Hadoop、Spark——完全分布式HA集群搭建
前言
完全分布式就是把Hadoop核心组件分开部署到不同的服务器节点上运行。
通常,建议HDFS和YARN以单独的用户身份运行。在大多数安装中,HDFS进程以“hdfs”执行。YARN通常使用“yarn”帐户。
hadoopHA集群的工作机制如下图:
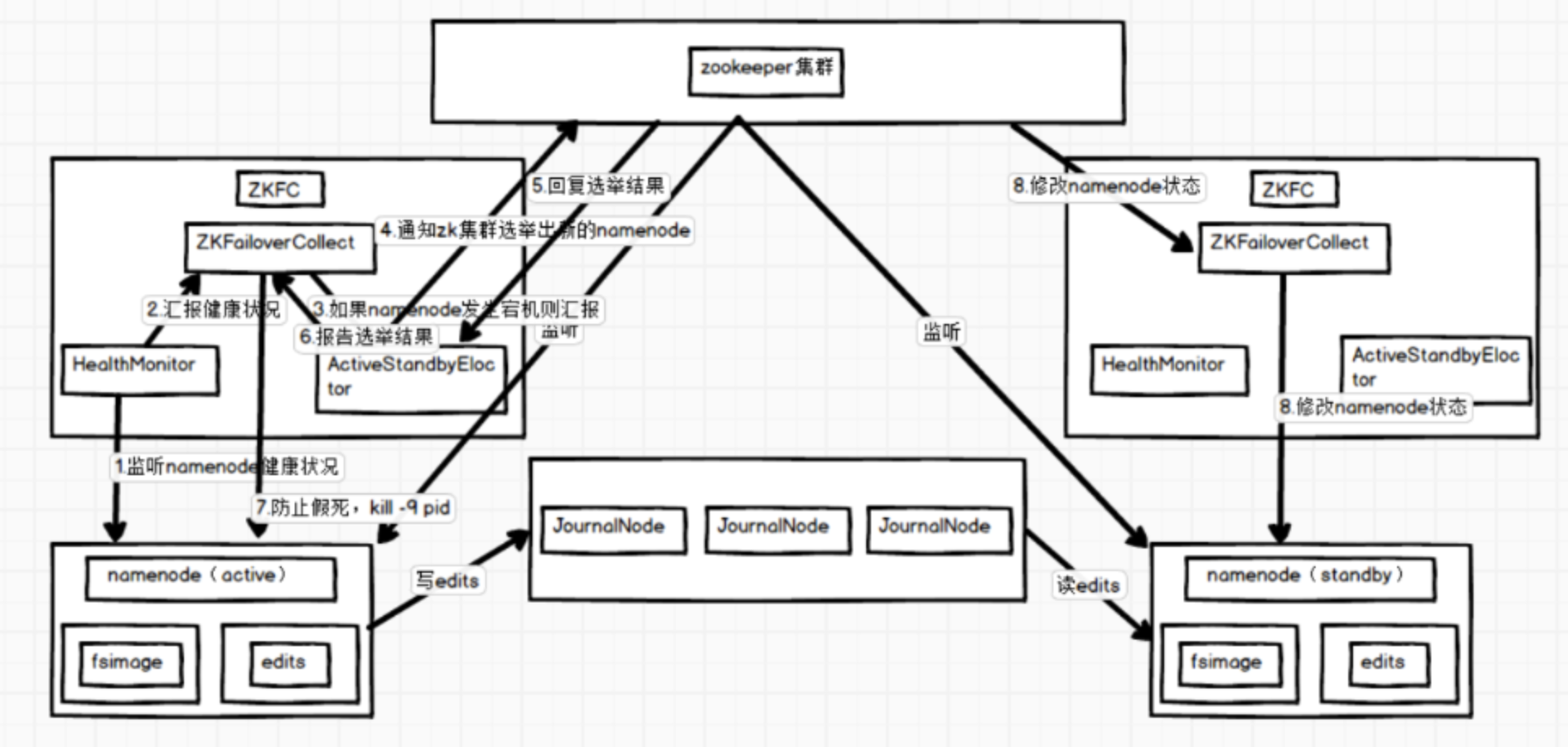
Hadoop HA集群总体上可以分为三部分:NameNode集群、JournalNode集群和Zookeeper集群。NameNode在某一时刻只有一个处于活跃状态,其他的都处于standby状态;JournalNode负责把edits文件传到standby的NameNode上;Zookeeper负责监控NameNode宕机情况,ZKFC(ZookeeperFailoverController)是专门监控NameNode健康的。
为了同步NameNode的元数据一致,有专门的JournalNode来同步元数据文件,活跃的NameNode的edits文件会写入journalnode集群,其他standby的结点会去读取journalnode上的edits文件,以此来同步自身的元数据。
详细过程如下:
1、ZKFC的HealthyMonitor是监控NameNode的进程,是专门监控NameNode将康情况的进程。
2、HealthyMonitor会定时向ZKFC进程报告NameNode情况。
3、当HealthyMonitor出现汇报了NameNode,ZKFC就会向AcitveStandbyEloctor报告。
4、AcitveStandbyEloctor接到NameNode宕机报告就会通知zk集群选举出新的NameNode。
5、zk集群经过内部选举,返回一个standby的NameNode给AcitveStandbyEloctor。
6、AcitveStandbyEloctor想ZKFC报告选举结果。
7、ZKFC为了防止是网络原因导致NameNode假死,就会结束NameNode进程。
8、zk集群就会通知另一个ZKFC要求它修改它监控的NameNode的进程为活跃节点。


在Hadoop 1.x的时候,NameNode存在单点故障问题。如果NameNode进程或者所在的机器有故障,会导致整个集群不可用,直到NameNode进程重启或者所在的机器恢复。在hadoop 2.x之后,增加了NameNode的HA机制。即在一个HDFS集群中运行两个NameNode节点,一个是Active状态的,一个是Standby状态的。当Active状态的NameNode挂掉后,Standby状态的NameNode会切换成Active状态。 NameNode的HA架构如上图 涉及到几个主要角色如下: Active NameNode: 与Standby NameNode形成互备,只有处于Active状态的NameNode节点才能对外提供读写服务。 Standby NameNode: 承接原来SecondaryNameNode的checkpoint功能。Standby NameNode从JN拉取edit log,合并到自己的fsimage上。在Active NameNode故障时,Standby会切换成Active状态。 JournalNode: 必须奇数个节点(3,5,7…),至少3个节点。当有N个JN时,可以允许(N-1)/2个NameNode发生故障。Active NameNode发送edit log到JN的绝大部分节点上。 ZKFailoverController: ZKFC作为独立的进程运行,对NameNode的主备切换进行总体控制。每个运行NameNode的机器上,都需要同时运行一个ZKFC。ZKFC定期监测它本机的NameNode的健康状态,会与Zookeeper之间维护一个session,当本机的NameNode是Active状态时,会把某个znode“加锁”(创建znode)。如果session过期,这个znode会被删除。当其他ZKFC看到这个znode不存在,会去请求“加锁”(创建znode),如果成功“加锁”,也就是所谓的赢得了选举(won the election),它所在机器上的NameNode成为了Active状态。当然,NameNode也支持不依赖Zookeeper的手动主备切换。 DataNode: 同时向Active NameNode和Standby NameNode上报数据块位置信息和心跳包。 Zookeeper: ZKFC和Zookeeper之间维护了一个session,如果NameNode挂掉了,会使session失效,进而导致Zookeeper上保存的lock znode被删除,而ZKFC就是通过这个znode来进行Active NameNode选举。
搭建分为四个阶段,每一个是环境准备,第二个是Zookeeper集群的搭建,第三是Hadoop集群的搭建,第四是Spark集群的搭建。
一、准备
1、软件及版本
- centOS-7.3.1611
- jdk1.8.0_131
- scala-2.11.11.tgz(可选)
- zookeeper-3.4.10.tar.gz
- hadoop-2.10.1.tar.gz
- spark-2.4.8-bin-hadoop2.7.tgz
软件包下载:
链接: https://pan.baidu.com/s/1WS10UlQ6sN_W5ZX5k1cYMA 提取码: 854q
2、服务器
这里将使用六台服务器进行搭建。分别命名spark01、spark02、spark03、spark04、spark05、spark06。
机器数为6台,但因为分布式算法的需要,集群通常部署在奇数台服务器上,所有主机共用上述6台机器,如下角色划分
1、Zookeeper集群分配三台。
2、Hadoop分配需要分开说:
2.1、HDFS:两个主节点,三个从节点,5台。
2.2、JN集群:三台
2.3、Yarn集群:两个主节点,三个从节点,5台。
3、Spark集群分配三台。
将以上各个集群的节点合并,具体分配如下:
| 机器名 | IP | 节点应用 |
|---|---|---|
| spark01 |
192.168.234.21
|
Zookeeper、NameNode(active)、ResourceManager(active) |
| spark02 |
192.168.234.22
|
Zookeeper、NameNode(standby) |
| spark03 |
192.168.234.23
|
Zookeeper、ResourceManager(standby) |
| spark04 |
192.168.234.24
|
JournalNode、DataNode、NodeManager、Spark |
| spark05 |
192.168.234.25
|
JournalNode、DataNode、NodeManager、Spark |
| spark06 |
192.168.234.26
|
JournalNode、DataNode、NodeManager、Spark |
-
服务器设置
每台服务器都要进行如下的配置。
1、关闭防火墙与selinux
systemctl stop firewalld systemctl disable firewalld sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config setenforce 0
2、配置主机名
hostnamectl set-hostname xxx
配置hosts
vim /etc/hosts # 填入以下内容 127.0.0.1 localhost ::1 localhost 192.168.234.21 spark01 192.168.234.22 spark02 192.168.234.23 spark03 192.168.234.24 spark04 192.168.234.25 spark05 192.168.234.26 spark06
配置好此文件之后可以通过远程命令将配置好的hosts文件scp到其他5台节点上,执行命令如下:
scp /etc/hosts spark02: /etc/hosts scp /etc/hosts spark03: /etc/hosts scp /etc/hosts spark04: /etc/hosts scp /etc/hosts spark05: /etc/hosts scp /etc/hosts spark06: /etc/hosts
-
配置免密登录
集群中所有主机都要互相进行免密登录,包括自己和自己。
生成密钥: ssh-keygen 发送公钥: ssh-copy-id root@spark01 此时在远程主机的/root/.ssh/authorized_keys文件中保存了公钥,在known_hosts中保存了已知主机信息,当再次访问的时候就不需要输入密码了。 通过以下命令远程连接,检验是否可以不需密码连接: ssh spark01 记得免密登录一定要给本机发送。 此次集群数量,互相发送免密登录的次数为36次。
