java中是否所有的stream流都需要主动关闭
流的概念
在输出数据时,内存中的特定数据排成一个序列,依次输出到文件中,这个数据序列就像流水一样源源不断地“流”到文件中,因此该数据序列称为输出流。同样,把文件中的数据输入到内存中时,这个数据序列就像流水一样“流”到内存中,因此把该数据序列称为输入流。
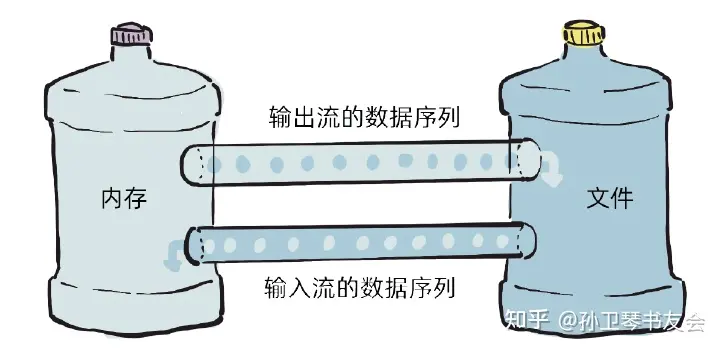
输入流与输出流
为什么要按照流的方式来读取和保存数据呢?
因为流可以保证原始数据的先后顺序不会被打乱,在很多情况下,这都是符合实际需求的。比如读一篇文章,肯定是希望从头到尾的读取文章,而不希望打乱文章的章节顺序。
无论是输入流还是输出流,如果数据序列中最小的数据单元是字节,那么称这种流为字节流。
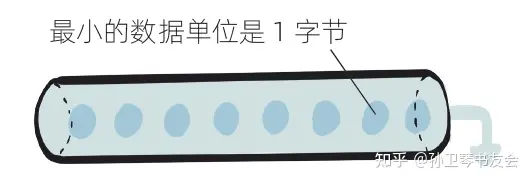
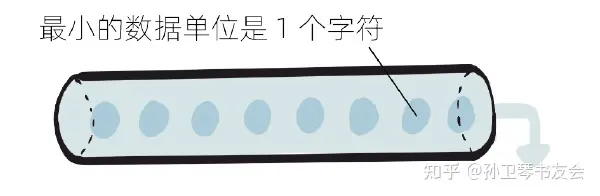
数据单元是字节的字节流如果数据序列中最小的数据单元是字符,那么称这种流为字符流。
InputStream为什么设计成不能重复读呢?
“在InputStream读取的时候,会有一个pos指针,他指示每次读取之后下一次要读取的起始位置,当读到最后一个字符的时候,pos指针不会重置。”
说的也有道理,就是说InputStream的读取是单向的。但是并不是所有的InputStream实现类都是这样的实现方式。
//BufferedInputStream代码片段:
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
//FileInputStream代码片段:
public native int read() throws IOException;
我们知道:
Java 的List内部是使用数组实现的,遍历的时候也有一个pos指针。但是没有说List遍历一个第二次遍历就没有了。第二次遍历是创建新的Iterator,所以pos也回到了数组起始位置。对于某些InputStream当然可以也这么做。例如:ByteArrayInputStream
ByteArrayInputStream就是将一个Java的byte数组保存到对象里,然后读取的时候遍历该byte数组。
就ByteArrayInputStream而言,要实现重复读取是很简单的,但是为什么没有。我想是为了遵循InputStream的统一标准。
在InputStream的read方法的注释上明确说明:
当流到达末尾后,返回-1.
InputStream顾名思义就是一个单向的字节流,跟水流一样,要想再次使用就自己再去源头取一下。
你看看上面那个图就明白了,InputStream是中间的管道,并不是左右两边的桶要想喝水了,就在把水管架在水源与杯子之间,让水流到杯子里(注意:这个动作完成了之后水管里面就没有水了)。
这样看来,InputStream其实是一个数据通道,只负责数据的流通,并不负责数据的处理和存储等其他工作范畴。
前面讲过,其实有的InputStream实现类是可以实现数据的处理工作的。但是没有这么做,这就是规范和标准的重要性。
流在传输过程中的缓冲区概念
先上个例子:
public class FlushTest {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("F:\\Hello1.txt"); //大文件
FileWriter fileWriter = new FileWriter("F:\\Hello2.txt");
int readerCount = 0;
//一次读取1024个字符
char[] chars = new char[1024];
while (-1 != (readerCount = fileReader.read(chars))) {
fileWriter.write(chars, 0, readerCount);
}
}
}
这里并没有调用close()方法。close()方法包含flush()方法 ,即close会自动flush结果:
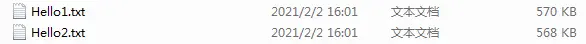
可以看到,复制的文件变小了。明显,数据有丢失,丢失的就是缓冲区“残余”的数据。在计算机层面,Java对磁盘进行操作,IO是有缓存的,并不是真正意义上的一边读一边写,底层的落盘(数据真正写到磁盘)另有方法。所以,最后会有一部分数据在内存中,如果不调用flush()方法,数据会随着查询结束而消失,这就是为什么数据丢失使得文件变小了。
BufferedOutputStream、BufferedFileWriter 同理再举个例子:
class FlushTest2{
public static void main(String[] args) throws IOException {
FileWriter fileWriter = new FileWriter("F:\\Hello3.txt");
fileWriter.write("今天打工你不狠,明天地位就不稳\n" +
"今天打工不勤快,明天社会就淘汰");
}
}
不调用flush()方法你会发现,文件是空白的,没有把数据写进来,也是因为数据在内存中而不是落盘到磁盘了。所以为了实时性和安全性,IO在写操作的时候,需要调用flush()或者close()

close() 和flush()的区别:
关close()是闭流对象,但是会先刷新一次缓冲区,关闭之后,流对象不可以继续再使用了,否则报空指针异常。
