
缓存淘汰算法(LFU、LRU、ARC、FIFO、2Q)
缓存算法用于决定缓存系统中哪些数据应该被删去。
LFU(Least Frequently Used):最近最不常用算法,根据数据的历史访问频率来淘汰数据。
核心思想是:最近使用频率高的数据很大概率将会再次被使用,而最近使用频率低的数据,很大概率不会再使用。
做法:把使用频率最小的数据置换出去。这种算法是完全从使用频率的角度去考虑的。
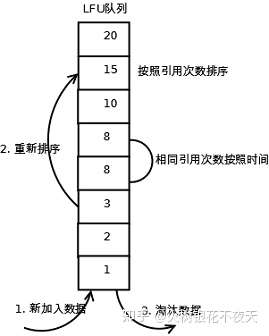
执行过程理解:
- 在缓存中查找客户端需要访问的数据
- 如果缓存命中,则将访问的数据从队列中取出,并将数据对应的频率计数加1,然后将其放到频率相同的数据队列的头部,比如原来是A(10)->B(9)->C(9)->D(8),D被访问后,它的time变成了9,这时它被提到A和B之间,而不是继续在C后面
- 如果没有命中,表示缓存穿透,将需要访问的数据从磁盘中取出,加入到缓存队列的尾部,记频率为1,这里也是加入到同为1的那一级的最前面
- 如果此时缓存满了,则需要先置换出去一个数据,淘汰队列尾部频率最小的数据,然后再在队列尾部加入新数据。
存在的问题:
某些数据短时间内被重复引用,并且在很长一段时间内不再被访问。由于它的访问频率计数急剧增加,即使它在相当长的一段时间内不会被再次使用,也不会在短时间内被淘汰。这使得其他可能更频繁使用的块更容易被清除,此外,刚进入缓存的新项可能很快就会再次被删除,因为它们的计数器较低,即使之后可能会频繁使用。
LRU(Least Recently User) 最近最少使用算法,根据数据的历史访问记录来进行淘汰数据
核心思想是:最近使用的数据很大概率将会再次被使用。而最近一段时间都没有使用的数据,很大概率不会再使用。
做法:把最长时间未被访问的数据置换出去。这种算法是完全从最近使用的时间角度去考虑的。
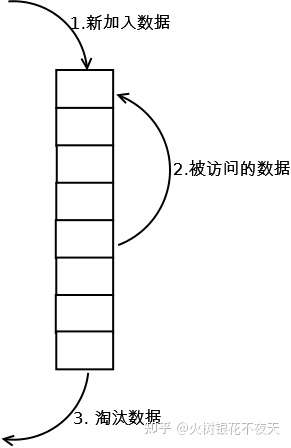
执行过程理解:
- 在缓存中查找客户端需要访问的数据 如果缓存命中,则将访问的数据中队列中取出,重新加入到缓存队列的头部。
- 如果没有命中,表示缓存穿透,将需要访问的数据从磁盘中取出,加入到缓存队列的尾部;
- 如果此时缓存满了,淘汰队列尾部的数据,然后再在队列头部加入新数据。
存在的问题:
缓存污染:如果某个客户端访问大量历史数据时,可能使缓存中的数据被这些历史数据替换,其他客户端访问数据的命中率大大降低。
ARC(Adaptive Replacement Cache): 自适应缓存替换算法,它结合了LRU与LFU,来获得可用缓存的最佳使用。
核心思想是:当时访问的数据趋向于访问最近的内容,会更多地命中LRU list,这样会增大LRU的空间; 当系统趋向于访问最频繁的内容,会更多地命中LFU list,这样会增加LFU的空间.