注意注意注意:做完密钥登陆后,一定要每台主机ssh root@来登陆一遍,把该输入的yes都输入完毕,保证ssh可以直接连接上,不在需要交互,否则后续hadoop脚本启服务时会出现问
- 安装Jdk
1、将jdk安装包上传、解压安装包,并更名,命令如下:
tar -zxvf jdk-8u65-linux-x64.tar.gz
mv jdk1.8.0_65 jdk1.8
2、修改/etc/profile, 在文件行尾加入以下内容后保存退出。
JAVA_HOME=/home/software/jdk1.8/
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH
- 安装Scala
1、上传解压scala-2.11.0.tgz,并更名,命令如下:
tar -zxvf scala-2.11.0.tgz
mv scala-2.11.0 scala2.11
2、修改/etc/profile,配置如下:

注:上图将Hadoop的环境变量也一起配置了,下面也有Hadoop的环境变量配置。
3、重新加载profile使配置生效:
source /etc/profile
ps:java、python、scala介绍
下面只是说说spark研发团队为什么选择scala,不是对比语言好坏。 第一:java与scala 1、当涉及到大数据Spark项目场景时,Java就不太适合,与Python和Scala相比,Java太冗长了,一行scala可能需要10行java代码。 2、当大数据项目,Scala支持Scala-shell,这样可以更容易地进行原型设计,并帮助初学者轻松学习Spark,而无需全面的开发周期。但是Java不支持交互式的shell功能。 第二:Python与Scala 虽然两者都具有简洁的语法,两者都是面向对象加功能,两者都有活跃的社区。 1、Python通常比Scala慢,Scala会提供更好的性能。 2、Scala是static typed. 错误在编译阶段就抛出,它使在大型项目中开发过程更容易。 3、Scala基于JVM,因为Spark是基于Hadoop的文件系统HDFS的。 Python与Hadoop服务交互非常糟糕,因此开发人员必须使用第三方库(如hadoopy)。 Scala通过Java中的Hadoop API来与Hadoop进行交互。 这就是为什么在Scala中编写本机Hadoop应用程序非常简单。 总之:选择哪种语言,要看作者的个人想法着重点,当然想“玩”spark,python也是非常好的。 Spark专注于数据的"transformation"和"mapping"的概念,这非常适合于完美支持像scala这样的概念的功能编程语言。 另外scala在JVM上运行,这使得更容易集成hadoop、YARN等框架。
二、Zookeeper完全分布式搭建
- 为什么要部署ZooKeeper
可以通过ZooKKeeper完成Hadoop NameNode的监控,发生故障时做到自动切换,从而达到高可用
部署在spark01、spark02、spark03上即可
三、Hadoop2.0 HA集群搭建步骤
此示例以spark01节点服务器为示例。
3.1、安装
直接解压Hadoop压缩包即可。
3.2、配置
以下配置文件均在hadoop-2.7.1/etc/hadoop目录下。
-
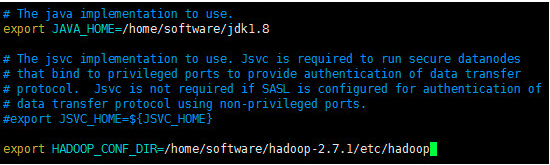
hadoop-env.sh
编辑hadoop-env.sh文件,命令如下:
cd hadoop-2.10.1/
vim etc/hadoop/hadoop-env.sh
此文件配置两项:jdk安装所在目录、hadoop配置文件所在目录。
- core-site.xml
直接编辑core-site.xml文件,命令如下:
vim etc/hadoop/core-site.xml
此文件配置项内容如下:
<configuration>
<!--用来指定hdfs的老大,ns为固定属性名,此值可以自己设置,但是后面的值要和此值对应,表示两个namenode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
<!--执行zookeeper地址,如果之前修改过zookeeper的clientPort,此处务必注意-->
<property>
<name>ha.zookeeper.quorum</name>
<value>spark01:2181,spark02:2181,spark03:2181</value>
</property>
</configuration>
- hdfs-site.xml
直接编辑hdfs-site.xml文件,命令如下:
vim etc/hadoop/hdfs-site.xml
配置内容如下:
<configuration> <!--执行hdfs的nameservice为ns,和core-site.xml保持一致--> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!--ns下有两个namenode,分别是nn1,nn2--> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!--nn1的RPC通信地址--> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>spark01:9000</value> </property> <!--nn1的http通信地址--> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>spark01:50070</value> </property> <!--nn2的RPC通信地址--> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>spark02:9000</value> </property> <!--nn2的http通信地址--> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>spark02:50070</value> </property> <!--指定namenode的元数据在JournalNode上的存放位置,这样,namenode2可以从jn集群里获取最新的namenode的信息,达到热备的效果--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://spark04:8485;spark05:8485;spark06:8485/ns</value> </property> <!--指定JournalNode存放数据的位置--> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/software/hadoop-2.7.1/journal</value> </property> <!--开启namenode故障时自动切换--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--配置切换的实现方式--> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置隔离机制--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--配置隔离机制的ssh登录秘钥所在的位置--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--配置namenode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径--> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/namenode</value> </property> <!--配置datanode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径--> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/datanode</value> </property> <!--配置block副本数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件,生产环境不配置此项,默认为true--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
- mapred-site.xml
