图论学习笔记
序
noip 迫在眉睫,图论算法久未谋面……
不是在沉默中爆发,就是在沉默中灭亡……
终于,我痛下决心,在一个风雨交加的夜晚,向图论宣战!
说明
-
部分图片或文字来源于网络,侵删。
-
整理过程中难免有纰漏,还请谅解~
-
从下一行开始,【标红且加粗且被框起来】的文字一般带有可以访问的链接。
若链接失效或对笔记本身有建议或意见,请【私信我】或在评论中@我哦~
-
大部分与图有关的图片由图论画图神器【csacademy】生成,使用方法可以参考这篇文章:【图论画图神器——CS Academy】。
-
如无特殊说明,默认用链式前向星存图。
head数组为表头,in、out数组为入度、出度,cnt_edge为边数。边的其他信息【如to「终点」、val「边权」等】统一存储在class Edge中。详细解释见后文「图论基础——图的存储——链式前向星」。 -
如有推荐例题,将在每章节末给出。例题链接一般为【蓝色】,可以直接访问。
为防止
代码过长影响阅读体验,例题只给出核心代码而不是 AC 代码,直接提交大概率无法 AC「甚至不能过编译」。「代码中省去的主要是缺省源中的namespace ly,将其补充在using namespace std;下应该能 AC。缺省源的介绍见下。」「完整的 AC 代码见:【例题完整代码】」 -
由于缺省源过长,因此多数代码只给出核心部分。如不另说明,头文件请自己补全。
namespace ly中用到的函数/容器和namespace std中对应函数/容器用法基本相同,仅为优化常数而重新实现一遍。「原理:内联+传址引用+auto/函数模板/类模板,同时省去 STL 中用不到的东西。更多与 STL 有关的注意事项详见这篇优质博客:【C++ STL 使用注意事项整理】」缺省源见:【缺省源】。大体来说:-
namespace ly::algorithm一些简单 STL 函数的重新实现,如
max、min、swap等。本人习惯随用随写。例如ly::min和ly::swap的简单实现:「这里move的原理可以参见这篇博客:【swap函数的高效实现:右值引用和move】。」namespace algorithm { auto min=[](const auto &x,const auto &y)->auto{return x<y?x:y;}; auto swap=[](auto &x,auto &y){auto t=move(x);x=move(y),y=move(t);}; }using namespace algorithm;- 若想使用 STL 中原来的函数,直接将代码中的
ly::去掉,并引入对应函数的头文件即可。 - 关于优化效果,其实取决于编译器和运行环境。不优化影响也不大,
甚至某些情况可能更优。在 【Debug心得&笔记——⑲#define版min、max的一个错误 & 各类min、max效率比较】中有对各种min、max实现方法的效率测试。测试结果是差别不大,选用哪种实现均可。其他常用函数尚未进行测试。
- 若想使用 STL 中原来的函数,直接将代码中的
-
namespace ly::DS一些简单 STL 容器的重新实现,如
stack、queue、deque、list、heap等。- 其中
heap对应 STL 中的priority_queue,声明时可以指定是大根堆/小根堆「默认大根堆」。如ly::DS::heap<int>h1(0),h2(1);声明了两个int类型的堆,其中h1是小根堆、h2是大根堆。 - 用法和 STL 基本相同,如
q.push(x)、h.top()、s.size()等使用效果与 STL 基本相同。 - 更多细节详见我之前的博客:【数据结构模板整合】。
- 若想使用 STL 中原来的容器,直接将代码中的
ly::DS::去掉,并引入对应容器的头文件即可。
- 其中
-
-
代码中出现的
read、write、put等函数定义在我自己的namespace ly::IO中,作用是优化输入、输出,详见我之前的一篇博客:【最全快读、快写模板「持续更新」 】。简单来讲:
-
read可以一次读入一个或多个不同类型的变量。【形如
read(x)、read(a,b,c,d,...)】 -
write可以一次输出一个或多个不同类型的变量。-
若输出多个变量,
write会自动用空格分隔并在结尾回车。【形如
write(a,b,c,d,...)】 -
若只有一个变量,
write只会输出该变量本身。【形如
write(x)】
-
-
put可以一次输出一种类型的变量-
后面可以接一个参数 0 或 1 表示输出空格或换行。
【形如
put(x,0)】 -
不加参数默认输出换行。
【形如
put(x)】
-
-
-
代码中出现的
INT_MAX、INT_MIN、LONG_MAX、LONG_MIN定义在头文件<climits>中,比较常用。但有时为了防止爆int,会选用0x3f3f3f3f而不是INT_MAX作为最大值,因为它是满足以下两个条件的最大整数:「参考——《算法竞赛进阶指南》P3」- 整数的两倍不超过
0x7fffffff,即int能表示的最大正整数。 - 整数的每 8 位「每个字节」都是相同的。
这样,当我们需要把一个数组中的数值初始化成正无穷时,为了避免加法算数上溢或者繁琐的判断,可以使用
memset(a,0x3f,sizeof(a))。「当然,
memset有时会导致 TLE。例如开一个1e6大小的数组a,使用memset(a,0,sizeof(a))就等价于for(int i=0;i<1e6;++i) a[i]=0,显然有很多不必要的时间浪费。当n比1e6小很多时,建议改为for(int i=1;i<=n;++i) a[i]=0,常数小一些。」 - 整数的两倍不超过
-
码风问题。
本人习惯 等价形式 if(x)if(x!=0)if(!x)if(x==0)if(~x)if(x!=-1)if(x&1)if(x%2==1)if(!(x&1))if(x%2==0)if(x^y)if(x!=y)x?y:z;if(x) y;else z;x<<1x*2x>>1x/2a[++b]=cb++,a[b]=ca[b++]=ca[b]=c,b++return a,b,c;a,b;return c;其他习惯:
ll x;等价于long long x;,在缺省源中有#define ll long long。- 习惯将数组最大值设为
maxn等等,#define maxn 1010等价于constexpr auto maxn=1010;,在 【Debug心得&笔记——⑰不同命名空间的宏定义冲突】中有较为详细的解释。
图论基础
图的定义
图由顶点的有穷非空集合和顶点之间边的集合组成,表示为 \(G(V,E)\),其中 \(G\) 表示一个图,\(V\) 是图 \(G\) 中顶点的集合,\(E\) 是图 \(G\) 中边的集合。
例如:
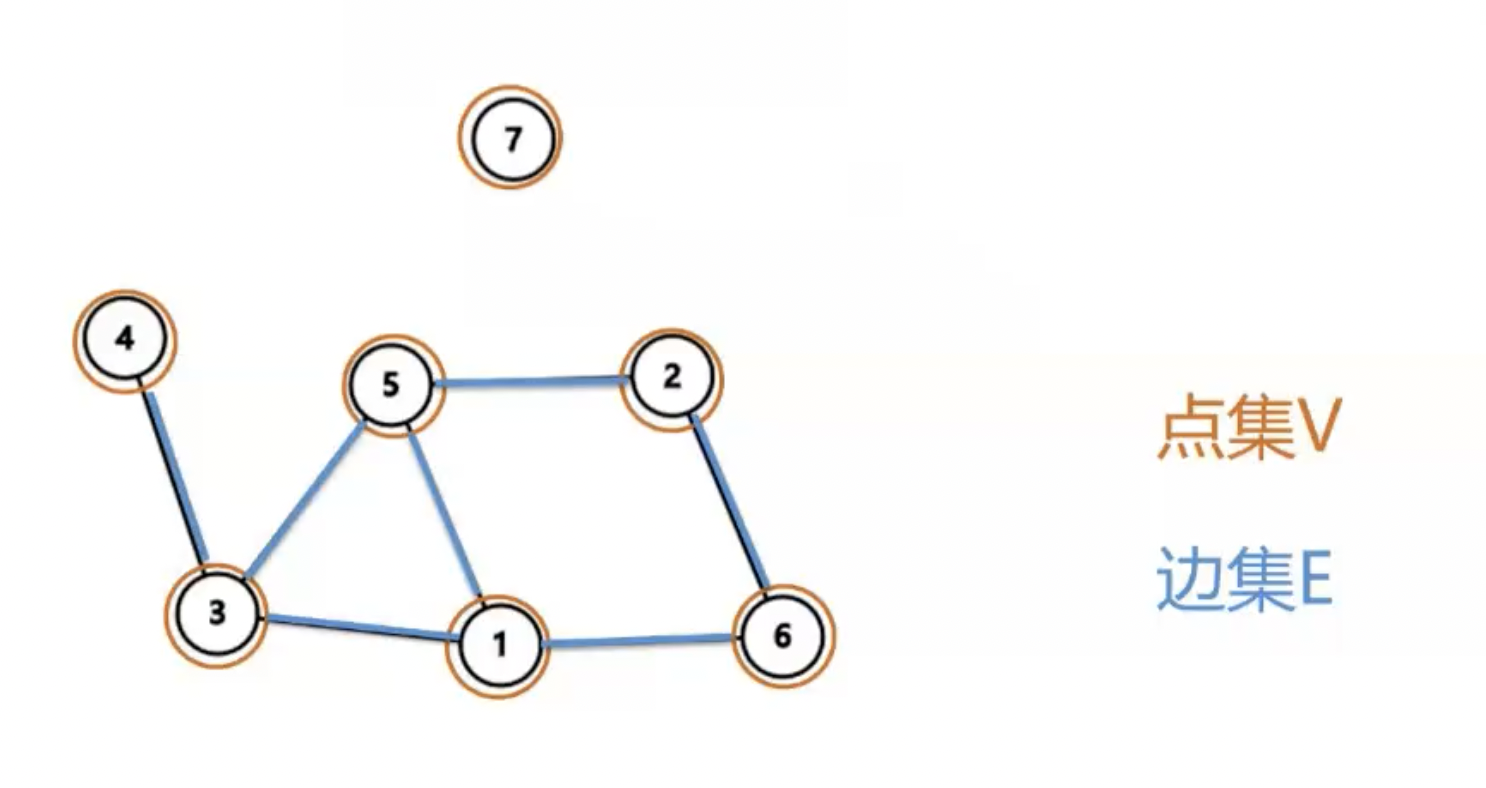
「由于在 \(OI\) 中,图的术语没有标准化,因此,称顶点为点、节点、结点、端点等都是可以的。名称不重要,理解才是关键。」
图的分类
-
无向图

- 无向边:没有方向的边,用无序偶对 \((u,v)\) 表示,在图中表示为连接 \(u\) 点和 \(v\) 点的线段。
- 如果图中所有的边都是无向边,则称该图为无向图。
- 度:与无向图中一点 \(u\) 相连的边数叫做点 \(u\) 的度。
-
有向图
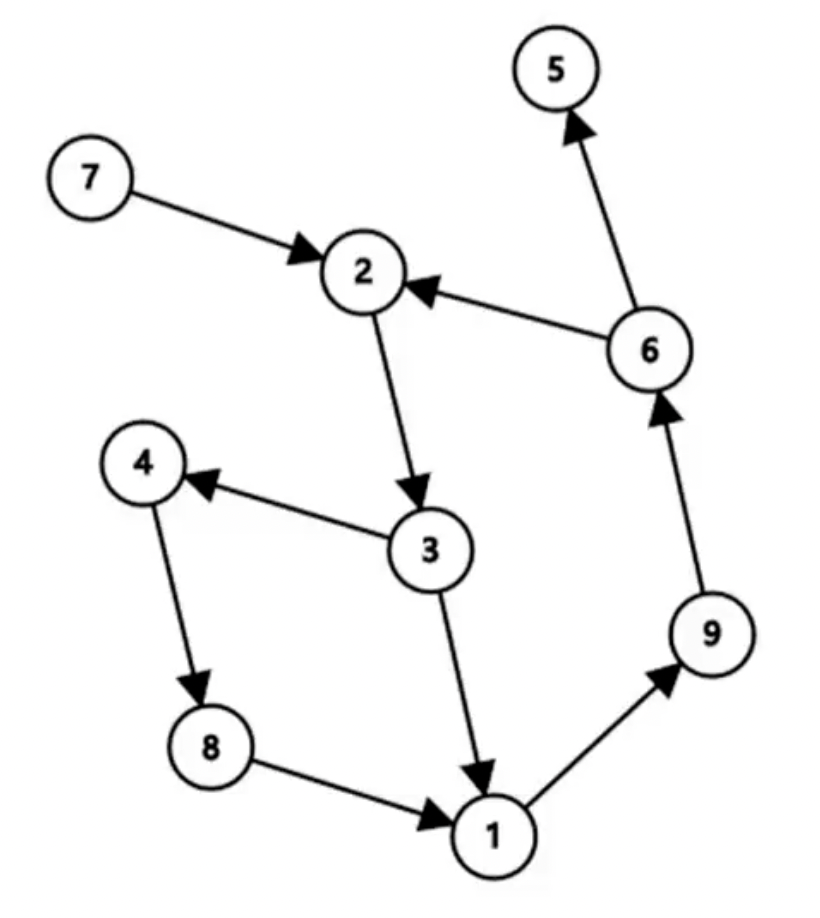
- 有向边:具有方向的边,也称为弧。用有序偶 \(<u,v>\) 表示,在图中表示为从 \(u\) 点指向 \(v\) 点的箭头。
- 如果图中所有边都是有向边,则称该图为有向图。
- 入度:有向图中一点 \(u\) 作为图中边的终点的次数之和叫做点 \(u\) 的入度。
- 出度:有向图中一点 \(u\) 作为图中边的起点的次数之和叫做点 \(u\) 的出度。
- 有向无环图:没有环的有向图,又称 DAG。
-
简单图
- 无重边「同一条边重复出现」且无自环「存在顶点到其自身的边」的图称为简单图。
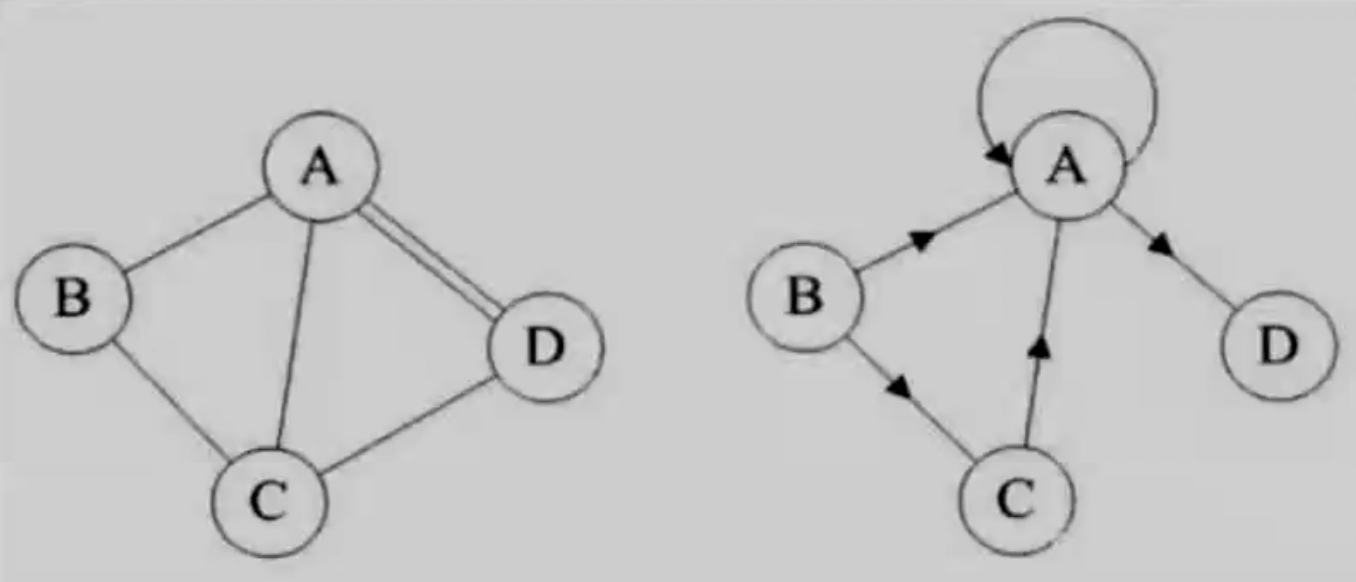
如上面左、右两图都不是简单图。「左图有重边,右图有自环。」
-
连通图
-
无向连通图
在无向图 \(G\) 中,如果从顶点 \(u\) 到顶点 \(v\) 有路径,则称 \(u\) 和 \(v\) 是连通的。如果图中任意两个顶点都是连通的,则称 \(G\) 是连通图。
-
强连通图
在有向图 \(G\) 中,如果 \(\forall u,v\in V,u\ne v\),从 \(u\) 到 \(v\) 和从 \(v\) 到 \(u\) 间都存在路径,则称 \(G\) 是强连通图。
-
-
完全图
-
无向完全图
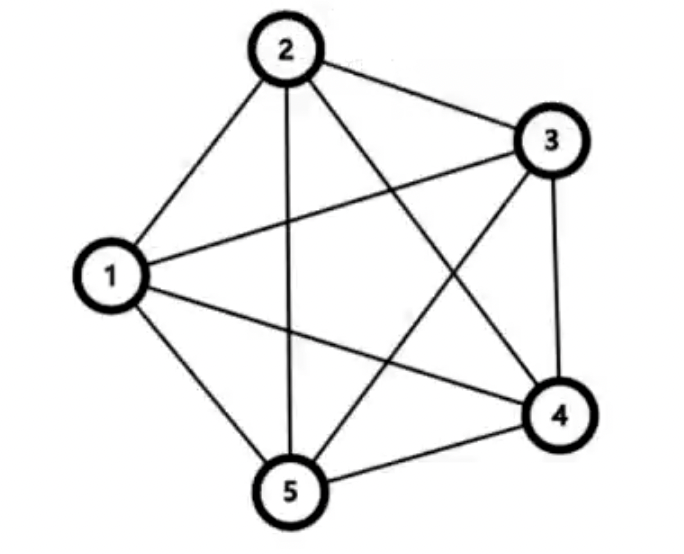
-
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。
-
一个有 \(n\) 个顶点的无向完全图,有 \(\frac{n(n-1)}2\) 条边。
-
-
有向完全图
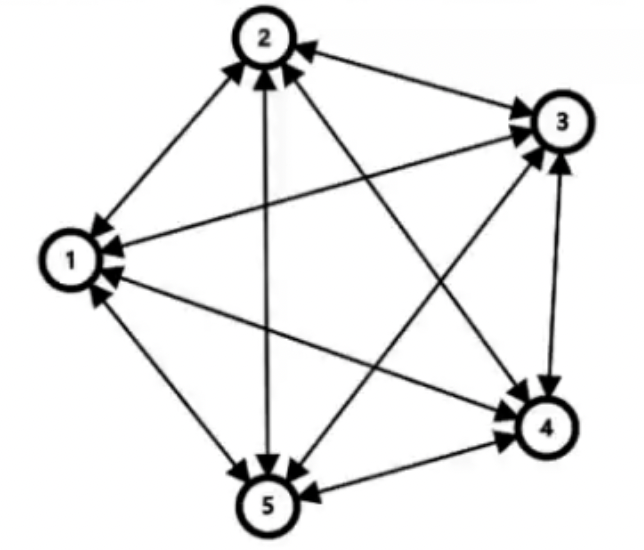
- 在有向图中,如果任意两个顶点之间都存在方向互为相反的两条有向边,则称该图为有向完全图。
- 一个有 \(n\) 个顶点的有向完全图,有 \(n(n-1)\) 条边。
-
-
二分图
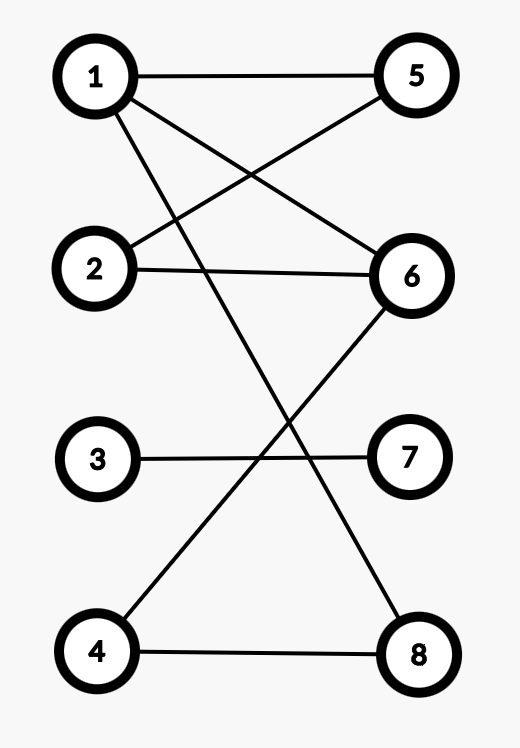
设 \(G=(V,E)\) 是一个无向图,如果顶点 \(V\) 可分割为两个互不相交的子集 \((A,B)\),并且图中的每条边 \((i,j)\) 所关联的两个顶点 \(i\) 和 \(j\) 分别属于这两个不同的顶点集,则称图 \(G\) 为一个二分图。
「如上面的二分图,可以将顶点分为 \(1\)~\(4\) 和 \(5\)~\(8\) 两部分,每部分中的顶点没有连边。」
特殊的图——树
-
树的定义和性质
- 树是任意两个顶点间有且只有一条路径的图。
- 树是点数比边数多 \(1\) 的连通图。
-
树的亿些概念
-
树的每个元素称为节点。有一个特定的节点被称为根节点或树根。
-
设 \(T_1,T_2,...,T_k\) 是树,它们的根节点分别为 \(n_1,n_2,...,n_k\)。用一个新节点 \(n\) 作为 \(n_1,n_2,...,n_k\) 的父亲,则得到一棵新树,节点 \(n\) 就是新树的根。我们称 \(n_1,n_2,...,n_k\) 为一组兄弟节点,它们都是节点 \(n\) 的子节点,\(T_1,T_2,...,T_k\) 为节点 \(n\) 的子树。
-
空树:空集合也是树,称为空树。空树中没有节点。
-
子节点:一个节点含有的子树的根节点称为该节点的子节点。
-
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点。
-
兄弟节点:具有相同父节点的节点互称为兄弟节点。
-
节点的度:一个节点含有的子节点的个数称为该节点的度。
-
叶节点:度为 \(0\) 的节点称为叶节点。
-
分支节点:度不为 \(0\) 的节点称为分支节点。
-
树的度:一棵树中,最大的节点的度称为树的度。
-
节点的祖先:从根到该节点所经分支上的所有节点。
-
节点的子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
-
森林:由 \(m(m\ge0)\) 棵互不相交的树组成的集合称为森林。
-
-
二叉树
- 每个节点最多有两个子树的树是二叉树。
- 满二叉树:在一棵二叉树中,如果所有分支节点都存在左子树和右子树,且所有叶子都在同一层上,这样的二叉树称为满二叉树。「感性理解为一个完整的三角形。。。」
- 完全二叉树:除最后一层外,其他各层的节点数都达到最大个数,且最后一层的节点都连续集中在最左边。
图的存储
说明:设待存图的点数为 \(n\),边数为 \(m\)。输入为第一行 \(n,m\),接下来 \(m\) 行,每行 \(3\) 个正整数 \(x,y,w\),表示 \(x\) 到 \(y\) 连边,边权为 \(w\)。下面举个栗子。
输入:
9 10
1 2 1
1 3 2
2 4 3
2 5 4
3 5 5
3 6 6
6 7 7
7 8 8
7 9 9
8 9 10
这样建好的图有两种情况:无向图和有向图。
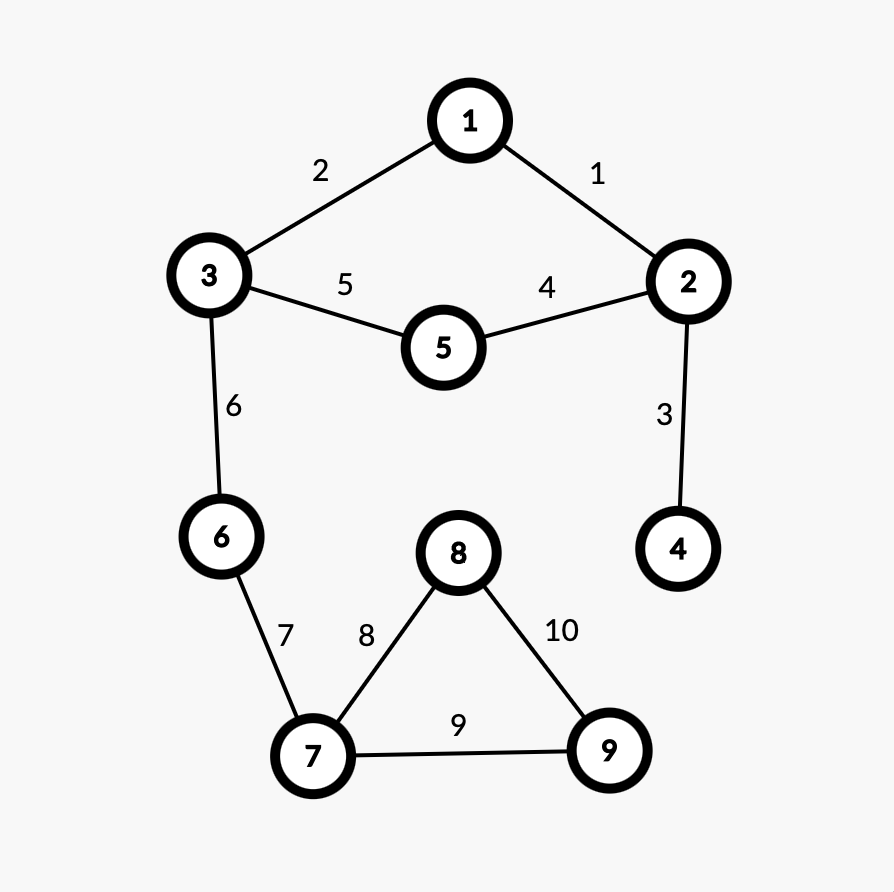
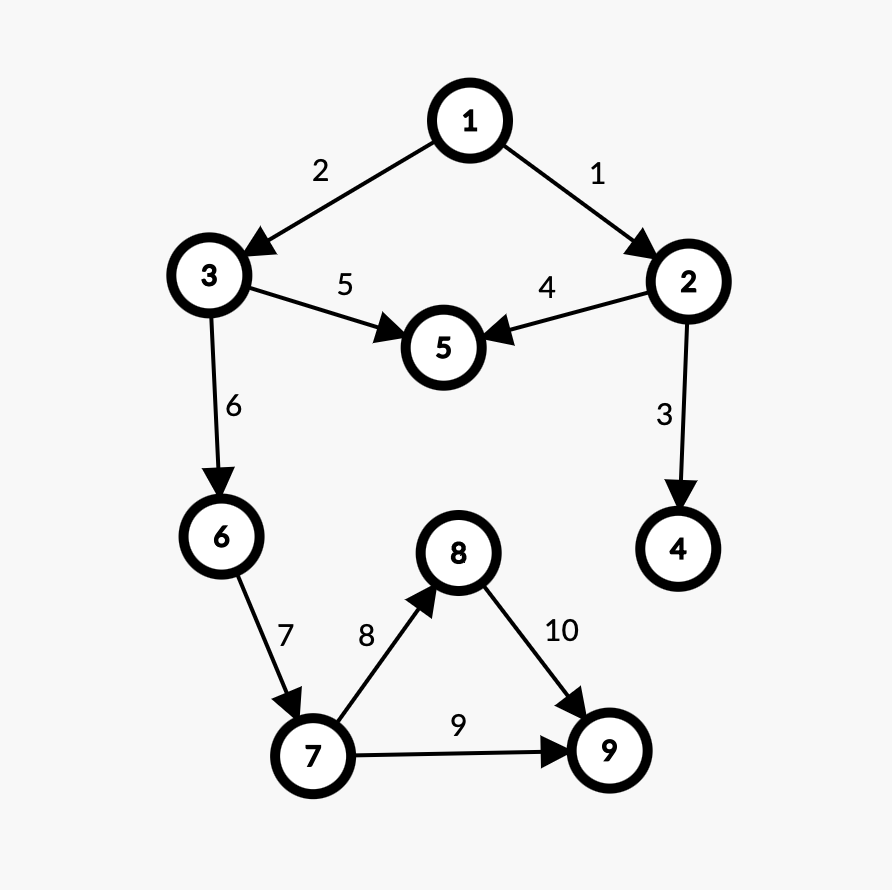
-
邻接矩阵【适合存稠密图】
-
用一个二维数组 \(a\) 存储边。
-
\(a[i][j]=\text{INF}\) 表示不存在点 \(i\) 向点 \(j\) 的边,\(a[i][j]=w\) 表示存在点 \(i\) 向点 \(j\) 的边且边权为 \(w\),\(a[i][i]=0\) 表示无自环。
-
空间复杂度 \(O(n^2)\)。
-
代码实现
#define maxn 1010 #define INF 0x3f3f3f3f int n,m,x,y,w,a[maxn][maxn]; signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) a[i][j]=INF; for(int i=1;i<=m;++i) read(x,y,w),a[x][y]=w; return 0; }- 其中,
i^j表示i!=j。 - 关于为什么不用
memset「其实这里用不用影响不大」,见「序——说明」。
- 其中,
-
注意
存储无向图时要正反双向建边:
a[x][y]=a[y][x]=1。 -
优点:写法简单。
-
缺点:空间复杂度过高。
-
-
邻接链表「
vector存图,因为几乎不用故不再详细整理。」- 优点:建图步骤较为简单。
- 缺点:常数大!!!
-
链式前向星【适合存稀疏图】「强烈推荐!!!」
-
建立 \(n\) 个链表,链表中的元素是图中的边。可以用数组或结构体/类模拟链表。
-
「可以这样想象,有 \(n\) 个链表,表头是 \(1\)~\(n\) 即每个节点的编号,第 \(i\) 个表中的元素是所有以节点 \(i\) 作为起点的边的编号。各个元素按照加边的顺序存储。」
