
Tesseract算法研究
https://github.com/tesseract-ocr/tesseract/wiki github上的资料。
https://blog.csdn.net/guzhenping/article/details/51023687 关于tesseract的博客。
An Over view of theTesseract OCR Engine论文的个人理解
概述
字符轮廓形成blobs(博主认为可能是指连通域),blobs被识别为文本行,文本行和区域将用于分析固定间隔或者成比例的间隔。文本行根据字符间隔分为不同的字符,固定间隔将迅速分割字符,比例间隔使用确定间隔和模糊间隔分割字符。识别分为两次过程进行。 在第一遍中,尝试依次识别每个单词。 识别效果好的单词都将作为训练数据传递给自适应分类器。 然后,自适应分类器将有机会更准确地识别页面下方的文本。由于自适应分类器进行了学习,进行第二次识别可能识别出原本难以识别的字符。最后,解析模糊间隔,以及检查x-height假设来确定小写字母。
总体流程:
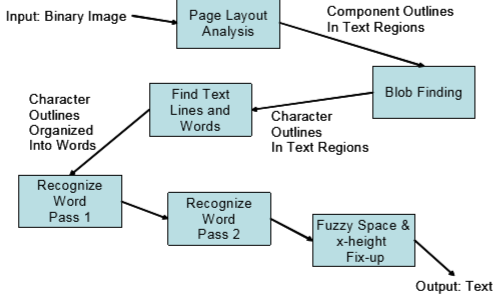
寻找行
行寻找算法已经公布https://www.hpl.hp.com/techreports/94/HPL-94-113.pdf,倾斜检查的一般方法是通过将霍夫变换应用于图像的部分区域简化地检查倾斜,或者是寻找平行于文本行基线的像素点集,进行不同角度的投影,选择投影最高峰的方向为倾斜方向。
此算法如下:
连通分量分析,连通域称为blob(个人推测),blob的尺寸和位置表示为外框坐标。
过滤blob,选择blob集合,这个集合可能代表着正文。精度不是非常重要,主要是过滤首字下沉,下划线和孤立的噪声。统计最多的高度、宽度作为参考,高度不足的blob会被删除,保留高度、宽度在一定范围内的blob。
根据blob外框左边界的x坐标排序,这种排序可以随着页面倾斜,确保blob不会被放进错误的行里。寻找与blob相交最多的已存在的行,如果不存在,则放入第一个blob,后续添加新的blob扩展行的上下界限制,根据blob的下界更新平均y的偏移。
(个人理解是利用排序后的连通域,根据上下界进行限制,连通域边界变化和页面倾斜相关,比较固定,可任意保证多数连通域分配在准确的行内,再根据分配后的连通域外框坐标拟合直线。)
拟合基线,对已经分配好的blob,使用least median of squares(最小二乘法?)拟合基线。
关键点在于blob的干扰过滤以及文本行构造。
行寻找可以识别倾斜的页面而不必进行倾斜校正,保证了图像质量。假设页面布局分析已经提供了大致相同的文本大小的文本区域,根据文本行高度,可以滤除高度不足的干扰信息。过滤后的blob更适合用于拟合不重叠、平行、可能倾斜的线模型。通过x坐标的排序和处理,可以将blob分配给不同的文本行,结合页面的斜率可以大大减少在存在倾斜的情况下分配给错误文本行的危险。将过滤干扰后的blob分配给文本行后,用least median of squares(最小二乘法?) 拟合基线,将过滤会后的blob重新拟合回合适的行。最后,将水平重叠至少一半的blob合并,把标点和正确的基线放在一起,将分裂的字符部分合并。
拟合基线
找到文本行后,将使用二次样条曲线更精确地拟合基线。 这是OCR系统的又一个先河,它使Tesseract能够处理具有弯曲基线的页面。将blob划分为几组来拟合基线,并为原始基线合理地连续位移。通过最小二乘法用二次样条拟合到最密集的区域。
带有基线,下降线,中间线和上升线的文本行示例,线都是平行的(y间隔在整行中为常量,可能有略微弯曲)。
固定间隔和比例间隔
在文本行中寻找固定间隔,使用固定间隔可以快速分割为字符。非固定间隔时,在基线和中间线之间的有限垂直范围内测量间隔,在此阶段使接近固定间隔阈值的空间变得模糊,以便可以在单词识别后做出最终决定。
识别
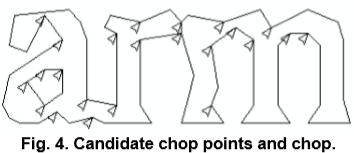
黏连字符(图4),通过多边形近似的顶点作为候选分割点,利用识别的置信度来判别。误分割字符,当候选分割点都使用后结果仍然不佳,则进行拼接。拼接时,进行搜索优先级队列,对未识别的组合进行识别来评估。利用先分割后拼接的方案简化对分割字符段维护的数据结构。
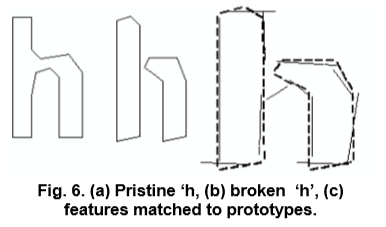