需要复制mapred-site.xml.template更名为mapred-site.xml然后配置,命令如下:
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vim etc/hadoop/mapred-site.xml
配置内容如下:
<configuration> <property> <!--指定mapreduce运行在yarn上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
- yarn-site.xml
直接编辑yarn-site.xml文件,命令如下:
vim etc/hadoop/yarn-site.xml
配置内容如下:
<configuration> <!-- 开启YARN HA --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定两个resourcemanager的名称 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 配置rm1,rm2的主机 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>spark01</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>spark03</value> </property> <!--开启yarn恢复机制--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--执行rm恢复机制实现类--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!-- 配置zookeeper的地址,如果之前修改过zookeeper的clientPort,此处务必注意 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>spark01:2181,spark02:2181,spark03:2181</value> <description>For multiple zk services, separate them with comma</description> </property> <!-- 指定YARN HA的名称 --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property> <!--指定yarn的老大 resoucemanager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>spark03</value> </property> <!--NodeManager获取数据的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--开启日志聚合--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--日志在HDFS上最多保存多长时间--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> </configuration>
<configuration> <!-- rm失联后重新链接的时间 --> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <!-- 启用RM高可用 --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> <description>启动Yran HA模式</description> </property> <property> <!-- 指定两台RM主机名标识符 --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> <description>resourcemanager id</description> </property> <property> <!--Ha功能,需要一组zk地址,用逗号分隔。被ZKFailoverController使用于自动失效备援failover。 --> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>Zookeeper 队列</description> </property> <property> <!--开启失效转移 --> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> <description>开启 ResourceManager 故障自动切换</description> </property> <property> <!-- 指定rm1的主机名--> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> <description>rm1 的hostname</description> </property> <property> <!-- 指定rm2的主机名--> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave1</value> <description>rm2 的hostname</description> </property> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <description>本机的rmid</description> </property> <property> <!-- RM故障自动恢复 --> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!-- 被RM用于状态存储的ZooKeeper服务器的主机:端口号,多个ZooKeeper的话使用逗号分隔。 --> <name>yarn.resourcemanager.zk-state-store.address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <!-- 配置RM状态信息存储方式,有MemStore和ZKStore。 --> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <!--使用ZK集群保存状态信息,指定zookeeper队列 --> <name>yarn.resourcemanager.zk-address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>my-yarn</value> <description>集群ID</description> </property> <property> <!-- schelduler失联等待连接时间,以毫秒为单位--> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <description>以下开始对 rm1 进行配置,rm2 改成对应的值!!!</description> <property> <!-- 客户端通过该地址向RM提交对应用程序操作 --> <name>yarn.resourcemanager.address.rm1</name> <value>master:8032</value> </property> <property> <!--ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。 --> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>master:8030</value> </property> <property> <!-- RM HTTP访问地址,查看集群信息--> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master:8088</value> </property> <property> <!-- NodeManager通过该地址交换信息 --> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>master:8031</value> </property> <property> <!