Kubernetes学习之路(十)pod资源
_____egon新书来袭请看:https://egonlin.com/book.html
一、什么是Pod?
K8s有很多技术概念,同时对应很多API对象,最重要的也是最基础的是微服务Pod。Pod是在K8s集群中运行部署应用或服务的最小单元。
在Kubrenetes集群中Pod有如下两种使用方式:
- 单容器:一个Pod中运行一个容器。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
- 多容器:在一个Pod中同时运行多个容器,这是一种比较高级的用法,只有当你的容器需要紧密配合协作的时候才考虑用这种模式。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
Pod对多容器的支持是K8s最基础的设计理念,多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
比如你运行一个操作系统发行版的软件仓库,一个Nginx容器用来发布软件,另一个容器专门用来从源仓库做同步,这两个容器的镜像不太可能是一个团队开发的,但是他们一块儿工作才能提供一个微服务;这种情况下,不同的团队各自开发构建自己的容器镜像,在部署的时候组合成一个微服务对外提供服务。这就是K8S中的POD。
Pod中共享的环境包括Linux的namespace,cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在Pod的环境中,每个容器中可能还有更小的子隔离环境。
Pod中的容器共享IP地址和端口号,它们之间可以通过localhost互相发现。它们之间可以通过进程间通信,需要明白的是同一个Pod下的容器是通过lo网卡进行通信。例如SystemV信号或者POSIX共享内存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
Pod中的容器也有访问共享volume的权限,这些volume会被定义成pod的一部分并挂载到应用容器的文件系统中。
就像每个应用容器,pod被认为是临时实体。在Pod的生命周期中,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。
二 pod带来的好处
1、Pod做为一个可以独立运行的服务单元,简化了应用部署的难度,以更高的抽象层次为应用部署提供了极大的方便
2、Pod做为最想的应用实例可以独立运行,因此可以方便的进行部署,水平扩展和收缩、方便进行调度管理与资源分配
3、Pod中的容器共享相同的数据和网络地址空间,Pod之间也进行了统一的资源管理与分配
三、Pod中如何管理多个容器?
Pod中可以同时运行多个进程(作为容器运行)协同工作。同一个Pod中的容器会自动的分配到同一个 node 上。同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。
注意在一个Pod中同时运行多个容器是一种比较高级的用法。只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为web服务器运行,需要用到共享的volume,有另一个“sidecar”容器来从远端获取资源更新这些文件,如下图所示:
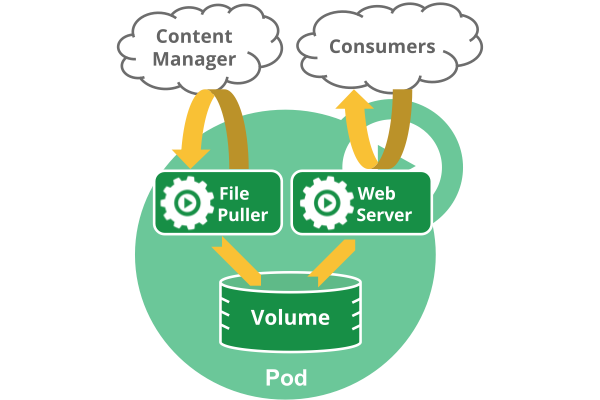
Pod中可以共享两种资源:网络和存储。
- 网络:
每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
- 存储:
可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
四、Pod的分类
通常把Pod分为两类:
- 自主式Pod :这种Pod本身是不能自我修复的,当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。Pod不会自愈。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。
# 创建自主式pod命令如下 kubectl run pod-test --image=nginx:1.8.1
- 控制器管理的Pod:Kubernetes使用更高级的称为Controller的抽象层,来管理Pod实例。Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上。虽然可以直接使用Pod,但是在Kubernetes中通常是使用Controller来管理Pod的,Controller可以提供集群级别的自愈功能、复制和升级管理。如下我们使用deployment控制器来创建pod
kubectl create deployment web --image=nginx:1.14
五、pod的组成
每个Pod都有一个特殊的被称为“根容器”的Pause 容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或者多个紧密相关的用户业务容器。
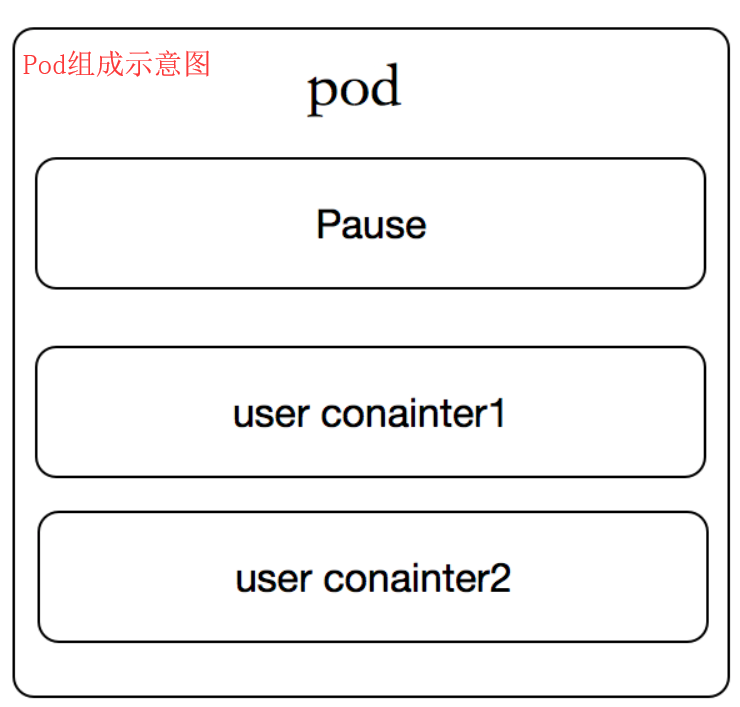
Kubernetes设计这样的Pod概念和特殊组成结构有什么用意?????