执行过程理解:
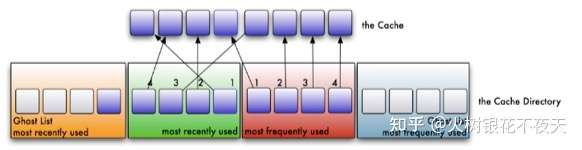
1. 整个Cache分成两部分,起始LRU和LFU各占一半,后续会动态适应调整partion的位置(记为p)除此,LRU和LFU各自有一个ghost list(因此,一共4个list)
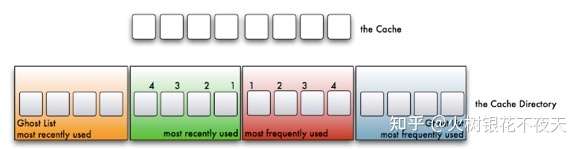
2. 在缓存中查找客户端需要访问的数据, 如果没有命中,表示缓存穿透,将需要访问的数据 从磁盘中取出,放到LRU链表的头部。
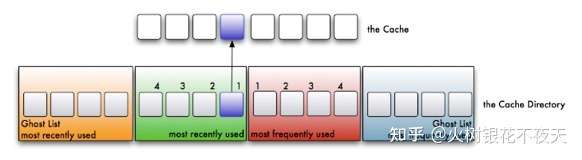
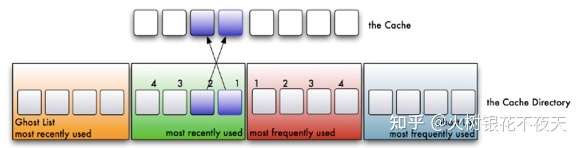
3. 如果命中,且LFU链表中没有,则将数据放入LFU链表的头部,所有LRU链表中的数据都必须至少被访问两次才会进入LFU链表。如果命中,且LFU链表中存在,则将数据重新放到LFU链表的头部。这么做,那些真正被频繁访问的页面将永远呆在缓存中,不经常访问的页面会向链表尾部移动,最终被淘汰出去。
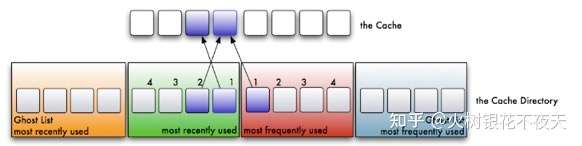
4. 如果此时缓存满了,则从LRU链表中淘汰链表尾部的数据,将数据的key放入LRU链表对应的ghost list。然后再在链表头部加入新数据。如果ghost list中的元素满了,先按照先进先出的方式来淘汰ghost list中的一个元素,然后再加入新的元素。
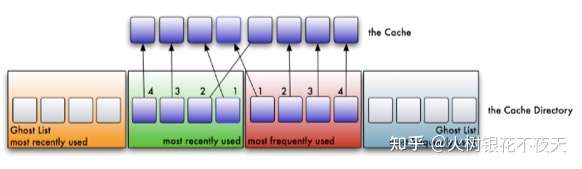
这里注意上面的the cache才是实际的LRU和LFU结合的链表,因此是删除了LRU链表的尾部元素,尾部元素对应下面的位置索引是1。
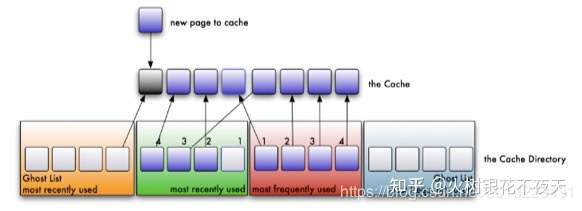
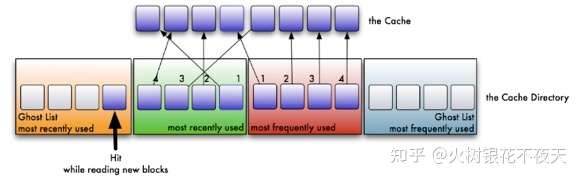
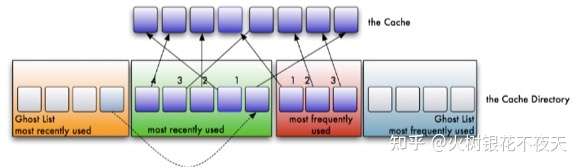