--管理员通过该地址向RM发送管理命令 --> <name>yarn.resourcemanager.admin.address.rm1</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>master:23142</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>slave1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>slave1:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave1:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>slave1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>slave1:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>slave1:23142</value> </property> <property> <!-- 为了能够运行MapReduce程序,需要让各个NodeManager在启动时加载shuffle server,shuffle server实际上是Jetty/Netty Server,Reduce Task通过该server从各个NodeManager上远程拷贝Map Task产生的中间结果。下面增加的两个配置均用于指定shuffle serve。 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <!--中间结果存放位置,类似于1.0中的mapred.local.dir。注意,这个参数通常会配置多个目录,已分摊磁盘IO负载 --> <name>yarn.nodemanager.local-dirs</name> <value>/home/hadoop/hadoop-2.9.0/data/nm</value> </property> <property> <!-- yarn node 运行时日志存放地址,记录container日志,并非nodemanager日志存放地址 --> <name>yarn.nodemanager.log-dirs</name> <value>/home/hadoop/hadoop-2.9.0/log/yarn</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>23080</value> </property> <property> <!-- 以轮训方式寻找活动的RM所使用的类--> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name> <value>/yarn-leader-election</value> </property> <property> <!-- 每使用一个物理cpu,可以使用的虚拟cpu的比例,默认为2--> <name>yarn.nodemanager.vcores-pcores-ratio</name> <value>1</value> </property> <property> <!-- 每单位的物理内存总量对应的虚拟内存量,默认是2.1,表示每使用1MB的物理内存,最多可以使用2.1MB的虚拟内存总量。--> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5.2</value> </property> <!-- (2)yarn.nodemanager.vmem-pmem-ratio 任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1 (3) yarn.nodemanager.pmem-check-enabled 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 (4) yarn.nodemanager.vmem-check-enabled 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <!-- 表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数 --> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> <property> <!-- 表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节>点的物理内存总量。 --> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <!-- 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数 --> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <!-- 单个任务可申请的最多物理内存量,默认是8192(MB)。 默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制 --> <name>yarn.scheduler.maximum-allocation-mb</name> <value>1024</value> </property> </configuration> 补充: 1、yarn监控nodemanager的运行状况 Hadoop提供了一种机制,管理员可以通过该机制定期运行管理员提供的脚本以确定节点是否健康。 管理员可以通过在脚本中执行对其选择的任何检查来确定节点是否处于正常状态。如果脚本检测到节点处于不健康状态,则必须以字符串ERROR开头的标准输出行。NodeManager定期生成脚本并检查其输出。如果脚本的输出包含字符串ERROR,如上所述,节点的状态将报告为运行状况不佳并且ResourceManager将节点列入黑名单。不会为此节点分配其他任务。但是,NodeManager继续运行脚本,因此如果节点再次变得健康,它将自动从ResourceManager上的黑名单节点中删除。如果节点不健康,则可以在ResourceManager Web界面中为管理员提供节点的运行状况以及脚本的输出。自节点健康以来的时间也显示在Web界面上。 以下参数在yarn.site.xml配置 参数 值 说明 yarn.nodemanager.health-checker.script.path 节点健康脚本 用于检查节点健康状况的脚本。 yarn.nodemanager.health-checker.script.opts 节点健康脚本选项 用于检查节点健康状态的脚本选项。 yarn.nodemanager.health-checker.interval-ms 节点健康脚本间隔 运行健康脚本的时间间隔。 yarn.nodemanager.health-checker.script.timeout-ms 节点运行状况超时间隔 健康脚本执行超时。 如果只有部分本地磁盘变坏,则运行状况检查程序脚本不应该给出错误。NodeManager能够定期检查本地磁盘的运行状况(具体检查nodemanager-local-dirs和nodemanager-log-dirs),并在达到配置属性yarn.nodemanager.disk-health-checker.min-healthy-disks设置的错误目录数阈值,整个节点被标记为运行状况不佳,此信息也会发送给资源管理器。引导磁盘被突袭或健康检查程序脚本识别引导磁盘中的故障。
- slaves
slaves文件是指定HDFS上有哪些DataNode节点。
直接编辑slaves文件,命令如下:
vim etc/hadoop/slaves
配置内容如下:
spark04
spark05
spark06
3.3、环境变量
如果在上面已经配置过了,此步骤可以忽略。
配置hadoop的环境变量,命令如下:
vim /etc/profile
内容如下:
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.3
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH HADOOP_HOME
重新加载:
source /etc/profile
3.4、创建文件夹
根据配置文件,创建相关的文件夹,用来存放对应数据。
在hadoop-2.7.1目录下创建:
- journal目录。
- 创建tmp目录。
- 在tmp目录下,分别创建namenode目录和datanode目录。
命令如下:
#当前所在Hadoop根目录 mkdir journal mkdir tmp cd tmp/ mkdir namenode mkdir datanode
3.5、拷贝文件&设置环境变量
通过scp 命令,将hadoop安装目录远程copy到其他5台机器上。
比如向spark02节点传输:
scp -r hadoop-2.10.1 root@spark02:/home/software/hadoop-2.10.1
