
KeepAlive
什么是KeepAlive?
首先,我们要明确我们谈的是TCP的 KeepAlive 还是HTTP的 Keep-Alive。TCP的KeepAlive和HTTP的Keep-Alive是完全不同的概念,不能混为一谈。实际上HTTP的KeepAlive写法是Keep-Alive,跟TCP的KeepAlive写法上也有不同。
-
TCP的keepalive是侧重在保持客户端和服务端的连接,一方会不定期发送心跳包给另一方,当一方端掉的时候,没有断掉的定时发送几次心跳包,如果间隔发送几次,对方都返回的是RST,而不是ACK,那么就释放当前链接。设想一下,如果tcp层没有keepalive的机制,一旦一方断开连接却没有发送FIN给另外一方的话,那么另外一方会一直以为这个连接还是存活的,几天,几月。那么这对服务器资源的影响是很大的。
-
HTTP的keep-alive一般我们都会带上中间的横杠,普通的http连接是客户端连接上服务端,然后结束请求后,由客户端或者服务端进行http连接的关闭。下次再发送请求的时候,客户端再发起一个连接,传送数据,关闭连接。这么个流程反复。但是一旦客户端发送connection:keep-alive头给服务端,且服务端也接受这个keep-alive的话,两边对上暗号,这个连接就可以复用了,一个http处理完之后,另外一个http数据直接从这个连接走了。减少新建和断开TCP连接的消耗。
二者的作用简单来说:
HTTP协议的Keep-Alive意图在于短时间内连接复用,希望可以短时间内在同一个连接上进行多次请求/响应。
TCP的KeepAlive机制意图在于保活、心跳,检测连接错误。当一个TCP连接两端长时间没有数据传输时(通常默认配置是2小时),发送keepalive探针,探测链接是否存活。
总之,记住HTTP的Keep-Alive和TCP的KeepAlive不是一回事。
tcp的keepalive是在ESTABLISH状态的时候,双方如何检测连接的可用行。而http的keep-alive说的是如何避免进行重复的TCP三次握手和四次挥手的环节。
TCP的KeepAlive
1.为什么要有KeepAlive?
在谈KeepAlive之前,我们先来了解下简单TCP知识(知识很简单,高手直接忽略)。首先要明确的是在TCP层是没有“请求”一说的,经常听到在TCP层发送一个请求,这种说法是错误的。
TCP是一种通信的方式,“请求”一词是事务上的概念,HTTP协议是一种事务协议,如果说发送一个HTTP请求,这种说法就没有问题。也经常听到面试官反馈有些面试运维的同学,基本的TCP三次握手的概念不清楚,面试官问TCP是如何建立链接,面试者上来就说,假如我是客户端我发送一个请求给服务端,服务端发送一个请求给我。。。
这种一听就知道对TCP基本概念不清楚。下面是我通过wireshark抓取的一个TCP建立握手的过程。(命令行基本上用TCPdump,后面我们还会用这张图说明问题):

现在我看只要看前3行,这就是TCP三次握手的完整建立过程,第一个报文SYN从发起方发出,第二个报文SYN,ACK是从被连接方发出,第三个报文ACK确认对方的SYN,ACK已经收到,如下图:

但是数据实际上并没有传输,请求是有数据的,第四个报文才是数据传输开始的过程,细心的读者应该能够发现wireshark把第四个报文解析成HTTP协议,HTTP协议的GET方法和URI也解析出来,所以说TCP层是没有请求的概念,HTTP协议是事务性协议才有请求的概念,TCP报文承载HTTP协议的请求(Request)和响应(Response)。
现在才是开始说明为什么要有KeepAlive。链接建立之后,如果应用程序或者上层协议一直不发送数据,或者隔很长时间才发送一次数据,当链接很久没有数据报文传输时如何去确定对方还在线,到底是掉线了还是确实没有数据传输,链接还需不需要保持,这种情况在TCP协议设计中是需要考虑到的。
TCP协议通过一种巧妙的方式去解决这个问题,当超过一段时间之后,TCP自动发送一个数据为空的报文给对方,如果对方回应了这个报文,说明对方还在线,链接可以继续保持,如果对方没有报文返回,并且重试了多次之后则认为链接丢失,没有必要保持链接。
2.怎么开启KeepAlive?
