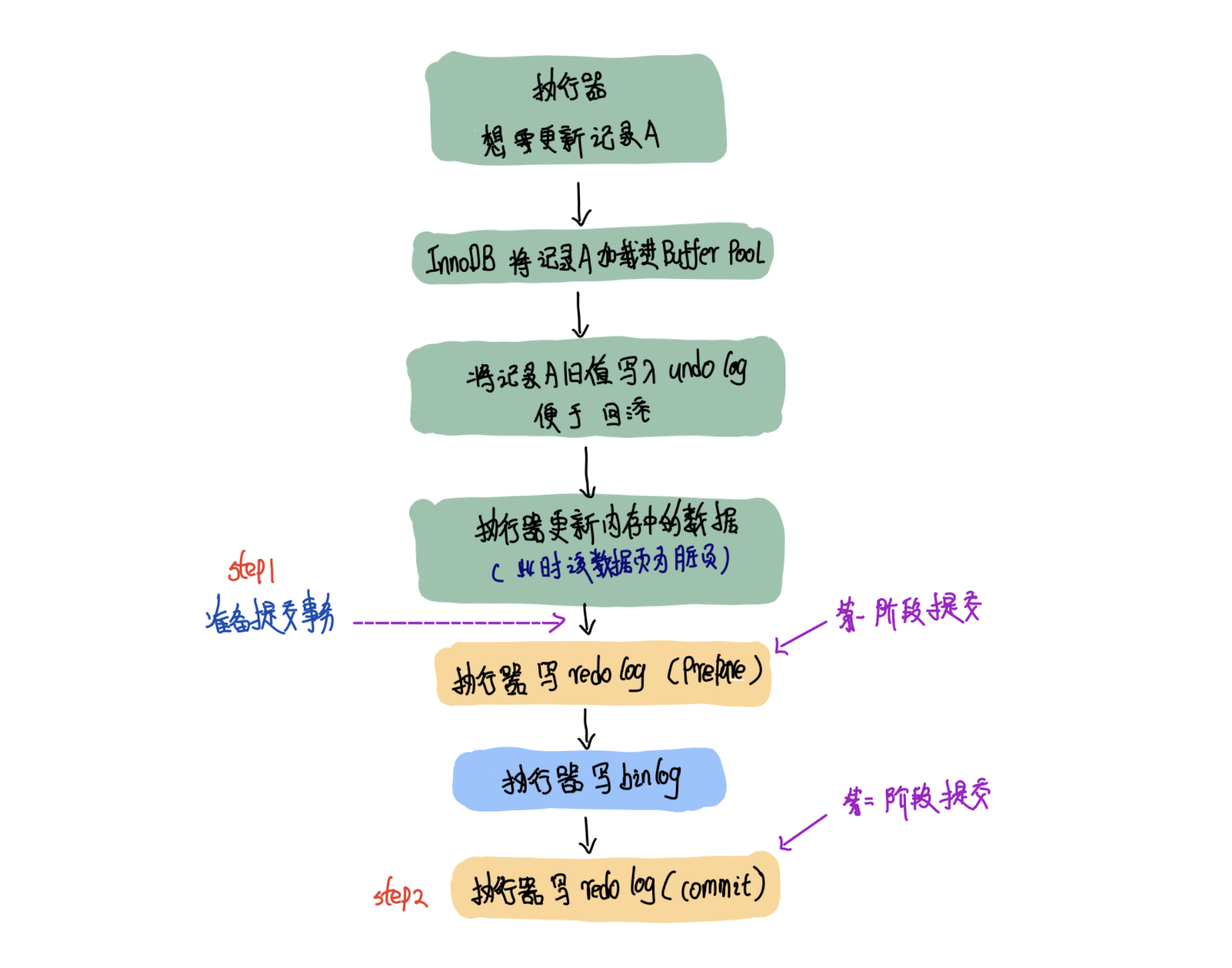
上图为两阶段提交的时序图。
你可以粗略的观察一下上图,MySQL想要准备事务的时候会先写redolog、binlog分成两个阶段。
两阶段提交的第一阶段 (prepare阶段):写rodo-log 并将其标记为prepare状态。
紧接着写binlog
两阶段提交的第二阶段(commit阶段):写redo-log 并将其标记为commit状态。
不了解这些日志是什么有啥用也没关系,你可以先去看我之前的系列文章。
四、两阶段写日志用意?#
你有没有想过这样一件事,binlog默认都是不开启的状态!