远程拷贝之前要先在其他服务器上创建对应的目录(当前主机一样的目录结构,因为配置文件中写死了),否则拷贝失败。
!!!拷贝完毕后要记得在目标主机设置环境变量
在目标主机配置hadoop的环境变量,命令如下: vim /etc/profile 内容如下: JAVA_HOME=/home/software/jdk1.8 HADOOP_HOME=/home/software/hadoop-2.7.3 PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export JAVA_HOME PATH HADOOP_HOME 重新加载: source /etc/profile
3.6、Hadoop集群启动
- 启动zookeeper集群(启动则忽略)
在Zookeeper安装目录的bin目录下执行:
zkServer.sh start
此命令需要在所有的Zookeeper节点服务器上执行,执行完成可以使用以下命令查看启动状态:
zkServer.sh status
以下是查看进程命令:
jps
- 格式化zkfc
zkfc用来做两个namenode的状态切换管理或者失败切换管理。
在运行namenode的zk的节点服务器上,Hadoop的bin目录中执行如下命令:
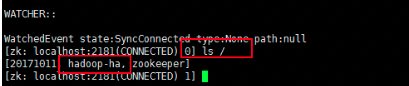
sh hdfs zkfc -formatZK
如果配置了Hadoop的环境变量,那么在此节点的任何目录下都可以执行,这个指令的作用是在zookeeper集群上生成ha节点(ns节点)。

vim /data/aicu-tob/software/zookeeper-3.4.10/conf/zoo.cfg # 添加 zookeeper.sasl.client=false
格式化以后会在Zookeeper写一些东西,现在可以看一下去(master节点):
- 启动journalnode集群
为hadoop提供元数据管理(edits)。在04、05、06任意一个节点服务器上,即分配了journalnode角色的节点服务器上,切换到hadoop安装目录的sbin目录下,执行如下命令:
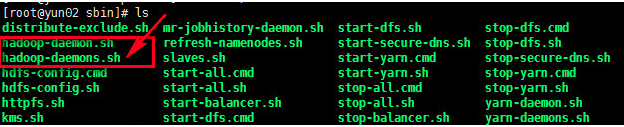
hadoop-daemons.sh start journalnode
注意:1、第一次需要手动起,以后就不需要手动启动了,就包含在了start-dfs.sh脚本里面了;
2、此命令执行一次就可以启动所有journalnode节点。如下图,命令使用的是hadoop-daemons.sh,是有s的,启动的时候一定要注意,不要用错了命令。
然后执行jps命令查看,如果此项启动不成功尝试重启,如果报ssh连接的问题Host key verification failed则手动检查每台主机的ssh密钥链接。这项启动不成功会影响下一步的格式化。
- 格式化NameNode
在spark01服务器上格式化namenode,执行如下命令:
hadoop namenode -format
- 启动NameNode
-
spark01服务器
-
在spark01节点上执行如下命令,启动NameNode节点:
hadoop-daemon.sh start namenode
可以用下述命令查看服务是否拉起,若正常拉起会显示服务名
jps
-
-
spark02服务器
-
首先把spark02服务器的 namenode节点变为standby namenode节点,执行命令如下:
hdfs namenode -bootstrapStandby
启动spark02服务器的namenode节点,执行命令如下:
hadoop-daemon.sh start namenode
- 启动DataNode
在spark04、spark05、spark06服务器上分别启动datanode节点,在这三台服务器上分别执行如下命令:
hadoop-daemon.sh start datanode
- 启动zkfc
FalioverControllerActive是失败恢复线程。这个线程需要在NameNode节点所在的服务器上启动,在spark01、spark02服务器上执行如下命令:
hadoop-daemon.sh start zkfc
- 启动Resourcemanager
-
-
spark01服务器
-
在spark01服务器上启动主Resourcemanager节点,执行如下命令:
start-yarn.sh
启动成功后,spark04、spark05、spark06服务器上的nodemanager 也会跟随启动。
-
-
spark03服务器
-
在spark03服务器上启动副 Resoucemanager节点,执行如下命令:
yarn-daemon.sh start resourcemanager
3.7、测试
访问主namenode,在浏览器中输入地址:http://192.168.234.21:50070,查看namenode的信息,是active状态的。此ip地址是我在配置的时候使用的ip地址,请不要照搬,要写自己使用的ip地址。
如果无法访问,请检查防火墙,或者端口是否方向or冲突,可以修改监听端口
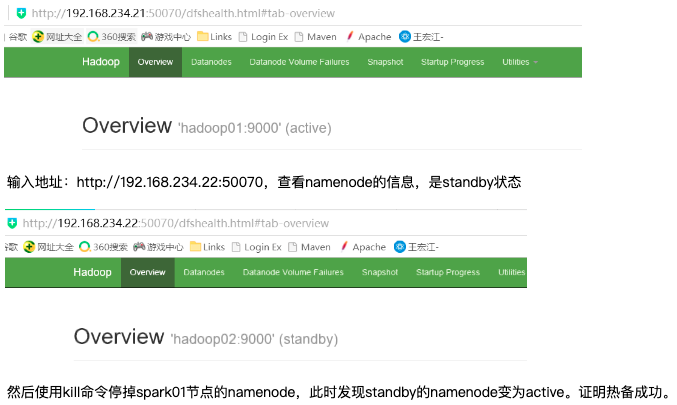
查看yarn的管理地址:
http://192.168.234.21:8088(spark01的8088端口)
四、Spark On Yarn搭建
目前Apache Spark支持一种单机模式、三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,详情参考。
- 本地模式
Spark单机运行,一般用于开发测试。
- Standalone模式
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
- Spark on Yarn模式
Spark客户端直接连接Yarn。不需要额外构建Spark集群。
- Spark on Mesos模式
Spark客户端直接连接Mesos。不需要额外构建Spark集群。
本文采用的是spark on YARM:原理见:https://www.cnblogs.com/linhaifeng/p/15919143.html#_label8
了解Spark standalone模式分布式部署:原理见:https://www.cnblogs.com/linhaifeng/p/15919143.html#_label5
1、安装
在spark04、spark05、spark06节点上安装配置spark。此处以spark04服务器为例。
直接解压压缩包即可。
2、配置
进入Spark安装目录的conf目录,配置以下文件。
-
spark-env.sh
conf目录下没有此文件,需要复制模版文件spark-env.sh.template更名,命令如下:
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
直接在文件末尾添加,内容示例如下:
export JAVA_HOME=/home/software/jdk1.8 export SCALA_HOME=/home/software/scala2.11 # 如果不依赖scala语言,则忽略 export HADOOP_HOME=/data/aicu-tob/software/hadoop-2.10.1 export HADOOP_CONF_DIR=/data/aicu-tob/software/hadoop-2.10.1/etc/hadoop #让spark知道hadoop配置文件的路径,完成spark整合hadoop export LANG="en_US.UTF-8"
-
spark-defaults.conf
此文件在目录下也没有,也需要复制模版文件,更名然后编辑,命令如下:
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
直接在文件末尾添加内容,配置示例如下:
spark.ui.port 8040 # 选配,不配置则端口默认
-
slaves
此文件在conf目录下也没有,同样需要赋值模版文件,更名然后编辑,命令如下:
cp slaves.template slaves
vim slaves
同样在文件末尾直接添加配置内容即可,配置示例如下:
spark04
spark05
spark06
-
yarn-site.xml
如果是用虚拟机搭建,可能会由于虚拟机内存过小而导致启动失败,比如内存资源过小,yarn会直接kill掉进程导致rpc连接失败。
所以,我们还需要配置Hadoop的yarn-site.xml文件,加入如下两项配置:
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property
至此spark on yarn就配置完毕。
强调!!!!
