一些网络流算法
对于一类数据范围较小的 规划 / 分配 / 调整求最值问题,可以考虑建图用网络流处理。
可以和优化建图等手段一起使用。
memset 的时候要 注意范围(点的个数)。
概念
- 流网络:一个包含点集和边集的有向图 \(G= (V, E)\),边 \((u, v)\) 有其属性 \(c(u, v)\),称为容量。图中有两个特殊顶点源点 \(s\) 和汇点 \(t\)。
- 净流:边 \((u, v)\) 的净流为 \((u, v)\) 的实际流减去 \((v, u)\) 的实际流。
- 可行流:记 \(f(u, v)\) 为边 \((u, v)\) 的净流,满足以下条件的流称为可行流:
- 容量限制:\(0 \leq f(u, v) \leq c(u, v)\)
- 流守恒:除 \(u = s\) 和 \(u = t\) 的情况外,\(\sum\limits_{x \in V} f(u, x) = \sum\limits_{x \in V} f(x, t)\)
- 流量值:令 \(f\) 为一个方案,表示每条边的取值。对于某一可行流而言,其流量值用 \(|f|\) 表示。\(|f| = \sum\limits_{(s, v) \in E} f(s, v) - \sum\limits_{(v, s) \in E} f(v, s)\)
- 残量网络(残留网络):残量网络总是针对原图中某一可行流而言,因此残量网络可以视作可行流的一个函数,通常记为 \(G_f = (V_f, E_f)\),其中 \(V_f = V\),\(E_f\) 为 \(E\) 和 \(E\) 的所有反向边。残量网络中的流量记为 \(c^{\prime}(u, v)\),定义为
- 最大流(最大可行流):图中流量值最大的可行流。
- 增广路径:残量网络中从源点 \(s\) 到汇点 \(t\) 的简单路径。
- 割:网络中顶点的一种划分,把所有顶点划分成两个顶点集合 \(S\) 和 \(T\),满足 \(s \in S, t \in T\),且 \(S \cup T = V, S \cap T = \emptyset\),记为割 \((S, T)\)
- 割的容量:定义割 \((S, T)\) 的容量 \(c(S, T) = \sum\limits_{u \in S, v \in T} c(u, v)\),也可以用 \(c(s, t)\) 表示。
- 最小割:图中容量最小的割。
最大流
求最大流可以用 \(\texttt{Edmonds-Karp, Dinic, ISAP, HLPP}\) 等算法。
\(\tt Edmonds-Karp\)
即 \(\tt EK\) 算法。
\(EK\) 算法的主要思路是在原图的残量网络中不断找增广路,直到原图中不存在增广路为止。
每次找到一条增广路,假设该增广路上最小的剩余容量为 \(k\),则源点通过该增广路流出 \(k\) 个单位的流量到汇点。不妨存图时直接将每条边的剩余容量存下,增广时直接将增广路上的边权减去 \(k\) 即可。
直接在原图中找增广路会导致结果不是最大流,原因是找增广路时可能会先遍历到较劣方案,而减去边权会对残量网络造成影响。解决方法是在原图中添加初始容量为 \(0\) 的反向边,每次增广时将增广路径上每条边的反向边剩余容量加上 \(k\)。
以下图为例,源点为 \(1\),汇点为 \(4\),尝试模拟 \(\tt EK\) 算法。
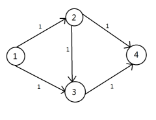
最坏情况下会找到增广路 \(1, 2, 3, 4\),增加流量 \(1\):
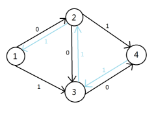
如果没有反向边,此时已经无法找到增广路,得到最大流为 \(1\),实际上该图最大流为 \(2\)。加入反向边后,发现增广路 \(1, 3, 2, 4\),增加流量 \(1\):
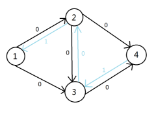
此时残量网络中无增广路,算法结束,得到最大流为 \(2\)
图中的反向边起到反悔作用。当选择第一条增广路后,我们发现实际上有更优的做法。所以通过 \(3 \rightarrow 2\) 这条反向边将 \(1\) 个单位流量退回给顶点 \(2\),由 \(1, 2, 4\) 这条增广路接管 \(1\) 个单位流量。同时原本边 \(3, 4\) 的流量贡献给了增广路 \(1, 3, 4\),成功将原本的较劣方案替换为最优方案。边权不为 \(1\)、顶点个数增加的情况同理。
\(\tt EK\) 算法的时间复杂度为 \(\mathcal{O}(m^2n)\),但一般跑不到这个上界
#include <cstdio>
#include <cstring>
#include <queue>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 205;
const int maxm = 1e4 + 5;
const ll inf = 1e18;
struct node {
int to, nxt;
ll w;
} edge[maxm];
int n, m, s, t;
int cnt = 1;
int head[maxn], pre[maxn];
ll ans;
ll dis[maxn];
ll val[maxn][maxn];
bool vis[maxn];
void add_edge(int u, int v, ll w) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
head[u] = cnt;
}
bool bfs() {
queue<int> q;
memset(vis, false, (n + 1) * sizeof(bool));
vis[s] = true;
