TCP、UDP
概念
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
应用
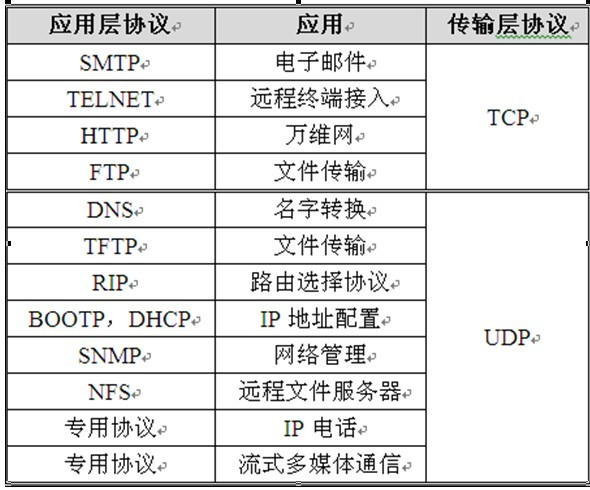
下图是TCP和UDP协议的一些应用。
区别

这里再详细说一下面向连接和面向无连接的区别:
- 面向连接举例:两个人之间通过电话进行通信;
- 面向无连接举例:邮政服务,用户把信函放在邮件中期待邮政处理流程来传递邮政包裹。显然,不可达代表不可靠。
从程序实现的角度来看,可以用下图来进行描述。

从上图也能清晰的看出,TCP通信需要服务器端侦听listen、接收客户端连接请求accept,等待客户端connect建立连接后才能进行数据包的收发(recv/send)工作。而UDP则服务器和客户端的概念不明显,服务器端即接收端需要绑定端口,等待客户端的数据的到来。后续便可以进行数据的收发(recvfrom/sendto)工作。
报文边界
在前面讲解UDP时,提到了UDP保留了报文的边界,下面我们来谈谈TCP和UDP中报文的边界问题。在默认的阻塞模式下,TCP无边界,UDP有边界。
对于TCP协议,客户端连续发送数据,只要服务端的这个函数的缓冲区足够大,会一次性接收过来,即客户端是分好几次发过来,是有边界的,而服务端却一次性接收过来,所以证明是无边界的;而对于UDP协议,客户端连续发送数据,即使服务端的这个函数的缓冲区足够大,也只会一次一次的接收,发送多少次接收多少次,即客户端分几次发送过来,服务端就必须按几次接收,从而证明,这种UDP的通讯模式是有边界的。
TCP无边界,造成对采用TCP协议发送的数据进行接收比较麻烦,在接收的时候易出现粘包,即发送方发送的若干包数据到接收方接收时粘成一包。由于TCP是流协议,对于一个socket的包,如发送 10AAAAABBBBB两次,由于网络原因第一次又分成两次发送, 10AAAAAB和BBBB,如果接包的时候先读取10(包长度)再读入后续数据,当接收得快,发送的慢时,就会出现先接收了 10AAAAAB,会解释错误 ,再接到BBBB10AAAAABBBBB,也解释错误的情况。这就是TCP的粘包。
在网络传输应用中,通常需要在网络协议之上再自定义一个协议封装一下,简单做法就是在要发送的数据前面再加一个自定义的包头,包头中可以包含数据长度和其它一些信息,接收的时候先收包头,再根据包头中描述的数据长度来接收后面的数据。详细做法是:先接收包头,在包头里指定包体长度来接收。设置包头包尾的检查位( 比如以0xAA开头,0xCC结束来检查一个包是否完整)。对于TCP来说:
- 不存在丢包,错包,所以不会出现数据出错
- 如果包头检测错误,即为非法或者请求,直接重置即可
为了避免粘包现象,可采取以下几种措施。
- 对于发送方引起的粘包现象,用户可通过编程设置来避免,TCP提供了强制数据立即传送的操作指令push,TCP软件收到该操作指令后,就立即将本段数据发送出去,而不必等待发送缓冲区满;
- 对于接收方引起的粘包,则可通过优化程序设计、精简接收进程工作量、提高接收进程优先级等措施,使其及时接收数据,从而尽量避免出现粘包现象;
- 由接收方控制,将一包数据按结构字段,人为控制分多次接收,然后合并,通过这种手段来避免粘包。
分段
MTU,Maximum Transmission Unit(最大传输单元),是链路层中的网络对数据帧的一个限制,以以太网为例,MTU为1500个字节。一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
MSS,Maximum Segment Size(最大分段大小),是TCP里的一个概念(首部的选项字段中)。MSS是TCP数据包每次能够传输的最大数据分段,TCP报文段的长度大于MSS时,要进行分段传输。TCP协议在建立连接的时候通常要协商双方的MSS值,每一方都有用于通告它期望接收的MSS选项(MSS选项只出现在SYN报文段中,即TCP三次握手的前两次)。MSS的值一般为MTU值减去两个首部大小(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes),所以如果用链路层以太网,MSS的值往往为1460。而Internet上标准的MTU(最小的MTU,链路层网络为x2.5时)为576,那么如果不设置,则MSS的默认值就为536个字节。很多时候,MSS的值最好取512的倍数。TCP报文段的分段与重组是在运输层完成的。