5. 如果没有命中的数据key处于ghost list中,则表示是一次幽灵(phantom)命中,系统知道,这是一个刚刚淘汰的页面,而不是第一次读取或者说很久之前读取的一个页面。ARC用这个信息来调整它自己,以适应当前的I/O模式(workload)。这个迹象说明我们的LRU缓存太小了。在这种情况下,LRU链表的长度将会被增加1,并将命中的数据key从ghost list中移除,放入LRU链表的头部。显然,LFU链表的长度将会被减少1。同样,如果一次命中发生在LFU ghost 链表中,它会将LRU链表的长度减一,以此在LFU 链表中加一个可用空间。
FIFO(First in First out),先进先出算法,最先进入的数据,最先被淘汰。
核心思想是:最近刚访问的,将来访问的可能性比较大 ,如果一个数据最先进入缓存中,则应该最早淘汰掉。
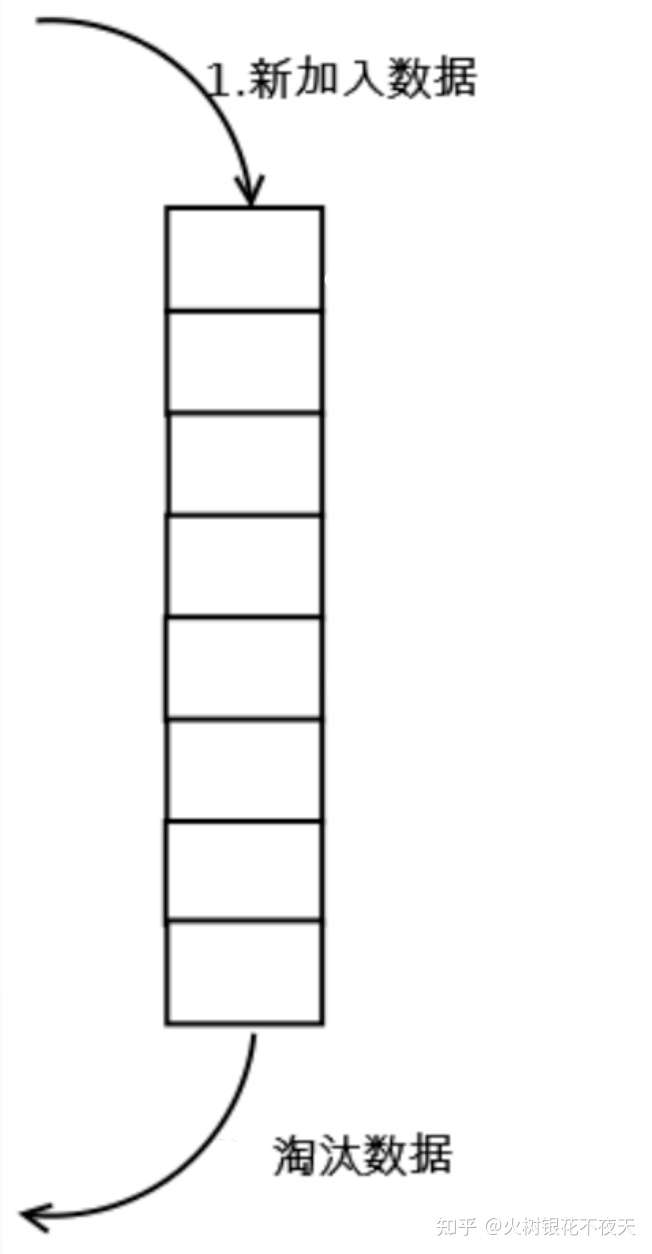
执行过程理解:
- 利用一个双向链表保存数据,
- 当来了新的数据之后便添加到链表末尾,
- 如果Cache存满数据,则把链表头部数据删除,
- 然后把新的数据添加到链表末尾。
- 在访问数据的时候,如果存在该数据的话,则返回对应的value值;
存在的问题:
这种绝对的公平方式容易导致效率的降低。例如,如果最先加载进来的页面是经常被访问的页面,这样做很可能造成常被访问的页面替换到磁盘上,导致很快就需要再次发生缺页中断,从而降低效率。
2Q(Two queues)
做法:有两个缓存队列,一个是FIFO队列,一个是LRU队列。当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
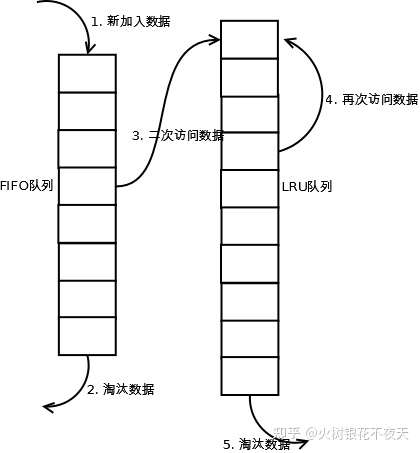
执行过程理解:
- 新访问的数据插入到FIFO队列;
- 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
- 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
- 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
- LRU队列淘汰末尾的数据。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
2020-02-11 TCP连接三次握手