也就是说,如果你根本不需要binlog带给你的特性(比如数据备份恢复、搭建MySQL主从集群),那你根本就用不着让MySQL写binlog,也用不着什么两阶段提交。
只用一个redolog就够了。无论你的数据库如何crash,redolog中记录的内容总能让你MySQL内存中的数据恢复成crash之前的状态。
所以说,两阶段提交的主要用意是:为了保证redolog和binlog数据的安全一致性。只有在这两个日志文件逻辑上高度一致了。你才能放心的使用redolog帮你将数据库中的状态恢复成crash之前的状态,使用binlog实现数据备份、恢复、以及主从复制。而两阶段提交的机制可以保证这两个日志文件的逻辑是高度一致的。没有错误、没有冲突。
当然,两阶段提交能做到足够的安全还需要你合理的设置redolog和binlog的fsync的时机,而这块知识点所涉及到的参数前几篇文章已经说过。如果不记得,可以去看下。
五、加餐:sync_binlog = 1 问题#
如果你看懂了我下面说的这些话,能帮你更好的理解两阶段提交哦!纯干货!
白日梦在前面的分享binlog的文章中有跟大家提到过一个参数sync_binlog=1。这个参数控制binlog的落盘时机,并且白日梦也知道你们公司线上数据库的该参数一定被设置成了1。
我在那篇binlog文章之前,就计划好写这篇文章了。白日梦的MySQL在动笔之前已经列好了大纲,从简单到复杂,从0到1开始更新,欢迎小伙伴们关注我,持续更新中~
Notice!!! 这个参数为1时,表示当事物提交时会将binlog落盘。
现在你用15s中的时间,思考一下,蓝色句子中说的事物提交时会将binlog落盘,这个提交时,是下图中的step1时刻呢?还是step2时刻呢?
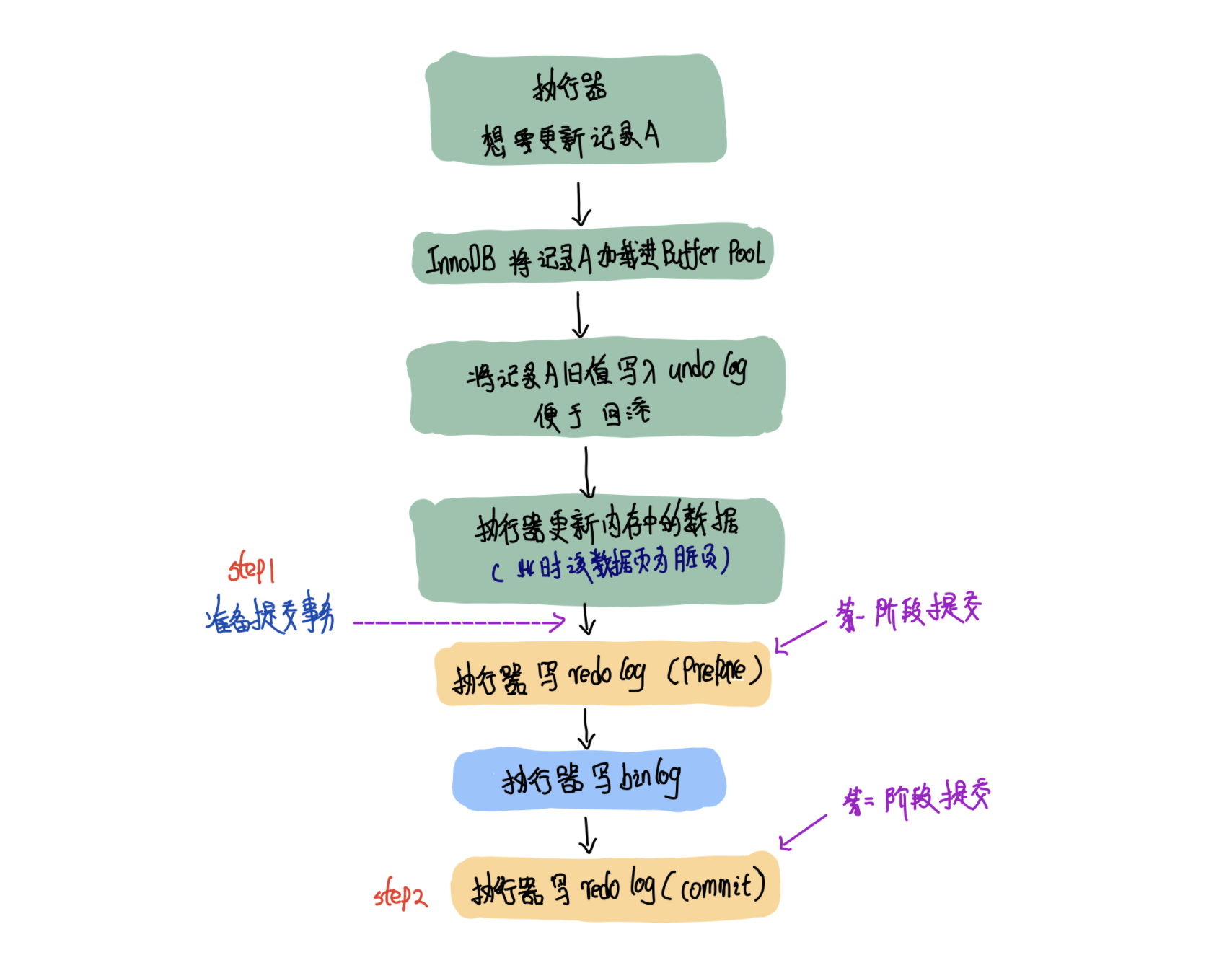
答案是:step1时刻!
