Linux五大网络模型之I/O多路复用浅入深出
网上寻得一篇讲解Linux I/O模型很好的文章,特此引用。
文章摘录自:https://new.qq.com/rain/a/20210610A05G9600
浅入深出的解释
清·俞樾《湖楼笔谈》六:“盖诗人用意之妙,在乎深入显出。入之不深,则有浅易之病;出之不显,则有艰涩之患。”
从出处可知,“入”说的是内容,“出”说的是表达,内容在文字之下,文字驾驭内容,是上下结构的深入浅出!
如果把一篇技术文章看作是一个房间,文章的开头是一道门,从此进入;文章的结束是另一道门,从此而出!那么“深入浅出”或者“浅入深出”就有不同的意思了!
就技术文章而言,“浅”莫过于举例,再抽象的理论,一个例子可以将你带入情景,理解起来也就简单了;“深”莫过于公式、拗口结论了,最精炼,但也最难懂!
如此定义,“深入浅出”就是一开始抛结论,先把读者震慑住,后面再慢慢地用浅显的例子解释阐述;“浅入深出”是一开始给你一个生动的例子,然后慢慢扩展延伸后再下结论!
个人喜好,中意“浅入深出”多点,如果是“深入浅出”的文章我也经常倒过来看,把它矫正为“浅入深出”,一来可以少死一点脑细胞,二来防止在先看到结论的情况下,自己举不恰当的例子去理解而误入歧途
正文:
基本概念
我们先来了解几个基本概念。
什么是I/O?
所谓的I/O(Input/Output)操作实际上就是输入输出的数据传输行为。程序员最关注的主要是磁盘IO和网络IO,因为这两个IO操作和应用程序的关系最直接最紧密。
磁盘IO:磁盘的输入输出,比如磁盘和内存之间的数据传输。
网络IO:不同系统间跨网络的数据传输,比如两个系统间的远程接口调用。
下面这张图展示了应用程序中发生IO的具体场景:
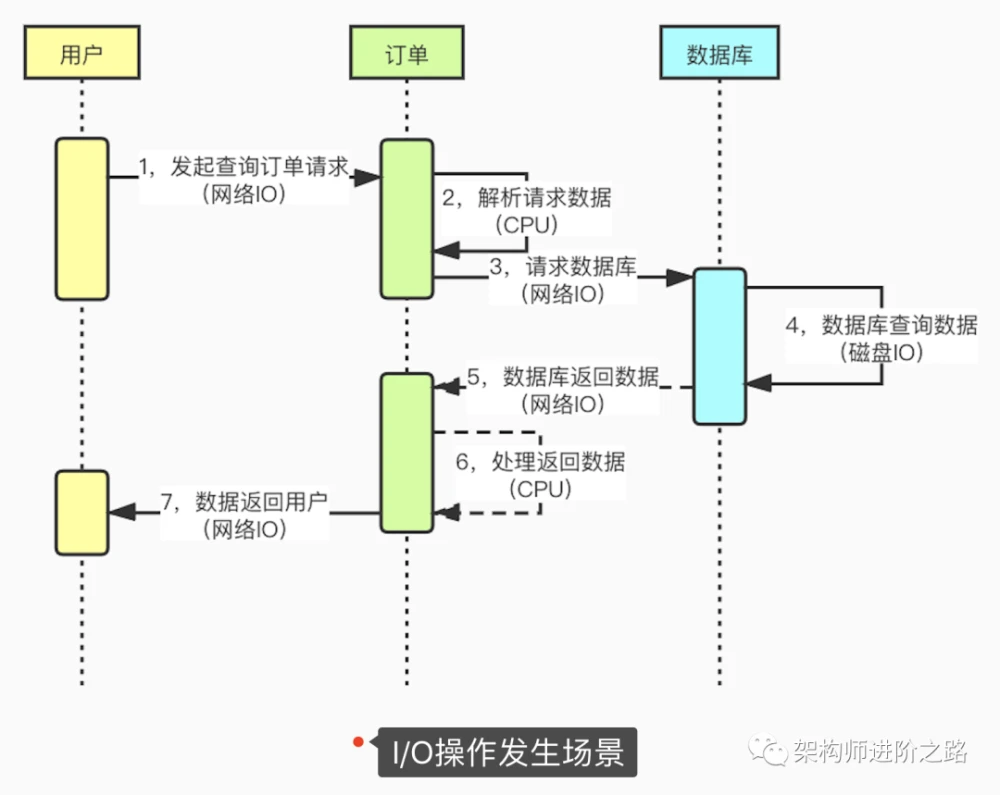
通过上图,我们可以了解到IO操作发生的具体场景。一个请求过程可能会发生很多次的IO操作:
1,页面请求到服务器会发生网络IO
2,服务之间远程调用会发生网络IO