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用YARN来做为Spark的Cluster Manager,来为Spark的应用程序分配资源。
在执行Spark应用程序前,要启动Hadoop的各种服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Worker守护进程。
怕你没看见,再强调一遍:在spark-Yarn模式下,Spark自身的Master结点和Worker结点不需要启动(只有集群的Standalone方式时,才需要这两个角色),但是Spark的部署包必须是基于对应的Yarn版本正确编译后的,否则会出现Spark和Yarn的兼容性问题
https://spark-reference-doc-cn.readthedocs.io/zh_CN/latest/deploy-guide/running-on-yarn.html
所以我们在部署完spark on yarn之后不需要启动spark,只需要用spark的工具提交任务即可,在提交之前,先把相关服务重启一下
五、重启集群
往往在测试的时候,需要重新启动集群服务,在重新启动的时候,就不需要第一次配置时那么麻烦,可以按照如下步骤进行重启集群服务。
1、重启zookeeper集群
在Zookeeper安装目录的bin目录下执行:
sh zkServer.sh stop/start
此命令同样需要在所有的Zookeeper节点服务器上执行。
2、重启Hadoop集群
-
重启HDFS
进入hadoop安装目录的sbin目录,执行如下命令,此命令会将HDFS相关的所有节点都启动,不需要切换服务器来进行单独启动HDFS相关的节点进程。
stop-dfs.sh
start-dfs.sh
-
重启Yarn
-
spark01服务器
-
在spark01服务器上启动主Resourcemanager节点,执行如下命令:
stop-yarn.sh
start-yarn.sh
启动成功后,spark04、spark05、spark06服务器上的nodemanager 也会跟随启动。
-
-
spark03服务器
-
在spark03服务器上启动副 Resoucemanager节点,执行如下命令:
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh start resourcemanager
3、启动spark任务
可以通过spark shell启动任务,进入Spark安装目录的bin目录,执行如下命令,下述采用的是yarn-cient,生产环境应该采用yarn-cluster,点击查看二者区别
spark-shell --master yarn-client
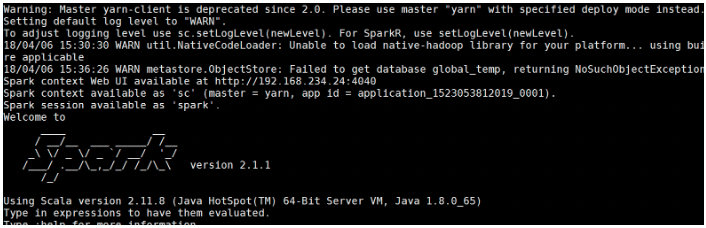
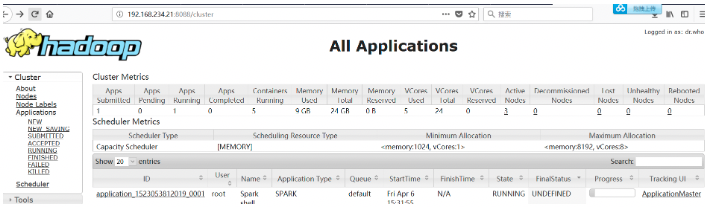
可以通过yarn控制台来验证,会发现新增一个应用正在运行,ctrl+c掉spark-shell后任务结束
如果启动spark shell时报错
spark用yarn提交任务会报
ERROR cluster.YarnClientSchedulerBackend: YARN
application has exited unexpectedly with state UNDEFINED! Check the YARN
application logs for more details.
ERROR cluster.YarnClientSchedulerBackend: Diagnostics message: Shutdown hook called before final status was reported.