知道这个知识点很重要,下面我来描述这样一个场景。
假如要执行一条update语句,那你肯定知道,先写undolog(便于后续对update事务的回滚)。然后你的update逻辑将Buffer Pool中的缓存页修改成了脏页。
当你准备提交事物时(也就是step1阶段),会写redolog,并将其标记为prepare阶段。然后再写binlog,并将binlog落盘。
然后发生了意外,MySQL宕机了。
那我问你,当你重启MySQL后,update对BufferPool中做出的修改是会被回滚还是会被提交呢?
答案是:会根据redolog将修改后的recovery出来,然后提交。
那为什么会这样做呢?
其实总的来说,不论mysql什么时刻crash,最终是commit还是rollback完全取决于MySQL能不能判断出binlog和redolog在逻辑上是否达成了一致。只要逻辑上达成了一致就可以commit,否则只能rollback。
比如还是上面描述的场景,binlog已经写了,但是MySQL最终选择了回滚。那代表你的binlog比BufferPool(或者Disk)中的真实数据多出一条更新,日后你用这份binlog做数据恢复,是不是结果一定是错误的?
六、如何判断binlog和redolog是否达成了一致#
这个知识点可是纯干货!
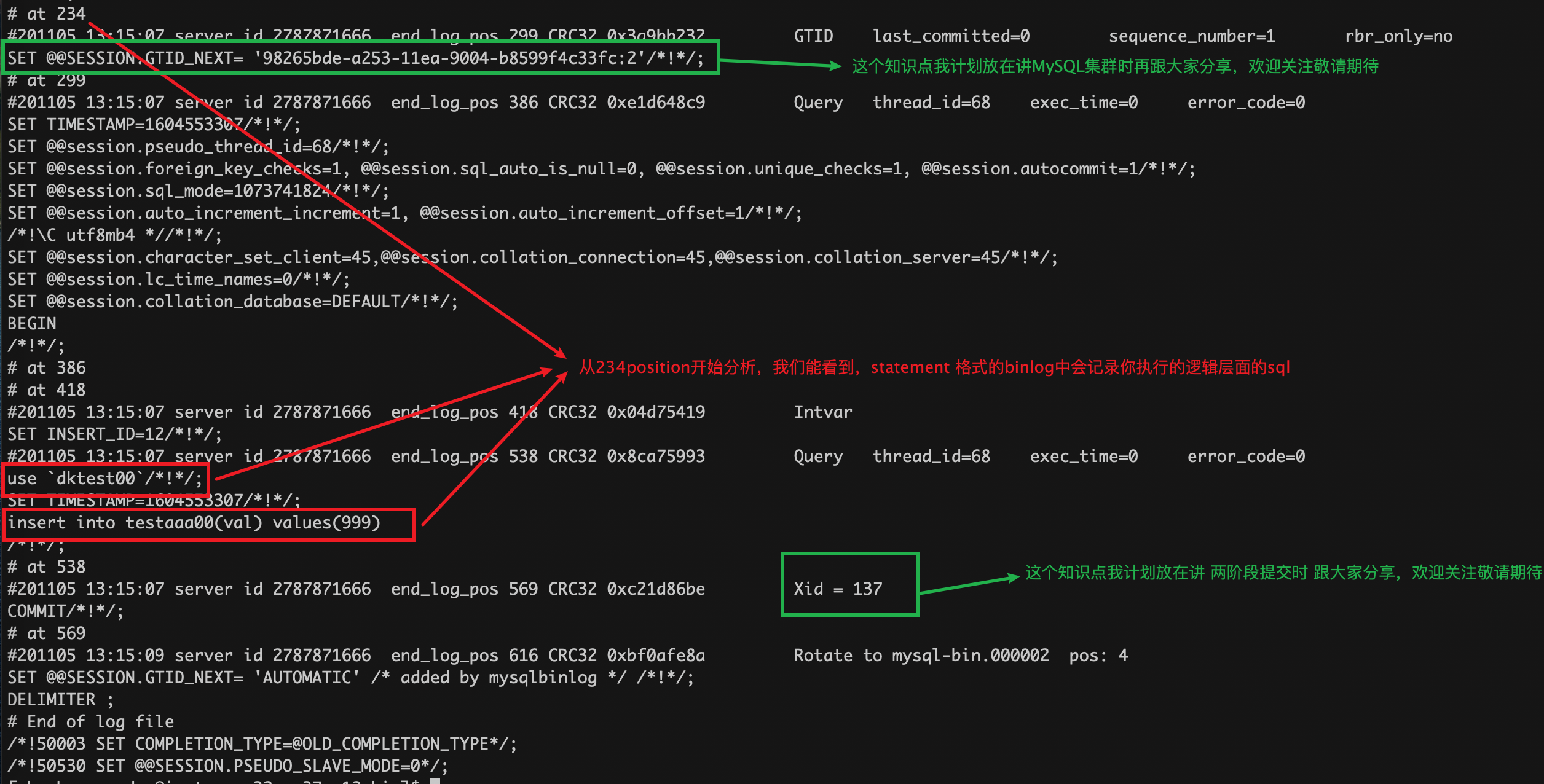
当MySQL写完redolog并将它标记为prepare状态时,并且会在redolog中记录一个XID,它全局唯一的标识着这个事务。而当你设置`sync_binlog=1`时,做完了上面第一阶段写redolog后,mysql就会对应binlog并且会直接将其刷新到磁盘中。
下图就是磁盘上的row格式的binlog记录。binlog结束的位置上也有一个XID。
只要这个XID和redolog中记录的XID是一致的,MySQL就会认为binlog和redolog逻辑上一致。就上面的场景来说就会commit,而如果仅仅是rodolog中记录了XID,binlog中没有,MySQL就会RollBack
七、两阶段提交设计的初衷 - 分布式事务#
其实两阶段提交更多的被使用在分布式事务的场景。
