定时任务之elastic-job概述
定时任务有哪些?
- Timer定时器
- ScheduledExecutorService
- Spring自带的@Scheduled
- Quartz定时任务
- 当当elastic job定时任务
Quartz实现定时任务的步骤
下面这个例子很好的覆盖了Quartz最重要的3个基本要素:
- Scheduler:调度器。所有的调度都是由它控制。
- Trigger: 定义触发的条件。例子中,它的类型是SimpleTrigger,每隔1秒中执行一次。
- JobDetail & Job: JobDetail 定义的是任务数据,而真正的执行逻辑是在Job中。
例子中是HelloQuartz。 为什么设计成JobDetail + Job,不直接使用Job?这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
package com.test.quartz;
import static org.quartz.DateBuilder.newDate;
import static org.quartz.JobBuilder.newJob;
import static org.quartz.SimpleScheduleBuilder.simpleSchedule;
import static org.quartz.TriggerBuilder.newTrigger;
import java.util.GregorianCalendar;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.Trigger;
import org.quartz.impl.StdSchedulerFactory;
import org.quartz.impl.calendar.AnnualCalendar;
public class QuartzTest {
public static void main(String[] args) {
try {
//创建scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
//定义一个Trigger
Trigger trigger = newTrigger().withIdentity("trigger1", "group1") //定义name/group
.startNow()//一旦加入scheduler,立即生效
.withSchedule(simpleSchedule() //使用SimpleTrigger
.withIntervalInSeconds(1) //每隔一秒执行一次
.repeatForever()) //一直执行,奔腾到老不停歇
.build();
//定义一个JobDetail
JobDetail job = newJob(HelloQuartz.class) //定义Job类为HelloQuartz类,这是真正的执行逻辑所在
.withIdentity("job1", "group1") //定义name/group
.usingJobData("name", "quartz") //定义属性
.build();
//加入这个调度
scheduler.scheduleJob(job, trigger);
//启动之
scheduler.start();
//运行一段时间后关闭
Thread.sleep(10000);
scheduler.shutdown(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
定义Job类为HelloQuartz类,这是真正的执行逻辑所在
package com.test.quartz;
import java.util.Date;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.Job;
import org.quartz.JobDetail;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class HelloQuartz implements Job {
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDetail detail = context.getJobDetail();
String name = detail.getJobDataMap().getString("name");
System.out.println("say hello to " + name + " at " + new Date());
}
}
当当实现定时任务步骤
当当是在quartz的基础上封装了quartz,对应的有
1.创建一个org.quartz.Job的实现类,并实现实现自己的业务逻辑。
public final class LiteJob implements Job {}
2.定义一个JobDetail,引用这个实现类 。
JobScheduleController jobScheduleController = new JobScheduleController(this.createScheduler(),this.createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()), liteJobConfigFromRegCenter.getJobName());
3.Scheduler调度器。
this.scheduler.scheduleJob(this.jobDetail, this.createTrigger(cron));
以下举例说明如何使用当当:
设置分片参数,定义Job配置类,执行计划等配置
定义Job类
public class SpringSimpleJob implements SimpleJob
public class SpringDataflowJob implements DataflowJob<Foo>
1.引入maven依赖
<!-- 引入elastic-job-lite核心模块 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${latest.release.version}</version>
</dependency>
2.作业开发
2.1 Simple类型作业
意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
public class MyElasticJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
// do something by sharding item 0
break;
case 1:
// do something by sharding item 1
break;
case 2:
// do something by sharding item 2
break;
// case n: ...
}
}
}
2.2 Dataflow类型作业
Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
public class MyElasticJob implements DataflowJob<Foo> {
@Override
public List<Foo> fetchData(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
List<Foo> data = // get data from database by sharding item 0
return data;
case 1:
List<Foo> data = // get data from database by sharding item 1
return data;
case 2:
List<Foo> data = // get data from database by sharding item 2
return data;
// case n: ...
}
}
@Override
public void processData(ShardingContext shardingContext, List<Foo> data) {
// process data
// ...