只需要将hadoop集群的yarn-site.xml配置中加入如下两行即可解决:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
如果你用的java8,则多会报此错误。
如果报警告: WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME
解决方案有两种
1、方案一:
1、上传jar包 在HDFS上,创建一个目录,用来存放spark的依赖jar包。此目录是spark-defaults.conf目录中配置的目录名称,命令如下: hadoop fs -mkdir /spark_jars 进入spark安装目录的jars目录,执行下述命令上传spark的jars hadoop fs -put ./* /spark_jars 2、修改spark配置文件:spark-defaults.conf 末尾增加 spark.yarn.jars=hdfs://spark01:9000/spark_jars/* # 可以将spark运行时需要的jar包缓存在HDFS上,无需每次运行任务的时候都进行分发。 注:此处hdfs的地址需要是active状态的节点,注意访问的是hdfs,可以通过3.7小节所示的页面查看谁是active状态。 # 推荐阅读 关于Spark on Yarn运行时加载的jar包,详见https://www.yixuebiancheng.com/article/61045.html https://www.cnblogs.com/zlslch/p/7612684.html
2、方案二:
说白了,就是spark2.1.0或spark2.2.0以上的版本的命令有所变化。所以压根可以需改动解决办法1所示的配置,直接用官网这样的命令来操作就可以了。
http://spark.apache.org/docs/latest/running-on-yarn.html
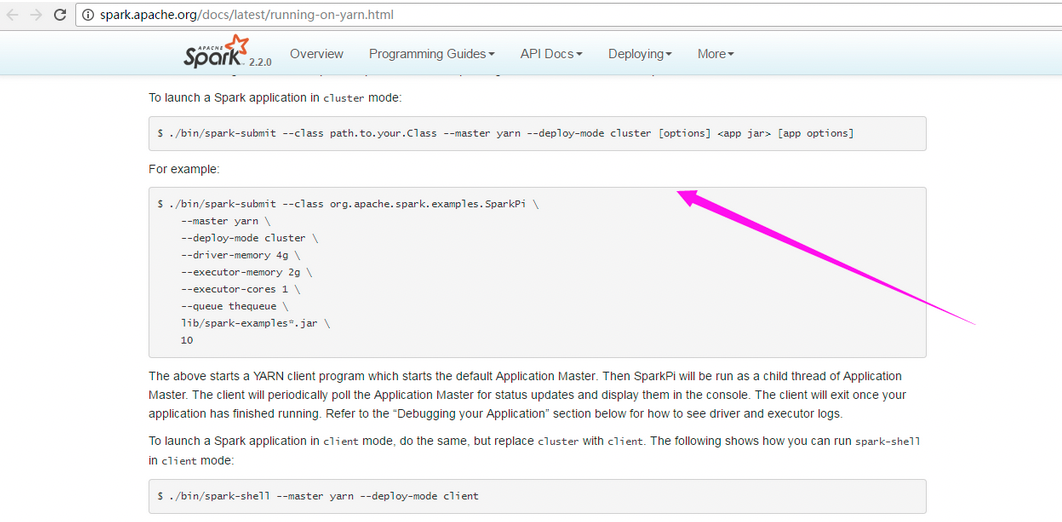
从图中得知提交任务的另外一种方式
cd /data/aicu-tob/software/spark-2.4.8-bin-hadoop2.7 # 切换到spark的安装目录下执行,因为命令引用的spark-examples_2.11-2.4.8.jar采用的相对路径,当然用绝对路径也是可以的
./bin/spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.JavaSparkPi ./examples/jars/spark-examples_2.11-2.4.8.jar 80
可以通过yarn控制台来验证
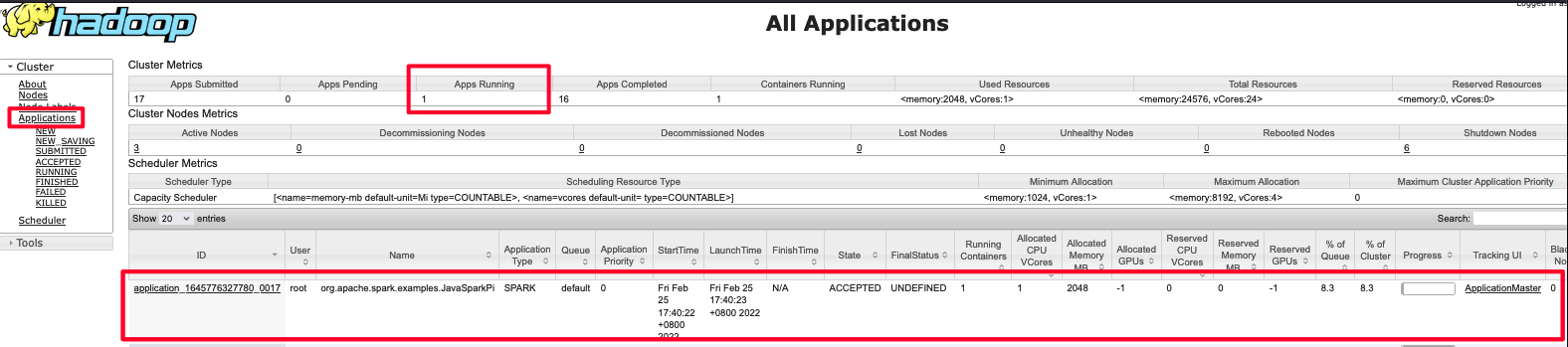
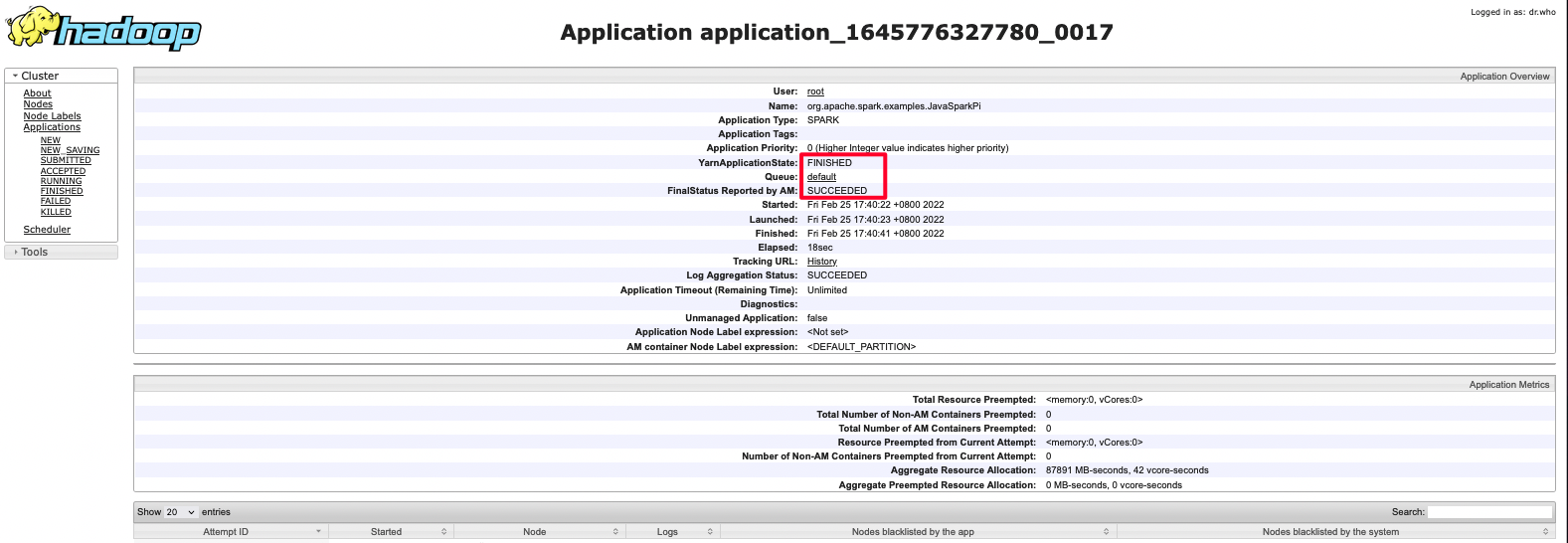
可以点击ID进去查看详情
六 开启Hadoop/Yarn的日志监控功能
配置 yarn-site.xml 开启日志聚合