KeepAlive并不是默认开启的,在Linux系统上没有一个全局的选项去开启TCP的KeepAlive。需要开启KeepAlive的应用必须在TCP的socket中单独开启。Linux Kernel有三个选项影响到KeepAlive的行为:
- tcp_keepalive_time 7200// 距离上次传送数据多少时间未收到新报文判断为开始检测,单位秒,默认7200s
- tcp_keepalive_intvl 75// 检测开始每多少时间发送心跳包,单位秒,默认75s
- tcp_keepalive_probes 9// 发送几次心跳包对方未响应则close连接,默认9次
TCP socket也有三个选项和内核对应,通过setsockopt系统调用针对单独的socket进行设置:
- TCPKEEPCNT: 覆盖 tcpkeepaliveprobes
- TCPKEEPIDLE: 覆盖 tcpkeepalivetime
- TCPKEEPINTVL: 覆盖 tcpkeepalive_intvl
举个例子,以我的系统默认设置为例,kernel默认设置的tcpkeepalivetime是7200s, 如果我在应用程序中针对socket开启了KeepAlive,然后设置的TCP_KEEPIDLE为60,那么TCP协议栈在发现TCP链接空闲了60s没有数据传输的时候就会发送第一个探测报文。
3. 需要注意,KeepAlive的不足和局限性
其实,tcp自带的keepalive还是有些不足之处的。
keepalive只能检测连接是否存活,不能检测连接是否可用。例如,某一方发生了死锁,无法在连接上进行任何读写操作,但是操作系统仍然可以响应网络层keepalive包。
TCP keepalive 机制依赖于操作系统的实现,灵活性不够,默认关闭,且默认的 keepalive 心跳时间是 两个小时, 时间较长。
代理(如socks proxy)、或者负载均衡器,会让tcp keep-alive失效
基于此,我们旺旺需要加上应用层的心跳。这个需要自己实现,这里就不展开了。
HTTP的Keep-Alive
1. HTTP为什么需要Keep-Alive?
通常一个网页可能会有很多组成部分,除了文本内容,还会有诸如:js、css、图片等静态资源,有时还会异步发起AJAX请求。只有所有的资源都加载完毕后,我们看到网页完整的内容。然而,一个网页中,可能引入了几十个js、css文件,上百张图片,如果每请求一个资源,就创建一个连接,然后关闭,代价实在太大了。
基于此背景,我们希望连接能够在短时间内得到复用,在加载同一个网页中的内容时,尽量的复用连接,这就是HTTP协议中keep-alive属性的作用。
- HTTP的Keep-Alive是HTTP1.1中默认开启的功能。通过headers设置"Connection: close "关闭
- 在HTTP1.0中是默认关闭的。通过headers设置"Connection: Keep-Alive"开启。
对于客户端来说,不论是浏览器,还是手机App,或者我们直接在Java代码中使用HttpUrlConnection,只是负责在请求头中设置Keep-Alive。Keep-Alive属性保持连接的时间长短是由服务端决定的,通常配置都是在几十秒左右。
TCP连接建立之后,HTTP协议使用TCP传输HTTP协议的请求(Request)和响应(Response)数据,一次完整的HTTP事务如下图:
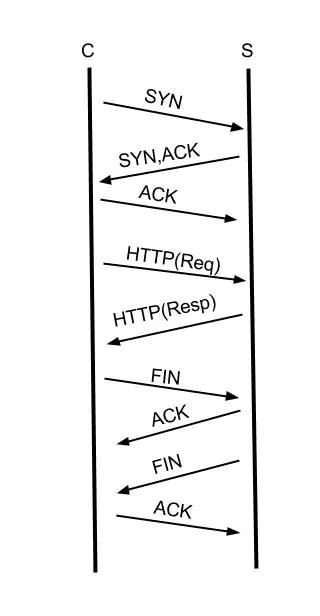
这张图我简化了HTTP(Req)和HTTP(Resp),实际上的请求和响应需要多个TCP报文。
从图中可以发现一个完整的HTTP事务,有链接的建立,请求的发送,响应接收,断开链接这四个过程,早期通过HTTP协议传输的数据以文本为主,一个请求可能就把所有要返回的数据取到,但是,现在要展现一张完整的页面需要很多个请求才能完成,如图片.JS.CSS等,如果每一个HTTP请求都需要新建并断开一个TCP,这个开销是完全没有必要的。
开启HTTP Keep-Alive之后,能复用已有的TCP链接,当前一个请求已经响应完毕,服务器端没有立即关闭TCP链接,而是等待一段时间接收浏览器端可能发送过来的第二个请求,通常浏览器在第一个请求返回之后会立即发送第二个请求,如果某一时刻只能有一个链接,同一个TCP链接处理的请求越多,开启KeepAlive能节省的TCP建立和关闭的消耗就越多。
当然通常会启用多个链接去从服务器器上请求资源,但是开启了Keep-Alive之后,仍然能加快资源的加载速度。HTTP/1.1之后默认开启Keep-Alive, 在HTTP的头域中增加Connection选项。当设置为Connection:keep-alive表示开启,设置为Connection:close表示关闭。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2015-01-12 jQuery修改css属性
2015-01-12 cssText