-
to数组:to[i]表示 \(i\) 号边的终点。 -
val数组:val[i]为第 \(i\) 条边的边权。 -
head数组:head[i]表示从第 \(i\) 个节点出发的第一条边在edge和to数组中的存储位置,初始时为 \(0\)。 -
next数组:从相同节点出发的下一条边在edge和to数组中的存储位置。 -
根据以上各数组的意义,设
maxn表示最大节点个数 \(+1\),maxm表示最大边数 \(+1\),则head数组的大小至少要开到maxn,to、val、next数组的大小至少要开到maxm。「无向图注意maxn要 \(\times2\)」 -
cnt:当前存的是第几条边。从编号 \(1\) 开始存,存到编号 \(m\)。 -
add_edge(int x,int y,int w):加边函数。-
x、y、w分别表示边的起点、终点、边权。 -
作用是从
x向y连一条边权为w的边。 -
实现:
-
先将
cnt++。 -
然后通过
to[cnt]=y记录终点。 -
val[cnt]=w记录边权。 -
next[cnt]=head[x]记录以x为起点的上一条边的编号,以便于以后访问以x为起点的每一条边。「虽然这样存储,访问是倒序的,但不影响结果。」
-
head[x]=cnt更新以x为起点的上一条边的编号。「后面再添加以
x为起点的边时,可以保证该边正确接到表头为x的链表后面。」
-
-
-
数组实现
#define maxn 1010 #define maxm 1010 #define next nxt int n,m,x,y,w; int cnt,head[maxn],val[maxm],to[maxm],next[maxm]; inline void add_edge(int x,int y,int w) { to[++cnt]=y; val[cnt]=w; next[cnt]=head[x]; head[x]=cnt; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); return 0; } -
其中,因为
next在c++中属于保留字,直接使用会报错:error: reference to 'next' is ambiguous,可以用#define next nxt解决。
将用到的
val、to、next这些与边有关的变量统一存入结构体/类中,可以更加一目了然。同时可以很轻松避免命名冲突的问题。「由于
head存的是每个节点而不是边的信息,因此要放到结构体/类的外面。类似的有每个节点的入度、出度等也要放在外面。」-
结构体实现
#define maxn 1010 #define maxm 1010 int n,m,x,y,w; int cnt,head[maxn]; struct Edge { int val,to,next; }edge[maxm]; inline void add_edge(int x,int y,int w) { edge[++cnt].to=y; edge[cnt].val=w; edge[cnt].next=head[x]; head[x]=cnt; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); return 0; } -
类实现
#define maxn 1010 #define maxm 1010 int n,m,x,y,w; int cnt,head[maxn]; class Edge { public: int val,to,next; }edge[maxm]; inline void add_edge(int x,int y,int w) { edge[++cnt].to=y; edge[cnt].val=w; edge[cnt].next=head[x]; head[x]=cnt; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); return 0; }
当然,写多了你可以像我一样:「存图的部分用空行分开,大概能增加代码可读性……」
#define maxn 1010 #define maxm 1010 int n,m,x,y,w; int cnt_edge,head[maxn]; class Edge{public:int val,to,next;}edge[maxm]; inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;} signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); return 0; }核心代码只有不到五行,十分简洁。「这里用
cnt_edge是为了避免与其他变量重名。」「扩展」善用 lambda 表达式可以使代码更简洁~
auto add_edge=[](auto x,auto y,auto w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;};- 空间复杂度 \(O(n+m)\)。
- 优点:太多,不说了。
- 缺点:不易上手,但多写几遍就会了。似乎也没啥其他缺点了。
-
由于树是一种特殊的图,因此在存储方式上二者本质并无区别。唯一比较特殊的就是树的输入中 \(m=n-1\)。下面用链式前向星实现树的存储「其实把上面改改就好了」:
#define maxn 1010
int n,x,y,w;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
return 0;
}
图的遍历
定义&说明
图的遍历是指从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次。
——百度百科
重点有两个:
- 每个顶点都要访问。
- 每个顶点只访问一次。
因此,不论怎样实现图的遍历,都可以开一个bool 类型的 vis 数组存储每个顶点是否已被访问的状态,vis[i]==0 表示顶点 \(i\) 未被访问,vis[i]==1 表示顶点 \(i\) 已被访问。当 vis[i]==1 且再遍历到顶点 \(i\) 时,直接跳过即可。
输入同前面「图论基础——图的存储」:
设待存图的点数为 \(n\),边数为 \(m\)。输入为第一行 \(n,m\),接下来 \(m\) 行,每行 \(3\) 个正整数 \(x,y,w\),表示 \(x\) 到 \(y\) 连边,边权为 \(w\)。
样例相同:
9 10 1 2 1 1 3 2 2 4 3 2 5 4 3 5 5 3 6 6 6 7 7 7 8 8 7 9 9 8 9 10
这里我们假设存的是有向图:「无向图中的边可以看作成对出现的双向边。」
深度优先遍历
「Depth-First-Search,简称 DFS」
深度优先遍历,就是在每个点 \(x\) 上面对多条分支时,任选一条边走下去,执行递归,直至回溯到点 \(x\) 后,再考虑走向其他的边。
——李煜东《算法竞赛进阶指南》P93
过程
- 选择一个点作为起点。
- 将被选择的点标记为已访问。
- 遍历以被选择的点为起点的所有边,当找到一条终点末被访问的边
时,访问该边的终点。 - 将终点作为已选择的点重复第 2~4 步,当不存在未访问的点时,遍历结
束。
邻接矩阵实现
#define maxn 1010
#define INF 0x3f3f3f3f
int n,m,x,y,w,a[maxn][maxn];
bool vis[maxn];
void dfs(int i)
{
vis[i]=1;
put(i,0);
for(int j=1;j<=n;++j)
if(!vis[j]&&a[i][j]^INF)
dfs(j);
return;
}
signed main()
{
read(n,m);
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
if(i^j) a[i][j]=INF;
for(int i=1;i<=m;++i) read(x,y,w),a[x][y]=w;
for(int i=1;i<=n;++i) if(!vis[i]) dfs(i);
return 0;
}
-
建图不再解释,见前面「图论基础——图的存储——邻接矩阵」。
-
dfs(i)的作用是从节点 \(i\) 开始,遍历以 \(i\) 为起点的每一条边。 -
遍历方式是枚举所有节点,访问每一个与 \(i\) 相连的节点 \(j\)。
-
为了保证每个节点只访问一次,我们用
vis数组记录每个节点是否被访问的状态。- 若
vis[j]==1,说明节点j已经被访问过,不用再访问。 - 若
vis[j]==0,说明节点j未被访问,dfs(j)递归访问j即可。 - 每次开始执行
dfs(i)时,此时i被第一次访问,也是唯一一次访问。令vis[i]=1并输出i,表示i此时被访问。
- 若
-
那
for(int i=1;i<=n;++i) if(!vis[i]) dfs(i);的作用是什么呢?直接看之前的图。如果只访问 \(1\) 个节点:
- 假设只访问节点 \(1\)「即
dfs(1)」,自然可以实现图的遍历,因为从节点 \(1\) 出发可以到达任何一个其他节点。 - 但如果只访问节点 \(4\)「或只访问节点 \(5\),或只访问节点 \(9\)」,则只能访问其本身,因为从该节点出发无法到达其他节点。
- 即使要遍历的图是无向图也要这样做,因为图不一定连通!「极端情况是每个节点都没有连边。」
- 因此要枚举每个节点作为起点,这样才一定可以访问到每个节点。
- 假设只访问节点 \(1\)「即
-
时间复杂度
访问 \(n\) 个节点,对访问到的每个节点 \(i\) 都要枚举 \(n\) 个节点 \(j\)。因此总时间复杂度 \(O(n^2)\)。
时间戳
样例输出:
1 2 4 5 3 6 7 8 9
可以发现,每个点确实只被访问了 \(1\) 次。
特殊地,如果该图是一颗树,则通过这种方法「在刚进入递归时记录该点编号」依次给这 \(n\) 个节点 \(1\)~\(n\) 的整数标记,该标记就被称为时间戳,记为 \(dfn\)。
对 dfs 简单修改即可求出 dfn 数组:
int cnt,dfn[maxn];
void dfs(int i)
{
vis[i]=1,dfn[i]=++cnt;
put(i,0);
for(int j=1;j<=n;++j)
if(!vis[j]&&a[i][j]^INF)
dfs(j);
return;
}
dfs 序
如果我们在对每个点的访问结束前再次输出其编号:
void dfs(int i)
{
vis[i]=1,put(i,0);
for(int j=1;j<=n;++j)
if(!vis[j]&&a[i][j]^INF)
dfs(j);
put(i,0);
return;
}
则会输出这样的结果:
1 2 4 4 5 5 2 3 6 7 8 9 9 8 7 6 3 1
特殊地,如果该图是一颗树,则通过这种方法「在刚进入递归和递归结束前分别记录该点编号」生成的长度为 \(2n\) 的节点序列被称为树的 DFS 序。
按照输出的序列画一下图:
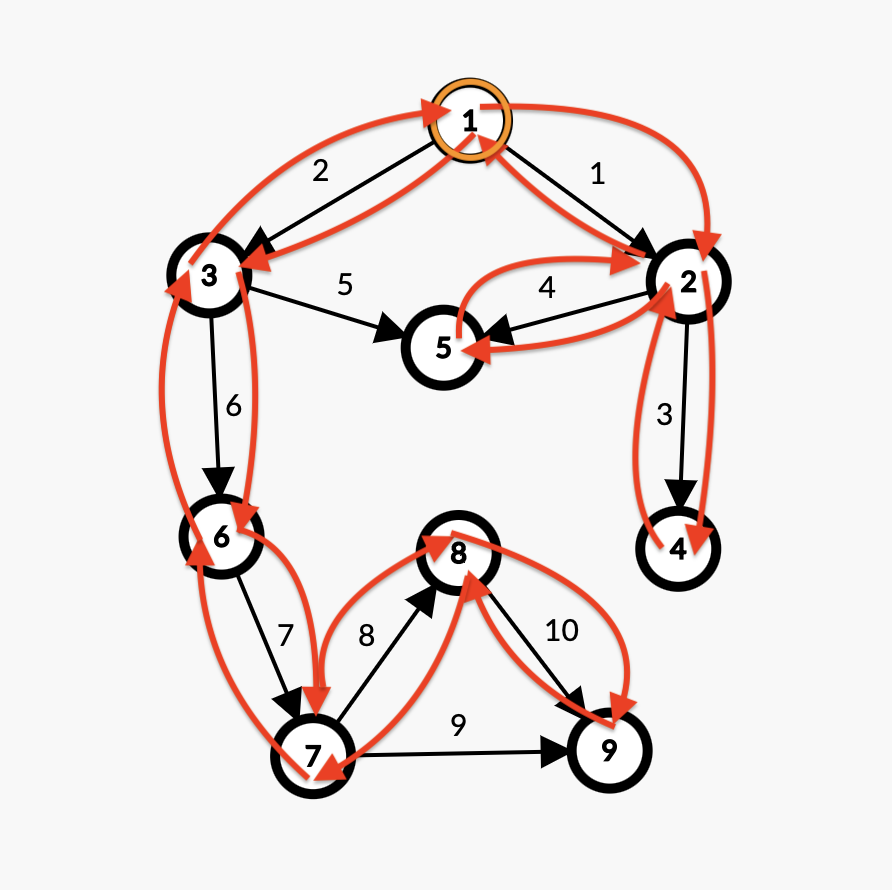
这便是用邻接矩阵实现的 dfs 对每个节点的访问顺序。
关于 DFS 序:
DFS 序的特点是:每个节点 \(i\) 的编号在序列中恰好出现两次。设这两次出现的位置为 \(l[i]\)、\(r[i]\),那么闭区间 \([l[i],r[i]]\) 就是以 \(i\) 为根的子树的 DFS 序。这是我们在很多与树相关的问题中,可以通过 DFS 序把子树统计转化为序列上的区间统计。
——李煜东《算法竞赛进阶指南》P94
链式前向星实现
「前面邻接矩阵实现中 dfs 参数用的 i,这样 for 循环中用变量 j,a[i][j] 符合习惯。但在链式前向星中没有 a[i][j] 的形式。当 x 作为递归参数时,循环变量用 i,令 y=edge[i].to,这样 <x,y> 构成一条有向边,比较符合习惯。因此下面链式前向星的递归参数用 x。」
「当然,还是根据个人偏好而定。」
#define maxn 1010
#define maxm 1010
int n,m,x,y,w;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxm];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=1,put(x,0);
int y;
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) dfs(y);
return;
}
signed main()
{
read(n,m);
for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w);
for(int i=1;i<=n;++i) if(!vis[i]) dfs(i);
return 0;
}
-
可以类比前面的邻接矩阵实现。
-
与邻接矩阵实现的主要区别在于枚举顶点的方式不同。
-
邻接矩阵
对于当前的顶点 \(i\),直接枚举所有顶点 \(j\),先判断顶点 \(j\) 是否已访问过「这点二者相同」,再判断 \(i\)、\(j\) 之间是否有连边。
-
链式前向星
由于链式前向星本身存的就是每个顶点连的边的信息,因此对于当前的顶点 \(x\),以 \(x\) 为表头的链表存储的就是以 \(x\) 为起点的所有边的信息。【这里不懂的回去看看「图论基础——图的存储——链式前向星」】
一开始接触这一过程可能不是很好理解,所以重新思考我们的目的是什么:当前已经访问节点 \(x\) 了,接下来要访问所有与 \(x\) 相连的节点。
我们可以枚举与 \(x\) 相连且以 \(x\) 为起点的边「设边的编号为 \(i\)」,这样边的终点「
edge[i].to」不就是我们要找的节点吗?现在问题转化为如何求出与 \(x\) 相连的边的编号。链式前向星模拟的 \(n\) 个链表存储的不就是以每个顶点为起点的所有边的编号吗?