原因一:在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。比如,一个容器死亡了,此时是算整体挂了么?那么引入与业务无关的Pause容器作为Pod的根容器,以它的状态代表着整个容器组的状态,这样就可以解决该问题。
原因二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂载的Volume,这样简化了业务容器之间的通信问题,也解决了容器之间的文件共享问题。
六、Pod的持久性和终止
(1)Pod的持久性
Pod在设计支持就不是作为持久化实体的。在调度失败、节点故障、缺少资源或者节点维护的状态下都会死掉会被驱逐。通常,我们是需要借助类似于Docker存储卷这样的资源来做Pod的数据持久化的。
(2)Pod的终止
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够放松删除请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
示例流程如下:
- 用户发送删除pod的命令,默认宽限期是30秒;
- 在Pod超过该宽限期后API server就会更新Pod的状态为“dead”;
- 在客户端命令行上显示的Pod状态为“terminating”;
- 跟第三步同时,当kubelet发现pod被标记为“terminating”状态时,开始停止pod进程:
- 如果在pod中定义了preStop hook,在停止pod前会被调用。如果在宽限期过后,preStop hook依然在运行,第二步会再增加2秒的宽限期;
- 向Pod中的进程发送TERM信号;
- 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
- 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
删除宽限期默认是30秒。 kubectl delete命令支持 —grace-period=<seconds> 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 --force 和 --grace-period=0 来强制删除pod。
Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当执行强制删除命令时,API server不会等待该pod所运行在节点上的kubelet确认,就会立即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被立即设置为terminating状态,不过在被强制删除之前依然有一小段优雅删除周期。
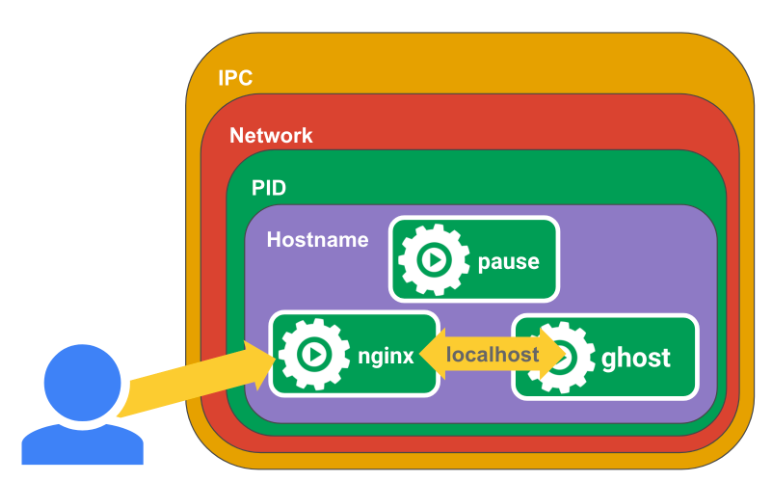
七、Pause容器
Pause容器,又叫Infra容器。我们检查node节点的时候会发现每个node上都运行了很多的pause容器,例如如下。
[root@k8s-node01 ~]# docker ps |grep pause 0cbf85d4af9e k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_myapp-848b5b879b-ksgnv_default_0af41a40-a771-11e8-84d2-000c2972dc1f_0 d6e4d77960a7 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_myapp-848b5b879b-5f69p_default_09bc0ba1-a771-11e8-84d2-000c2972dc1f_0 5f7777c55d2a k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_kube-flannel-ds-pgpr7_kube-system_23dc27e3-a5af-11e8-84d2-000c2972dc1f_1 8e56ef2564c2 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_client2_default_17dad486-a769-11e8-84d2-000c2972dc1f_1 7815c0d69e99 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_nginx-deploy-5b595999-872c7_default_7e9df9f3-a6b6-11e8-84d2-000c2972dc1f_2 b4e806fa7083 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_kube-proxy-vxckf_kube-system_23dc0141-a5af-11e8-84d2-000c2972dc1f_2