dis[s] = inf;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((edge[i].w == 0) || vis[v]) {
continue;
}
dis[v] = min(dis[u], edge[i].w);
pre[v] = i;
if (v == t) {
return true;
}
vis[v] = true;
q.push(v);
}
}
return false;
}
void update() {
int cur = t;
while (cur != s) {
edge[pre[cur]].w -= dis[t];
edge[pre[cur] ^ 1].w += dis[t];
cur = edge[pre[cur] ^ 1].to;
}
ans += dis[t];
}
int main() {
int u, v;
ll w;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%lld", &u, &v, &w);
val[u][v] += w;
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (val[i][j]) {
add_edge(i, j, val[i][j]);
add_edge(j, i, 0);
}
}
}
while (bfs()) {
update();
}
printf("%lld\n", ans);
return 0;
}
\(\tt Dinic\)
\(\tt Dinic\) 算法是 \(\tt EK\) 算法的优化。
我们发现 \(\tt EK\) 算法每次可能会遍历整个残量网络,但只能找出一条增广路。这种单路增广的方式效率低下,因此考虑用多路增广优化。
前置知识:分层图
这里的分层图不是将原图复制成若干份,而是将原图划分成若干个层次。
令 \(d_u\) 为起点 \(s\) 到达顶点 \(u\) 需要经过的最少边数,表示该点的层次。由满足 \(d_v = d_u + 1\) 的边构成的子图称为分层图。显然分层图是一个有向无环图。
不妨先在残量网络上进行 \(bfs\),求出每个顶点的层次。然后从源点开始搜索,\(\forall (u, v) \in E_f\),规定只有当 \(d_v = d_u + 1\) 时才能递归到顶点 \(v\) 找增广路,即在残量网络构造的分层图上找增广路。搜索到顶点 \(t\) 时说明找到了增广路,返回到达当前顶点的流量,回溯更新剩余容量。
当前弧优化:显然一条边在搜索结束后不会再次对答案产生影响,因此可以记录下当前顶点访问到的边。下一次访问该顶点直接从这条边开始搜索即可。
时间复杂度 \(\mathcal{O}(n^2m)\)
\(\tt Dinic\) 求二分图最大匹配的时间复杂度是 \(\mathcal{O}(m \sqrt{n})\)
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
typedef long long ll;
const int maxn = 205;
const int maxm = 1e4 + 5;
const ll inf = 1e18;
struct node {
int to, nxt;
ll w;
} edge[maxm];
int n, m, s, t;
int cnt = 1;
int head[maxn], cur[maxn], dep[maxn];
ll ans;
ll val[maxn][maxn];
void add_edge(int u, int v, ll w) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
head[u] = cnt;
}
bool bfs() {
queue<int> q;
memset(dep, 0, (n + 1) * sizeof(int));
dep[s] = 1;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((dep[v] == 0) && (edge[i].w > 0)) {
dep[v] = dep[u] + 1;
q.push(v);
}
}
}
if (dep[t] > 0) {
return true;
}
return false;
}
ll dfs(int u, ll dis) {
if (u == t) {
return dis;
}
for (int &i = cur[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((dep[v] == dep[u] + 1) && (edge[i].w > 0)) {
ll dist = dfs(v, min(dis, edge[i].w));
if (dist > 0) {
edge[i].w -= dist;
edge[i ^ 1].w += dist;
return dist;
}
}
}
return 0;
}
void dinic() {
while (bfs()) {
ll dis;
for (int i = 1; i <= n; i++) {
cur[i] = head[i];
}
while (dis = dfs(s, inf)) {
ans += dis;
}
}
}
int main() {
int u, v;
ll w;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%lld", &u, &v, &w);
val[u][v] += w;
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (val[i][j]) {
add_edge(i, j, val[i][j]);
add_edge(j, i, 0);
}
}
}
dinic();