以顶点 \(x\) 为起点的上一条边「这里上一条的含义是上一次加入」的编号即为
head[x],这就是我们找到的第一条边的编号。令
i=head[x],由于edge[i].next的含义是在第 \(i\) 条边之前加入的上一条与第 \(i\) 条边同起点「起点也是 \(x\)」的边的编号,因此,第edge[i].next条边是我们找到的第二条满足条件的边。接下来,不断令i=edge[i].next,则第edge[i].next条边同样满足条件。直到edge[i].next的值为 \(0\),此时我们已经找不到上一条满足条件的边,edge[i]即为我们第一个插入的起点为 \(x\) 的边,循环终止。这个过程中遇到的每个
i都是起点为 \(x\) 的边的编号,因此对于每个i,edge[i].to都是对应边的终点,即我们一开始要找的与 \(x\) 相连的节点。如果edge[i].to未被访问过,对其用dfs(edge[i].to)递归访问即可。这就有了:
for(int i=head[x];i;i=edge[i].next) if(!vis[edge[i].to]) dfs(edge[i].to);有时访问每个
i时要进行额外的操作,每次都写一遍edge[i].to未免有些麻烦,我们可以定义一个变量int y=edge[i].to,直接if(!vis[y]) dfs(y);即可,变得十分简洁。「而且,
<x,y>恰好构成一条有向边,这种形式符合习惯。」容易发现,此过程中我们只枚举了满足起点为 \(x\) 的边,并没有枚举每一条边,因此显然优于邻接矩阵的遍历方式。
-
-
时间复杂度
我们已经知道链式前向星实现的时间复杂度优于邻接矩阵实现,那么其时间复杂度到底是多少?
容易发现,这段
dfs代码访问每个点和每条边恰好 \(1\) 次「如果是无向边,正反向各访问一次」,其时间复杂度为 \(O(n+m)\)。 -
访问顺序
上面的代码输入样例后,输出如下:
1 3 6 7 9 8 5 2 4和邻接矩阵实现的输出结果不同?
不会是写错了吧?其实,两种实现方式都是正确的,因为都保证了每个节点只被访问一次。
邻接矩阵是按照 \(1\)~\(n\) 的顺序枚举顶点 \(j\),而链式前向星是按照加入起点为 \(i\) 的边的倒序枚举边的编号 \(j\)。
枚举顺序不同,导致了访问节点的顺序不同,输出结果不同。
我们不妨再看一下在对每个点的访问结束前再次输出其编号的结果。
1 3 6 7 9 9 8 8 7 6 5 5 3 2 4 4 2 1再次按照输出的序列画一下图:
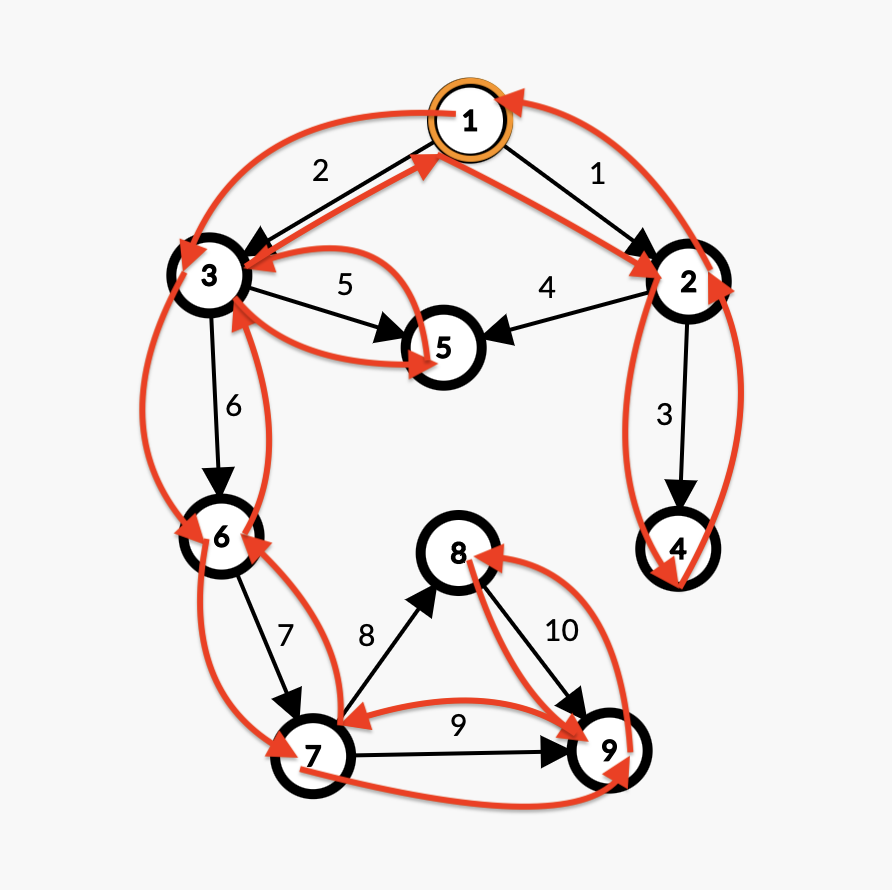
这便是用链式前向星实现的 dfs 对每个节点的访问顺序。
图的连通块划分
在「图论基础——图的遍历——链式前向星——深度优先遍历——邻接矩阵实现」中,我们已经提及了 for(int i=1;i<=n;++i) if(!vis[i]) dfs(i); 的作用,且提到过图不连通的情况。
先给出连通块的定义:
若在无向图的一个子图中,任意两个节点之间都存在一条路径「可以互相到达」,并且这个子图是“极大”的「不能再扩张」,则称该子图为无向图的一个连通块。一张不连通的无向图由 \(\ge2\) 个连通块组成,而一张无向连通图整体是一个连通块。
——李煜东《算法竞赛进阶指南》P96
如果只调用 dfs(x),那么只能访问从 \(x\) 到达的所有点和边。因此,对一张图进行多次深度优先遍历,可以划分出该图中的各个连通块;对一个森林进行多次深度优先遍历,可以划分出森林中的每棵树。
设 cnt 为无向图包含连通块的个数,v 数组标记了每个点属于哪个连通块。
「其实不用再开一个 v 数组,直接将原来的 vis 数组改为 int 类型,直接当作 v 数组来用就可以,这也不影响其记录每个节点是否被访问的功能。」
代码如下:
#define maxn 1010
#define maxm 1010
int n,m,x,y,w,cnt;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxm];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=cnt;
int y;
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) dfs(y);
return;
}
signed main()
{
read(n,m);
for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w);
for(int i=1;i<=n;++i) if(!vis[i]) cnt++,dfs(i);
return 0;
}
树的遍历
和图的遍历几乎一模一样,但不需要 for(int i=1;i<=n;++i) if(!vis[i]) dfs(i);。设根节点编号为 \(x\),只需调用一次 dfs(x) 即可。
代码如下:
#define maxn 1010
int n,x,y,w;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=1;
int y;
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) dfs(y);
return;
}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
dfs(1);
return 0;
}
对于有根树「有确定根节点的树」还有一种更简单的写法:设父节点的编号为 \(fa\),在遍历所有出边的终点时,直接判断 edge[i].to!=fa 即可,无需用 vis 数组记录是否访问。「根节点的 \(fa\) 设为 \(0\) 即可。」
代码如下:
#define maxn 1010
int n,x,y,w;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
void dfs(int x,int fa)
{
int y;
for(int i=head[x];i;i=edge[i].next)
if((y=edge[i].to])^fa) dfs(y,x);
return;
}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
dfs(1,0);
return 0;
}
树的深度
树中各个节点的深度是一种自顶向下的统计信息。起初,我们已知跟节点的深度为 \(0\)。若节点 \(x\) 的深度为 \(d[x]\),则它的子节点 \(y\) 的深度就是 \(d[y]=d[x]+1\)。在深度优先遍历的过程中结合自顶向下的递推,就可以求出每个节点的深度 \(d\)。
——李煜东《算法竞赛进阶指南》P94
代码实现:「设根节点编号为 \(1\)」
#define maxn 1010
int n,x,y,w;
int cnt_edge,head[maxn],d[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=1;
int y;
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) d[y]=d[x]+1,dfs(y);//从父节点 x 向子节点 y 递推,计算深度
return;
}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
dfs(1);
return 0;
}
树的重心
当然,也有许多信息是自底向上进行统计的,比如以每个节点 \(x\) 为根的子树大小 \(size[x]\)。对于叶子节点,我们已知“以它为根的子树”大小为 \(1\)。若节点 \(x\) 有 \(k\) 个子节点 \(y_1\)~\(y_k\),并且以 \(y_1\)~\(y_k\) 为根的子树大小分别是 \(size[y_1],size[y_2]...,size[y_k]\),则以 \(x\) 为根的子树大小就是 \(size[x]=size[y_1]+size[y_2]+...+size[y_k]+1\)。
对于一个节点 \(x\),如果我们把它从树中删除,那么原来的一棵树可能会分成若干个不相连的部分,其中每一部分都是一棵子树。设 \(\text{max}\_\text{part}(x)\) 表示在删除节点 \(x\) 产生的子树中,最大的一棵的大小。使 \(\text{max\_part}\) 函数取到最小值的节点 \(p\) 就称为整颗树的重心。
——李煜东《算法竞赛进阶指南》P95
直接求重心可能有些棘手,我们不妨先考虑如何求出 size 数组。
#define maxn 1010
int n,x,y,w,size[maxn];
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=1,size[x]=1;//x 的子树包含 x 本身
int y;
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) dfs(y),size[x]+=size[y];//从子节点 y 向父节点 x 递推,计算子树大小
return;
}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
dfs(1);
return 0;
}
设全局变量 ans 为重心对应的 max_part,pos 为重心的编号。「将 ans 初始化为总节点个数 n 即可。」
利用求出来的 size 数组,很容易求得树的重心:
#define maxn 1010
int n,x,y,w,ans=n,pos,size[maxn];
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxn];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
void dfs(int x)
{
vis[x]=1,size[x]=1;
int y,max_part=0;//删掉 x 后分成的最大子树的大小
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to])
{
dfs(y),size[x]+=size[y];
max_part=ly::max(max_part,size[y]);
}
max_part=ly::max(max_part,n-size[x]);//别忘了还有节点 x 的祖先!
if(max_part<ans) ans=max_part,pos=x;//更新重心
return;
}
signed main()
{
read(n);
for(int i=1;i<n;++i) read(x,y,w),add_edge(x,y,w);
dfs(1);
put(pos);
return 0;
}
-
注:代码中的
ly::max用法与std::max基本相同,「序——说明」中已作过解释。namespace ly中,简单实现如下:namespace algorithm { auto max=[](const auto &x,const auto &y)->auto{return x>y?x:y;}; }using namespace algorithm;类似的函数「如
ly::min、ly::swap等等」后文不再解释。
总体来说,链式前向星的思维复杂度稍高,但编程复杂度与邻接矩阵相差不大。由于其存储、访问的时间、空间复杂度远优于邻接矩阵,除有特殊说明外「如 Floyed、Prim、传递闭包等算法一般用邻接矩阵实现」,后文统一使用链式前向星存图。
例题
【洛谷P1330 封锁阳光大学】
「板子题」
-
题意简述
- 给定一张 \(n\) 个点、\(m\) 条边的简单无向图。
- 若某个点上存在一只螃蟹,则与该点相连的所有边无法通行。
- 不允许出现两个端点都有螃蟹的边。
- 问至少用多少只螃蟹可以使所有边无法通行。
- 输出最少需要的螃蟹数。若不可能使所有边无法通行,输出
Impossible。 - 数据范围:\(1\le n\le10^4,1\le m\le10^5\)。
-
分析
-
由题意得,当一条边无法通行时,该边的两个端点有且只有一个螃蟹。
-
注意到图不一定连通!故要考虑每个连通块内的情况。
-
先判断可行性。
- 若有方案使得所有连通块内所有边有且只有一个端点有螃蟹,则该方案可行。
- 假设一个点有螃蟹,则可以推出该连通块内其他所有点是否有螃蟹。
- 若所有点的状态被确定后存在一条两端点都有螃蟹的边,则无可行方案,反之有可行方案。
-
接下来考虑最小化螃蟹数量。
- 容易发现,当一个连通块存在可行方案时,仅有两种情况。
- 每个节点只有有螃蟹和无螃蟹两种状态,将一种可行方案的所有节点的状态改变,则可以转化为另一种可行方案。
- 因此两种方案中螃蟹数之和即为连通块内节点总数 \(tot\)。
- 我们只需要求出一种可行方案的螃蟹数 \(num\),答案对每个连通块内的 \(num\) 和 \(tot-num\) 取最小值并累加即可。
-
-
核心代码
【所有例题的代码为增加可读性,已去掉缺省源,只保留核心代码,不保证提交能 AC「甚至无法过编译」,详见「序——说明」。完整 AC 代码见【例题完整代码】。后文不再赘述。】
constexpr auto maxn=10010; constexpr auto maxm=100010; int n,m,x,y,cnt,tot,ans; int cnt_edge,head[maxn]; class Edge{public:int to,next;}edge[maxm<<1]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge;} int state[maxn],vis[maxn]; void dfs(int x,int have) { vis[x]=1,state[x]=have; cnt+=have,tot++; int y; for(int i=head[x];i;i=edge[i].next) { y=edge[i].to; if(have&&state[y]) { put("Impossible"); exit(0); } if(!vis[y]) dfs(y,have^1); } } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y),add_edge(y,x); for(int i=1;i<=n;++i) if(!vis[i]) cnt=tot=0,dfs(i,1),ans+=ly::min(cnt,tot-cnt); write(ans); return 0; }dfs(x,have)表示搜索到编号为 \(x\) 的点,其状态为have,表示该点是否有螃蟹。state数组记录当前每个节点的have状态。枚举与当前节点连边的节点时,若两个节点都有螃蟹则无合法方案,直接输出Impossible并用exit(0)退出程序即可。cnt和tot分别记录每个连通块中的螃蟹个数和节点总数。ans即为答案。if(!vis[y]) dfs(y,have^1);中,have^1将待搜索的节点状态设为与当前节点状态相反,保证同一条边上有且仅有一只螃蟹。
-
总结
此题为一个简单的图的遍历的应用,没有涉及其他任何算法,是一道完美的模板题。
这道题启示我们,做题时一定要:
- 看清要建的图是有向图还是无向图,无向图要双向建边,
edge开两倍大小。 - 注意图是否连通,若不连通要在每个连通块中统计答案。
我们还可以发现,把不同状态「有、无螃蟹」的点分为黑、白两种颜色,当存在一种可行方案时,不存在连接两个同色节点的边。这就是说,可以将所有节点分成两个互不相交的子集。
诶?怎么感觉这么熟悉啊?回顾一下二分图的定义:「图论基础——图的分类——二分图」
设 \(G=(V,E)\) 是一个无向图,如果顶点 \(V\) 可分割为两个互不相交的子集 \((A,B)\),并且图中的每条边 \((i,j)\) 所关联的两个顶点 \(i\) 和 \(j\) 分别属于这两个不同的顶点集,则称图 \(G\) 为一个二分图。
于是,我们愉快地发现了二分图的判定方法:染色法。或许把代码中的
have改为color你就明白了。 - 看清要建的图是有向图还是无向图,无向图要双向建边,
广度优先遍历
「Breadth-First-Search,简称 BFS」
广度优先遍历是一种按照层次顺序进行访问的方法,需要一个队列实现。
【这里的队列我用的是 namespace ly::DS 中的已封装的手写队列,常数较小,与 STL 中的 queue 用法基本相同。也可以将代码中的 ly::DS:: 去掉,引入头文件 <queue>,直接使用 STL 实现的队列。这一点在「序——说明」已说明,后文不再赘述。】
过程
- 选择一个点作为起点。
- 将起点入队并标记为已访问。
- 若队列不为空,则队头出队,遍历以队头为起点的所有边。当遍历到一条终点未入队的边时,将终点入队并标记为已访问,继续遍历其他边。
- 重复第 \(2\)~\(3\) 步,当队列为空时,遍历结束。
代码实现
很显然,这个过程非常适合用链式前向星实现。
代码如下:
#define maxn 1010
#define maxm 1010
int n,m,x,y,w;
int cnt_edge,head[maxn];
class Edge{public:int val,to,next;}edge[maxm];
inline void add_edge(int x,int y,int w){edge[++cnt_edge].to=y,edge[cnt_edge].val=w,edge[cnt_edge].next=head[x],head[x]=cnt_edge;}
bool vis[maxn];
ly::DS::queue<int>q;
void bfs(int x)
{
q.push(x),vis[x]=1;
int y;
while(!q.empty())
{
x=q.front(),q.pop(),put(x,0);
for(int i=head[x];i;i=edge[i].next)
if(!vis[y=edge[i].to]) vis[y]=1,q.push(y);
}
}
signed main()
{
read(n,m);
for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w);
for(int i=1;i<=n;++i) if(!vis[i]) bfs(i);
return 0;
}
-
!q.empty()表示队列不为空。其他也没啥好说的了。 -
访问顺序
输入样例同前面「图论基础——图的存储」给出的例子,输出结果为:
1 3 2 6 5 4 7 9 8再次画一下图:
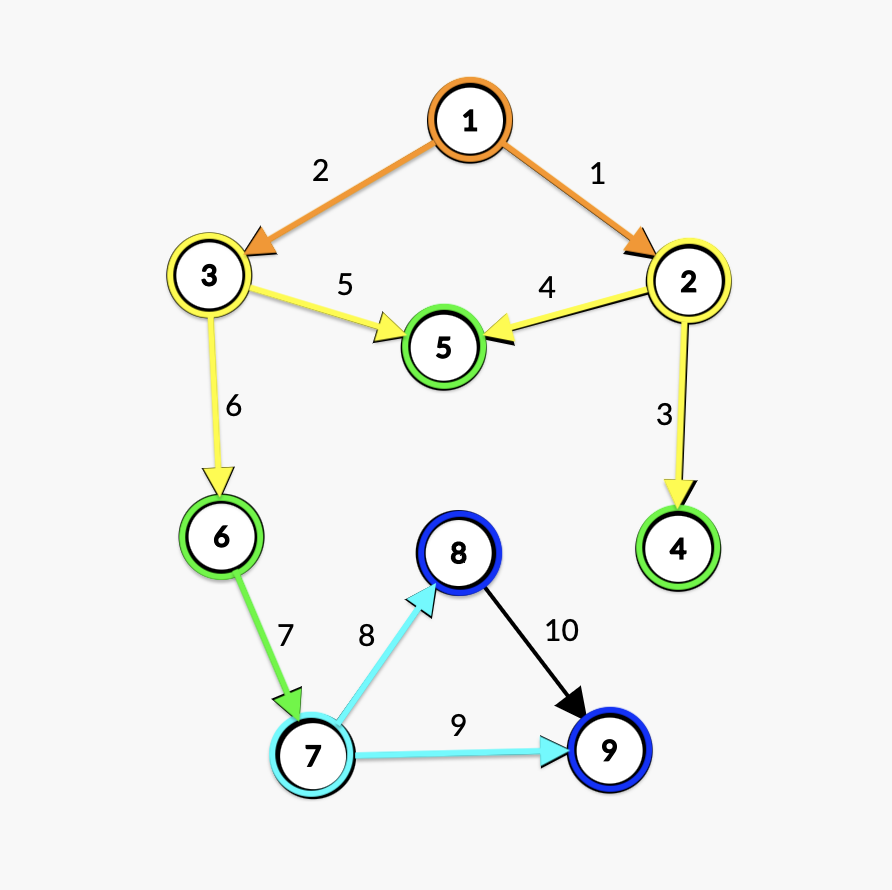
我们可以对代码略作修改,将
bool类型的vis数组改为int类型的d数组:int d[maxn]; void bfs(int x) { q.push(x),d[x]=1; int y; while(!q.empty()) { x=q.front(),q.pop(),put(x,0); for(int i=head[x];i;i=edge[i].next) if(!d[y=edge[i].to]) d[y]=d[x]+1,q.push(y); } }不难看出:对于一棵树来说,\(d[x]\) 就是点 \(x\) 在树中的深度;对于一张图来说,\(d[x]\) 被称为点 \(x\) 的层次「从起点走到点 \(x\) 需要经过的最少点数」。