flush()仅仅是刷新缓冲区,准确的说是"强制写出缓冲区的数据",流对象还可以继续使用。
总结一下:
1、Java的IO有一个 缓冲区 的概念,不是Buffer概念的缓冲区。
2、如果是文件读写完的同时缓冲区刚好装满 , 那么缓冲区会把里面的数据朝目标文件自动进行读或写(这就是为什么总剩下有一点没写完) , 这种时候你不调用close()方法也0不会出现问题
3、如果文件在读写完成时 , 缓冲区没有装满,也没有flush(), 这个时候装在缓冲区的数据就不会自动的朝目标文件进行读或写 , 从而造成缓冲区中的这部分数据丢失 , 所以这个是时候就需要在close()之前先调用flush()方法 , 手动使缓冲区数据读写到目标文件。
举个很形象的例子加深理解:我从黄桶通过水泵把水抽到绿桶,水管就相当于缓冲区,当我看到黄桶水没有了,我立马关了水泵,但发现水管里还有水没有流到绿桶,这些残留的水就相当于内存中丢失的数据。如果此时我再把水泵打开,把水管里的水都抽了一遍,此时水管里面的水又流到了绿桶,这就相当于调用了flush()方法。

java Stream对象如果不关闭会发生什么?
比如FileStream或者说HttpClient 中的HTTPResponse,不关闭会发生什么呢?或者说调用close防范实际上在底层都做了哪些事?
看是什么类了, 不同的类的close里执行的逻辑当然是不一样的. close就是用来做收尾工作的, 如果你学过servlet, 可以认为就是servlet的destroy方法.
有一些类会占用特殊资源(比如文件句柄, 线程, 数据库连接等), 而这些资源是有限的/比较消耗性能的, 而且不会自动释放(或者需要很久才能自动释放), 因此需要你在不用的时候及时释放, 避免浪费资源.
比如IO里面的:
FileInputStream会占用系统里的一个文件句柄, 每个进程可以打开的文件数量是有限的, 如果一直打开而不关闭, 理论上迟早会遇到无法打开的情况.StringWriter就没有什么.close方法没什么卵用
Closing a StringWriter has no effect. The methods in this class can be called after the stream has been closed without generating an IOException.
ps: FileInputStream的finalize方法会自动调用close方法. 但是需要等待很长很长时间. 所以最好自己手工调用.
一般而言, 如果是接口里有close方法, 我们调用时是不应该关注close里究竟执行了什么, 不调用是不是有坏处, 而应该是始终调用
你打开文件是会在系统里有一个文件句柄的,这个句柄数量操作系统里是有限的,如果不close,这个句柄所代表的资源就泄露了,就跟悬垂指针一样,如果量大或时间长了之后再打开文件就可能打不开了,超过了系统的限制
有没有不需要关闭的流
曾几何时,作为java程序员要记住的一条准则就是,流用完了一定要在关闭,一定要写在finally里。
finally {
out.flush();
out.close();
}
但是最近发现一个stream是不需要关闭的。它就是ByteArrayOutputStream,当然还有它的妹妹ByteArrayInputStream和表哥StringWriter。道理一样,我们就不讨论亲戚们了。 作为一种OutputStream它也extends了OutputStream,自然也有继承了flush()和close()。 但这2个方法的方法体为空。
/**
* Closing a <tt>ByteArrayOutputStream</tt> has no effect. The methods in
* this class can be called after the stream has been closed without
* generating an <tt>IOException</tt>.
*/
public void close() throws IOException {
}
/***
* OutputStream的方法,ByteArrayInputStream并未重写
*/
public void flush() throws IOException {
}
究其原因也不难理解。其实ByteArrayInputStream内部实现是一个byte数组,是基于内存中字节数据的访问。并没有占用硬盘,网络等资源。就算是不关闭,用完了垃圾回收器也会回收掉。这点跟普通数组并没有区别。既然是操作内存,就要考虑到内存大小,如果字节流太大,就要考虑内存溢出的情况。
但是,作为一个蛋疼的程序员,习惯性关闭流是一个好习惯,不管三七五十八,先close掉再说,现在close是空方法,保不齐哪天就有了呢?这也是百利无一害的事,就好像保健品,吃了不治病,但是也吃不坏。
- 结论就是:指向内存的流可以不用关闭,指向硬盘/网络等外部资源的流一定要关闭。
本篇文章如有帮助到您,请给「翎野君」点个赞,感谢您的支持。
出处:http://www.cnblogs.com/lingyejun/
若本文如对您有帮助,不妨点击一下右下角的【推荐】。
如果您喜欢或希望看到更多我的文章,可扫描二维码关注我的微信公众号《翎野君》。
转载文章请务必保留出处和署名,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号