我用大白话描述一个这样的场景,大家自行脑补一下:
MySQL单机本来是支持事务的,但是这里所谓的分布式事务实际上指的是跨数据库、跨集群的事务。比如说你公司的业务太火爆了,每天都产生大量的数据,这些数据不仅单表存不下,甚至单库都存不下了(已经达到了服务器硬件存储的瓶颈)
那你怎么办?是不是只能将单库拆分成多库?
那你拆分成多库就会面临这样一个新的问题。假设Tom给Jerry转账,但是由于你拆分了数据库,原本在同库同表上的Tom和Jerry的信息,被你拆分进A库a表和B库b表。那你再发起转账逻辑时,万一失败了。如何回滚保证数据的安全?这就是分布式事务的要解决的问题。
通常各大公司都有自己的支持分布式事务中间件,中间件的作用本质上就是处理好各个数据库节点之间两阶段提交的问题。
简单来说:就是中间件要协调各个数据节点。
第一阶段:中间件告诉各数据库节点,让它们开启XA事务,然后判断所有数据库节点是否已经处于prepare状态
第二阶段:中间件判断事务提交还是回滚的阶段。如果所有节点都prepare那就统一提交。但凡出现一个失败的节点,统一回滚。
这里只是稍微提及一下:两阶段提交和分布式事务的渊源。
白日梦后续计划还会有文章中进一步跟大家详细的分享分布式事务话题。
八、再看MySQL两阶段写日志#
那我们再将思路拉回到MySQL两阶段写日志的话题。
其实说到这里,你大概也能直接想到,其实上一篇文章中的两阶段提交,表面上其实就是两阶段写入日志。
通过我前面的描述,你也一定知道了两份日志文件逻辑对齐的标记是有一份相同的XID。
就是这种两阶段的机制保证了两个日志(在分布式事务中就是多个数据节点)在逻辑上能达到一致的效果。
九、留一个彩蛋#
如果你仔细想一下,上面第三部分在分享 sync_binlog=1 加餐时,我所描述的示例场景其实是适用于单机MySQL的简单场景。
其实这个场景还能再复杂一些!
串联MySQL集群、将同步、半同步、异步的主从复制关系以及这里的两阶段提交、日志的落盘时机、幽灵事务!结合成一个场景效果会更好。
但是我将它放在《为研发同学定制的面试指南》排期的后半部分也就是MySQL集群部分。让我们从易到难过度过去! 欢迎关注白日梦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号