从代码、示意图和 \(d\) 数组中可以发现,与 dfs 不同,bfs 的访问顺序具有很强的层次感。
具体来说,它具有两个十分重要的性质:
- 在访问完所有的第 \(i\) 层节点后,才会开始访问第 \(i+1\) 层节点。
- 任意时刻,队列中至多有两个层次的节点。若其中一部分节点属于第 \(i\) 层,则另一部分节点属于第 \(i+1\) 层,并且所有第 \(i\) 层节点排在第 \(i+1\) 层节点之前。也就是说,广度优先遍历队列中的元素关于层次满足“两段性”和“单调性”。
——李煜东《算法竞赛进阶指南》P97这两条性质是所有广度优先思想的基础。
-
与深度优先遍历一样,用链式前向星实现的广度优先遍历时间复杂度为 \(O(n+m)\)。
拓扑排序
给定一张有向无环图,若一个由图中所有点构成的序列 \(A\) 满足:对于图中的每条边 \((x,y)\),\(x\) 在 \(A\) 中 都出现在 \(y\) 之前,则称 \(A\) 是该有向无环图顶点的一个拓扑序。求解序列 \(A\) 的过程就称为拓扑排序。
——李煜东《算法竞赛进阶指南》P98
由于这一部分和边权关系不大,因此输入改为:
设图的点数为 \(n\),边数为 \(m\)。输入为第一行 \(n,m\),接下来 \(m\) 行,每行 \(2\) 个正整数 \(x,y\),表示从 \(x\) 向 \(y\) 连一条有向边。
这里给一组新的样例:
9 10
6 5
2 6
7 2
2 3
3 4
4 8
8 1
1 9
6 9
3 1
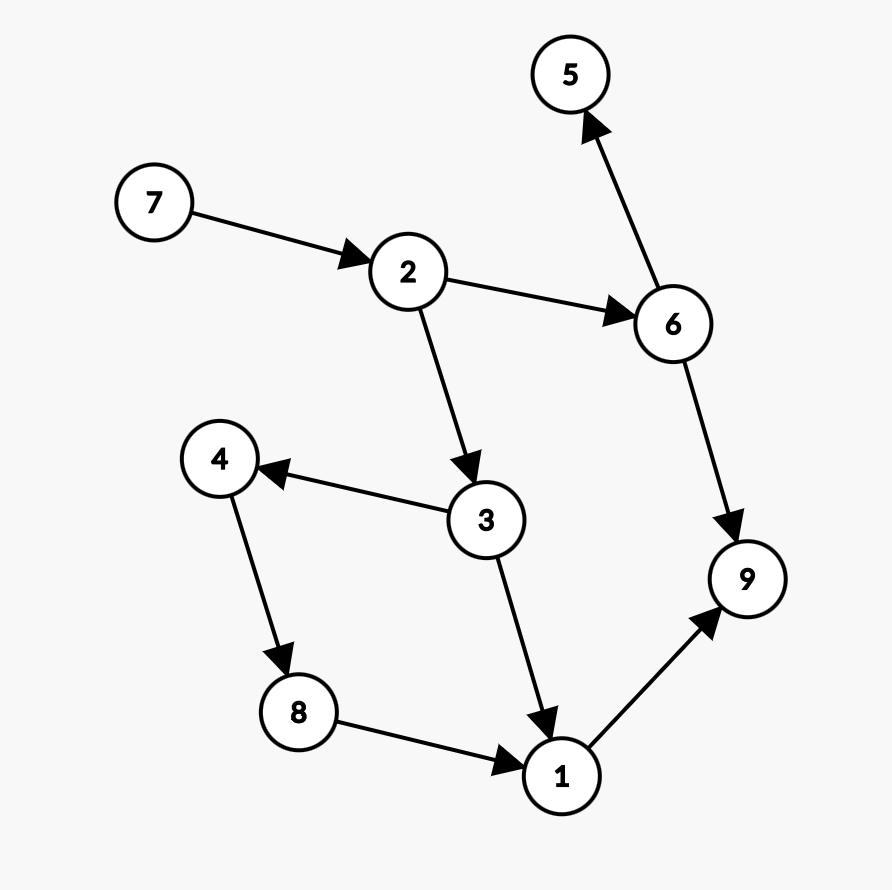
-
过程
拓扑排序的过程很简单,可以结合 bfs 的框架高效实现:
- 准备一个队列和一个空的拓扑序列 \(a\)。
- 加边时记录所有点的入度。
- 将所有入度为 \(0\) 的点入队。
- 若队列不为空,取出队头节点 \(x\),将 \(x\) 放入序列 \(a\) 的末尾。
- 遍历以 \(x\) 为起点的所有边,并将边的终点 \(y\) 入度减 \(1\)。若被减为 \(0\),则将 \(y\) 入队。
- 重复第 \(4\)~\(5\) 步直到队列为空。此时 \(a\) 即为所求。
-
模拟
下面模拟一下样例,加深对过程的理解。
要求出每个点的入度,只需要开一个
in数组,in[x]表示节点 \(x\) 的入度。每次执行add_edge(x,y)时,由于多了一条指向 \(y\) 的边,令in[y]++即可。最后求出的
in数组如下:\(x\) 1 2 3 4 5 6 7 8 \(in[x]\) 2 1 1 1 1 1 0 1 发现入度为 \(0\) 的只有节点 \(7\),于是将 \(7\) 入队。
队列中只有 \(7\),\(7\) 出队,\(x=7\) 放在了 \(a[1]\) 的位置。
以后的其他节点都只会放在 \(7\) 的后面。这是合理的,因为 \(7\) 的入度为 \(0\),\(7\) 前面没有任何节点。
接下来遍历以 \(7\) 为起点的所有边——只有
7 2,然后将边的终点 \(2\) 的入度减一,此时 \(in[2]=0\),令 \(2\) 入队。队列中只有 \(2\),\(2\) 出队,\(x=2\) 放在 \(a[2]\) 的位置。
由图可知除了节点 \(7\),没有节点在节点 \(2\) 的前面,因此这也是合理的。
遍历以 \(2\) 为起点的边——
2 3、2 6「遍历顺序与加边顺序相反」,入度减一后 \(in[3]=in[6]=0\),令 \(3\)、\(6\) 入队。队列:
3,6。\(3\) 出队放在 \(a[3]\) 的位置。这里 \(3\) 还是 \(6\) 放在 \(a[3]\) 的位置其实都可以,因为都满足拓扑序的要求。因此拓扑序列的结果不一定唯一。
「如果该图是全序图,即所有顶点之间都有优先关系,则拓扑序唯一。因此,又可以将拓扑排序描述为用某个集合上的一个偏序得到该集合上的一个全序的操作过程。【感性理解:偏序是指集合中只有部分成员可以比较,全序是指集合中所有的成员之间均可以比较。】」
接下来遍历以 \(6\) 为起点的所有边……
整个过程结束后,我们可以得到序列 \(a\):
7 2 3 6 4 5 8 1 9。可以验证,该序列中任意两个元素 \(a[i],a[j](i<j)\) 只要在图中有连边,则一定是从 \(a[i]\) 到 \(a[j]\) 的有向边。
-
判环
拓扑排序可以判定有向图中是否存在环。
若上面拓扑排序的过程结束后,\(a\) 序列的长度小于图中点的数量,则说明某些节点未被遍历,进而说明图中存在环。
举个简单的例子:
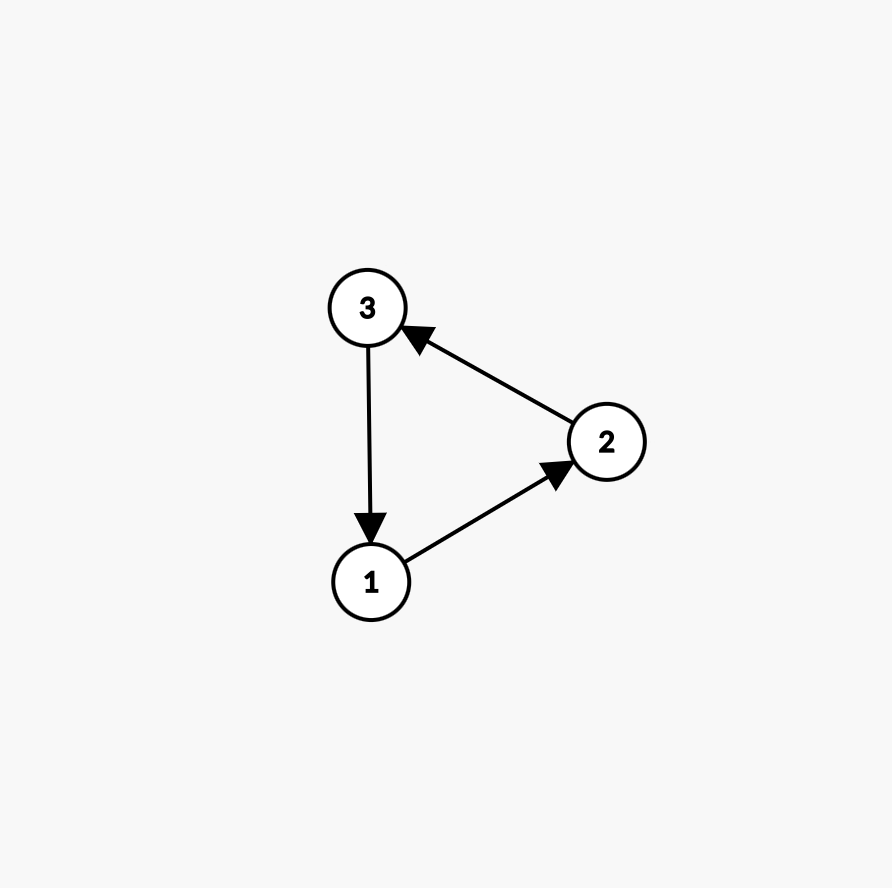
在这个最简单的环中,每个节点的入度都是 \(1\),没有点入度为 \(0\),
因此还没开始就结束了(即使再加一个入度为 \(0\) 的节点 \(4\):
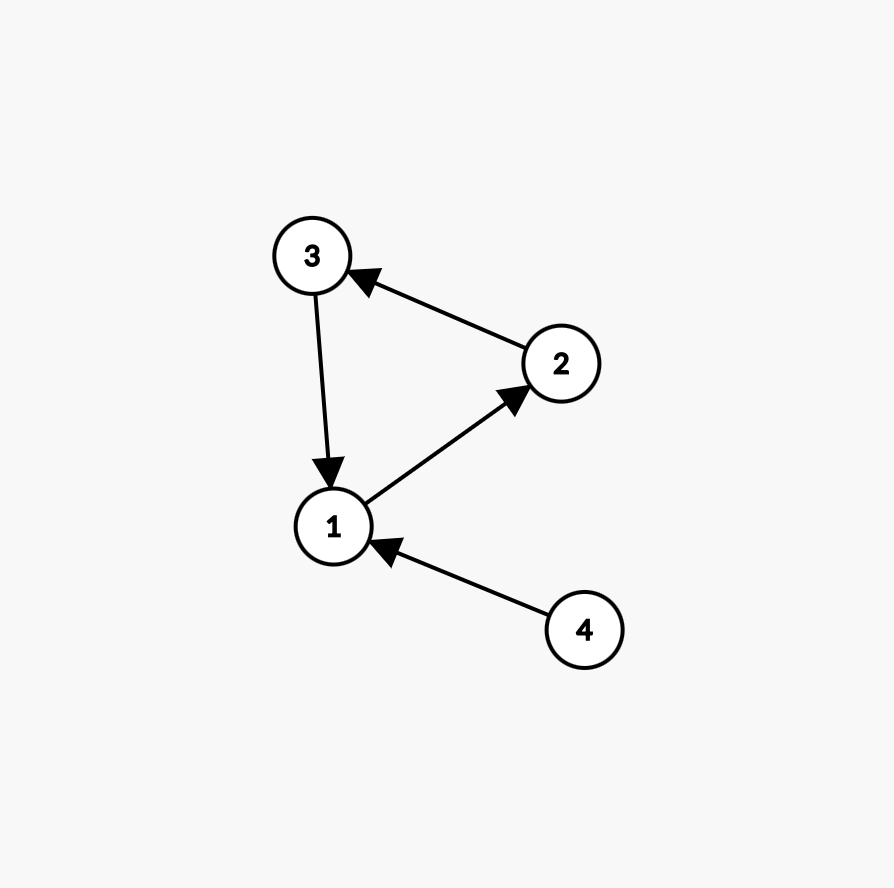
只有 \(4\) 入队。然后 \(4\) 出队,扫描与其相连的边的终点——只有 \(1\)。但由于在这个图中节点 \(1\) 的入度为 \(2\),入度减一后仍不为 \(0\),因此再次
没有进队,遗憾退役。于是拓扑排序再次提前结束,\(a\) 中只有 \(1\) 个元素,而图中有 \(4\) 个顶点,说明存在环。
-
代码实现
#define maxn 1010 #define maxm 1010 int n,m,x,y,cnt,a[maxn]; int cnt_edge,head[maxn],in[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++;} ly::DS::queue<int>q; void topsort() { for(int i=1;i<=n;++i) if(!in[i]) q.push(i); while(!q.empty()) { x=q.front(),q.pop(),a[++cnt]=x; for(int i=head[x];i;i=edge[i].next) if(!(--in[y=edge[i].to])) q.push(y); } } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); topsort(); for(int i=1;i<=cnt;++i) put(a[i],0); return 0; }- 注意到,在
add_edge函数中,加入了in[y]++以更新每个节点的入度。 for(int i=1;i<=n;++i) if(!in[i]) q.push(i);:将入度为 \(0\) 的节点入队。x=q.front(),q.pop(),a[++cnt]=x;:取出队头元素并将其加入拓扑序列。if(!(--in[y=edge[i].to])) q.push(y);:其实这是将y=edge[i].to,--in[y]和if(!in[y]) q.push(y)结合到了一起。若 \(y\) 的入度减一后为 \(0\),则将其入队。- 其实
!(--in[y=edge[i].to])的括号可以去掉,即!--in[y=edge[i].to]。 - 输出:
7 2 3 6 4 5 8 1 9,与模拟的结果相同。 - 如果
cnt<n,则说明存在环。 - 显然,和单纯的 bfs 一样,bfs 实现的拓扑排序时间复杂度也是 \(O(n+m)\)。
- 注意到,在
-
dfs 实现拓扑排序【参见《算法导论》P355】
没想到吧?dfs 也能实现拓扑排序!但由于使用较少,这里只是简单介绍,也可以直接跳过。
-
过程
其思想十分简单:回溯。
在利用 dfs 对每一个结点的遍历结束、到最后一个结点开始回溯时,前面所有点已经遍历过了,此时存下拓扑的逆序列,最后倒序输出即可。「可以简单地用栈实现,即把 \(a\) 数组看作一个栈。」
-
代码实现
#define maxn 1010 #define maxm 1010 int n,m,x,y,cnt,a[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge;} bool vis[maxn]; void dfs(int x) { vis[x]=1; for(int i=head[x];i;i=edge[i].next) if(!vis[y=edge[i].to]) dfs(y); a[++cnt]=x; return; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); for(int i=1;i<=n;++i) if(!vis[i]) dfs(i); while(cnt) put(a[cnt--],0); return 0; }可以看到,代码也十分简洁。与 bfs 实现的区别主要有:
-
bfs 用队列,这里用的是栈。「最后
while(cnt) put(a[cnt--],0);倒序输出。」 -
bfs 要记录入度,这里无需记录入度但要用
vis记录每个节点是否访问。 -
bfs 在出队时加入拓扑序列,这里在回溯时加入。
-
还有一点。
有木有发现,基于 dfs 的拓扑排序需要
for(int i=1;i<=n;++i) if(!vis[i]) dfs(i);以防图不连通的情况,但基于 bfs 的拓扑排序似乎不需要像这样单独遍历所有点?这是因为,bfs 实现的拓扑排序在寻找入度为 \(0\) 的点时已经考虑每个连通块内的点了。最后扫描节点出边时,入队的是图中所有连通块的节点。
-
-
输出:
7 2 6 5 3 4 8 1 9。虽然与bfs得到的结果不同,但确确实实也是正确的拓扑序。毕竟前面说了拓扑序不一定唯一嘛。 -
判环
dfs 实现的拓扑排序判环也很简单,如果在往后搜的过程中搜到前面搜过但未回溯的节点,说明存在环,直接返回即可。
具体操作是将
vis数组改为int类型,\(0\) 表示未访问,\(1\) 表示已访问但未回溯,\(2\) 表示已回溯。代码实现:
#define maxn 1010 #define maxm 1010 int n,m,x,y,cnt,a[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge;} int vis[maxn]; void dfs(int x) { vis[x]=1; for(int i=head[x];i;i=edge[i].next) { if(!vis[y=edge[i].to]) dfs(y); else if(vis[y]==1) return; } a[++cnt]=x,vis[x]=2; return; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); for(int i=1;i<=n;++i) if(!vis[i]) dfs(i); while(cnt) put(a[cnt--],0); return 0; }else if(vis[y]==1) return;使得有环情况提前回溯,否则最后cnt和n相等,无法判断是否有环。- 回溯结束时
vis[x]=2标记已回溯。
拓扑排序结束后,和 bfs 实现的拓扑排序判环一样,最后只需判断是否有
cnt<n即可。 -
显然,和单纯的 dfs 一样,dfs 实现的拓扑排序时间复杂度也是 \(O(n+m)\)。
总体来说,bfs 和 dfs 都能实现拓扑排序和判环操作,且时间复杂度相同。但鉴于 bfs 实现的拓扑排序更为经典和流行,加之本人习惯,后文除特殊说明,统一用 bfs 实现拓扑排序。两种算法各有特点,实际运用中熟练掌握一种即可。
-
例题
【洛谷P4017 最大食物链计数】
「板子题」
-
题意简述
- 给定一张 \(n\) 个点、\(m\) 条边的有向无环图,求图中路径总数。
- 这里的路径要求起点入度为 \(0\)、终点出度为 \(0\)。
- 答案对
80112002取模。 - 数据范围:\(n\le5\times10^3,m\le5\times10^5\)。
-
思路一
-
设 \(f[x]\) 为以 \(x\) 为起点的路径数,\(a_1,a_2,...,a_k\) 为与 \(x\) 直接相连的后继节点。
-
显然有 \(f[x]=f[a_1]+f[a_2]+...+f[a_k]\)。
-
容易想到一个暴力的做法。
将每个入度为 \(0\) 的节点当作起点,直接
dfs递归计算其路径数并累加统计答案。若当前节点出度为 \(0\),直接返回 \(1\) 即可。「以该节点为起点的路径只有一条。」
「入度和出度都可以在一开始加边时计算。每加一条边,必然有起点出度加一、终点入度加一。」
核心代码:
constexpr auto maxn=5010; constexpr auto maxm=500010; int n,m,x,y; ll ans,p=80112002; int cnt_edge,head[maxn],in[maxn],out[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++,out[x]++;} ll dfs(int x) { if(!out[x]) return 1; ll res=0; for(int i=head[x];i;i=edge[i].next) res+=dfs(edge[i].to),res%=p; return res; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); for(int i=1;i<=n;++i) if(!in[i]) ans+=dfs(i),ans%=p; put(ans); return 0; } -
然而这样做只有 \(20pts\),后面全 TLE。
-
简单分析一下该算法的时间复杂度。
若图中存在 \(t\) 个汇点「这里姑且定义汇点为下图的节点 \(8\) 的形式,与网络流中的汇点不同」,每两个汇点之间有 \(k\) 个互相“独立”的点「如下图节点 \(2\) 到节点 \(7\)」。
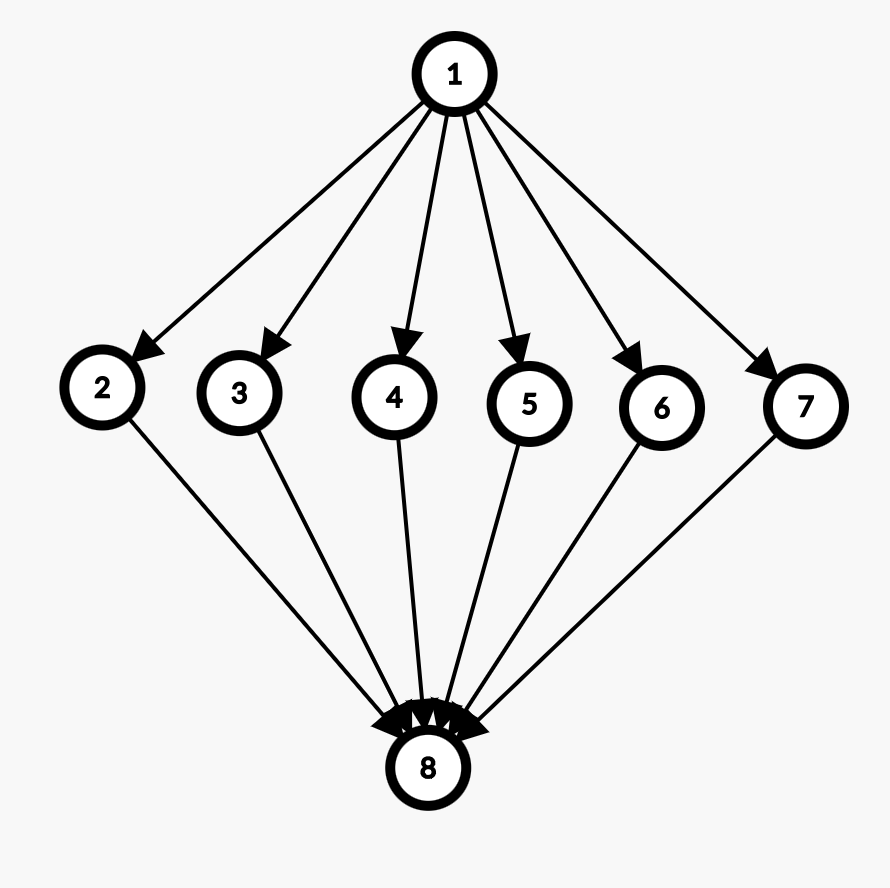
则从 \(1\) 号节点「汇点」到 \(n\) 号节点「汇点」可以走的路径数大约为 \(k^t\),总节点数 \(n\) 和 \(m\) 都大约为 \(kt\) 级别。
那么从上到下执行 dfs 的次数大概是:
\[\sum_{i=0}^{t-1}k^i=\frac{k^t-1}{k-1} \]大致也是 \(k^t\) 级别,显然过不了。
-
优化
容易发现从上到下搜索的过程中有大量重复计算,比如若在上图中 \(8\) 号节点下面还有许多其他节点,那么调用
dfs(1)后递归调用的dfs(2)、dfs(3)、...、dfs(7)会重复调用 \(6\) 次dfs(8)。为了提高效率、避免重复计算,可以对搜索过程记忆化。简单来说,开一个
f数组存一下每个节点的答案,每当一个节点 \(x\) 的dfs搜索结束,可以在回溯前用f数组保存本次搜索结果「f[x]=res」。以后在调用dfs(x)时直接返回f[x]的值即可。同时,由于取模运算很慢,可以改用三目运算符做减法运算,优化常数。
核心代码:
constexpr auto maxn=5010; constexpr auto maxm=500010; int n,m,x,y; ll ans,p=80112002,f[maxn]; int cnt_edge,head[maxn],in[maxn],out[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++,out[x]++;} ll dfs(int x) { if(f[x]) return f[x]; if(!out[x]) return f[x]=1; ll res=0; for(int i=head[x];i;i=edge[i].next) res+=dfs(edge[i].to),res-=(res<p?0:p); return f[x]=res; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); for(int i=1;i<=n;++i) if(!in[i]) ans+=dfs(i),ans-=(ans<p?0:p); put(ans); return 0; } -
时间复杂度 \(O(n+m)\),AC。
-
-
思路二
-
这次我们设 \(f[x]\) 为以 \(x\) 为终点的路径数,\(a_1,a_2,...,a_k\) 为与 \(x\) 直接相连的前驱节点。
-
则同样显然有 \(f[x]=f[a_1]+f[a_2]+...+f[a_k]\)。
-
这一次我们不再
乱搜,而是考虑更新顺序,按照顺序依次更新每个节点的 \(f\) 值。 -
由于每个节点的 \(f\) 值只与其前驱节点有关,因此要保证更新顺序为前驱节点在前、该节点本身在后。
-
很容易想到拓扑序满足这个性质,因此可以对该图进行拓扑排序,按照求出的拓扑序的顺序对每个节点扫描其前驱节点更新答案。
-
初始化:如果节点入度为 \(0\),则其 \(f\) 值为 \(1\)。
-
核心代码
constexpr auto maxn=5010; constexpr auto maxm=500010; int n,m,x,y; ll ans,p=80112002,f[maxn]; int cnt_edge,head[maxn],in[maxn],out[maxn]; class Edge{public:int to,next;}edge[maxm]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++,out[x]++;} ly::DS::queue<int>q; void topsort() { for(int i=1;i<=n;++i) if(!in[i]) q.push(i),f[i]=1; while(!q.empty()) { x=q.front(),q.pop(); for(int i=head[x];i;i=edge[i].next) { if(!--in[y=edge[i].to]) q.push(y); f[y]+=f[x],f[y]=(f[y]<p?f[y]:f[y]-p); } } } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y),add_edge(x,y); topsort(); for(int i=1;i<=n;++i) if(!out[i]) ans+=f[i],ans=(ans<p?ans:ans-p); put(ans); return 0; } -
时间复杂度 \(O(n+m)\),AC。
-
【洛谷P1983 「NOIP2013 普及组」车站分级】
「不那么板子的题」
-
题意简述
- 一条单向铁路上依次有编号为 \(1\) 到 \(n\) 的 \(n\) 个车站和 \(m\) 条线路,每个车站有一个级别「最小为 \(1\)」。
- 每条线路若停靠了车站 \(x\),则一定停靠了始发站和终点站间所有级别 \(\ge x\) 的车站「包括始发站和终点站」。
- 问最少要将车站分为多少个级别,才能使每条线路都满足上述条件?