}
}
流式作业:涉及到两个概念分片分批
即上面重写的两个方法中
fetchData用于抓取,如数据库中的待抓取歌曲中有一个字段用来标识该任务是属于哪一个分片,即到时候会在哪一个分片上执行。如有两个分片,用分片号0、1表示。1000首待抓取的歌,500首标记为0,500首标记为1。那么到时候我们将歌曲的信息作为上下文参数传入到fetch方法中,500首歌可以limit 100,每次查出100首歌进行处理,这就叫分批,一个任务被分成了2片,每片里面按照100首歌一批,分5批执行完。
processData就是按照批次每次处理100首歌,其中100首歌作为一个子事物,其中有一首歌抛异常或者出现任何失败,那么都认为这个批次执行失败,下次会将这个批次内的所有任务数据在执行一遍。
3.作业任务状态记录跟踪(通过代码配置开启事件追踪)
事件追踪的event_trace_rdb_url属性对应库自动创建JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引。
JOB_EXECUTION_LOG记录每次作业的执行历史。分为两个步骤:
作业开始执行时向数据库插入数据,除failure_cause和complete_time外的其他字段均不为空。
作业完成执行时向数据库更新数据,更新is_success, complete_time和failure_cause(如果作业执行失败)。
JOB_STATUS_TRACE_LOG记录作业状态变更痕迹表。可通过每次作业运行的task_id查询作业状态变化的生命周期和运行轨迹。
4.任务监听
可通过配置多个任务监听器,在任务执行前和执行后执行监听的方法。监听器分为每台作业节点均执行和分布式场景中仅单一节点执行2种。
4.1 每台作业节点均执行的监听
若作业处理作业服务器的文件,处理完成后删除文件,可考虑使用每个节点均执行清理任务。此类型任务实现简单,且无需考虑全局分布式任务是否完成,请尽量使用此类型监听器。
步骤:
定义监听
将监听器作为参数传入JobScheduler
//1.定义监听器
public class MyElasticJobListener implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
// do something ...
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
// do something ...
}
}
//2.将监听器作为参数传入JobScheduler
public class JobMain {
public static void main(String[] args) {
new JobScheduler(createRegistryCenter(), createJobConfiguration(), new MyElasticJobListener()).init();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("zk_host:2181", "elastic-job-demo"));
regCenter.init();
return regCenter;
}
private static LiteJobConfiguration createJobConfiguration() {
// 创建作业配置
...
}
}
4.2 分布式场景中仅单一节点执行的监听
若作业处理数据库数据,处理完成后只需一个节点完成数据清理任务即可。此类型任务处理复杂,需同步分布式环境下作业的状态同步,提供了超时设置来避免作业不同步导致的死锁,请谨慎使用。
步骤:
定义监听
将监听器作为参数传入JobScheduler
//1.定义监听器
public class TestDistributeOnceElasticJobListener extends AbstractDistributeOnceElasticJobListener {
public TestDistributeOnceElasticJobListener(long startTimeoutMills, long completeTimeoutMills) {
super(startTimeoutMills, completeTimeoutMills);
}
@Override
public void doBeforeJobExecutedAtLastStarted(ShardingContexts shardingContexts) {
// do something ...
}
@Override
public void doAfterJobExecutedAtLastCompleted(ShardingContexts shardingContexts) {
// do something ...
}
}
//2.将监听器作为参数传入JobScheduler
public class JobMain {
public static void main(String[] args) {
long startTimeoutMills = 5000L;
long completeTimeoutMills = 10000L;
new JobScheduler(createRegistryCenter(), createJobConfiguration(), new MyDistributeOnceElasticJobListener(startTimeoutMills, completeTimeoutMills)).init();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("zk_host:2181", "elastic-job-demo"));
regCenter.init();
return regCenter;
}
private static LiteJobConfiguration createJobConfiguration() {
// 创建作业配置
...