printf("%lld\n", ans);
return 0;
}
\(\tt ISAP\)
\(\tt ISAP\) 也是优化的 \(\tt Dinic\) 算法,但是与 \(\tt Dinic\) 算法的思路不同。\(\tt Dinic\) 算法选择多路增广优化,而 \(\tt ISAP\) 仍然是单路增广。
类似地,从汇点 \(t\) 出发进行 \(bfs\),构造出原图的分层图。规定只有当 \(d_u = d_v + 1\) 时,才能将 \((u, v)\) 加入增广路。但是这样做可能会导致相邻点的层次相等,所以若当前点 \(u\) 无法继续增广时,尝试将当前顶点的层次抬高 \(1\),使得剩余的流量可以继续被增广。
当源点的层次大于点数时,说明已经无法找到合法的增广路,算法结束。
\(gap\) 优化:令 \(gap_i\) 表示层次为 \(i\) 的顶点个数。令抬高前的层次为 \(k\),若抬高后 \(gap_k = 0\),说明此时顶点可以分成两部分:层次小于 \(k\) 的和层次大于 \(k\) 的。又因为规定的增广条件,所以此时一定无法到达 \(t\),直接结束算法。
同样地,\(\tt ISAP\) 算法可以使用当前弧优化。
#include <cstdio>
#include <cstring>
#include <queue>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 205;
const int maxm = 1e4 + 5;
const ll inf = 1e18;
struct node {
int to, nxt;
ll w;
} edge[maxm];
int n, m, s, t;
int cnt = 1;
int head[maxn], cur[maxn], dep[maxn], gap[maxn];
ll ans;
void add_edge(int u, int v, ll w) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
head[u] = cnt;
}
void bfs() {
queue<int> q;
memset(dep, -1, sizeof(dep));
memset(gap, 0, sizeof(gap));
dep[t] = 0;
gap[0] = 1;
q.push(t);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (dep[v] == -1) {
dep[v] = dep[u] + 1;
gap[dep[v]]++;
q.push(v);
}
}
}
}
ll dfs(int u, ll flow) {
if (u == t) {
ans += flow;
return flow;
}
ll used = 0;
for (int &i = cur[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (edge[i].w && (dep[v] + 1 == dep[u])) {
ll val = dfs(v, min(flow - used, edge[i].w));
if (val) {
edge[i].w -= val;
edge[i ^ 1].w += val;
used += val;
}
if (used == flow) {
return flow;
}
}
}
gap[dep[u]]--;
if (!gap[dep[u]]) {
dep[s] = n + 1;
}
dep[u]++;
gap[dep[u]]++;
return used;
}
void isap() {
bfs();
while (dep[s] < n) {
memcpy(cur, head, (n + 1) * sizeof(int));
dfs(s, inf);
}
}
int main() {
int u, v;
ll w;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%lld", &u, &v, &w);
add_edge(u, v, w);
add_edge(v, u, 0);
}
isap();
printf("%lld\n", ans);
return 0;
}
\(\tt HLPP\)
最高标号预流推进(\(\texttt{High Level Preflow Push, HLPP}\))是一种高效的预流推进算法。
假设顶点 \(u\) 有其高度 \(h_u\),初始时 \(h_s = n, h_t = 0\),其余顶点高度为其到 \(t\) 的最短路长度。规定流量只向下一层流,即推送流量只能经过 \(\forall (u, v) \in E\),满足 \(h_u = h_v + 1\) 的边。\(\tt HLPP\) 的核心即为不断尝试抬高每个点的高度,将其剩余的流量推送到下一层的顶点。
假设当前顶点 \(u\) 仍有剩余流量无法推送,则尝试对 \(u\) 重标号。显然可以令 \(h_u = \min(h_v + 1)\),其中 \((u, v) \in E\)。如果最后该点高度被抬高到 \(n + 1\),说明该点的剩余流量都无法流出,此时会回流给源点。
每次用队列保存需要推送流量的顶点,每次推送完当前顶点的流量后将与其相邻的顶点加入队列。将队列换成优先队列就是 \(\tt HLPP\)
\(gap\) 优化:不同于 \(\tt ISAP\),\(\tt HLPP\) 的 \(gap\) 优化是若点 \(u\) 被抬高,其原本高度为 \(k\),当抬高点 \(u\) 后不存在高度为 \(k\) 的顶点,则可以将令 \(\forall h_i > k\),令 \(h_i = n + 1\)。
该算法的时间复杂度是 \(\mathcal{O}(n^2 \sqrt{m})\)