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启用pid命名空间,开启init进程。
如图:
[root@k8s-node01 ~]# docker run -d --name pause -p 8880:80 k8s.gcr.io/pause:3.1
d3057ceb54bc6565d28ded2c33ad2042010be73d76117775c130984c3718d609
[root@k8s-node01 ~]# cat <<EOF >> nginx.conf
> error_log stderr;
> events { worker_connections 1024; }
> http {
> access_log /dev/stdout combined;
> server {
> listen 80 default_server;
> server_name example.com www.example.com;
> location / {
> proxy_pass http://127.0.0.1:2368;
> }
> }
> }
> EOF
[root@k8s-node01 ~]# docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf --net=container:pause --ipc=container:pause --pid=container:pause nginx
d04f848b7386109085ee350ebb81103e4efc7df8e48da18404efb9712f926082
[root@k8s-node01 ~]# docker run -d --name ghost --net=container:pause --ipc=container:pause --pid=container:pause ghost
332c86a722f71680b76b3072e85228a8d8e9608456c653edd214f06c2a77f112
现在访问http://192.168.56.12:8880/就可以看到ghost博客的界面了。
解析
pause容器将内部的80端口映射到宿主机的8880端口,pause容器在宿主机上设置好了网络namespace后,nginx容器加入到该网络namespace中,我们看到nginx容器启动的时候指定了--net=container:pause,ghost容器同样加入到了该网络namespace中,这样三个容器就共享了网络,互相之间就可以使用localhost直接通信,--ipc=contianer:pause --pid=container:pause就是三个容器处于同一个namespace中,init进程为pause,这时我们进入到ghost容器中查看进程情况。
[root@k8s-node01 ~]# docker exec -it ghost /bin/bash root@d3057ceb54bc:/var/lib/ghost# ps axu USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 1012 4 ? Ss 03:48 0:00 /pause root 6 0.0 0.0 32472 780 ? Ss 03:53 0:00 nginx: master process nginx -g daemon off; systemd+ 11 0.0 0.1 32932 1700 ? S 03:53 0:00 nginx: worker process node 12 0.4 7.5 1259816 74868 ? Ssl 04:00 0:07 node current/index.js root 77 0.6 0.1 20240 1896 pts/0 Ss 04:29 0:00 /bin/bash root 82 0.0 0.1 17496 1156 pts/0 R+ 04:29 0:00 ps axu
在ghost容器中同时可以看到pause和nginx容器的进程,并且pause容器的PID是1。而在kubernetes中容器的PID=1的进程即为容器本身的业务进程。
八、init容器
拓展阅读:https://kubernetes.io/zh/docs/concepts/workloads/pods/init-containers/
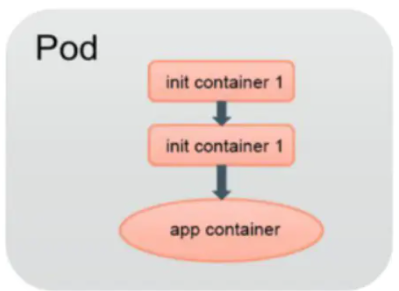
init container与应用容器在本质上是一样的,但它们是仅运行一次!!!就结束的任务,并且必须在成功执行完成后!!!,系统才能继续执行下一个容器。
根据Pod的重启策略(RestartPolicy),当init container执行失败,而且设置了RestartPolicy=Never时,Pod将会启动失败!!!;而设置RestartPolicy=Always时,Pod将会被系统自动重启。