未知的特征不必和训练库中的完全一致,在训练过程中,使用多边形近似的线段作为特征,但是在识别中,从轮廓中提取了固定长度较小(以标准化单位)的特征,并将其与聚类的原型特征进行多对一匹配 训练数据。短而粗的线是从未知中提取的,长而细的线是通过多边形近似聚集的段,作为原型(图6)。分割字符的特征和完整字符的特征是不匹配的,但是将完整字符特征分为小部分的特征是非常匹配的。这说明通过小特征匹配能够解决误分割字符的情况。唯一的问题是,计算位置特征和原型之间的距离的计算代价是很高的。未知提取的特征用三维向量表示(x, y, angle),多边形拟合的原型用四维向量表示(x, y , angle, length)。多边形的长特征被分解成等长的较短片段,因此长度从特征向量中消除了,这在识别破损字符时增加了适应性。
特征距离:
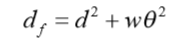
d是x,y坐标距离,θ是角度差。
相似性证据:
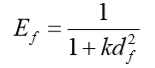
常量k决定减小的速度。
当提取特征和原型匹配时,将Ef复制为Ep,这些和通过特征的数量Nf和原型长度的总和Lp归一化,结果转换为反向距离:
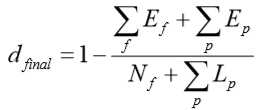
分类
分类分为两个过程。首先,使用局部敏感哈希查找表(LSH)(解决像汉字这类大字符集数据问题),创建一个特征分类列表,未知特征可能会匹配。从一个粗量化的三维查找表中提取每个特征,对所有匹配位向量求和,和最高的特征(即最匹配的)作为下一步的列表。每个未知特征和可能匹配的原型特征进行位向量比较,计算他们之间的相似度。每个原型被表示为合理的乘积和(a logical sum-of-product expression),相似度计算排序了匹配的原型特征。距离计算过程会记录每个特征以及每个原型中的总体相似性证据。最佳的综合相似度,汇总了特征和相似性证据。
语言分析
选择下列分类中最好的结果,最频繁字,字典,数字,大写字母,小写字母,分类选择字。最终的结果是选择最小距离评分,虽然每个类乘上不同的常量。字符不同的分割可能得到不同的结果,即使有概率也很难直接比较这些字符。为每个字符分类生成两个数字,第一个是置信度,是减去归一化原型的距离得来的。第二个是评分,通过归一化原型的距离乘上字符轮廓长度,因为一个字符的轮廓长度总是不变的。基线/x-height归一化,可以防止偏高、偏低以及噪点干扰。字符矩形归一化的主要好处是可以消除不同字体的宽高比和笔画宽度影响。
自适应分类器
使用静态分类器必须概况所有情况,因此对于字符、非字符的区分能力会下降。因此,通常使用静态分类器识别出来的字符训练更有区分能力的自适应分类器。自适应分类器和静态分类器的显著不同在于,使用的归一化方法不同。自适应分类器使用各向同性基线/ x-height归一化,静态分类器通过质心(一阶矩)对字符位置和二阶矩对尺寸进行归一化。基线/ x-height归一化对大小写字母有较好的区分度,可以抗噪声,矩归一化的优点是消除了字符宽高比和笔画粗细的不同。
看完这篇概述,主要的启发还是倾斜检测的想法,利用连通域来分析拟合基线,还有大字符集利用了局部敏感哈希查找,选择出近似的小字符集后再细化比较特征(牺牲精度和空间选择出范围,再从细颗粒度作区分)。分割部分的黏连分割和拼接没有详细的说明,也不是很理解具体是怎么实现的,大概是结合了识别置信度来选择最佳分割点,还有固定间隔和比例间隔的判断依据是什么。识别部分分类器的训练方式以及长特征和短特征的匹配方式也不是特别理解。
转载请注明出处。
图像的矩归一化的相关说明。

参考资料:
https://blog.csdn.net/guzhenping/article/details/51023687 关于tesseract的博客。
https://blog.csdn.net/gdfsg/article/details/51015066图像矩。
An Over view of theTesseract OCR Engine 论文。
Adapting the Tesseract Open Source OCR Engine for Multilingual OCR 论文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号