3,应用程序访问数据库会发生网络IO
4,数据库查询或者写入数据会发生磁盘IO
阻塞与非阻塞
所谓阻塞,就是发出一个请求不能立刻返回响应,要等所有的逻辑全处理完才能返回响应。
非阻塞反之,发出一个请求立刻返回应答,不用等处理完所有逻辑。
内核空间与用户空间
在Linux中,应用程序稳定性远远比不上操作系统程序,为了保证操作系统的稳定性,Linux区分了内核空间和用户空间。可以这样理解,内核空间运行操作系统程序和驱动程序,用户空间运行应用程序。Linux以这种方式隔离了操作系统程序和应用程序,避免了应用程序影响到操作系统自身的稳定性。这也是Linux系统超级稳定的主要原因。
所有的系统资源操作都在内核空间进行,比如读写磁盘文件,内存分配和回收,网络接口调用等。所以在一次网络IO读取过程中,数据并不是直接从网卡读取到用户空间中的应用程序缓冲区,而是先从网卡拷贝到内核空间缓冲区,然后再从内核拷贝到用户空间中的应用程序缓冲区。对于网络IO写入过程,过程则相反,先将数据从用户空间中的应用程序缓冲区拷贝到内核缓冲区,再从内核缓冲区把数据通过网卡发送出去。
Socket(套接字)
Socket可以理解成,在两个应用程序进行网络通信时,一个应用程序将数据写入Socket,然后通过网卡把数据发送到另外一个应用程序的Socket中。
所有的网络协议都是基于Socket进行通信的,不管是TCP还是UDP协议,应用层的HTTP协议也不例外。这些协议都需要基于Socket实现网络通信。5种网络IO模型也都要基于Socket实现网络通信。实际上,HTTP协议是建立在TCP协议之上的应用层协议。HTTP协议负责如何包装数据,而TCP协议负责如何传输数据。
绝大部分编程语言,都支持Socket编程,例如Java,Php,Python等等。而这些语言的Socket SDK都是基于操作系统提供的 socket() 函数来实现的。不管是Linux还是windows,都提供了相应的 socket() 函数。