下面以Nginx应用为例,在启动Nginx之前,通过初始化容器busybox为Nginx创建一个index.html主页文件。这里为init container和Nginx设置了一个共享的Volume,以供Nginx访问init container设置的index.html文件:
# nginx-init-containers.yaml apiVersion: v1 kind: Pod metadata: name: nginx annotations: spec: initContainers: # 这个是重点, initcontainers - name: install image: busybox command: ["/bin/sh","-c","wget -O /work-dir/index.html http://www.baidu.com"] volumeMounts: - name: workdir # volume mount mountPath: "/work-dir" containers: - name: nginx image: nginx ports: - containerPort: 80 volumeMounts: - name: workdir # nginx使用这个volume mountPath: /usr/share/nginx/html dnsPolicy: Default volumes: # volume - name: workdir emptyDir: {}
应用
kubectl apply -f nginx-init-containers.yaml # 在运行init container的过程中查看Pod的状态,可见init过程还未完成 [root@k8s-master01 init_container]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE nginx 0/1 PodInitializing 0 10s # 启动成功后,登录进Nginx容器,可以看到/usr/share/nginx/html目录下的index.html文件为init container所生成,其内容为: [root@k8s-master01 init_container]# kubectl exec nginx -it -- /bin/sh # ls /usr/share/nginx/html index.html
init container与应用容器的区别如下。
(1)init container的运行方式与应用容器不同,它们必须先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,并且只有前一个init container运行成功后才能运行后一个init container。当所有init container都成功运行后,Kubernetes才会初始化Pod的各种信息,并开始创建和运行应用容器。
(2)在init container的定义中也可以设置资源限制、Volume的使用和安全策略,等等。但资源限制的设置与应用容器略有不同。
-
如果多个init container都定义了资源请求/资源限制,则取最大的值作为所有init container的资源请求值/资源限制值。
-
Pod的有效(effective)资源请求值/资源限制值取以下二者中的较大值。
- a)所有应用容器的资源请求值/资源限制值之和。
- b)init container的有效资源请求值/资源限制值。
-
调度算法将基于Pod的有效资源请求值/资源限制值进行计算,也就是说init container可以为初始化操作预留系统资源,即使后续应用容器无须使用这些资源。
-
Pod的有效QoS等级适用于init container和应用容器。
-
资源配额和限制将根据Pod的有效资源请求值/资源限制值计算生效。
-
Pod级别的cgroup将基于Pod的有效资源请求/限制,与调度机制一致。
(3)init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行在Pod中定义的普通容器。
在Pod重新启动时,init container将会重新运行,常见的Pod重启场景如下。
- init container的镜像被更新时,init container将会重新运行,导致Pod重启。仅更新应用容器的镜像只会使得应用容器被重启。
- Pod的infrastructure容器更新时,Pod将会重启
- 若Pod中的所有应用容器都终止了,并且RestartPolicy=Always,则Pod会重启。
九、Pod的生命周期
(1)Pod phase(Pod的相位/状态)
Pod 的 status 在信息保存在 PodStatus 中定义,其中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的 phase值。
下面是 phase 可能的值:
- 挂起(Pending):API Server创建了Pod资源对象并已经存入了etcd中,但是它并未被调度完成,或者仍然处于从仓库下载镜像的过程中。
- 运行中(Running):Pod已经被调度到某节点之上,并且所有容器都已经被kubelet创建完成。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
下图是Pod的生命周期示意图,从图中可以看到Pod状态的变化。

综上,pod的创建分为两大阶段
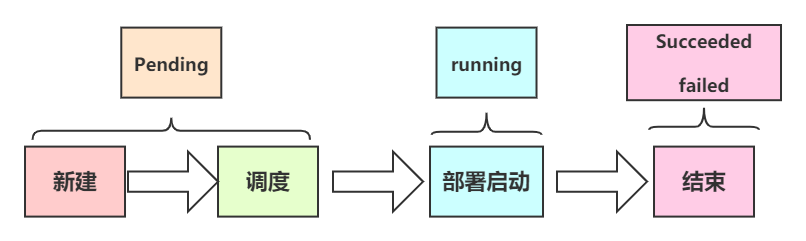
阶段1:Pending,对应的状态有

阶段2:创建,对应的状态有

(2)Pod的创建过程
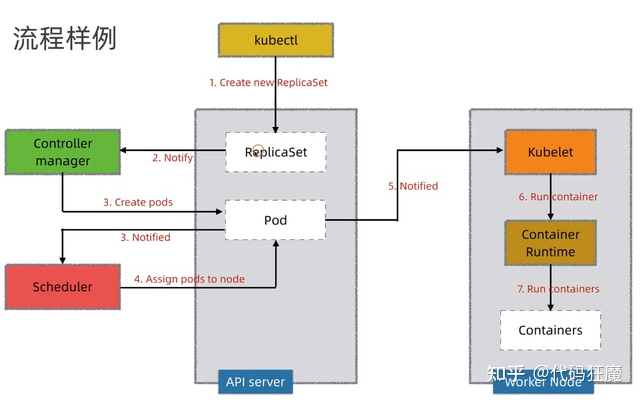
pod创建过程之各部分组件间通信
pod创建过程之kubelet组件创建pod容器
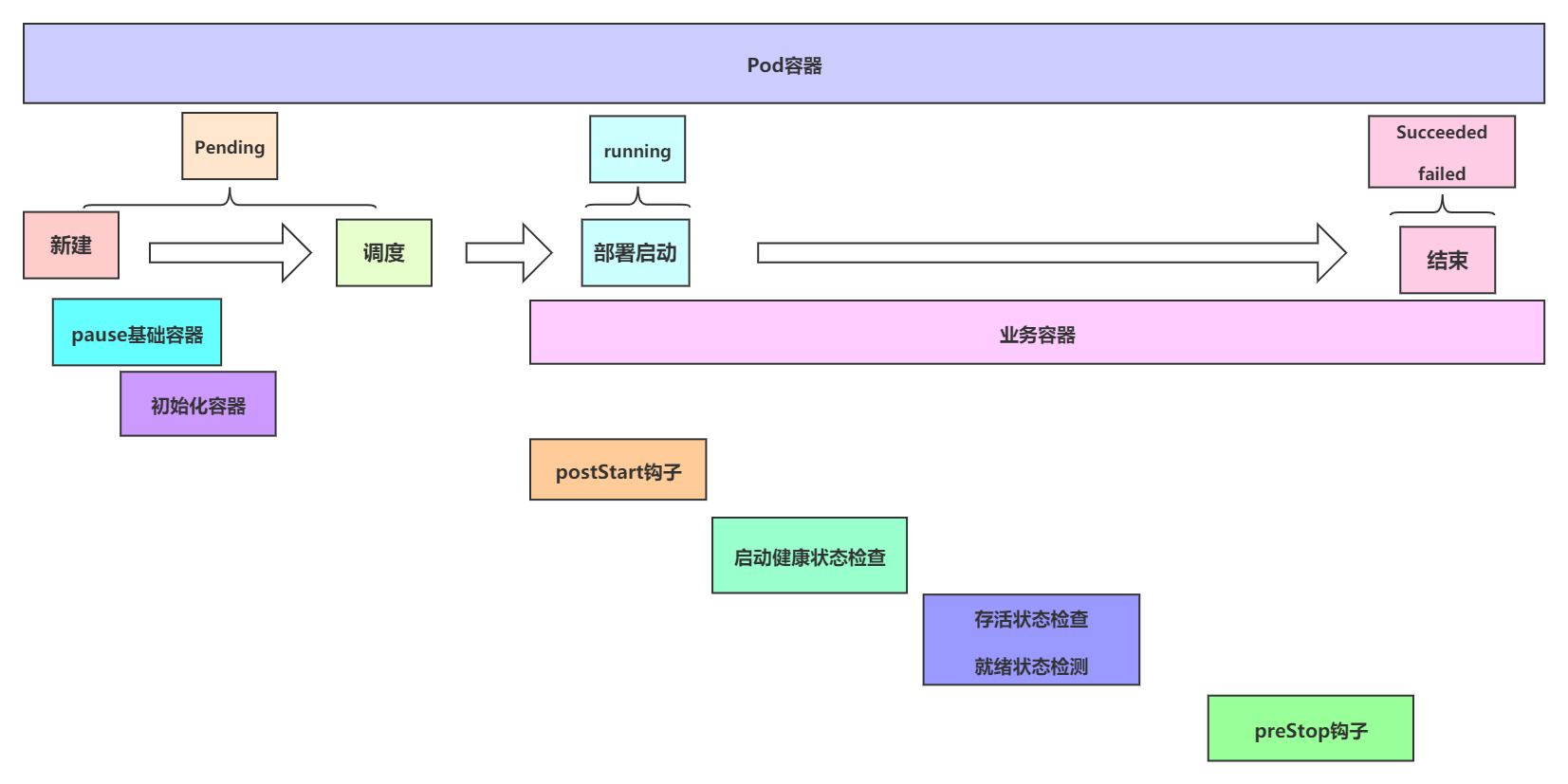
Pod是Kubernetes的基础单元,了解其创建的过程,更有助于理解系统的运作,结合上述两幅图,总结pod创建流程如下
①用户通过kubectl或其他API客户端提交Pod Spec给API Server。
②API Server尝试将Pod对象的相关信息存储到etcd中,等待写入操作完成,API Server返回确认信息到客户端。
③API Server开始反映etcd中的状态变化。
④所有的Kubernetes组件(例如controller-mananger组件,kube-scheduler组件)通过"watch"机制跟踪检查API Server上的相关信息变动。
⑤kube-scheduler(调度器)通过其"watcher"检测到API Server创建了新的Pod对象但是没有绑定到任何工作节点。
⑥kube-scheduler为Pod对象挑选一个工作节点并将结果信息更新到API Server。
⑦调度结果新消息由API Server更新到etcd,并且API Server也开始反馈该Pod对象的调度结果。
⑧Pod被调度到目标工作节点上的kubelet尝试在当前节点上调用docker engine进行启动容器,启动过程如下,并将容器的状态结果返回到API Server。
1、pause容器
启动包括初始化容器的任何容器之前先创建pause基础容器
它初始化Pod环境并为后续加入的容器提供共享的名称空间。 2、一个或多个init容器
按顺序以串行的方式运行用户定义的各个初始化init容器进行Pod环境初始化;
任何一个初始化容器运行失败都将导致Pod创建失败,并按其restartPolicy的策略进行处理,默认为重启。 3、PostStart钩子->业务容器
等待所有容器初始化成功完成后,启动业务容器或称主容器,多容器Pod环境中,此步骤会并行启动所有业务容器。
他们各自按其自定义展开其生命周期;
容器启动的那一刻会同时运行业务容器上定义的PostStart钩子事件,该步骤失败将导致相关容器被重启。 4、判断pod是否启动成功
运行容器启动健康状态监测(startupProbe),判断容器是否启动成功;
该步骤失败,同样参照restartPolicy定义的策略进行处理;未定义时,默认状态为Success。 5、pod启动成功后执行存活检测与就绪检查
容器启动成功后,定期进行存活状态监测(liveness)和就绪状态监测(readiness);
存活监测状态失败将导致容器被删除然后重启新的作为替代品
而就绪状态监测失败则会使得该容器从其所属的Service对象的可用端点列表中移除,并非干掉容器。 6、如果pod被终止则执行preStop钩子
终止Pod对象时,会想运行preStop钩子事件,并在宽限期(termiunationGracePeriodSeconds)结束后终止主容器,宽限期默认为30秒。 #简述 1、创建pod,并调度到合适节点 2、创建pause基础容器,提供共享名称空间 3、串行业务容器容器初始化 4、启动业务容器,启动那一刻会同时运行主容器上定义的Poststart钩子事件 5、健康状态监测,判断容器是否启动成功 6、持续存活状态监测、就绪状态监测 7、结束时,执行prestop钩子事件 8、终止容器
⑨API Server将Pod信息存储到etcd系统中。
⑩在etcd确认写入操作完成,API Server将确认信息发送到相关的kubelet。
(3)钩子PostStart、PreStop
PostStart :在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。 主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费时间过长以及于不能运行或者挂起,容器将不能达到Running状态。
容器启动后执行,注意由于是异步执行,它无法保证一定在ENTRYPOINT之后运行。如果失败,容器会被杀死,并根据RestartPolicy决定是否重启
