Java集合框架
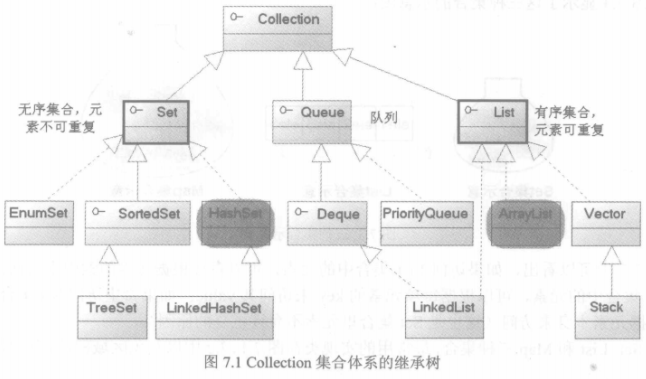
Collection是集合接口
|————Set子接口:无序,不允许重复。
|————List子接口:有序,可以有重复元素。
区别:Collections是集合类
Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
Set和List具体子类:
Set
|————HashSet:以哈希表的形式存放元素,插入删除速度很快。
List
|————ArrayList:动态数组
|————LinkedList:链表、队列、堆栈。
Array和java.util.Vector
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
Collection是集合接口

Collections是集合类

Set接口继承自Collection集合接口

List接口继承自Collection集合接口

Set接口:是Collection接口的一个子接口,它表示数学意义上的集合概念。Set中不包含重复的元素,即Set中不存两个这样的元素e1和e2,使得e1.equals(e2)为true。
1、TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的 String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例 。
package cn.czbk.no7; import java.util.HashSet; import java.util.Set; import java.util.TreeSet; public class CollectionTest { public static void main(String[] args) { HashSet hs=new HashSet(); hs.add("abc"); hs.add("abc"); hs.add("ab"); hs.add("ac"); hs.add("ab"); hs.add("ac"); hs.add("abcd"); System.out.println(hs);// //定义一个接口类型的引用变量来引用实现接口的类的实例 Set treeSet=new TreeSet(hs); System.out.println(treeSet); } }
上述代码执行完毕后的控制台打印出来的数据如下:

List接口:继承了 Collection 接口以定义一个允许重复项的有序集合。该接口不但能够对列表的一部分进行处理,还添加了面向位置的操作。
ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
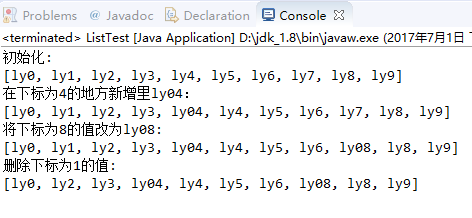
package cn.czbk.no7; import java.util.ArrayList; import java.util.List; public class ListTest { public static void main(String[] args) { List l1=new ArrayList(); for(int i=0;i<=9;i++) { l1.add("ly"+i); } System.out.println("初始化: \n"+l1); l1.add(4, "ly04"); System.out.println("在下标为4的地方新增里ly04: \n"+l1); l1.set(8, "ly08"); System.out.println("将下标为8的值改为ly08: \n"+l1); l1.remove(1); System.out.println("删除下标为1的值: \n"+l1); } }
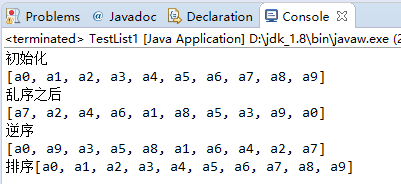
package cn.czbk.no7; import java.util.Collections; import java.util.LinkedList; import java.util.List; public class TestList1 { public static void main(String[] args) { List l1=new LinkedList(); for(int i=0;i<=9;i++){ l1.add("a"+i); } System.out.println("初始化\n"+l1); Collections.shuffle(l1); System.out.println("乱序之后\n"+l1); Collections.reverse(l1); System.out.println("逆序\n"+l1); Collections.sort(l1); System.out.println("排序"+l1); } }
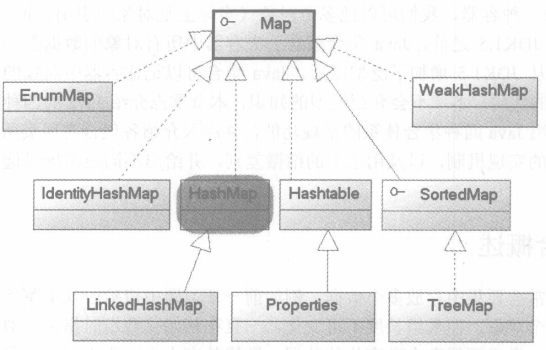
Map接口:不是 Collection 接口的继承。而是从自己的用于维护键-值关联的接口层次结构入手。按定义,该接口描述了从不重复的键到值的映射。
导读:
1 HashMap不是线程安全的
HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
2 HashTable是线程安全。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。 HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。 Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。 最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差
总结:
|
hashmap |
线程不安全 |
允许有null的键和值 |
效率高一点、 |
方法不是Synchronize的要提供外同步 |
有containsvalue和containsKey方法 |
HashMap 是Java1.2 引进的Map interface 的一个实现 |
HashMap是Hashtable的轻量级实现 |
|
hashtable |
线程安全 |
不允许有null的键和值 |
效率稍低、 |
方法是是Synchronize的 |
有contains方法方法 |
、Hashtable 继承于Dictionary 类 |
Hashtable 比HashMap 要旧 |
出处:http://www.cnblogs.com/lingyejun/
若本文如对您有帮助,不妨点击一下右下角的【推荐】。
如果您喜欢或希望看到更多我的文章,可扫描二维码关注我的微信公众号《翎野君》。
转载文章请务必保留出处和署名,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号