Socket 编程过程
我们来看看Socket 编程过程是怎样的。
不管Java、Python还是Php,很多编程语言都支持Socket编程。Linux,Windows等操作系统都开放了网络编程接口。只不过,各种编程语言对底层操作系统提供的网络编程接口做了封装而已。
从服务端开始,服务端首先调用 函数,按指定的网络协议和传输协议创建 Socket ,例如创建一个网络协议为 IPv4,传输协议为 TCP 的Socket。接着调用 函数,给这个 Socket 绑定一个 IP 地址和端口,绑定这两个的目的是什么?
绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里的端口号,来找到我们的应用程序,然后把数据传递给我们
绑定 IP 地址的目的:一台机器可能有多个网卡,每个网卡都对应一个 IP 地址,只有绑定一个网卡对应的IP时,内核在收到该网卡上的包,才会发给我们的应用程序
绑定完 IP 地址和端口后,就可以调用 函数进行监听。如果我们要判定服务器上某个网络程序有没有启动,可以通过 命令查看对应的端口号是否被监听。
服务端进入了监听状态后,通过调用 函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。
那客户端是怎么发起连接的呢?客户端在创建好 Socket 后,调用 函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后众所周知的 TCP 三次握手就开始了。
连接建立后,客户端和服务端就开始相互传输数据了,双方可以通过 和 函数来读写数据。
基于TCP 协议的 Socket 编程过程就结束了,整个过程如下图所示:
网络IO模型
5种Linux网络IO模型包括:同步阻塞IO、同步非阻塞IO、多路复用IO、信号驱动IO和异步IO。
同步阻塞IO
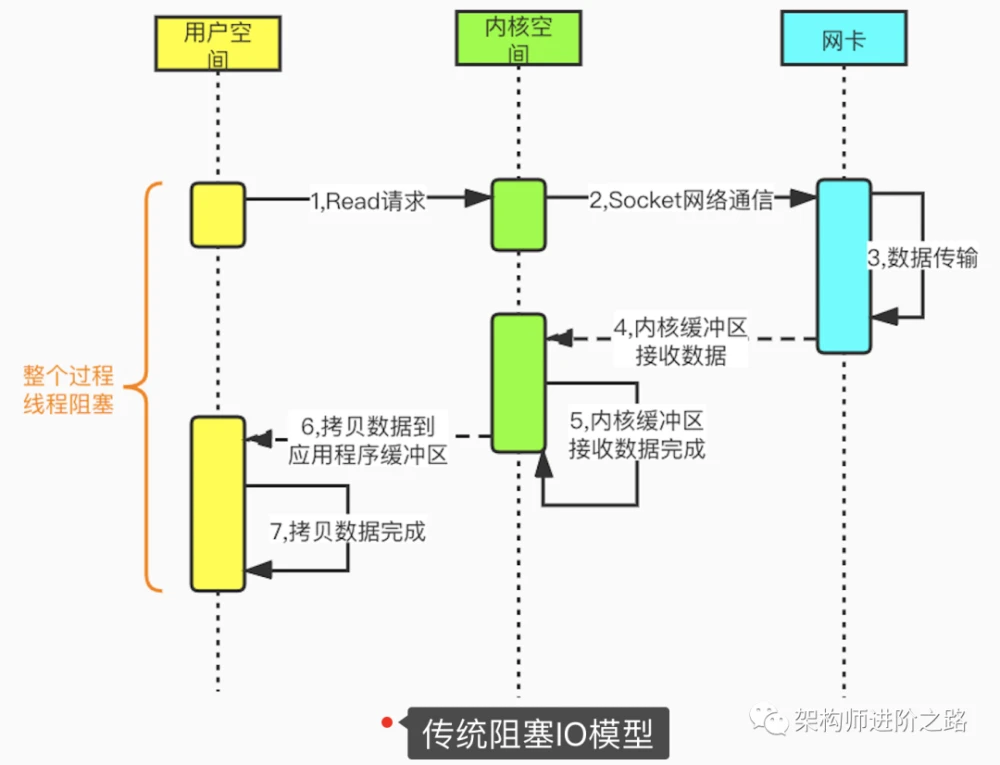