PreStop :在容器终止前立即被调用。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用出发之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod阶段将停留在Running状态并且不会达到failed状态
容器停止前执行,常用于资源清理。如果失败,容器同样也会被杀死
(4)Pod的状态
Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组。 PodCondition 数组的每个元素都有一个 type 字段和一个 status 字段。type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和 Unschedulable。status 字段是一个字符串,可能的值有 True、False 和 Unknown。
(5)Pod存活性探测
在pod生命周期中可以做的一些事情。主容器启动前可以完成初始化容器,初始化容器可以有多个,他们是串行执行的,执行完成后就推出了,在主程序刚刚启动的时候可以指定一个post start 主程序启动开始后执行一些操作,在主程序结束前可以指定一个 pre stop 表示主程序结束前执行的一些操作。在程序启动后可以做两类检测 liveness probe(存活性探测) 和 readness probe(就绪性探测)。如下图:

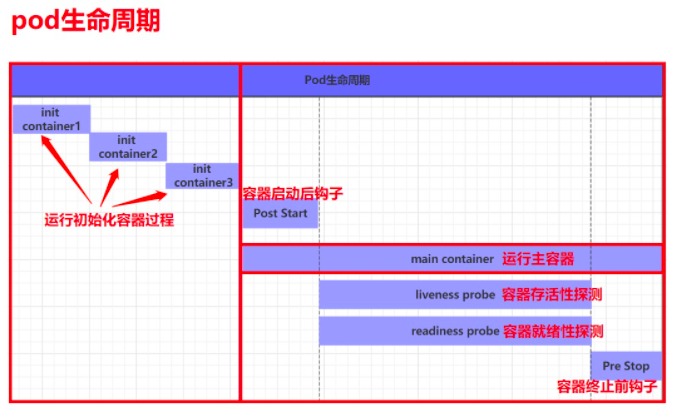
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的Handler。其存活性探测的方法有以下三种:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
设置exec探针举例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-exec
name: liveness-exec
spec:
containers:
- name: liveness-exec-demo
image: busybox
args: ["/bin/sh","-c","touch /tmp/healthy;sleep 60;rm -rf /tmp/healthy;"sleep 600]
livenessProbe:
exec:
command: ["test","-e","/tmp/healthy"]
上面的资源清单中定义了一个Pod 对象, 基于 busybox 镜像 启动 一个 运行“ touch/ tmp/ healthy; sleep 60; rm- rf/ tmp/ healthy; sleep 600” 命令 的 容器, 此 命令 在 容器 启动 时 创建/ tmp/ healthy 文件, 并于 60 秒 之后 将其 删除。 存活 性 探针 运行“ test -e/ tmp/ healthy” 命令 检查/ tmp/healthy 文件 的 存在 性, 若 文件 存在 则 返回 状态 码 0, 表示 成功 通过 测试。
设置HTTP探针举例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-http
name: liveness-http
spec:
containers:
- name: liveness-http-demo
image: nginx:1.12-alpine
ports:
- name: http
containerPort: 80
lifecycle:
postStart:
exec:
command: ["/bin/sh","-c","echo healthy > /usr/share/nginx/html/healthy"]
livenessProbe:
httpGet:
path: /healthy
port: http
scheme: HTTP
上面 清单 文件 中 定义 的 httpGet 测试 中, 请求 的 资源 路径 为“/ healthy”, 地址 默认 为 Pod IP, 端口 使用 了 容器 中 定义 的 端口 名称 HTTP, 这也 是 明确 为 容器 指明 要 暴露 的 端口 的 用途 之一。
设置TCP探针举例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness-tcp
name: liveness-tcp
spec:
containers:
- name: liveness-tcp-demo
image: nginx:1.12-alpine
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket:
port: http
上面的资源清单文件,向Pod IP的80/tcp端口发起连接请求,并根据连接建立的状态判断Pod存活状态。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出反应:
