
Golang 协程调度
一、线程模型
- N:1模型,N个用户空间线程在1个内核空间线程上运行。优势是上下文切换非常快但是无法利用多核系统的优点。
- 1:1模型,1个内核空间线程运行一个用户空间线程。这种充分利用了多核系统的优势但是上下文切换非常慢,因为每一次调度都会在用户态和内核态之间切换。(POSIX线程模型(pthread),Java)
- M:N模型, 每个用户线程对应多个内核空间线程,同时也可以一个内核空间线程对应多个用户空间线程。Go打算采用这种模型,使用任意个内核模型管理任意个goroutine。这样结合了以上两种模型的优点,但缺点就是调度的复杂性。
下面看看golang的协程调度
- M:一个用户空间线程,同时对应一个内核线程,类似posix pthread
- P:代表运行的上下文环境, 也就是我们上一节实现的调度器,一个调度器也会对应一个就绪队列
- G:goroutine,即协程
二、调度模型简介
groutine能拥有强大的并发实现是通过GPM调度模型实现,下面就来解释下goroutine的调度模型。
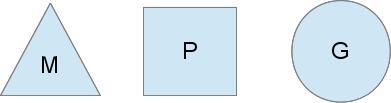
Go的调度器内部有三个重要的结构:M,P,G
M:M是对内核级线程的封装,数量对应真实的CPU数,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息
G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
P:P全称是Processor,处理器,它的主要用途就是用来执行goroutine的。每个Processor对象都拥有一个LRQ(Local Run Queue),未分配的Goroutine对象保存在GRQ(Global Run Queue )中,等待分配给某一个P的LRQ中,每个LRQ里面包含若干个用户创建的Goroutine对象。
M:M是对内核级线程的封装,数量对应真实的CPU数,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息
G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
P:P全称是Processor,处理器,它的主要用途就是用来执行goroutine的。每个Processor对象都拥有一个LRQ(Local Run Queue),未分配的Goroutine对象保存在GRQ(Global Run Queue )中,等待分配给某一个P的LRQ中,每个LRQ里面包含若干个用户创建的Goroutine对象。
Golang采用的是多线程模型,更详细的说他是一个两级线程模型,但它对系统线程(内核级线程)进行了封装,暴露了一个轻量级的协程goroutine(用户级线程)供用户使用,而用户级线程到内核级线程的调度由golang的runtime负责,调度逻辑对外透明。goroutine的优势在于上下文切换在完全用户态进行,无需像线程一样频繁在用户态与内核态之间切换,节约了资源消耗。
调度实现
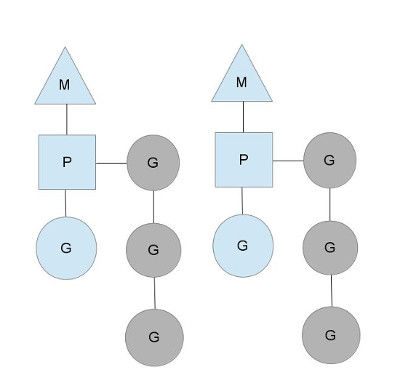
从上图中看,有2个物理线程M,每一个M都拥有一个处理器P,每一个也都有一个正在运行的goroutine。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),
Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个
goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),
Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个
goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
当一个OS线程M0陷入阻塞时(如下图),P转而在运行M1,图中的M1可能是正被创建,或者从线程缓存中取出。
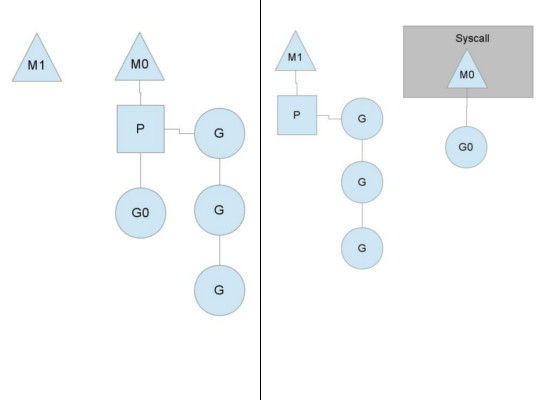
当MO返回时,它必须尝试取得一个P来运行goroutine,一般情况下,它会从其他的OS线程那里拿一个P过来,
如果没有拿到的话,它就把goroutine放在一个global runqueue里,然后自己睡眠(放入线程缓存里)。所有的P也会周期性的检查global runqueue并运行其中的goroutine,否则global runqueue上的goroutine永远无法执行。
如果没有拿到的话,它就把goroutine放在一个global runqueue里,然后自己睡眠(放入线程缓存里)。所有的P也会周期性的检查global runqueue并运行其中的goroutine,否则global runqueue上的goroutine永远无法执行。
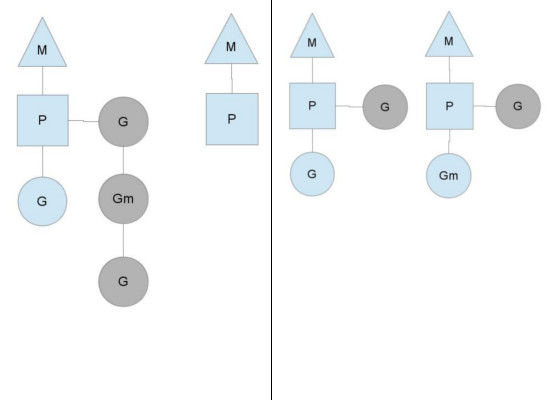
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了这个处理器P很忙,但是其他的P还有任务,此时如果global
runqueue没有任务G了,那么P不得不从其他的P里拿一些G来执行。一般来说,如果P从其他的P那里要拿任务的话,一般就拿run
queue的一半,这就确保了每个OS线程都能充分的使用,如下图:
三、GPM创建相关问题
M和P的数量如何确定?或者说何时会创建M和P?
1、P的数量:
- 由启动时环境变量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定(默认是1)。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个goroutine在同时运行。
2、M的数量:
- go语言本身的限制:go程序启动时,会设置M的最大数量,默认10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。
- runtime/debug中的SetMaxThreads函数,设置M的最大数量
- 一个M阻塞了,会创建新的M。
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
3、P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
4、M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
M选择哪一个P关联?
- M会选择导致此M被创建的那个P关联。
什么时候会切换P与M的关联关系?
当M因系统调用而阻塞时(M上运行的G进入了系统调用的时候),M与P会分开,如果此时P的就绪队列中还有任务,
P就会去关联一个空闲的M,或者创建一个M进行关联。(也就是说go不是像libtask一样处理IO阻塞的?不确定。)
就绪的G如何选择进入哪个P的就绪队列?
- 默认情况下:因为P的默认数量是1(M不一定是1),所以如果我们不改变GOMAXPROCS,无论我们在程序中用go语句创建多少个goroutine,它们都只会被塞入同一个P的就绪队列中。
- 有多个P的情况下:如果修改了GOMAXPROCS或者调用了runtime.GOMAXPROCS,运行时系统会把所有的G均匀的分布在各个P的就绪队列中。
如何保证每个P的就绪队列中都会有G
如果一个P的就绪队列所有任务都执行完了,那么P会尝试从其他P的就绪队列中取出一部分到自己的就绪队列中,以保证每个P的就绪队列都有任务可以执行。
you are the best!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号