2.安装Spark与Python练习
一、安装Spark
- 检查基础环境hadoop,jdk

- 下载spark
(已完成,略过)
- 解压,文件夹重命名、权限
(已完成,略过)
- 配置文件
(已完成,略过)
- 环境变量

- 试运行Python代码
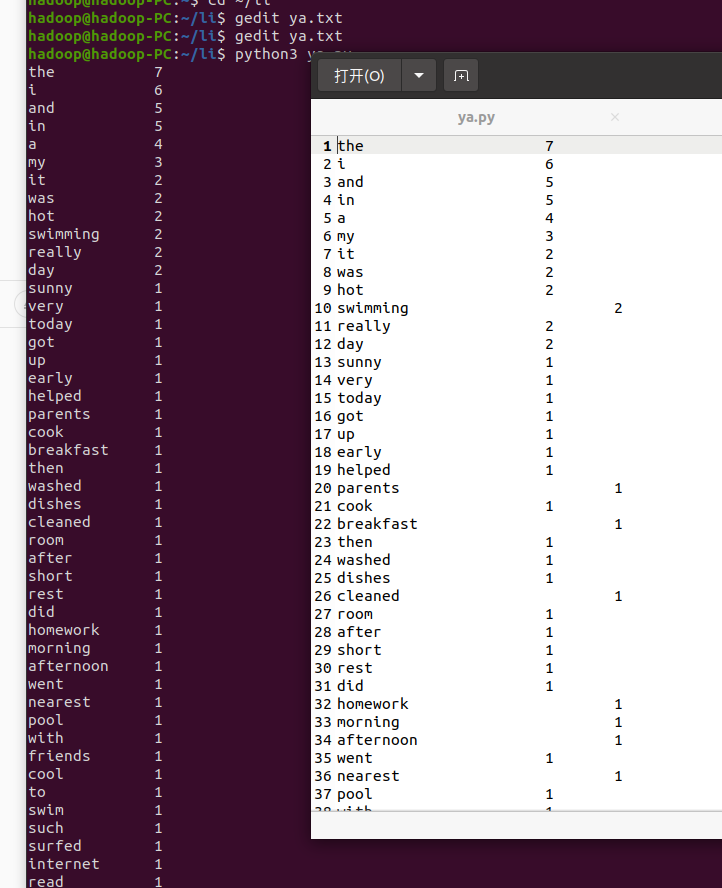
二、Python编程练习:英文文本的词频统计
- 准备文本文件

2.读文件
path='/home/hadoop/li/ya.txt'
with open(path) as f:
text=f.read()
3.预处理:大小写,标点符号,停用词
text = text.lower() # 转为小写字母
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
text = text.replace(ch, ' ')
4.分词
words = text.split()
- 统计每个单词出现的次数
counts={}
for word in words:
# 若字典中无当前词语则创建一个键值对,若有则将原有值加1
counts[word] = counts.get(word, 0) + 1
items = list(counts.items()) # 将无序的字典类型转换为有序的列表类型
- 按词频大小排序
items.sort(key=lambda x: x[1], reverse=True) # 按统计值从高到低排序(以第二列排序)
for i in range(len(items)):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count)) # 格式化输出词频统计结果
open('output.txt', 'a').write(word+"\t\t\t"+str(count)+"\n") # 写入output.txt中
- 结果写文件