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为Success。readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
(6)livenessProbe和readinessProbe使用场景
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针; kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作。
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。
如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是 spec 中的就绪探针的存在意味着 Pod 将在没有接收到任何流量的情况下启动,并且只有在探针探测成功后才开始接收流量。
如果您希望容器能够自行维护,您可以指定一个就绪探针,该探针检查与存活探针不同的端点。
请注意,如果您只想在 Pod 被删除时能够排除请求,则不一定需要使用就绪探针;在删除 Pod 时,Pod 会自动将自身置于未完成状态,无论就绪探针是否存在。当等待 Pod 中的容器停止时,Pod 仍处于未完成状态。
(7)Pod的重启策略

PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算;例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。
每种控制器对Pod的重启策略要求如下,详解下一小节“pod的生命”

(8)Pod的生命
一般来说,Pod 不会消失,直到人为销毁他们。这可能是一个人或控制器。这个规则的唯一例外是成功或失败的 phase 超过一段时间(由 master 确定)的Pod将过期并被自动销毁。
有三种可用的控制器:
- 使用 Job 运行预期会终止的 Pod,例如批量计算。Job 仅适用于重启策略为
OnFailure或Never的 Pod。
- 对预期不会终止的 Pod 使用 ReplicationController、ReplicaSet 和 Deployment ,例如 Web 服务器。 ReplicationController 仅适用于具有
restartPolicy为 Always 的 Pod。 - 提供特定于机器的系统服务,使用 DaemonSet 为每台机器运行一个 Pod 。
所有这三种类型的控制器都包含一个 PodTemplate。建议创建适当的控制器,让它们来创建 Pod,而不是直接自己创建 Pod。这是因为单独的 Pod 在机器故障的情况下没有办法自动复原,而控制器却可以。
如果节点死亡或与集群的其余部分断开连接,则 Kubernetes 将应用一个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed。
(9)livenessProbe解析
[root@k8s-master ~]# kubectl explain pod.spec.containers.livenessProbe KIND: Pod VERSION: v1 RESOURCE: livenessProbe <Object> exec command 的方式探测 例如 ps 一个进程
failureThreshold 探测几次失败 才算失败 默认是连续三次
periodSeconds 每次的多长时间探测一次 默认10s
timeoutSeconds 探测超市的秒数 默认1s
initialDelaySeconds 初始化延迟探测,第一次探测的时候,因为主程序未必启动完成
tcpSocket 检测端口的探测
httpGet http请求探测
举个例子:定义一个liveness的pod资源类型,基础镜像为busybox,在busybox这个容器启动后会执行创建/tmp/test的文件啊,并删除,然后等待3600秒。随后定义了存活性探测,方式是以exec的方式执行命令判断/tmp/test是否存在,存在即表示存活,不存在则表示容器已经挂了。
[root@k8s-master ~]# vim liveness.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
labels:
name: myapp
spec:
containers:
- name: livess-exec
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/test; sleep 30; rm -f /tmp/test; sleep 3600"]
livenessProbe:
exec:
command: ["test","-e","/tmp/test"]
initialDelaySeconds: 1
periodSeconds: 3