日志聚集是YARN提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,且提供一个中央化存储和分析机制。默认情况下,Container/任务日志存在在各个NodeManager上
<!-- Site specific YARN configuration properties -->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 如果没有设置的话,会显示3个目录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
配置 mapred-site.xml<property>
<!-- 表示提交到hadoop中的任务采用yarn来运行,要是已经有该配置则无需重复配置 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--日志监控服务的地址,一般填写为namenode机器地址,选主namenode即可 -->
<name>mapreduce.jobhistroy.address</name>
<value>namenode主机的ip地址:10020</value>
</property>
<property>
<name>mapreduce.jobhistroy.webapp.address</name>
<value>namenode主机的ip地址:19888</value>
</property>
重启yarn
stop-yarn.sh
start-yarn.sh
开启日志监控服务进程
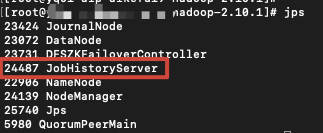
在nodenode机器上执行 sbin/mr-jobhistory-daemon.sh start historyserver 命令,执行完成后使用jps命令查看是否启动成功,若启动成功则会显示出JobHistoryServer服务
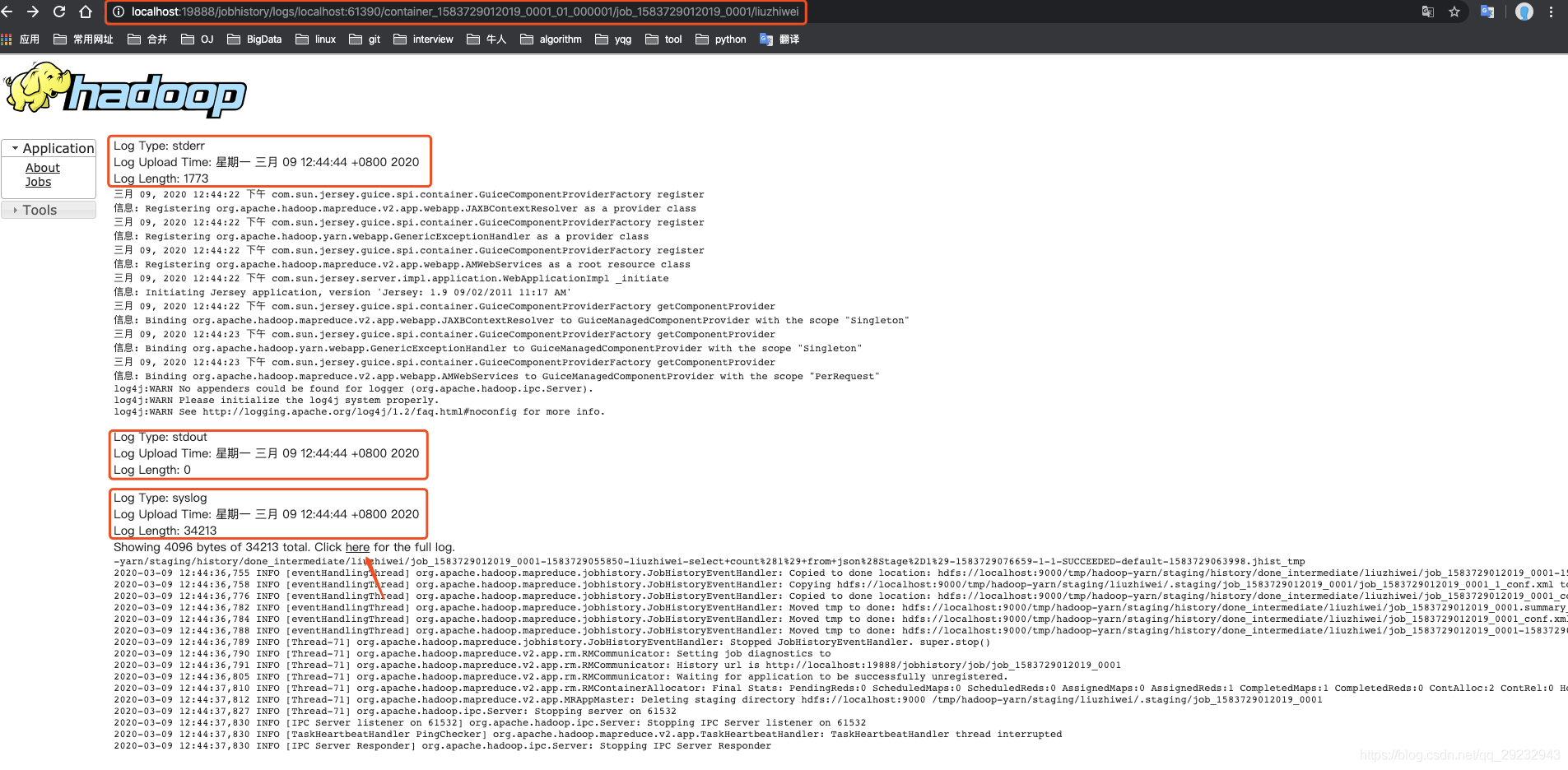
最好将yarn-site.xml 的 yarn.log.server.url也配置上
<property>
<name>yarn.log.server.url</name>
<value>http://namenode主机的ip地址:19888/jobhistory/logs</value>
</property>
不然的话这个链接跳转不到
引用:
http://www.51niux.com/?id=180
https://www.cnblogs.com/52mm/p/p13.html
https://www.daimajiaoliu.com/daima/48605606a900402
https://www.kancloud.cn/willseecloud/bigdata/2324801
hadoop原理剖析:https://www.saoniuhuo.com/article/detail-1124.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号