- 输出最少级别数,保证存在方案。
- 数据范围:\(1\le n,m\le1000\)。
-
思路
-
由题意得,在一条线路中,未停靠的车站级别一定小于停靠了的车站的级别。
-
可以考虑建图。
-
用有向边
i->j表示车站 \(i\) 的级别小于车站 \(j\)。 -
对每条线路涉及的所有线路这样加边,最后得到的图的最长路径的长度即为所求最小级别数。
-
可以用 dfs、bfs 或拓扑排序求最长路径的长度。这里以拓扑排序为例。
-
用 \(f[x]\) 表示以 \(x\) 为终点的最长路径的长度,则显然有:
- 若 \(x\) 入度为 \(0\),则 \(f[x]=1\)。
- 若 \(x\) 的后继节点为 \(y\),则 \(f[y]=f[x]+1\)。
-
因此可以进行拓扑排序,从入度为 \(0\) 的节点开始更新其后继节点,直到所有节点被扫描完毕。
-
过程中可以用 \(ans\) 取所有 \(f[x]\) 的最大值,拓扑排序后 \(ans\) 即为答案。
-
核心代码
constexpr auto maxn=1010; int n,m,t,l,r,x,y,ans,a[maxn],b[maxn],f[maxn]; bool vis[maxn][maxn]; int cnt_edge,head[maxn],in[maxn]; class Edge{public:int to,next;}edge[maxn*maxn]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++;} ly::DS::queue<int>q; void topsort() { for(int i=1;i<=n;++i) if(!in[i]) q.push(i),f[i]=1; while(!q.empty()) { x=q.front(),q.pop(); for(int i=head[x];i;i=edge[i].next) { if(!--in[y=edge[i].to]) q.push(y); f[y]=f[x]+1; } } ans=ly::max(ans,f[x]); } signed main() { read(n,m); while(m--) { for(int i=1;i<=n;++i) b[i]=0; read(t); for(int i=1;i<=t;++i) read(a[i]),b[a[i]]=1; l=a[1],r=a[t]; for(int i=1;i<=t;++i) for(int j=l+1;j<r;++j) if(!vis[j][a[i]]&&!b[j]) vis[j][a[i]]=1,add_edge(j,a[i]); } topsort(); put(ans); return 0; }-
注意建图时,若不考虑重复加边,最终边数会在 \(mn^2\) 级别,存不下「会 \(\color{purple}RE\) 或 \(MLE\)」。因此可以用 \(vis[i][j]\) 表示 \(i\) 到 \(j\) 之间是否有连边,若 \(vis[i][j]=1\) 则无需再次加边。这样可以使边数降到 \(n^2\) 级别。
-
边数最多在 \(n^2\) 级别,因此
edge大小要开到maxn*maxn。 -
if(!vis[j][a[i]]&&!b[j]) vis[j][a[i]]=1,add_edge(j,a[i]);a[i]是当前线路中第 \(i\) 个停靠的车站,!b[j]说明位于 \(a[1]\) 到 \(a[t]\) 之间的车站 \(j\) 未停靠。根据上面的分析,车站 \(j\) 的级别小于车站 \(a[i]\),因此从 \(j\) 向 \(a[i]\) 连边。如果vis[j][a[i]]==1说明之前已经连过这条边了,为了节省空间无需再次连边。 -
ans=ly::max(ans,f[x]);:所有节点 \(f\) 中的最大值即为答案。
-
-
-
优化
-
上面的做法按理来讲并不能过掉 \(100\%\) 的数据,
但由于数据太水了实际上可以 AC。 -
其瓶颈主要在于时间复杂度为 \(O(mn^2)\)。「空间复杂度通过避免重复加边,已从 \(O(mn^2)\) 降至 \(O(n^2)\)。」
-
这里有一个巧妙的做法:对每条线路用一个“虚点”作中转。
所有未停靠的车站向虚点连边,虚点向所有停靠了的车站连边。
-
这样仍然能保证所有点的先后顺序正确,但是时间复杂度降到了 \(O(mn)\) 级别。同时,无需用 \(vis\) 数组避免重复加边,空间复杂度同样在 \(O(n^2)\) 级别。
-
怎么建立虚点?一个简单的想法是对于第 \(i\) 条线路,用第 \(n+i\) 号点作为“虚点”。
-
同时,在计算以每个节点为终点的最长路径 \(f\) 数组时,注意虚点对路径长度没有贡献!
具体来讲,对于
x->y->z「\(y\) 为虚点」的情形,我们希望得到的是f[z]=f[x]+1。若像以前一样f[y]=f[x]+1、f[z]=f[y]+1,这样会得到f[z]=f[x]+2。因此,只需要判断 \(y\) 是否是虚点「即 \(y\) 是否 \(>n\)」,若 \(y\) 为虚点则只进行f[y]=f[x]+1、f[z]=f[y]+1二者之一的操作即可。 -
核心代码「只需在先前代码上略作修改即可。」
constexpr auto maxn=1010; int n,m,t,l,r,x,y,ans,b[maxn],f[maxn<<1]; int cnt_edge,head[maxn<<1],in[maxn<<1]; class Edge{public:int to,next;}edge[maxn*maxn]; inline void add_edge(int x,int y){edge[++cnt_edge].to=y,edge[cnt_edge].next=head[x],head[x]=cnt_edge,in[y]++;} ly::DS::queue<int>q; void topsort() { for(int i=1;i<=n;++i) if(!in[i]) q.push(i),f[i]=1; for(int i=n+1;i<=n+m;++i) if(!in[i]) q.push(i); while(!q.empty()) { x=q.front(),q.pop(); for(int i=head[x];i;i=edge[i].next) { if(!--in[y=edge[i].to]) q.push(y); f[y]=f[x]+(y<=n); } } ans=ly::max(ans,f[x]); } signed main() { read(n,m); for(int j=1;j<=m;++j) { for(int i=1;i<=n;++i) b[i]=0; read(t,l),b[l]=1; for(int i=2;i<t;++i) read(x),b[x]=1; read(r),b[r]=1; for(int i=l;i<=r;++i) if(b[i]) add_edge(n+j,i); else add_edge(i,n+j); } topsort(); put(ans); return 0; }- 先前的 \(a\)、\(vis\) 数组都没用了。
- 由于加入虚点「\(m\) 个虚点」,因此与虚点有关的数组「\(f\)、\(head\)、\(in\)」都要将大小开为两倍。
- 注意入度为 \(0\) 的虚点也要加入队列,但无需令其 \(f\) 值为 \(1\)。
f[y]=f[x]+(y<=n);:若y<=n,则 \(y\) 不是虚点,f[y]=f[x]+1;否则 \(y\) 是虚点,f[y]=f[x]。这样可以保证虚点不影响答案。
-
-
对比
-
优化前

用时:1.25s。
-
优化后
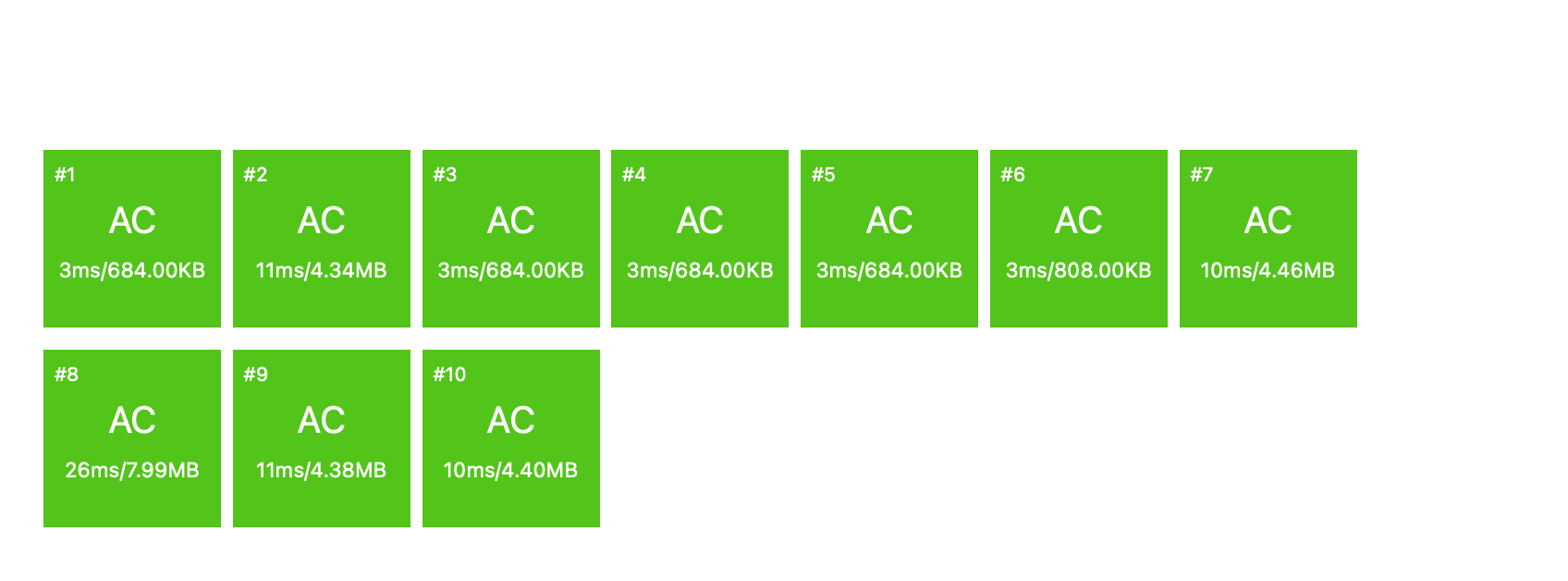
用时:83ms。
显然,优化效果还是很明显的。再优化一下常数,进 rank 前十也不是不可能。
据说还有一种更优秀的做法:拓扑排序 + 虚点优化 + 线段树优化连边。空间复杂度 \(O(n\log n)\)。
这里就不多做介绍,先给出【链接】。以后复习到线段树优化建图再说吧。
-
基本算法
最短路
这部分大家都很熟悉了,知识部分将尽可能简练,但会保留很多重要细节。后面会给出一些模板题和比较好的例题。
更多内容可以参考李煜东《算法竞赛进阶指南》0x61最短路 和【OI Wiki-最短路】。
Floyd
-
用途:求解无负环图全源最短路「任意两点间最短路」。
-
本质:动态规划。
-
思想
设 \(f[k,i,j]\) 表示经过若干个编号不超过 \(k\) 的节点从 \(i\) 到 \(j\) 的最短路长度。
显然可以将该问题划分为两个子问题:
- 经过编号不超过 \(k-1\) 的节点从 \(i\) 到 \(j\) 的最短路长度。「即 \(f[k-1,i,j]\)。」
- 从 \(i\) 先到 \(k\) 再到 \(j\) 的最短路长度。「即 \(f[k-1,i,k]+f[k-1,k,j]\)。」
写成状态转移方程就是:
\[f[k,i,j]=\min(f[k-1,i,j],f[k-1,i,k]+f[k-1,k,j]) \]初始状态:\(f[0,i,j]=a[i][j]\),其中 \(a\) 为输入的邻接矩阵。
很显然,\(k\) 是阶段,所以必须放在最外层循环。\(i\) 和 \(j\) 是状态,所以应该放在内层循环。
同时,可以利用滚动数组的思想将 \(k\) 这一维滚掉,使空间复杂度降为 \(O(n^2)\)。
\[f[i,j]=\min(f[i,j],f[i,k]+f[k,j]) \]算法结束时,\(f[i,j]\) 即为 \(i\) 到 \(j\) 的最短路长度。
-
核心代码
constexpr auto INF=0x3f3f3f3f; constexpr auto maxn=110; int n,m,x,y,w,f[maxn][maxn]; signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) f[i][j]=INF; for(int i=1;i<=m;++i) read(x,y,w),f[x][y]=f[y][x]=ly::min(f[x][y],w); for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) f[i][j]=ly::min(f[i][j],f[i][k]+f[k][j]); return 0; }-
INF设为0x3f3f3f3f而不设为0x7f7f7f7f或INT_MAX的原因是防止f[i][k]+f[k][j]爆int。「
0x3f3f3f3f的两倍是 \(2122219134\),在int范围内。」 -
输入的边有重边时,用邻接矩阵存边权要取 \(\min\),即 \(f[x][y]=\min(f[x][y],w)\)。
-
-
时间复杂度:\(O(n^3)\)。
-
空间复杂度:\(O(n^2)\)。
-
传递闭包
在交际网络中,给定若干个元素和若干对二元关系,且关系具有传递性「设 \(\odot\) 是定义在集合 \(S\) 上的二元关系,若对于 \(\forall a,b,c\in S\),只要有 \(a\odot b\) 且 \(b\odot c\),就必然有 \(a\odot c\),则称关系 \(\odot\) 具有传递性。」。“通过传递性推导出尽量多的元素之间的关系”的问题被称为传递闭包。
——李煜东《算法竞赛进阶指南》P359举个例子。“小于”关系显然具有传递性,即:若 \(a<b,b<c\),则 \(a<c\)。
建立邻接矩阵 \(f\),其中 \(f[i,j]=1\) 表示 \(i\) 与 \(j\) 有关系,\(f[i,j]=0\) 表示 \(i\) 与\(j\) 没有关系。利用 Floyd 算法可以解决传递闭包问题。
-
代码实现
for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) f[i][j]|=f[i][k]&f[k][j];注:《算法竞赛进阶指南》中认定 \(f[i,i]\) 始终为 \(1\),其实是错误的。比如 \(<\) 关系,不满足 \(a<a\)。「已在 Github 上反馈。」
-
bitset 优化「参考【OI Wiki-最短路】」
进一步用 bitset 优化,复杂度可以到 \(O(\frac{n^3}w)\)。
std::bitset<maxn>f[maxn]; for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) if(f[i][k]) f[i]|=f[k];
-
Dijkstra
-
用途:求解非负权图单源最短路。
-
松弛操作
对于边 \((x,y)\),松弛操作对应这个式子:\(dis(y)=\min\set{dis(y),dis(x)+w(x,y)}\)。
-
过程 & 时间复杂度「摘自【OI Wiki-最短路】」
过程
将结点分成两个集合:已确定最短路长度的点集(记为 \(S\) 集合)的和未确定最短路长度的点集(记为 \(T\) 集合)。一开始所有的点都属于 \(T\) 集合。
初始化 \(dis(s)=0\),其他点的 \(dis\) 均为 \(+\infty\)。
然后重复这些操作:
- 从 \(T\) 集合中,选取一个最短路长度最小的结点,移到 \(S\) 集合中。
- 对那些刚刚被加入 \(S\) 集合的结点的所有出边执行松弛操作。
直到 \(T\) 集合为空,算法结束。
时间复杂度
有多种方法来维护 1 操作中最短路长度最小的结点,不同的实现导致了 Dijkstra 算法时间复杂度上的差异。
- 暴力:不使用任何数据结构进行维护,每次 2 操作执行完毕后,直接在 \(T\) 集合中暴力寻找最短路长度最小的结点。2 操作总时间复杂度为 \(O(m)\),1 操作总时间复杂度为 \(O(n^2)\),全过程的时间复杂度为 \(O(n^2 + m) = O(n^2)\)。
- 二叉堆:每成功松弛一条边 \((u,v)\),就将 \(v\) 插入二叉堆中(如果 \(v\) 已经在二叉堆中,直接修改相应元素的权值即可),1 操作直接取堆顶结点即可。共计 \(O(m)\) 次二叉堆上的插入(修改)操作,\(O(n)\) 次删除堆顶操作,而插入(修改)和删除的时间复杂度均为 \(O(\log n)\),时间复杂度为 \(O((n+m) \log n) = O(m \log n)\)。
- 优先队列:和二叉堆类似,但使用优先队列时,如果同一个点的最短路被更新多次,因为先前更新时插入的元素不能被删除,也不能被修改,只能留在优先队列中,故优先队列内的元素个数是 \(O(m)\) 的,时间复杂度为 \(O(m \log m)\)。
- Fibonacci 堆:和前面二者类似,但 Fibonacci 堆插入的时间复杂度为 \(O(1)\),故时间复杂度为 \(O(n \log n + m) = O(n \log n)\),时间复杂度最优。但因为 Fibonacci 堆较二叉堆不易实现,效率优势也不够大,算法竞赛中较少使用。
- 线段树:和二叉堆原理类似,不过将每次成功松弛后插入二叉堆的操作改为在线段树上执行单点修改,而 1 操作则是线段树上的全局查询最小值。时间复杂度为 \(O(m \log n)\)。
在稀疏图中,\(m = O(n)\),使用二叉堆实现的 Dijkstra 算法较 Bellman-Ford 算法具有较大的效率优势;而在稠密图中,\(m = O(n^2)\),这时候使用暴力做法较二叉堆实现更优。
在《算法竞赛进阶指南》P351 原文中有一段错误的分析:
上面程序的时间复杂度为 \(O(n^2)\),主要瓶颈在于第 \(1\) 步的寻找全局最小值的过程。可以用二叉堆(C++ STL priority_queue,0x71 节)对 \(dist\) 数组进行维护,用 \(O(\log n)\) 的时间获取最小值并从堆中删除,用 \(O(\log n)\) 的时间执行一条边的扩展和更新,最终可在 \(O(m\log n)\) 的时间[1]内实现 Dijkstra 算法。
前面 OI Wiki 中的解释已经很清楚了,优先队列中先前插入更新时的元素不能被删除/修改,只能留在优先队列中,且同一个点的最短路可能被更新多次,因此优先队列内元素个数为 \(O(m)\) 级别,时间复杂度也就为 \(O((n+m)\log m)=O(m\log m)\)。
本人已在【GitHub Tedukuri】作为【issue】提出该错误,欢迎前来评论或完善~
-
细节
-
未知点中 \(dis\) 值最小的点的 \(dis\) 值就是起点到它的最短路径长度,因为该点的 \(dis\) 值不可能再被其他点的 \(dis\) 值更新。
-
\(vis\) 数组记录该点是否已更新。已更新的点无需更新。
-
图中可以存在重边和自环,但不能有负边权。
-
关于 Fibonacci 堆
这里引用 minghu6 的评论:
最小生成树和这里都提到了 Fib 堆,这里稍微讲一下,由于完整的 Fib 依赖链表结构(这种算法就是靠指针跳来跳去来实现看起来很优的理论时间复杂度),它有三大优点:
- 代码行数多。
- 实现容易出错。
- 在大缓存的 CPU 架构下实际表现特别差。
而相对地,二叉堆不仅实现简单,而且可以在一块儿连续内存上实现,不仅简单而且非常快。
-
-
说明
除特殊说明,下文统一用 C++ STL 中的
priority_queue优化 Dijkstra 算法「因为好写」,时间复杂度 \(O(m\log m)\)。「
你非得让 \(m=0\) 我也不好说啥……」
Bellman-Ford 和 SPFA
「以下引用内容参考《算法竞赛进阶指南》P353。」
-
用途:求解单源最短路。「可以有负权。」
-
三角形不等式
给定一张有向图,若对于图中的某一条边 \((x,y,w)\),有 \(dis[y]\le dis[x]+w\) 成立,则称该边满足三角形不等式。若所有边都满足三角形不等式,则 \(dis\) 数组就是所求最短路。
先介绍基于迭代思想的 Bellman-Ford 算法。
- 过程
- 扫描所有边 \((x,y,w)\),若 \(dis[y]>dis[x]+w\),则用 \(dis[x]+w\) 更新 \(dis[y]\)。
- 重复上述步骤,直到没有更新操作发生。
- 时间复杂度:\(O(nm)\)。
下面介绍 SPFA 算法。
事实上,SPFA 算法在国际上通称为“队列优化的 Bellman-Ford 算法”,仅在中国大陆流行“SPFA 算法”的称谓。
- 过程
- 建立一个队列,最初队列中只有起点 \(s\)。
- 取出队头节点 \(x\),扫描它的所有出边 \((x,y,w)\),若 \(dis[y]>dis[x]+w\),则用 \(dis[x]+w\) 更新 \(dis[y]\)。同时,若 \(y\) 不在队列中,则把 \(y\) 入队。
- 若队列为空,算法结束。否则重复第 \(2\) 步。
在任意时刻,该算法的队列都保存了待扩展的节点。每次入队相当于完成一次 \(dis\) 数组的更新操作,使其满足三角形不等式。一个节点可能会入队、出队多次。最终图中节点收敛到全部满足三角形不等式的状态。这个队列避免了 Bellman-Ford 算法中对不需要扩展的节点的冗余扫描,在随机图上运行效率为 \(O(km)\) 级别,其中 \(k\) 是一个较小的常数。但在特殊构造的图上,该算法很可能退化为 \(O(nm)\) 级别,必须谨慎使用。
- 细节
- \(vis\) 数组记录该点是否在队列中。在队列中的点无需入队。「注意与 Dijkstra 算法中的 \(vis\) 数组的区别。」
- 图中可以存在负边权。
- 如果图中不存在负边权,那么可以用优先队列「堆」代替一般的队列对 SPFA 算法进行优化,每次取出“当前距离最小”的节点「堆顶」进行扩展,节点第一次从堆中取出时就得到了该点的最短路。这与 Dijkstra 算法的流程完全一致,二者殊途同归。
- 关于 spfa 的各种卡法,详见【如何卡spfa】。
Johnson
- 用途:和 Floyd 相同,求解无负环图全源最短路。
- 思想:在保证最短路不变的条件下将边权映射到正数,从而利用 Dijkstra 求出每个节点的单源最短路。
- 过程
- 新建一个虚拟节点「在这里设其编号为 \(0\)」,从该点向其他所有点连一条边权为 \(0\) 的边。
- 用 Bellman-Ford 求出从 \(0\) 号点到其他所有点的最短路,记为 \(h_i\)。
- 对每条边 \((x,y,w)\),将其边权重新设置为 \(w+h_x-h_y\)。
- 以每个点为起点,跑 \(n\) 轮 Dijkstra 即可求出任意两点间的最短路。
- 时间复杂度:\(O(nm\log m)\)。
- 详细内容请直接传送至讲解得十分清晰易懂的【OI Wiki-最短路-Johnson 全源最短路径算法】。更严谨的内容可以参考《算法导论》P409「25.3 用于稀疏图的 Johnson 算法」。
- 扩展
- 虽然 Johnson 是很优秀的全源最短路算法,但是实际应用中全源最短路似乎并不常见……更常见的还是单源最短路。
- 用 Bellman-Ford 求解单源最短路的时间复杂度为 \(O(nm)\),无论是在稀疏图还是稠密图上都不如 Dijkstra。「稀疏图堆优化:\(O(m\log n)\)。稠密图:\(O(n^2)\)。」
- 但在求解费用流问题时,网络上存在单位费用为负的边,无法直接使用 Dijkstra 算法。
- 这时我们可以借鉴 Johnson 算法的思想:为每个节点设置一个势能,将所有边的费用映射为非负值。
- 这就是所谓的 Primal-Dual 原始对偶算法。关于该算法的更多详细内容可以参考【OI Wiki-网络流-费用流-Primal-Dual 原始对偶算法】。
例题
模板题
【洛谷B3647「模板」Floyd 算法】
-
核心代码
constexpr auto INF=0x3f3f3f3f; constexpr auto maxn=110; int n,m,x,y,w,f[maxn][maxn]; signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) f[i][j]=INF; for(int i=1;i<=m;++i) read(x,y,w),f[x][y]=f[y][x]=ly::min(f[x][y],w); for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) f[i][j]=ly::min(f[i][j],f[i][k]+f[k][j]); for(int i=1;i<=n;++i) { for(int j=1;j<=n;++j) put(f[i][j],0); write('\n'); } return 0; }
