

微博关系
风起
2009 年微博刚刚上线的时候,微博关系服务使用的是最传统的 Memcache+Mysql 的方案。Mysql 按 uid hash 进行了分库分表,表结构非常简单:
tid fromuid touid addTime 自增 id 关系主体 关系客体 加关注时间业务方存在两种查询:
- 查询用户的关注列表:select touid from table where fromuid=?order by addTime desc
- 查询用户的粉丝列表:select fromuid from table where touid=?order by addTime desc
两种查询的业务需求与分库分表的架构设计存在矛盾,最终导致了冗余存储:以 fromuid 为 hash key 存一份,以 touid 为 hash key 再存一份。memcache key 为 fromuid.suffix ,使用不同的 suffix 来区分是关注列表还是粉丝列表,cache value 则为 PHP Serialize 后的 Array。后来为了优化性能,将 value 换成了自己拼装的 byte 数组。
云涌
2011 年微博进行平台化改造过程中,业务提出了新的需求:在核心接口中增加了“判断两个用户的关系”的步骤,并增加了“双向关注”的概念。因此两个用户的关系存在四种状态:关注,粉丝,双向关注和无任何关系。为了高效的实现这个需求,平台引入了 Redis 来存储关系。平台使用 Redis 的 hash 来存储关系:key 依然是 uid.suffix,关注列表,粉丝列表及双向关注列表各自有一个不同的 suffix,value 是一个 hash,field 是 touid,value 是 addTime。order by addTime 的功能则由 Service 内部 sort 实现。部分大 V 的粉丝列表可能很长,与产品人员的沟通协商后,将存储限定为“最新的 5000 个粉丝列表”。
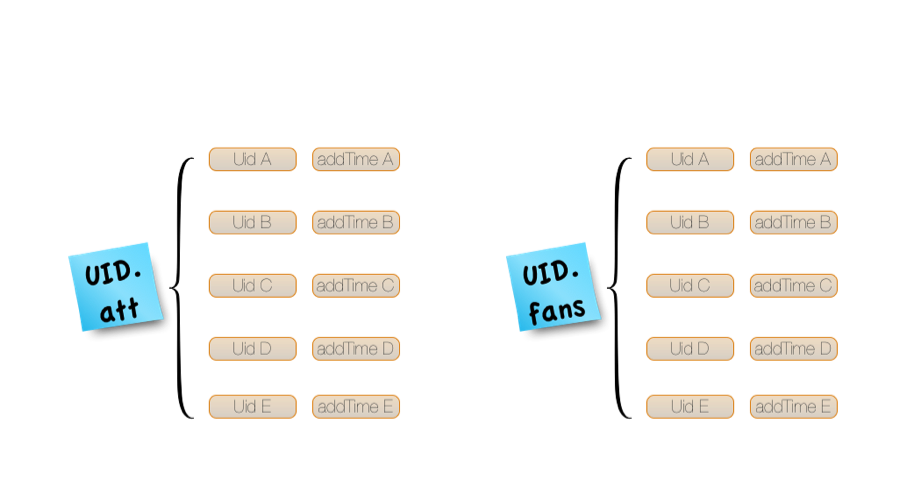
微博关系存储 Redis 结构
需求实现:
- 查询用户关注列表:hgetAll uid.following ,then sort
- 查询用户粉丝列表:hgetAll uid.follower,then sort
- 查询用户双向关注列表:hgetAll uid.bifollow,then sort
- 判断两个用户关系:hget uidA.following uidB && hget uidB.following uidA
后来又增加了几个更复杂的需求:“我与他的共同关注列表”、“我关注的人里谁关注了他”等等,就不展开来讲了。
平台在刚引入 Redis 的一段时间里踩了不少坑,举几个例子:
- 运维工具和流程从零开始做,运维成熟的速度赶不上业务增长的速度:在还没来得及安排性能调优的工作,fd 已经达到默认配置的上限了,最后我们只能趁凌晨业务低峰期重启 Redis 集群,以便设置新的 ulimit 参数
- 平台最开始使用的 Redis 版本是 2.0,因为 Redis 代码足够简单,从引入到微博起,我们就开始对其进行了定制化开发,从主从复制,到写磁盘限速,再到内存管理,都进行了定制。导致的结果是,有一段时间,微博的线上存在超过 5 种不同的 Redis 修改版,对于运维,bugfix,升级都带来了巨大的麻烦。后来由田风军 @果爸果爸 为内部 Redis 版本提供了不停机升级功能后,才慢慢好转。
- 平台有一个业务曾经使用了非默认 db ,后来费了好大力气去做迁移
- 平台还有一个业务需要定期对数据进行 flush db ,以腾出空间存储最新数据。为了避免在 flush db 阶段影响线上业务,我们从 client 到 server 都做了大量的修改。