[root@k8s-master ~]# kubectl apply -f lineness.yaml
(10)资源需求和资源限制
在Docker的范畴内,我们知道可以对运行的容器进行请求或消耗的资源进行限制。而在Kubernetes中,也有同样的机制,容器或Pod可以进行申请和消耗的资源就是CPU和内存。CPU属于可压缩型资源,即资源的额度可以按照需求进行收缩。而内存属于不可压缩型资源,对内存的收缩可能会导致无法预知的问题。
资源的隔离目前是属于容器级别,CPU和内存资源的配置需要Pod中的容器spec字段下进行定义。其具体字段,可以使用"requests"进行定义请求的确保资源可用量。也就是说容器的运行可能用不到这样的资源量,但是必须确保有这么多的资源供给。而"limits"是用于限制资源可用的最大值,属于硬限制。
在Kubernetes中,1个单位的CPU相当于虚拟机的1颗虚拟CPU(vCPU)或者是物理机上一个超线程的CPU,它支持分数计量方式,一个核心(1core)相当于1000个微核心(millicores),因此500m相当于是0.5个核心,即二分之一个核心。内存的计量方式也是一样的,默认的单位是字节,也可以使用E、P、T、G、M和K作为单位后缀,或者是Ei、Pi、Ti、Gi、Mi、Ki等形式单位后缀。
资源需求举例:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "128Mi"
cpu: "200m"
上面的配置清单中,nginx请求的CPU资源大小为200m,这意味着一个CPU核心足以满足nginx以最快的方式运行,其中对内存的期望可用大小为128Mi,实际运行时不一定会用到这么多的资源。考虑到内存的资源类型,在超出指定大小运行时存在会被OOM killer杀死的可能性,于是该请求值属于理想中使用的内存上限。
资源限制举例:
容器的资源需求只是能够确保容器运行时所需要的最少资源量,但是并不会限制其可用的资源上限。当应用程序存在Bug时,也有可能会导致系统资源被长期占用的情况,这就需要另外一个limits属性对容器进行定义资源使用的最大可用量。CPU是属于可压缩资源,可以进行自由地调节。而内存属于硬限制性资源,当进程申请分配超过limit属性定义的内存大小时,该Pod将会被OOM killer杀死。如下:
[root@k8s-master ~]# vim memleak-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: memleak-pod
labels:
app: memleak
spec:
containers:
- name: simmemleak
image: saadali/simmemleak
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "64Mi"
cpu: "1"
[root@k8s-master ~]# kubectl apply -f memleak-pod.yaml
pod/memleak-pod created
[root@k8s-master ~]# kubectl get pods -l app=memleak
NAME READY STATUS RESTARTS AGE
memleak-pod 0/1 OOMKilled 2 12s
[root@k8s-master ~]# kubectl get pods -l app=memleak
NAME READY STATUS RESTARTS AGE
memleak-pod 0/1 CrashLoopBackOff 2 28s
Pod资源默认的重启策略为Always,在memleak因为内存限制而终止会立即重启,此时该Pod会被OOM killer杀死,在多次重复因为内存资源耗尽重启会触发Kunernetes系统的重启延迟,每次重启的时间会不断拉长,后面看到的Pod的状态通常为"CrashLoopBackOff"。
这里还需要明确的是,在一个Kubernetes集群上,运行的Pod众多,那么当节点都无法满足多个Pod对象的资源使用时,是按照什么样的顺序去终止这些Pod对象呢??
Kubernetes是无法自行去判断的,需要借助于Pod对象的优先级进行判定终止Pod的优先问题。根据Pod对象的requests和limits属性,Kubernetes将Pod对象分为三个服务质量类别:
- Guaranteed:每个容器都为CPU和内存资源设置了相同的requests和limits属性的Pod都会自动归属于该类别,属于最高优先级。
- Burstable:至少有一个容器设置了CPU或内存资源的requests属性,单不满足Guaranteed类别要求的资源归于该类别,属于中等优先级。
- BestEffort:未对任何容器设置requests属性和limits属性的Pod资源,自动归于该类别,属于最低级别。
顾名思义,最低级别,死得越快!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号