【洛谷B3611「模板」传递闭包】
-
核心代码
constexpr auto maxn=110; int n,f[maxn][maxn]; signed main() { read(n); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) read(f[i][j]); for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) f[i][j]|=f[i][k]&f[k][j]; for(int i=1;i<=n;++i) { for(int j=1;j<=n;++j) put(f[i][j],0); write('\n'); } return 0; }
【洛谷P3371「模板」单源最短路径(弱化版)】
-
Dijkstra「\(O(nm)\)」「\(70pts\),MLE」
核心代码:
constexpr auto INF=(1ll<<31)-1; constexpr auto maxn=10010; int n,m,s,x,y,w,a[maxn][maxn]; ll f[maxn]; int vis[maxn]; inline void Dijkstra() { for(int T=1;T<n;++T) { x=0; for(int i=1;i<=n;++i) if(!vis[i]&&(!x||f[i]<f[x])) x=i; vis[x]=1; for(int i=1;i<=n;++i) f[i]=ly::min(f[i],f[x]+a[x][i]); } } signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) a[i][j]=INF; for(int i=1;i<=n;++i) f[i]=INF; f[read(s)]=0; for(int i=1;i<=m;++i) read(x,y,w),a[x][y]=ly::min(a[x][y],w); Dijkstra(); for(int i=1;i<=n;++i) put(f[i],0); return 0; } -
Dijkstra「\(O(m\log m)\)」「\(100pts\)」
链式前向星无需考虑重边。
核心代码:
constexpr auto INF=(1ll<<31)-1; constexpr auto maxn=10010; constexpr auto maxm=500010; int n,m,s,x,y,w; ll f[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm]; auto add_edge=[](auto x,auto y,auto w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn]; class node{public:int i;ll w;bool operator<(const node &a)const{return w>a.w;}}; priority_queue<node>q; inline void Dijkstra() { q.push({s,0}); while(!q.empty()) { x=q.top().i,q.pop(); if(vis[x]) continue; vis[x]=1; for(int i=head[x];i;i=edge[i].next) if(f[y=edge[i].to]>f[x]+(w=edge[i].w)) f[y]=f[x]+w,q.push({y,f[y]}); } } signed main() { read(n,m); for(int i=1;i<=n;++i) f[i]=INF; f[read(s)]=0; for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); Dijkstra(); for(int i=1;i<=n;++i) put(f[i],0); return 0; } -
spfa「\(O(km)\)」「\(100pts\)」
核心代码:
constexpr auto INF=(1ll<<31)-1; constexpr auto maxn=10010; constexpr auto maxm=500010; int n,m,s,x,y,w; ll f[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm]; auto add_edge=[](auto x,auto y,auto w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn]; queue<int>q; inline void spfa() { q.push(s),vis[s]=1; while(!q.empty()) { x=q.front(),q.pop(); vis[x]=0; for(int i=head[x];i;i=edge[i].next) if(f[y=edge[i].to]>f[x]+(w=edge[i].w)) { f[y]=f[x]+w,q.push(y); if(!vis[y]) q.push(y),vis[y]=1; } } } signed main() { read(n,m); for(int i=1;i<=n;++i) f[i]=INF; f[read(s)]=0; for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); spfa(); for(int i=1;i<=n;++i) put(f[i],0); return 0; }
【洛谷P4779「模板」单源最短路径(标准版)】
-
Dijkstra「\(O(m\log m)\)」「\(100pts\)」
同上。只需要改一下数组大小即可。
constexpr auto maxn=100010; constexpr auto maxm=200010; -
spfa「\(O(nm)\)」「\(32pts\),TLE」
本题卡 spfa,时间复杂度退化为 \(O(nm)\)。
【洛谷B3601 最短路问题_1】
-
核心代码「spfa,\(O(km)\)」
constexpr auto maxn=2010; constexpr auto maxm=2010; int n,m,x,y,w; ll f[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm]; auto add_edge=[](int x,int y,int w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn]; queue<int>q; inline void spfa() { q.push(1),vis[1]=1; while(!q.empty()) { x=q.front(),q.pop(),vis[x]=0; for(int i=head[x];i;i=edge[i].next) if(f[y=edge[i].to]>f[x]+(w=edge[i].w)) { f[y]=f[x]+w; if(!vis[y]) q.push(y),vis[y]=1; } } } signed main() { read(n,m); for(int i=2;i<=n;++i) f[i]=INT_MAX; for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); spfa(); for(int i=1;i<=n;++i) put((f[i]==INT_MAX?-1:f[i]),0); return 0; }
【洛谷B3602 最短路问题_2】
本题卡 spfa。
-
核心代码「Dijkstra,\(O(m\log m)\)」
constexpr auto INF=LONG_MAX>>2; constexpr auto maxn=300010; constexpr auto maxm=300010; int n,m,x,y,w; ll f[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm]; auto add_edge=[](int x,int y,int w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn]; class node{public:int i;ll w;bool operator <(const node &a)const{return w>a.w;}}; priority_queue<node>q; inline void Dijkstra() { q.push({1,0}); while(!q.empty()) { x=q.top().i,q.pop(); if(vis[x]) continue; vis[x]=1; for(int i=head[x];i;i=edge[i].next) if(f[y=edge[i].to]>f[x]+(w=edge[i].w)) f[y]=f[x]+w,q.push({y,f[y]}); } } signed main() { read(n,m); for(int i=2;i<=n;++i) f[i]=INF; for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); Dijkstra(); for(int i=1;i<=n;++i) put(f[i]==INF?-1:f[i],0); return 0; }
【洛谷P5905「模板」Johnson 全源最短路】
-
核心代码
constexpr auto INF=1e9; constexpr auto maxn=3010; constexpr auto maxm=6010; int n,m,x,y,w; ll ans; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxn+maxm]; inline void add_edge(int x,int y,int w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn],h[maxn],cnt[maxn]; queue<int>q; inline bool spfa() { for(int i=1;i<=n;++i) h[i]=INF; q.push(0),vis[0]=1; while(!q.empty()) { x=q.front(),q.pop(),vis[x]=0; for(int i=head[x];i;i=edge[i].next) if(h[y=edge[i].to]>h[x]+(w=edge[i].w)) { h[y]=h[x]+w,cnt[y]=cnt[x]+1; if(cnt[y]==n+1) return false; if(!vis[y]) q.push(y),vis[y]=1; } } return true; } int f[maxn][maxn]; class node{public:int i,w;bool operator <(const node &a)const{return w>a.w;}}; priority_queue<node>pq; inline void Dijkstra(int s) { for(int i=0;i<=n;++i) vis[i]=0,f[s][i]=INF; pq.push({s,0}),f[s][s]=0; while(!pq.empty()) { x=pq.top().i,pq.pop(); if(vis[x]) continue; vis[x]=1; for(int i=head[x];i;i=edge[i].next) if(f[s][y=edge[i].to]>f[s][x]+(w=edge[i].w)) { f[s][y]=f[s][x]+w; if(!vis[y]) pq.push({y,f[s][y]}); } } } signed main() { read(n,m); for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w); for(int i=1;i<=n;++i) add_edge(0,i,0); if(!spfa()) return put(-1),0; for(int i=1;i<=n;++i) for(int j=head[i];j;j=edge[j].next) edge[j].w+=h[i]-h[edge[j].to]; for(int i=1;i<=n;++i) Dijkstra(i); for(int i=1;i<=n;++i) { ans=0; for(int j=1;j<=n;++j) ans+=f[i][j]==INF?j*INF:1ll*j*(f[i][j]+h[j]-h[i]); put(ans); } return 0; }- 开
long long。 - \(cnt[i]\) 表示 \(0,i\) 两个节点之间最短路的长度。
- 正常情况下,一个有 \(n\) 个节点的图中两点之间最短路长度不超过 \(n-1\),否则说明存在负环。
- 因此一般用 spfa 判负环时,直接判断 \(cnt[i]\) 是否大于等于 \(n\) 即可。
- 但 Johnson 算法中新加入一个虚拟节点 \(0\),总节点数为 \(n+1\),因此判负环时要判断
if(cnt[y]==n+1)。
- 由于虚拟节点向其他所有节点连一条边,因此
edge数组要开到maxn+maxm。
- 开
其他例题
【洛谷P3905 道路重建】
-
题意简述
- 给定一张 \(n\) 个点、\(m\) 条边的简单带权无向连通图。
- 图中一些边被破坏。对于一条被破坏的边,可以花费与其边权相同的代价使其恢复。
- 给定节点 \(A,B\),求打通一条从 \(A\) 到 \(B\) 的路径至少需要花费多少代价。
- 数据范围:\(2<n\le100,n-1\le m\le\frac12n(n-1)\)。
-
分析
- 容易发现只有在走被破坏的边时才需要付出代价。
- 因此直接将所有未被破坏的边的边权设为 \(0\),被破坏的边的边权不变,跑一遍最短路即可。
- 注意到 \(2<n\le100\),直接写 Floyd \(O(n^3)\) 就能过。当然也可以求出以 \(A\) 或 \(B\) 为起点的单源最短路,但不如直接 Floyd 方便。
-
核心代码「Floyd,\(O(n^3)\)」
constexpr auto INF=0x3f3f3f3f; constexpr auto maxn=110; int n,m,d,A,B,x,y,w,a[maxn][maxn],b[maxn][maxn]; signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) a[i][j]=INF; for(int i=1;i<=m;++i) read(x,y,w),a[x][y]=a[y][x]=ly::min(a[x][y],w); read(d); for(int i=1;i<=d;++i) read(x,y),b[x][y]=b[y][x]=1; for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(!b[i][j]&&a[i][j]^INF) a[i][j]=a[j][i]=0; for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) a[i][j]=ly::min(a[i][j],a[i][k]+a[k][j]); read(A,B),put(a[A][B]); return 0; }
【洛谷P6175 无向图的最小环问题】
-
分析
-
有一篇题解【Histone的题解】说得很好:
考虑图中的一个最小环 \(i\ldots j\rightarrow k\rightarrow i\),如果我们随意去掉一条路径 \(i\ldots j\),那么剩下的 \(j\rightarrow k\rightarrow i\) 一定是图中 \((i,j)\) 间的最短路径。
-
因此,可以利用 Floyd 算法的一个性质:
当外层循环 \(k\) 刚开始时,\(f[i,j]\) 保存着「经过编号不超过 \(k-1\) 的节点」从 \(i\) 到 \(j\) 的最短路长度。
-
对应在 \(i\ldots j\rightarrow k\rightarrow i\) 中,\(f[i,j]\) 就是第一段 \(i\ldots j\) 的长度。而对于 \(j\rightarrow k\) 和 \(k\rightarrow i\),其长度显然就是边权 \(w(j,k)\) 和 \(w(k,i)\)。
-
这样,枚举 \(i,j<k(i\ne j)\) 就能求出「由编号不超过 \(k\) 的节点构成且经过节点 \(k\)」的最小环长度。
-
该最小环长度即为 \(\min_{1\le i,j<k(i\ne j)}\set{f[i,j]+w(j,k)+w(k,i)}\)。
-
-
核心代码「Floyd,\(O(n^3)\)」
constexpr auto INF=0x3f3f3f3f; constexpr auto maxn=110; int n,m,x,y,w,a[maxn][maxn],f[maxn][maxn]; ll ans=INF; signed main() { read(n,m); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j) a[i][j]=INF; for(int i=1;i<=m;++i) read(x,y,w),a[x][y]=a[y][x]=ly::min(a[x][y],w); for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) f[i][j]=a[i][j]; for(int k=1;k<=n;++k) for(int i=1;i<=n;++i) for(int j=1;j<=n;++j) if(i^j&&i^k&&j^k) { ans=ly::min(ans,1ll*f[i][j]+a[j][k]+a[k][i]); f[i][j]=ly::min(f[i][j],f[i][k]+f[k][j]); } if(ans==INF) put("No solution."); else put(ans); return 0; }- 注意可能有重边,输入时取 \(\min\) 即可。
【洛谷P5837「USACO19DEC」Milk Pumping G】
-
题意简述
- 给定一张 \(n\) 个点 \(m\) 条边的无向图,每条边都有流量和花费两个属性「均为 \(1\)~\(1000\) 的正整数」。
- 定义一条路径的流量为该路径上所有边流量的最小值,一条路径的花费为该路径上所有边的花费之和。
- 找出 \(\frac{\text{流量}}{\text{花费}}\) 最大的从 \(1\) 到 \(n\) 的一条路径,输出该最大值 \(\times1000000\) 后向下取整的结果。
- 数据范围:\(2\le n\le 1000,1\le m\le1000\)。
-
分析
- 因为有流量最小值的限制,似乎不好直接跑最短路。
- 不妨换个思路:枚举流量最小值,求出在该流量最小值限制下的最小花费,更新答案。
- 因此可以直接枚举 \(1\)~\(1000\) 作为流量最小值限制,每次用 Dijkstra 求出最小花费并更新答案。注意小于该限制的边要忽略不计。
- 这样,很容易想到一个更优的解法:将所有边按流量从大到小排序,每加一条边跑一遍 Dijkstra 求最小花费并更新答案。这样就避免了对流量限制的判断。
-
核心代码「Dijkstra,\(O(m^2\log m)\)」
constexpr auto INF=0x3f3f3f3f; constexpr auto maxn=1010; constexpr auto maxm=1010; int n,m,ans,f[maxn]; int cnt_edge,head[maxn]; class Verge{public:int x,y,c,f;}a[maxm<<1]; class Edge{public:int to,next,cost,flow;}edge[maxm<<1]; auto add_edge=[](int x,int y,int c,int f){edge[++cnt_edge]={y,head[x],c,f},head[x]=cnt_edge;}; auto Add=[](int i){add_edge(a[i].x,a[i].y,a[i].c,a[i].f),add_edge(a[i].y,a[i].x,a[i].c,a[i].f);}; int vis[maxn]; class node{public:int i,w;bool operator <(const node &x)const{return w>x.w;}}; priority_queue<node>q; inline void Dijkstra() { for(int i=1;i<=n;++i) f[i]=INF,vis[i]=0; int x,y; q.push({1,f[1]=0}); while(!q.empty()) { x=q.top().i,q.pop(); if(vis[x]) continue; vis[x]=1; for(int i=head[x];i;i=edge[i].next) { Edge& e=edge[i];y=e.to; if(f[y]>f[x]+e.cost) f[y]=f[x]+e.cost,q.push({y,f[y]}); } } } signed main() { read(n,m); for(int i=1;i<=m;++i) read(a[i].x,a[i].y,a[i].c,a[i].f); sort(a+1,a+m+1,[](auto &x,auto &y){return x.f>y.f;}); for(int i=1;i<=m;++i) Add(i),Dijkstra(),ans=ly::max(ans,int(1e6*a[i].f/f[n])); put(int(ans)); return 0; }- 这里用到一个常用技巧:
Edge& e=edge[i]。这样几乎可以用e完全替代edge[i],包括赋值操作,可以简化代码、提高可读性。
- 这里用到一个常用技巧:
并查集
说明
最基础的部分并不难,网上也有不少详细的讲解,此处不再赘述。下面仅说明两点比较重要的问题。
-
并查集要用到的 \(get\) 函数与头文件
<utility>中pair和tuple的 \(get\) 函数命名冲突。-
为啥没用头文件
<utility>也会冲突?因为
<iostream>、<algorithm>、<map>、<vector>……这些头文件都包含了<utility>。 -
解决方案
- 命名空间
- 宏定义
- 类的成员函数
具体见后面例题的代码。
-
-
\(get\) 函数一般有两种实现方法:递归实现、迭代实现。
-
递归实现
int get(int x){return x==fa[x]?x:get(fa[x]);}显然十分简洁,你大可以采用这种写法,本人也推荐这种写法,因为实现简单、不易出错。
-
迭代实现
auto get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;};看起来长了一些,但也比较好理解。
首先从 \(x\) 出发找到其所在集合根节点,然后再次沿该路线更新所有 \(fa\) 的值,最后返回 \(x\)。
本人比较习惯此种写法,因为没有递归开销、常数较小「其实应该也差不多」,思路也比较简单。
除特殊说明,下文统一用第二种实现方法。但如果不习惯,还是推荐用第一种写法,避免写错。
-
-
扩展
- 种类并查集
- 带扩展域的并查集
- 带权并查集
- 可持久化并查集
- 可撤销并查集
- ……
-
推荐参考资料
- 《算法竞赛进阶指南》P195
- 【「算法学习」并查集以及它的一些扩展】
- 【「喵的算法课」并查集/带权并查集「8期」】
例题
【洛谷P3367「模板」并查集】
-
核心代码
constexpr auto maxn=10010; namespace solve { int n,m,op,x,y; int fa[maxn],size[maxn]; //function<int(int)>get=[](int x){return x==fa[x]?x:(fa[x]=get(fa[x]));}; const auto& get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;}; const auto& merge=[](int x,int y){((x=get(x))==(y=get(y)))?0:((size[x]>size[y]?(ly::swap(x,y),0):0),fa[x]=y,size[y]+=size[x]);}; signed main() { read(n,m); for(int i=1;i<=n;++i) fa[i]=i,size[i]=1; for(int i=1;i<=m;++i) { read(op,x,y); if(op&1) merge(x,y); else put(get(x)==get(y)?'Y':'N'); } return 0; } } signed main() { solve::main(); return 0; }- 小技巧:用命名空间解决命名冲突问题。
【洛谷P1111 修复公路】
-
题意简述
- \(A\) 地区有 \(n\) 个村庄。
- 现打算修 \(m\) 条公路连接 \(n\) 个村庄,第 \(i\) 条公路 \((x_i,y_i)\) 将在第 \(t_i\) 天修成。
- 求最早第几天所有村庄间可以通车。若所有公路修复完毕后仍存在两个村庄无法通车,输出
-1。 - 数据范围:\(n\le 1000,m\le 100000\)。
-
分析
- 按照时间顺序从小到大加入每一条边,直到所有点属于同一连通块,答案即为最后一次加入边的时间。
-
核心代码「并查集」
#define get _get #define merge _merge constexpr auto maxn=1010; constexpr auto maxm=100010; int n,m,cnt,ans; class node{public:int x,y,t;}a[maxm]; int fa[maxn],size[maxn]; auto get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;}; auto merge=[](int x,int y){(x=get(x))==(y=get(y))?0:(size[x]>size[y]?ly::swap(x,y),0:0),fa[x]=y,size[y]+=size[x];}; signed main() { read(n,m); for(int i=1;i<=n;++i) fa[i]=i,size[i]=1; for(int i=1;i<=m;++i) read(a[i].x,a[i].y,a[i].t); sort(a+1,a+m+1,[](auto &x,auto &y){return x.t<y.t;}); for(int i=2;i<=n;++i) { if(get(i)==get(1)) continue; if(cnt==m) return put(-1),0; while(cnt<m&&get(i)^get(1)) cnt++,merge(a[cnt].x,a[cnt].y),ans=a[cnt].t; } put(ans); return 0; }- 小技巧:用宏定义解决命名冲突问题。
【洛谷P1892「BOI2003」团伙】
-
分析
- 简单的种类并查集。
- 若只有朋友关系,容易想到可以直接将 \(n\) 个人看作独立的集合,用并查集求出连通块数。
- 如何处理敌对关系?假设 \(x\) 与 \(a,b,c,d\) 这四个人都是敌人,那么显然 \(a,b,c,d\) 互为朋友。
- 我们要做的是让 \(x\) 单独在一个连通块内,让 \(a,b,c,d\) 在一个连通块内。
- 那么可以新建一个点 \(x+n\),让 \(a,b,c,d\) 分别与 \(x+n\) 合并,这样就能使 \(a,b,c,d\) 在一个连通块内。
- 具体来说:将并查集大小开到 \(2n\),若 \(a,b\) 敌对,则合并 \((a,b+n)\)、合并 \((a+n,b)\)。
- 这样就能保证同一个人的所有敌人在同一个连通块里。
-
核心代码
constexpr auto maxn=1010; int n,m,x,y,ans,vis[maxn<<1]; char op; class UFS { public: int fa[maxn<<1],size[maxn<<1]; void init(){for(int i=1,j=n<<1;i<=j;++i)fa[i]=i,size[i]=1;} int get(int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;} void merge(int x,int y){((x=get(x))==(y=get(y)))?0:((size[x]>size[y]?(ly::swap(x,y),0):0),fa[x]=y,size[y]+=size[x]);} }s; signed main() { read(n,m); s.init(); for(int i=1;i<=m;++i) { read(op,x,y); if(op=='F') s.merge(x,y); else s.merge(x,y+n),s.merge(x+n,y); } for(int i=1,t;i<=n;++i) if(!vis[t=s.get(i)]) vis[t]=1,ans++; put(ans); return 0; }- 小技巧:用类封装解决命名冲突问题。
【洛谷P1196「NOI2002」银河英雄传说】
-
分析
-
看到合并、查询两个操作很容易想到并查集。
-
唯一不同的是,此题要维护两个节点之间的节点个数。
-
我们可以稍作转化:设 \(pre[x]\) 表示节点 \(x\) 前面的节点个数「在树上就是祖先个数」,那么节点 \(x,y\) 之间的节点个数显然就是 \(\abs{pre[x]-pre[y]}+1\)。
-
关键是如何维护 \(pre\) 数组?我们可以对 \(merge\) 和 \(get\) 两个操作分别讨论。
-
我们知道 \(size\) 数组是 \(x\) 所在集合的大小。当把 \(x\) 所在集合移到 \(y\) 所在集合的后面时,显然有 \(pre[get(x)]=size[y]\),即 \(x\) 所在集合的根节点前面有 \(size[y]\) 个元素。
-
现在考虑如何在路径压缩的 \(get\) 函数中维护 \(pre\) 数组。
-
直接看图:「
图有点简陋,可能不是很准确,凑合着看吧……」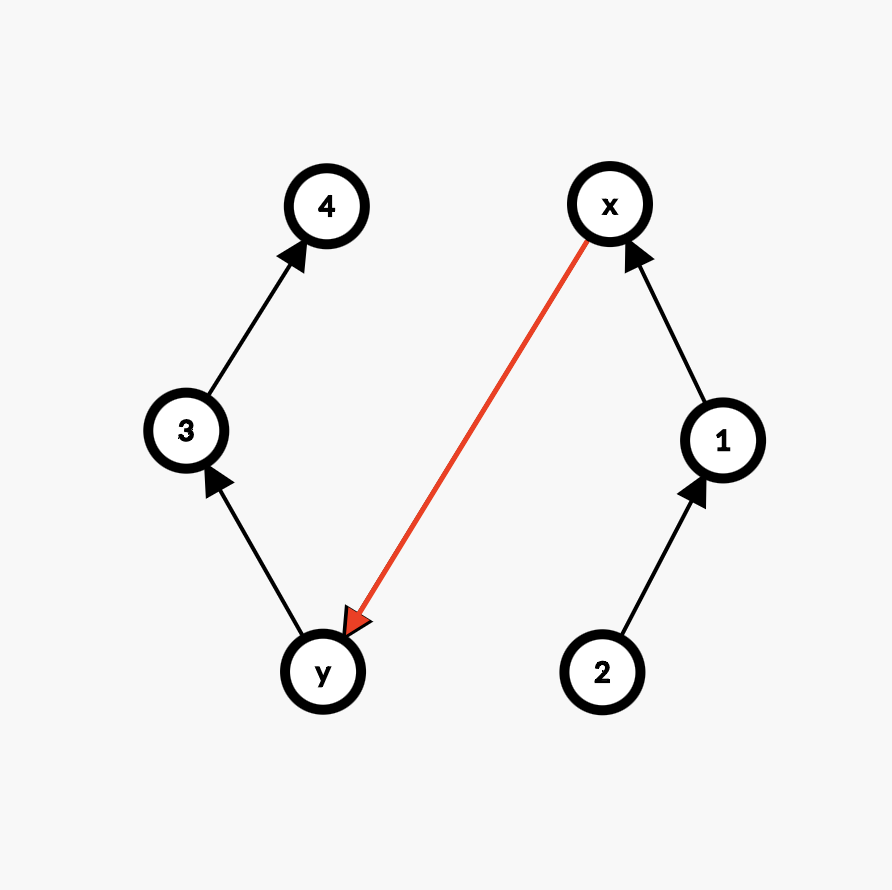
「注意实际上合并时是 \(x\) 向 \(4\) 连边,但为了方便理解,这里图中向左边集合的末尾 \(y\) 连边,不影响结果。」
开始时 \(\set{x,1,2}\) 与 \(\set{y,3,4}\) 是两个独立的集合,显然有:
\[\begin{aligned} size[x]&=3 \\size[y]&=3 \\pre[x]&=0 \\pre[1]&=1 \\pre[2]&=2 \end{aligned} \]现在将 \(x\) 所在集合合并到 \(y\) 的后面,根据我们前面所说,更新:「为避免歧义,这里 \(:\) 表示赋值。」
\[\begin{aligned} pre[x]&:size[y]=3 \\size[y]&:size[y]+size[x]=6 \end{aligned} \]但此时 \(pre[1],pre[2]\) 没有更新,于是我们要试图在 \(get\) 函数中更新它们。
根据观察,显然有:
\[\begin{aligned} pre[1]&:pre[1]+pre[x]=1+3=4 \\pre[2]&:pre[2]+pre[x]=2+3=5 \end{aligned} \]于是,我们便有了思路:先找到 \(1,2\) 所在集合的根节点「\(x\)」,然后将 \(pre[1],pre[2]\) 分别加上 \(pre[x]\),即可完成集合 \(\set{x,1,2}\) 的更新。
概括来说:我们要压缩 \((x,fa[x])\) 之间的路径时,\(fa[x]\) 前面的元素个数 \(pre[fa[x]]\) 还没有算在 \(pre[x]\) 中,因此要让 \(pre[x]+=pre[fa[x]]\)。
但要注意更新顺序:从 \(fa[x]\) 向 \(x\) 更新。也就是说,需要先找到整个集合的根节点,然后从根节点开始沿着来时的路走回 \(x\),过程中更新每一个节点的 \(pre\) 值。
-
\(get\) 函数的实现
-
递归实现
上述过程用递归很好实现:直接在回溯时更新 \(pre\)。
int get(int x) { if(x==fa[x]) return x; int t=get(fa[x]); pre[x]+=pre[fa[x]]; return fa[x]=t; } -
迭代实现
迭代实现也很容易理解。
开一个栈 \(s\),存下从 \(x\) 到根节点路径上的所有节点「不包括根节点」,然后用相反的顺序更新 \(pre\) 即可。
int top,s[maxn]; inline int get(int x) { int tx=x,t; while(x^fa[x]) s[++top]=x,x=fa[x]; while(top) t=s[top],pre[t]+=pre[fa[t]],top--; while(tx^fa[tx]) t=fa[tx],fa[tx]=x,tx=t; return x; }
-
-
-
核心代码
#define get _get constexpr auto maxn=30010; int T,x,y; char op; int fa[maxn],size[maxn],pre[maxn],top,s[maxn]; auto get=[](int x) { int tx=x,t; while(x^fa[x]) s[++top]=x,x=fa[x]; while(top) t=s[top],pre[t]+=pre[fa[t]],top--; while(tx^fa[tx]) t=fa[tx],fa[tx]=x,tx=t; return x; }; signed main() { for(int i=1;i<maxn;++i) fa[i]=i,size[i]=1; read(T); while(T--) { read(op,x,y); if(op=='M') x=get(x),y=get(y),fa[x]=y,pre[x]=size[y],size[y]+=size[x]; else put(get(x)==get(y)?ly::abs(pre[x]-pre[y])-1:-1); } return 0; }- 这里就不再加按秩合并了,因为要按照题目给定的顺序合并,不是很好维护。
其实是懒……
- 这里就不再加按秩合并了,因为要按照题目给定的顺序合并,不是很好维护。
【洛谷P2024「NOI2001」食物链】
-
做法一:带扩展域的并查集「最简单易懂的做法,但是有点取巧」
作用:同时维护多组关系。
思想:将一个点拆成多个点,在不同关系中使用。
实现:开一个大小为 \(k\times n\) 的并查集「每个节点拆为 \(k\) 个节点」,第 \(i\) 个节点拆成的第 \(j\) 个节点编号为 \(i+(j-1)n\)。推荐用宏定义增加代码可读性,见下。
分析:
-
不妨先找一些简单的性质。
-
容易发现,这个食物链中的每个动物与其他动物之间可能有三种关系:同类、猎物、天敌。
-
而且由已知的关系可以推出一些未知关系。例如:
- \(x,y\) 是同类,则 \(x\) 的猎物也是 \(y\) 的猎物,\(x\) 的天敌也是 \(y\) 的天敌。
- \(x,y\) 都吃 \(z\),则 \(x,y\) 是同类。
- \(x\) 吃 \(y\),\(y\) 吃 \(z\),则 \(z\) 吃 \(x\)。
后两句不理解?注意题目的第一句话:
动物王国中有三类动物 \(A,B,C\),这三类动物的食物链构成了有趣的环形。\(A\) 吃 \(B\),\(B\) 吃 \(C\),\(C\) 吃 \(A\)。
「以下内容参考《算法竞赛进阶指南》P202。」
-
我们可以将每个动物 \(x\) 拆成三个节点:同类域 \(x_{self}\)、猎物域 \(x_{eat}\)、天敌域 \(x_{enemy}\)。
-
然后对每句话进行分类讨论。我们先要判断这句话的真假,再对真话进行处理。为方便理解,这里先分析真话。
-
1 x y即 \(x,y\) 是同类,因此 \(x\) 的同类也是 \(y\) 的同类,\(x\) 的猎物也是 \(y\) 的猎物,\(x\) 的天敌也是 \(y\) 的天敌。
此时,我们合并 \(x_{self}\) 与 \(y_{self}\)、\(x_{eat}\) 与 \(y_{eat}\)、\(x_{enemy}\) 与 \(y_{enemy}\)。
-
2 x y即 \(x\) 吃 \(y\),因此 \(x\) 的猎物是 \(y\) 的同类,\(x\) 的同类是 \(y\) 的天敌。
注意题目告诉我们食物链是一个长度为 \(3\) 的环「\(x\) 吃 \(y\),\(y\) 吃 \(z\),\(z\) 就吃 \(x\)」,所以 \(y\) 的猎物是 \(x\) 的天敌。
此时,我们合并 \(x_{eat}\) 与 \(y_{self}\)、\(x_{self}\) 与 \(y_{enemy}\)、\(x_{enemy}\) 与 \(y_{eat}\)。
-
-
-
然后分析每句话的真假。
有两种信息与
1 x y「\(x,y\) 是同类」矛盾:- \(x\) 吃 \(y\)。「\(x_{eat}\) 与 \(y_{self}\) 在同一集合里。」
- \(y\) 吃 \(x\)。「\(y_{eat}\) 与 \(x_{self}\) 在同一集合里。」
也有两种信息与
2 x y「\(x\) 吃 \(y\)」矛盾:- \(x\) 与 \(y\) 是同类。「\(x_{self}\) 与 \(y_{self}\) 在同一集合里。」
- \(y\) 吃 \(x\)。「\(y_{eat}\) 与 \(x_{self}\) 在同一集合里。」
-
实现
可以开一个大小为 \(3n\) 的并查集,第 \(i\) 个动物所对应的同类域、猎物域、天敌域分别对应 \(i,i+n,i+2n\)「可以用宏定义让代码思路更清晰,见下」,直接按照上面的思路模拟即可。
-
核心代码
#define get _get #define merge _merge #define self(x) (x) #define eat(x) (x+n) #define enemy(x) (x+n+n) constexpr auto maxn=50010; int n,k,op,x,y,ans; int fa[maxn<<2],size[maxn<<2]; auto get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;}; auto merge=[](int x,int y){(x=get(x))==(y=get(y))?0:(size[x]>size[y]?ly::swap(x,y),0:0),fa[x]=y,size[y]+=size[x];}; auto eq=[](int x,int y){return get(x)==get(y);}; signed main() { read(n,k); for(int i=1,j=n*3;i<=j;++i)fa[i]=i,size[i]=1; while(k--) { read(op,x,y); if(x>n||y>n){ans++;continue;} if(op&1) { if(eq(self(x),eat(y))||eq(self(y),eat(x))) ans++; else merge(self(x),self(y)),merge(eat(x),eat(y)),merge(enemy(x),enemy(y)); } else { if(eq(eat(y),self(x))||eq(self(x),self(y))) ans++; else merge(eat(x),self(y)),merge(self(x),enemy(y)),merge(enemy(x),eat(y)); } } put(ans); return 0; }-
记得特判 \(x,y>n\) 的情况!否则只有 \(60pts\)。
-
数组要开到 \(3n\),否则会 RE。
-
使用宏定义:
#define self(x) (x) #define eat(x) (x+n) #define enemy(x) (x+n+n)这样或许会使代码变长,但可读性明显提高,思路更加清晰。
-
-
-
做法二:带权并查集「稍微难理解一些,但是适用范围更广」
思想:简单来说,“带权”就是在两个元素建立联系时,不只将它们所在的两个集合合并,还要给它们之间赋一个权值来表示它们之前的关系。
想到这些并不难,带权并查集真正难就难在路径压缩或集合合并时,如何维护权值的变化。
可能你已经发现,上一题【洛谷P1196「NOI2002」银河英雄传说】其实就是一个简单的带权并查集,路径压缩前每个节点与其父节点之间的边的权值为 \(1\),而 \(pre\) 则是维护每个节点到根节点的路径上的权值之和。
现在分析一下本题:
-
每个节点与其父节点之间的关系好像无法简单地只用权值 \(1\) 来表示。
-
因此我们仍然用做法一发现的三种关系:同类关系、捕食关系、天敌关系。
「注意这是父节点对当前节点的关系,如捕食关系即当前节点吃父节点、天敌关系即父节点吃当前节点。」
-
然后分别给这三种关系赋值为 \(0,1,2\)。这样我们就表示出了路径压缩前,每个节点与其父节点之间的关系。
-
【难点一】问题来了,路径压缩后,每个节点「根节点除外」的父亲变为根节点,如何更新权值的变化呢?也就是说,每个节点与根节点之间的关系,如何通过路径上的权值表示出来?
-
不妨从最简单的情况入手。
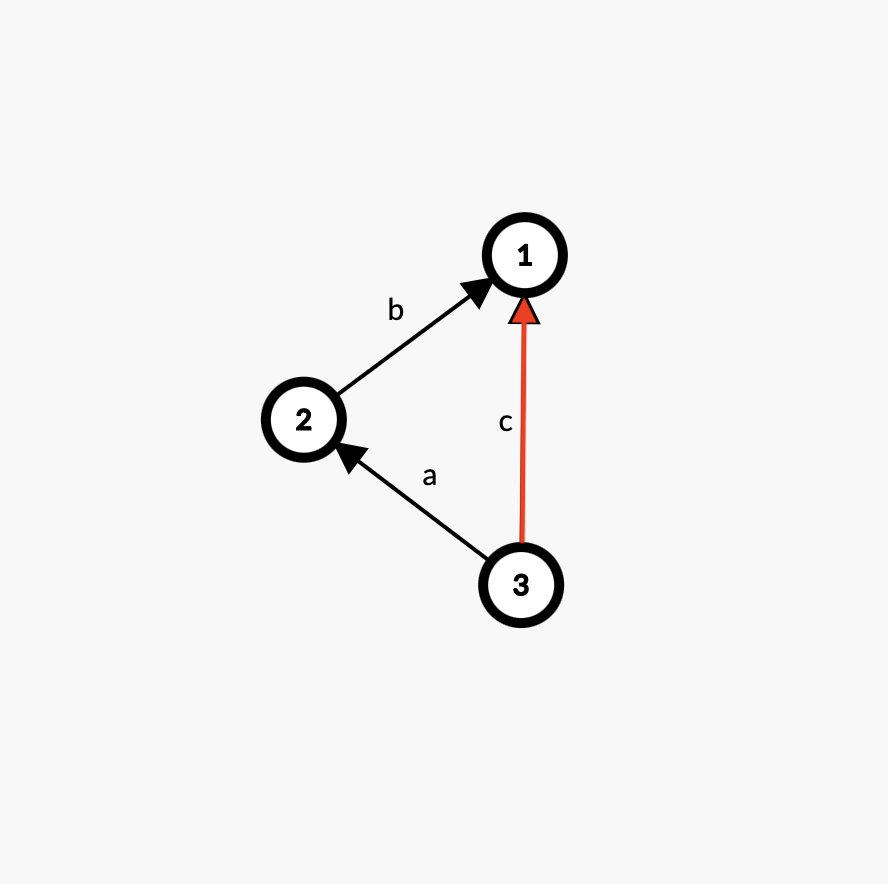
如图,开始时 \(3\) 到 \(1\) 的路径为 \((3,2,a),(2,1,b)\) 两条边,路径压缩后变为 \((3,1,c)\) 这一条边,现在我们要做的就是用 \(a,b\) 表示 \(c\)。
考虑几种比较简单的情况:
-
\(a=b=0\):\(3,2\)、\(2,1\) 为同类关系,故 \(3,1\) 也为同类关系,\(c=0\)。
容易发现,如果 \(a=0\),则 \(3,2\) 为同类关系,\(c=b\)。同理,\(b=0\) 则 \(c=a\)。
-
\(a=b=1\):\(3\) 吃 \(2\),\(2\) 吃 \(1\),根据题意,有 \(1\) 吃 \(3\),即 \(1\) 对于 \(3\) 是天敌关系,故 \(c=2\)。
-
\(a=b=2\):\(2\) 吃 \(3\),\(1\) 吃 \(2\),根据题意,有 \(3\) 吃 \(1\),即 \(1\) 对于 \(3\) 是猎物关系,故 \(c=1\)。
-
\(a=1,b=2\):\(3\) 吃 \(2\),\(1\) 吃 \(2\),根据题意,\(1,3\) 是同类,故 \(c=0\)。同理 \(a=2,b=1\) 时也有 \(c=0\)。
额,好像稍微讨论了一下就把所有情况都讨论完了?不过我们终于发现了一条规律:\(c=(a+b)\bmod 3\)!!!
而且,既然两条边压缩为一条边的情况可以成立,则对于任意一条边数 \(\ge2\) 的路径,这条规律都成立!「数学归纳法。」可以类比数学中的向量加法感性理解一下。
实现的方法与【洛谷P1196「NOI2002」银河英雄传说】完全相同,因为同样是加法。这里不再赘述。
-
-
【难点二】我们已经解决了路径压缩的问题,现在来考虑在合并两个集合时,如何给两个根节点的连边赋值?