- 平台每年长假前都会做一些线上业务排查,和故障模拟(2013 年甚至做了一个名叫 Touchstone 的容灾压测系统)。2011 年十一假前,我们用 iptables 将 Redis 端口的所有包都 drop 掉,结果 client 端等了 120 秒才返回。于是我们在放假前熬夜加班给 client 添加超时检测功能,但真正上线还是等到了假期回来后。
破茧
对于微博关系服务,最大的挑战还是容量和访问量的快速增长,这给我们的 Redis 方案带来了不少的麻烦:
第一个碰到的麻烦是 Redis 的 hgetAll 在 hash size 较大的场景下慢请求比例较高。我们调整了 hash-max-zip-size,节约了 1/3 的内存,但对业务整体性能的提升有限。最后,我们不得不在 Redis 前面又挡了一层 memcache,用来抗 hgetAll 读的问题。
第二个麻烦是新上的需求:“我关注的人里谁关注了他”,由于用户的粉丝列表可能不全,在这种情况下就不能用关注列表与粉丝列表求交集的方式来计算结果,只能降级到需求的字面描述步骤:取我的关注人列表,然后逐个判断这些人里谁关注了他。client 端分批并行发起请求,还好 Redis 的单个关系判断非常快。
第三个麻烦,也是最大的麻烦,就是容量增长的问题了。最初的设计方案,按 uid hash 成 16 个端口,每台 64G 内存的机器上部署 2 个端口,每个业务 IDC 机房部署一套。后来,每台机器上就只部署一个端口了。再后来,128G 内存的机器还没有进入公司采购目录,64G 内存就即将 OOM 了,所以我们不得不做了一次端口扩容:16 端口拆 64 端口,依然是每台 64G 内存机器上部署 2 个端口。再后来,又只部署一个端口。再后来,升级到 128G 内存机器。再后来,128G 机器上出现 OOM 了!现在怎么办?
化蝶
为了从根本上解决容量的问题,我们开始寻找一种本质的解决方案。最初选择引入 Redis 作为一个 storage,是因为用户关系判断功能请求的数据热点不是很集中,长尾效果明显,cache miss 可能会影响核心接口性能,而保证一个可接受的 cache 命中率,耗费的内存与 storage 差别不大。但微博经过了 3 年的演化,最初作为选择依据的那些假设前提,数据指标都已经发生了变化:随着用户基数的增大,冷用户的绝对数量也在增大;Redis 作为存储,为了数据可靠性必须开启 rdb 和 aof,而这会导致业务只能使用一半的机器内存;Redis hash 存储效率太低,特别是与内部极度优化过的 RedisCounter 对比。种种因素加在一起,最终确定下来的方向就是:将 Redis 在这里的 storage 角色降低为 cache 角色。
前面提到的微博关系服务当前的业务场景,可以归纳为两类:一类是取列表,一类是判断元素在集合中是否存在,而且是批量的。即使是 Redis 作为 storage 的时代,取列表都要依赖前面的 memcache 帮忙抗,那么作为 cache 方案,取列表就全部由 memcache 代劳了。批量判断元素在集合中是否存在,redis hash 依然是最佳的数据结构,但存在两个问题:cache miss 的时候,从 db 中获取数据后,set cache 性能太差:对于那些关注了 3000 人的微博会员们,set cache 偶尔耗时可达到 10ms 左右,这对于单线程的 Redis 来说是致命的,意味着这 10ms 内,这个端口无法提供任何其它的服务。另一个问题是 Redis hash 的内存使用效率太低,对于目标的 cache 命中率来说,需要的 cache 容量还是太大。于是,我们又祭出 “Redis 定制化”的法宝:将 redis hash 替换成一个“固定长度开放 hash 寻址数组”,在 Redis 看来就是一个 byte 数组,set cache 只需要一次 redis set。通过精心选择的 hash 算法及数组填充率,能做到批量判断元素是否存在的性能与原生的 redis hash 相当。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2015-03-10 MySQL 表的命令