我们先看一下传统阻塞IO。在Linux中,默认情况下所有socket都是阻塞模式的。当用户线程调用系统函数read(),内核开始准备数据(从网络接收数据),内核准备数据完成后,数据从内核拷贝到用户空间的应用程序缓冲区,数据拷贝完成后,请求才返回。从发起read请求到最终完成内核到应用程序的拷贝,整个过程都是阻塞的。为了提高性能,可以为每个连接都分配一个线程。因此,在大量连接的场景下就需要大量的线程,会造成巨大的性能损耗,这也是传统阻塞IO的最大缺陷。
同步非阻塞IO
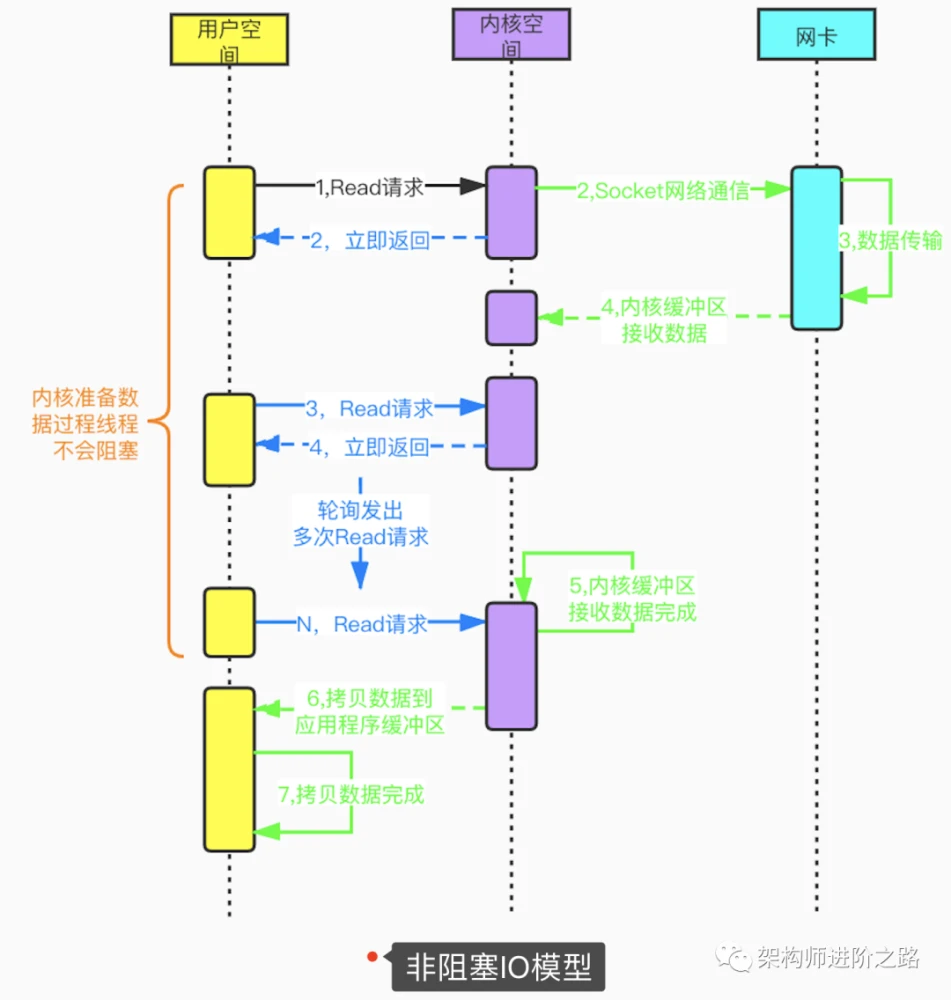
用户线程在发起Read请求后立即返回,不用等待内核准备数据的过程。如果Read请求没读取到数据,用户线程会不断轮询发起Read请求,直到数据到达(内核准备好数据)后才停止轮询。非阻塞IO模型虽然避免了由于线程阻塞问题带来的大量线程消耗,但是频繁的重复轮询大大增加了请求次数,对CPU消耗也比较明显。这种模型在实际应用中很少使用。
多路复用IO模型
多路复用IO模型,建立在多路事件分离函数select,poll,epoll之上。在发起read请求前,先更新select的socket监控列表,然后等待select函数返回(此过程是阻塞的,所以说多路复用IO并非完全非阻塞)。当某个socket有数据到达时,select函数返回。此时用户线程才正式发起read请求,读取并处理数据。这种模式用一个专门的监视线程去检查多个socket,如果某个socket有数据到达就交给工作线程处理。由于等待Socket数据到达过程非常耗时,所以这种方式解决了阻塞IO模型一个Socket连接就需要一个线程的问题,也不存在非阻塞IO模型忙轮询带来的CPU性能损耗的问题。多路复用IO模型的实际应用场景很多,比如大家耳熟能详的Java NIO,Redis,Nginx以及Dubbo采用的通信框架Netty都采用了这种模型。
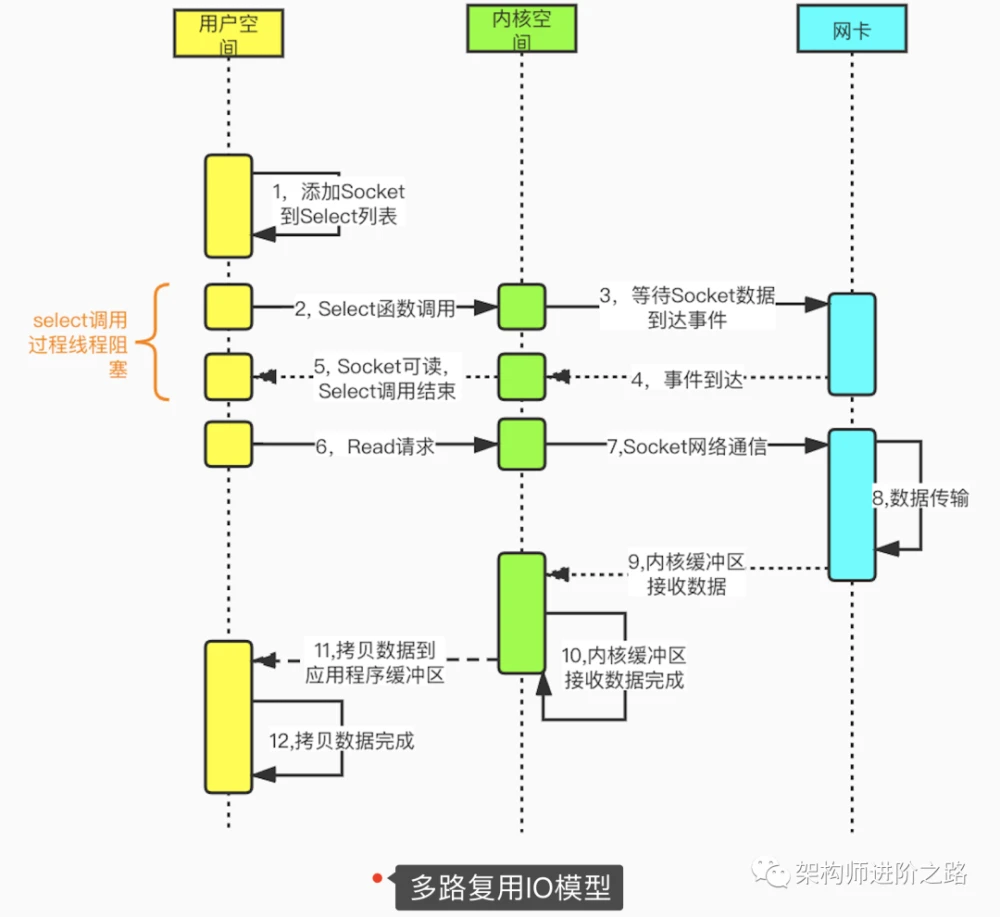