直接看图。
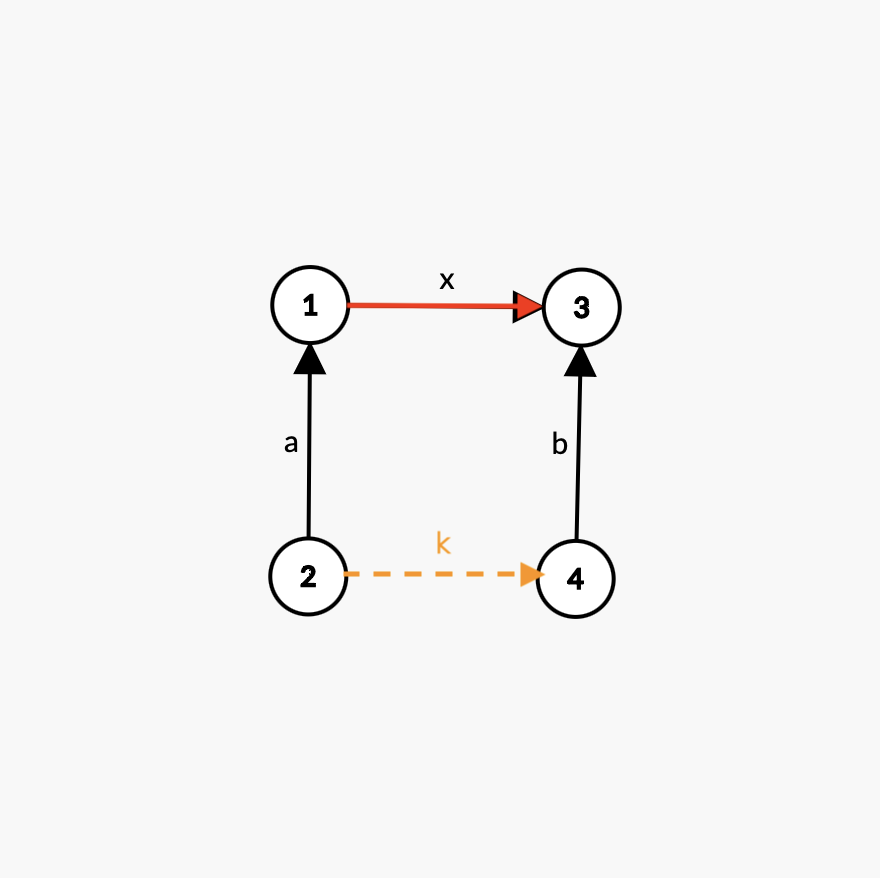
开始时 \(\set{1,2}\)、\(\set{3,4}\) 是两个互不相交的集合。
现考虑将两个元素 \(2,4\) 合并到一个集合,显然只需要将其所在两个集合的根节点 \(1,3\) 合并即可。
具体的,可以令 \(1\) 的父节点为 \(3\),并将 \((1,3)\) 的权值设为 \(x\),我们的目的就是求出 \(x\)。
别忘了,\(2,4\) 既然可以合并,说明它们之间的关系已经确定,即设 \((2,4)\) 的权值为 \(k\),则 \(k\) 是已知的。
因此,根据前面的结论,我们有:
\[(x+a)\bmod 3=(b+k)\bmod 3 \]移项,得:
\[x=(b-a+k)\bmod 3 \]同时,如果合并后已知 \(x\)、未知 \(k\),也能得到合并后 \(2,4\) 的关系权值 \(k=a+x-b\)。
现在我们将上面的结论稍作整理。
用 \(f[x]\) 表示 \(x\) 到其父节点「路径压缩后是根节点」之间的边权,如上图的 \(a\) 对应 \(f[2]\)、\(b\) 对应 \(f[4]\)、\(x\) 对应 \(f[1]\)。
-
不同集合合并时的关系
设 \(x,y\) 所在的两个不同集合的根节点分别为 \(a,b\) 且 \(x,y\) 关系的权值为 \(k\)。如果要合并两个集合「令 \(fa[a]=b\)」,则有:
\[f[a]=(f[y]-f[x]+k)\bmod 3 \] -
同一集合两个不同元素的关系
设 \(x,y\) 在同一集合中,\(x,y\) 关系的权值为 \(k\),则有:
\[k=(f[x]-f[y])\bmod 3 \]
注意实际计算时要先加 \(3\) 再取模,因为可能出现负数。
-
-
至此,我们已经正确维护了 \(get\) 和 \(merge\) 操作对边权的影响,可以轻松得到每个动物与其所在集合根节点之间的关系以及同一集合中两个动物之间的关系。
-
判断真假比上一种做法简单了一些。
1 x y:若 \(x,y\) 在同一集合,且与根节点关系不同,则为假。否则为真。2 x y:若在同一集合,且 \(y\) 对于 \(x\) 不是猎物关系,则为假。否则为真。
-
处理真话也很简单。直接将 \(x,y\) 合并,按照前面推的式子维护边权即可。
前面已提到过,注意先 \(+3\) 再取模,防止负数。
-
核心代码
#define get _get #define merge _merge constexpr auto maxn=50010; int n,k,op,x,y,a,b,ans; int fa[maxn],f[maxn]; auto get=[](int x) { int tx=x,t; static int s[maxn],top(0); while(x^fa[x]) s[++top]=x,x=fa[x]; while(top) t=s[top--],f[t]=(f[t]+f[fa[t]])%3; while(tx^fa[tx]) t=fa[tx],fa[tx]=x,tx=t; return x; }; auto merge=[](int x,int y,int k){int a=get(x),b=get(y);fa[a]=b,f[a]=(f[y]-f[x]+k+3)%3;}; signed main() { read(n,k); for(int i=1;i<=n;++i) fa[i]=i; while(k--) { read(op,x,y); a=get(x),b=get(y); if(x>n||y>n){ans++;continue;} if(op&1) { if(a==b&&f[x]^f[y]) ans++; else merge(x,y,0); } else { if(a==b&&(f[x]-f[y]+3)%3!=1) ans++; else merge(x,y,1); } } put(ans); return 0; }- 这里的 \(get\) 函数用栈更新 \(f\) 数组,可以类比上一题【洛谷P1196「NOI2002」银河英雄传说】。
-
扩展——路径压缩+按秩合并的带权并查集
只需把上面的代码略作修改即可。
和前面一样,用一个 \(size\) 数组表示每个节点所在集合的大小,里面的元素初始化为 \(1\)。
然后只需修改 \(merge\) 操作即可:
auto merge=[](int x,int y,int k) { int a=get(x),b=get(y); if(a==b) return; if(size[a]>size[b]) ly::swap(x,y),ly::swap(a,b),k=(k?(k&1?2:1):0); fa[a]=b,f[a]=(f[y]-f[x]+k+3)%3,size[b]+=size[a]; };注意在交换 \(x,y\) 时,二者的关系权值 \(k\) 也会发生改变。
不难发现,\(k=0\) 时,\(x,y\) 同类,交换后还是同类关系,故 \(k\) 仍为 \(0\)。
而 \(k=1,2\) 时,\(x,y\) 之间吃与被吃的关系颠倒过来,因此 \(k=1\) 时变为 \(2\),\(k=2\) 时变为 \(1\)。
-
最小生成树
概念
-
连通网
在连通图中,若图的每一条边都对应着一个数,则称这个数为权,权表示连接两个顶点的代价。带权连通图称为连通网。
-
生成树
一个连通图的生成树是指一个连通子图,它含有图中全部 \(n\) 个顶点,但只有足以构成一棵树的 \(n-1\) 条边。如果生成树中再添加一条边,则必定成环。
-
最小生成树
在连通网的所有生成树中,边权之和最小的生成树称为最小生成树。
《算法竞赛进阶指南》P363中对最小生成树的定义如下:
给定一张边带权的无向图 \(G=(V,E),n=|V|,m=|E|\)。由 \(V\) 中全部 \(n\) 个顶点和 \(E\) 中 \(n-1\) 条边构成的无向连通子图称为 \(G\) 的一棵生成树。边的权值之和最小的生成树被称为无向图 \(G\) 的最小生成树(Minimum Spanning Tree,MST)。
《算法导论》P363中「一定是巧合」给出了最小生成树算法的通用方法和伪代码,十分简洁易懂:「已将原文内容简化。」
在每个时刻生长最小生成树的一条边,维护一个边集合 \(A\),满足条件:「在每遍循环之前,\(A\) 是某棵最小生成树的一个子集。」
在每一步,我们要做的事情是选择一条边 \((u,v)\),将其加入到集合 \(A\) 中,使得 \(A\) 不违反上面的条件,即 \(A\cup\set{(u,v)}\) 也是某棵最小生成树的子集。我们称这样的边为集合 \(A\) 的安全边。「safe for \(A\)。」
\[\begin{array}{ll} 1 & A=\varnothing \\ 2 & \textbf{while } A\text{ does not form a spanning tree}\\ 3 & \qquad\text{find an edge }(u,v)\text{ that is safe for }A \\ 4 & A=A\cup\set{(u,v)} \\ 5 & \textbf{return } A \end{array} \]
最终返回的集合 \(A\) 就是一棵最小生成树。
Kruskal
-
定理「此部分引自《算法竞赛进阶指南》P363。」
任意一棵最小生成树一定包含无向图中权值最小的边。
-
证明
反证法。假设无向图 \(G=(V,E)\) 存在一棵最小生成树不包含权值最小的边 \(e=(x,y,w)\)。把 \(e\) 添加到树中,\(e\) 会和树上从 \(x\) 到 \(y\) 的路径一起构成一个环,并且环上其他边的权值都比 \(w\) 大。因此,用 \(e\) 代替环上的其他任意一条边,会形成一棵权值和更小的生成树,与假设矛盾。故假设不成立,原命题成立。
证毕。
-
推论
给定一张无向图 \(G=(V,E),n=|V|,m=|E|\)。从 \(E\) 中选出 \(k<n-1\) 条边构成 \(G\) 的一个生成森林。若再从剩余的 \(m-k\) 条边中选出 \(n-1-k\) 条添加到生成森林中,使其成为 \(G\) 的生成树,并且选出的边的权值之和最小,则该生成树一定包含这 \(m-k\) 条边中连接生成森林的两个不连通节点的权值最小的边。
-
-
思想
- Kruskal 算法就是基于该推论的,它总是维护无向图的最小生成森林。
- 初始时每个点各自单独构成一棵仅包含一个节点的树。
- 在剩余的边中选出一条权值最小的,并且这条边的两个顶点属于生成森林中两棵不同的树「不连通」,把该边加入生成森林。
图中节点的连通情况可以用并查集维护。
-
过程
-
建立一个并查集并初始化。
-
把所有边按边权从小到大排序。
-
从小到大依次扫描所有边 \((x,y,w)\)。
-
若 \(x,y\) 连通,则忽略该边,继续扫描下一条边。
-
否则合并 \(x,y\) 所在的集合,并将 \(w\) 累加到答案。
-
算法结束后,第 3 步中处理过的边就构成最小生成树。
-
-
时间复杂度:\(O(m\log m)\)。
-
实现:见后面例题。
Prim
-
思想
-
Prim 算法同样基于上面的推论,但它总是维护最小生成树的一部分。
具体来讲,Kruskal 算法直接选择权值最小的边,而 Prim 算法从顶点出发,间接选择与顶点相连、权值最小的边。
-
Prim 算法和 Dijkstra 算法十分类似,区别在于 Dijkstra 算法中的 \(f\) 数组存的是每个节点到起点的最短距离,而 Prim 中的 \(f\) 数组存的是每个节点到最小生成树中其父亲节点的距离。我们希望生成树的边权和最小,也就是父亲到儿子之间的边权最小,因此对于同一个父亲,选边权最小的儿子是最优的。
-
直观理解后,为保证严谨性,以下内容摘自《算法竞赛进阶指南》P365。
在任意时刻,设已经确定属于最小生成树的节点集合为 \(T\),剩余节点集合为 \(S\)。Prim 算法找到 \(\min_{x\in S,y\in T}\set{w}\),即两个端点分别属于集合 \(S,T\) 的权值最小的边,然后把点 \(x\) 从集合 \(S\) 中删除,加入到集合 \(T\),并把 \(w\) 累加到答案中。
具体来说,可以维护数组 \(d\):若 \(x\in S\),则 \(d[x]\) 表示节点 \(x\) 与集合 \(T\) 中的节点之间权值最小的边的权值。若 \(x\in T\),则 \(d[x]\) 就等于 \(x\) 被加入 \(T\) 时选出的最小边的权值。
可以类比 Dijkstra 算法,用一个数组标记节点是否属于 \(T\)。每次从未标记的节点中选出 \(d\) 值最小的,把它标记(新加入 \(T\)),同时扫描所有出边,更新另一个端点的 \(d\) 值。最后,最小生成树的权值总和就是 \(\sum_{x=2}^nd[x]\)。
-
-
过程
- 找到一个不属于最小生成树且到最小生成树中点的距离最小的节点 \(x\)。「即 \(x\in S\) 且 \(d[x]\) 最小。」
- 将 \(x\) 加入最小生成树。
- 扫描 \(x\) 的所有出边 \((x,y,w)\),若 \(y\) 不在最小生成树中,更新 \(d[y]\):\(d[y]=\min\set{d[y],w}\)。
- 所有节点都加入最小生成树后,算法结束,答案即为 \(\sum_{x=2}^nd[x]\)。
整个过程的时间复杂度为 \(O(n^2+m)\)。
其中,第 \(1\) 步寻找最小值的操作可以类似堆优化 Dijkstra,用一个小根堆维护:开始时将任意一个节点加入堆,每次操作时直接取出队顶元素,每次更新 \(y\) 后将 \(y\) 加入堆。这样可以进一步减少时间复杂度,且时间复杂度与堆的实现方式有关。
-
时间复杂度
- 暴力:\(O(n^2+m)\)。
- 二叉堆优化:\(O((n+m)\log n)\)。
- 斐波那契堆优化:\(O(n\log n+m)\)。
-
关于优化的不同说法
以下给出两个来源的参考。
《算法竞赛进阶指南》P365:
可以用二叉堆优化到 \(O(m\log n)\),但是这样就不如直接用 Kruskal 方便,且常数比 Kruskal 大。
因此,Prim 主要用于稠密图,尤其是完全图的最小生成树的求解。
堆优化的方式类似 Dijkstra 的堆优化,但如果使用二叉堆等不支持 \(O(1)\) decrease-key 的堆,复杂度就不优于 Kruskal,常数也比 Kruskal 大。所以,一般情况下都使用 Kruskal 算法,在稠密图尤其是完全图上,暴力 Prim 的复杂度比 Kruskal 优,但 不一定 实际跑得更快。
-
实现:见下面例题。
例题
【洛谷P3366「模板」最小生成树】
-
Kruskal「\(O(m\log m)\)」
核心代码:
constexpr auto maxn=5010; constexpr auto maxm=200010; namespace solve { int n,m,t,ans; class Edge{public:int x,y,w;}edge[maxm]; int fa[maxn],size[maxn]; auto clear=[](){for(int i=1;i<=n;++i)fa[i]=i,size[i]=1;}; auto get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[x])t=fa[x],fa[x]=x,tx=t;return x;}; auto merge=[](int x,int y){(x=get(x))==(y=get(y))?0:((size[x]>size[y]?(x^=y^=x^=y):0),fa[x]=y,size[y]+=size[x]);}; inline void Kruskal() { sort(edge+1,edge+m+1,[](const Edge &x,const Edge &y){return x.w<y.w;}); clear(); for(int i=1;i<=m;++i) if(get(edge[i].x)^get(edge[i].y)) merge(edge[i].x,edge[i].y),ans+=edge[i].w; } signed main() { read(n,m); clear(); for(int i=1;i<=m;++i) read(edge[i].x,edge[i].y,edge[i].w),merge(edge[i].x,edge[i].y); t=get(1); for(int i=2;i<=n;++i) if(get(i)^t) return put("orz"),0; Kruskal(); put(ans); return 0; } } signed main() { solve::main(); return 0; } -
Prim「\(O((n+m)\log n)\)」
核心代码:
constexpr auto maxn=5010; constexpr auto maxm=200010; int n,m,x,y,w,cnt,ans,d[maxn]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm<<1]; auto add_edge=[](int x,int y,int w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; int vis[maxn]; class node{public:int i,w;bool operator <(const node &a)const{return w>a.w;}}; priority_queue<node>q; inline void Prim() { q.push({1,0}),d[1]=0; while(!q.empty()) { x=q.top().i,q.pop(); if(vis[x]) continue; vis[x]=1,cnt++,ans+=d[x]; for(int i=head[x];i;i=edge[i].next) if(!vis[y=edge[i].to]&&(w=edge[i].w)<d[y]) d[y]=w,q.push({y,d[y]}); } } signed main() { read(n,m); for(int i=1;i<=n;++i) d[i]=INT_MAX; for(int i=1;i<=m;++i) read(x,y,w),add_edge(x,y,w),add_edge(y,x,w); Prim(); if(cnt==n) put(ans); else put("orz"); return 0; }
【洛谷P1967「NOIP2013 提高组」货车运输】
-
题意简述
- 给定一张 \(n\) 个点 \(m\) 条边的带权无向图。
- 有 \(q\) 次询问,每次询问两点间最小边权最大的路径上的最小边权。
- 若询问的两点不连通,输出 \(-1\)。
- 数据范围:\(1\le n<10^4,1\le m<5\times10^4,1\le q<3\times10^4\)。
-
分析
-
对初始的图求出最大生成树。
最大生成树和最小生成树的唯一区别是按照边权从大到小排序。
-
每个询问的答案即为最大生成树上两点之间的路径上的最小边权。
-
这里,找一棵树上两点之间的路径用到了最近公共祖先「LCA」的知识。
-
最近公共祖先
给定一棵有根树,若节点 \(z\) 既是节点 \(x\) 的祖先,也是节点 \(y\) 的祖先,则称 \(z\) 是 \(x,y\) 的公共祖先。在 \(x,y\) 的所有公共祖先中,深度最大的一个称为 \(x,y\) 的最近公共祖先,记为 \(\text{LCA}(x,y)\)。
\(\text{LCA}(x,y)\) 是 \(x\) 到根的路径与 \(y\) 到根的路径的交会点。它也是 \(x\) 与 \(y\) 之间的路径上深度最小的节点。
——李煜东《算法竞赛进阶指南》P375 -
如果我们求出 \(x,y\) 的最近公共祖先 \(lca\),那么 \(x,y\) 在树上的路径就可以分为 \(x\rightarrow lca\)、\(lca\rightarrow y\) 两部分,从而可以求出 \(x,y\) 路径上的最小边权。
-
求解最近公共祖先一般有三种算法:向上标记法、树上倍增法、Tarjan 算法。
-
篇幅有限,此处仅介绍最简单的向上标记法。
- 十分简单的过程
- 从 \(x\) 向上走到根节点,并标记所有经过的节点。
- 从 \(y\) 向上走,第一个遇到的已标记的节点即为 \(\text{LCA}(x,y)\)。
- 对于每个询问,向上标记法的时间复杂度最坏是 \(O(n)\)。
- 十分简单的过程
-
综上,用 Kruskal 求最大生成树、对每个询问用向上标记法求 LCA,整个过程可以在 \(O(nq)\) 的时间内实现。
-
按说只能得 \(60pts\),但本题数据比较水所以能过…… -
容易发现,本题的时间复杂度瓶颈在于求解最近公共祖先。
可以用树上倍增法或 Tarjan 算法进行优化。
对于 \(q\) 次询问,不同算法实现的时间复杂度如下:
算法 向上标记法 树上倍增法 Tarjan 算法 时间复杂度 \(O(nq)\) \(O((n+q)\log n)\) \(O(n+q)\)
-
-
-
-
核心代码「Kruskal+向上标记法,\(O(nq)\)」
constexpr auto maxn=10010; constexpr auto maxm=50010; int n,m,q; class Verge{public:int x,y,w;}a[maxm]; int cnt_edge,head[maxn]; class Edge{public:int to,next,w;}edge[maxm<<1]; auto add_edge=[](int x,int y,int w){edge[++cnt_edge]={y,head[x],w},head[x]=cnt_edge;}; auto Add=[](int x,int y,int w){add_edge(x,y,w),add_edge(y,x,w);}; namespace Kruskal//求解最大生成树 { int fa[maxn],size[maxn]; auto init=[]{for(int i=1;i<=n;++i) fa[i]=i,size[i]=1;}; auto get=[](int x){int tx=x,t;while(x^fa[x])x=fa[x];while(tx^fa[tx])t=fa[tx],fa[tx]=x,tx=t;return x;}; auto merge=[](int x,int y){(x=get(x))==(y=get(y))?0:(size[x]>size[y]?ly::swap(x,y),0:0),fa[x]=y,size[y]+=size[x];}; auto connected=[](int x,int y){return get(x)==get(y);};//判断两个节点是否连通 void main() { init(); sort(a+1,a+m+1,[](const auto &x,const auto &y){return x.w>y.w;}); for(int i=1;i<=m;++i) if(get(a[i].x)^get(a[i].y)) merge(a[i].x,a[i].y),Add(a[i].x,a[i].y,a[i].w); } } int fa[maxn],fw[maxn];//父节点,与父节点连边的边权 void dfs(int x)//预处理fa、fw数组 { for(int i=head[x],y;i;i=edge[i].next) if((y=edge[i].to)^fa[x]) fa[y]=x,fw[y]=edge[i].w,dfs(y); } int vis[maxn]; inline int calc(int x,int y)//向上标记法 { int tx=x,lca=y,res=INT_MAX; while(tx) vis[tx]=1,tx=fa[tx];//1:从x向上标记 while(!vis[lca]) lca=fa[lca];//2:从y向上寻找标记 while(x^lca) vis[x]=0,res=ly::min(res,fw[x]),x=fa[x];//取消标记并沿路径x->lca更新答案 while(y^lca) res=ly::min(res,fw[y]),y=fa[y];//沿路径y->lca更新答案 while(x) vis[x]=0,x=fa[x];//取消标记 return res; } signed main() { read(n,m); for(int i=1;i<=m;++i) read(a[i].x,a[i].y,a[i].w); Kruskal::main(); for(int i=1;i<=n;++i) if(!fa[i]) dfs(i); read(q); for(int x,y;q;q--) { read(x,y); if(Kruskal::connected(x,y)) put(calc(x,y)); else put(-1); } return 0; }- 由于用到两个 \(fa\) 数组,因此用命名空间区分开避免命名冲突。
namespace Kruskal里面的 \(fa\):求最大生成树用的并查集中的 \(fa\),维护两个节点是否有相同的祖先「在同一连通块内」。- 外面的 \(fa\):存储最大生成树中每个节点的父亲,\(fa[x]\) 即 \(x\) 的父亲。根节点的 \(fa\) 值为 \(0\)。
- 注意图不一定连通,因此要在每个连通块内跑一遍
dfs。 calc计算答案时,向上标记法第一步标记的vis[tx]=1在第二步结束后要改回 \(0\),避免影响后续答案。
- 由于用到两个 \(fa\) 数组,因此用命名空间区分开避免命名冲突。
参考资料
- 李煜东《算法竞赛进阶指南》
- 《算法导论》
- 【OI Wiki】
严格来说,时间复杂度为 \(O((m+n)\log n)\)。为方便起见,我们假设 \(m\) 的规模不小于 \(n\) 的规模,因此简写为 \(O(m\log n)\),下略。 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号