}
}
5.框架提供的分片策略
5.1 AverageAllocationJobShardingStrategy
全路径:
io.elasticjob.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。如:
如果有3台服务器,分成9片,则每台服务器分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
5.2 OdevitySortByNameJobShardingStrategy
全路径:
io.elasticjob.lite.api.strategy.impl.OdevitySortByNameJobShardingStrategy
策略说明:
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP升序。
作业名的哈希值为偶数则IP降序。
用于不同的作业平均分配负载至不同的服务器。
5.3 RotateServerByNameJobShardingStrategy
全路径:
io.elasticjob.lite.api.strategy.impl.RotateServerByNameJobShardingStrategy
策略说明:
根据作业名的哈希值对服务器列表进行轮转的分片策略。
6.运维平台
解压缩elastic-job-lite-console-${version}.tar.gz并执行bin\start.sh。打开浏览器访问http://localhost:8899/即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端口号。
elastic-job-lite-console-${version}.tar.gz可通过mvn install编译获取。
登录
提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限。默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf\auth.properties修改管理员及访客用户名及密码。
功能列表
登录安全控制
注册中心、事件追踪数据源管理
快捷修改作业设置
作业和服务器维度状态查看
操作作业禁用\启用、停止和删除等生命周期
事件追踪查询
备注:
请使用JDK1.7及其以上版本
请使用Zookeeper 3.4.6及其以上版本
请使用Maven 3.0.4及其以上版本
7.原理说明
7.1 弹性分布式实现
- 第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
- 某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
- 主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
- 定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
- 通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
- 每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
- 实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
7.2 注册中心数据结构
注册中心在定义的命名空间下,创建作业名称节点,用于区分不同作业,所以作业一旦创建则不能修改作业名称,如果修改名称将视为新的作业。作业名称节点下又包含4个数据子节点,分别是config, instances, sharding, servers和leader。
config节点
作业配置信息,以JSON格式存储
instances节点
作业运行实例信息,子节点是当前作业运行实例的主键。作业运行实例主键由作业运行服务器的IP地址和PID构成。作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心监控这些节点的变化来协调分布式作业的分片以及高可用。 可在作业运行实例节点写入TRIGGER表示该实例立即执行一次。
sharding节点
作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。节点详细信息说明:
|
子节点名 |
临时节点 |
描述 |
|
instance |
否 |
执行该分片项的作业运行实例主键 |
|
running |
是 |
分片项正在运行的状态 |
|
failover |
是 |
如果该分片项被失效转移分配给其他作业服务器,则此节点值记录执行此分片的作业服务器IP |
|
misfire |
否 |
是否开启错过任务重新执行 |
|
disabled |
否 |
是否禁用此分片项 |
servers节点
作业服务器信息,子节点是作业服务器的IP地址。可在IP地址节点写入DISABLED表示该服务器禁用。 在新的cloud native架构下,servers节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。为了更加纯粹的实现job核心,servers功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
leader节点
作业服务器主节点信息,分为election,sharding和failover三个子节点。分别用于主节点选举,分片和失效转移处理。
leader节点是内部使用的节点,如果对作业框架原理不感兴趣,可不关注此节点。
|
子节点名 |
临时节点 |
描述 |
|
election\instance |
是 |
主节点服务器IP地址 |
|
election\latch |
否 |
主节点选举的分布式锁 |
|
sharding\necessary |
否 |
是否需要重新分片的标记 |
|
sharding\processing |
是 |
主节点在分片时持有的节点 |
|
failover\items\分片项 |
否 |
一旦有作业崩溃,则会向此节点记录 |
|
failover\items\latch |
否 |
分配失效转移分片项时占用的分布式锁 |
8.作业启动

9.作业执行
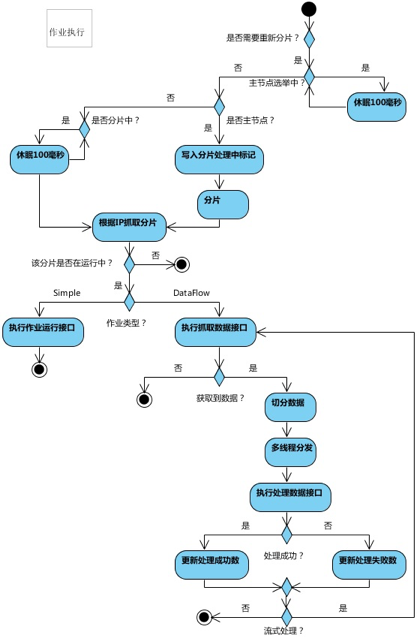
出处:http://www.cnblogs.com/lingyejun/
若本文如对您有帮助,不妨点击一下右下角的【推荐】。
如果您喜欢或希望看到更多我的文章,可扫描二维码关注我的微信公众号《翎野君》。
转载文章请务必保留出处和署名,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号