MSS=MTU-20字节TCP报头-20字节IP报头,那么在以太网环境下,MSS值一般就是1500-20-20=1460字节。当然,也可以由发收双方来决定。
TCP分段的原因是MSS,IP分片的原因是MTU,由于一直有MSS<=MTU,很明显,分段后的每一段TCP报文段再加上IP首部后的长度不可能超过MTU,因此也就不需要在网络层进行IP分片了,因此TCP报文段很少会发生IP分片的情况。再来看UDP数据报,由于UDP数据报不会自己进行分段,因此当长度超过了MTU时,会在网络层进行IP分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
总结:UDP不会分段,就由IP来分。TCP会分段,不用IP来分。
MTU为1500字节的原因
当时以太网在所有系统之间共享同一同轴电缆,或者使用以太网集线器,后者一次只能允许一个数据包在以太网网段的所有成员之间传输。因此必须选择一个合适的数值,这样在共享网络段(有时很忙)上的传输等待时间不会太久,而且数据包头的开销也不会太大。太小的话,传输效率比较低,因此工程师最终选择了1500 字节(约 12000 bit)作为最佳“安全”值。
假如带宽是 100Mbps 的话,(1500 * 8) / (100 * 1024 * 1024) * 1000 = 0.11 ms。如果很大,则传输时间必定很长。
如果一次传送太大量的数据,一旦该数据中有一小部分被干扰,那么接收方的数据校验算法由于无法判断具体是哪里产生了错误以及如何修复错误,所以只能将这份数据全部丢弃,并通知发送方重传,这极度浪费了网络带宽资源。
还有,如果一份数据太大,则接收方必须将该数据全部接收完之后,才会通知上游程序“有新数据到了请来处理”,这个延迟太大了,如果能将数据切片,一小片一小片传递,那么接收方的处理程序可以更快的拿到数据。正常来说,程序是要拿到完整的数据包才能处理,但是程序可以经过设计,即使数据本身并不完整,但可以跟着一点一点的处理数据,这样,形成类似流水线的过程,反而能够增加最终的数据处理速度。
缓冲区
应用程序可通过调用send(write, sendmsg等)利用tcp socket向网络发送应用数据,而tcp/ip协议栈再通过网络设备接口把tcp数据报真正发送到网络上。应用程序调用send接口,接口返回成功就默认发送了,但由于应用程序调用send的速度跟网络介质发送数据的速度存在差异,所以,一部分应用数据被组织成tcp数据报之后,会缓存在tcp socket的发送缓存队列中,等待网络空闲时再发送出去。同时,tcp协议要求对端在收到tcp数据报后,要对其序号进行ACK,只有当收到一个tcp数据报的ACK之后,才可以把这个tcp数据报从socket的发送缓冲队列中清除。
在非阻塞模式下,一般是用setsockopt函数设置发送阻塞的时间,然后调用send()发送数据。当超出这个时间,send函数会返回已发送的数据大小, 但是请注意此时缓存中可能还有些数据没有发送到网络上。那么当在应用层再一次调用send函数时,就会报告经典的错误:Resource temporarily unavailable。那么如果是阻塞情况,send函数会一直等到所有应用层的数据全部发送完毕再返回。
UDP的报文若超过发送缓冲区,则直接报错。
TCP的发送缓冲区为:缺省是512 KB,最大是16M
TCP的接收缓冲区为:缺省是128 KB,最大是8M
UDP的发送缓冲区为:缺省是256 KB,最大是8M
UDP的接收缓冲区为:缺省是128 KB,最大是8M
这些值可以通过设置文件来实现:/proc/sys/net/core/rmem_max 等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号