下图是基于select函数Socket编程的详细流程。
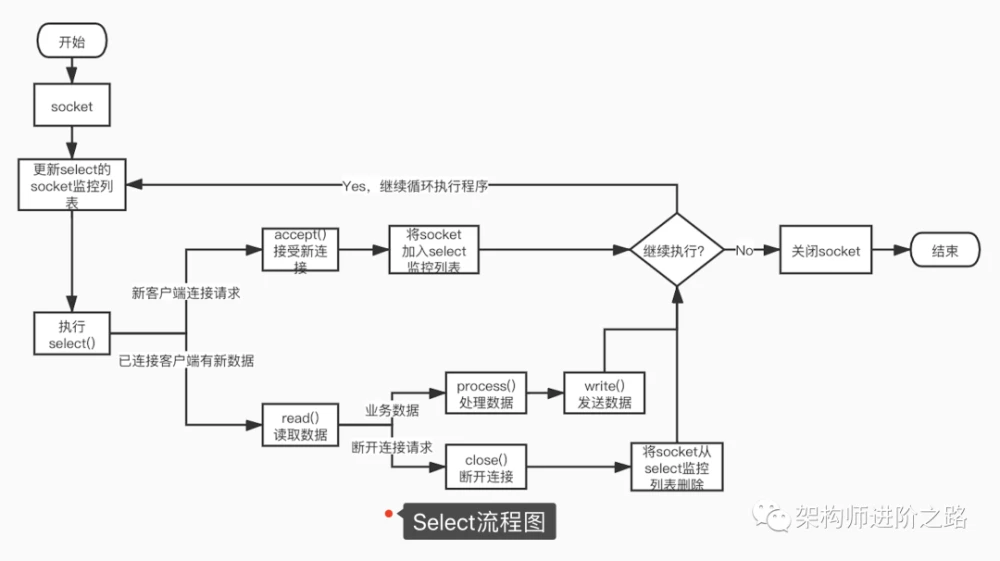
用一句话解释多路复用模型。多路:可以理解成多个网络连接(TCP连接)。复用:服务端反复使用同一个线程去监听所有网络连接中是否有IO事件(如果有IO事件就交给工作线程从对应的连接中读取并处理数据)。
信号驱动IO模型
信号驱动IO模型,应用进程使用sigaction函数,内核会立即返回,也就是说内核准备数据的阶段应用进程是非阻塞的。内核准备好数据后向应用进程发送SIGIO信号,接到信号后数据被复制到应用程序进程。
采用这种方式,CPU的利用率很高。不过这种模式下,在大量IO操作的情况下可能造成信号队列溢出导致信号丢失,造成灾难性后果。
异步IO模型
异步IO模型的基本机制是,应用进程告诉内核启动某个操作,内核操作完成后再通知应用进程。在多路复用IO模型中,socket状态事件到达,得到通知后,应用进程才开始自行读取并处理数据。在异步IO模型中,应用进程得到通知时,内核已经读取完数据并把数据放到了应用进程的缓冲区中,此时应用进程
直接使用数据即可。
很明显,异步IO模型性能很高。不过到目前为止,异步IO和信号驱动IO模型应用并不多见,传统阻塞IO和多路复用IO模型还是目前应用的主流。Linux2.6版本后才引入异步IO模型,目前很多系统对异步IO模型支持尚不成熟。很多应用场景采用多路复用IO替代异步IO模型。
文章引用
https://new.qq.com/rain/a/20210610A05G9600
出处:http://www.cnblogs.com/lingyejun/
若本文如对您有帮助,不妨点击一下右下角的【推荐】。
如果您喜欢或希望看到更多我的文章,可扫描二维码关注我的微信公众号《翎野君》。
转载文章请务必保留出处和署名,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号