#include <cstdio>
#include <cstring>
#include <queue>
#include <algorithm>
using namespace std;
const int maxn = 1.2e3 + 5;
const int maxm = 1.2e5 + 5;
const int inf = 0x3f3f3f3f;
struct node {
int to, nxt, w;
} edge[maxm << 1];
int n, m, s, t;
int cnt = 1;
int head[maxn], h[maxn], flow[maxn], gap[maxn << 1];
bool vis[maxn];
struct cmp {
bool operator()(int a, int b) const {
return (h[a] < h[b]);
}
};
priority_queue<int, vector<int>, cmp> pq;
void add_edge(int u, int v, int w) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
head[u] = cnt;
}
bool bfs() {
queue<int> q;
memset(h, 0x3f, (n + 1) * sizeof(int));
h[t] = 0;
q.push(t);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (edge[i ^ 1].w && (h[v] > h[u] + 1)) {
h[v] = h[u] + 1;
q.push(v);
}
}
}
return (h[s] != inf);
}
void push(int u) {
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (edge[i].w && (h[v] + 1 == h[u])) {
int val = min(flow[u], edge[i].w);
edge[i].w -= val;
edge[i ^ 1].w += val;
flow[u] -= val;
flow[v] += val;
if ((v != s) && (v != t) && (!vis[v])) {
pq.push(v);
vis[v] = true;
}
if (!flow[u]) {
break;
}
}
}
}
void relabel(int u) {
h[u] = inf;
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (edge[i].w) {
h[u] = min(h[u], h[v] + 1);
}
}
}
void hlpp() {
if (!bfs()) {
return;
}
h[s] = n;
memset(gap, 0, (n << 1) * sizeof(int));
for (int i = 1; i <= n; i++) {
if (h[i] != inf) {
gap[h[i]]++;
}
}
for (int i = head[s]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (edge[i].w) {
int cur = edge[i].w;
edge[i].w -= cur;
edge[i ^ 1].w += cur;
flow[s] -= cur;
flow[v] += cur;
if ((v != s) && (v != t) && (!vis[v])) {
pq.push(v);
vis[v] = true;
}
}
}
while (!pq.empty()) {
int u = pq.top();
pq.pop();
vis[u] = false;
push(u);
if (flow[u]) {
gap[h[u]]--;
if (!gap[h[u]]) {
for (int i = 1; i <= n; i++) {
if ((i != s) && (i != t) && (h[i] > h[u]) && (h[i] < n + 1)) {
h[i] = n + 1;
}
}
}
relabel(u);
gap[h[u]]++;
pq.push(u);
vis[u] = true;
}
}
}
int main() {
int u, v, w;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%d", &u, &v, &w);
add_edge(u, v, w);
add_edge(v, u, 0);
}
hlpp();
printf("%d\n", flow[t]);
return 0;
}
最小割
最小割最大流(\(\texttt{Max-flow Min-cut}\)) 定理:对于一个网络 \(G\),有其最小割容量等于最大流流量。
对于网络 \(G\) 的任一可行流 \(f\) 和任一割 \((S, T)\),总有其汇入 \(t\) 的流量为 \(\sum\limits_{u \in S, v \in T} f(u, v) - f(v, u)\),即 \(S\) 到 \(T\) 的净流。显然上式小于等于 \(\sum\limits_{u \in S, v \in T} c(u, v)\),即最小割容量。因此有任一可行流小于等于任一割,由此知最大流流量小于等于最小割容量。
显然任一割的容量等于最大流流量时取最小值,则我们可以构造一个符合条件的割:在原图中跑完最大流后,将 \(s\) 通过残量网络可以到达的点集设为 \(S\),其余设为 \(T\),那么 \((S, T)\) 就是一组可行的最小割。原因是从 \(S\) 到 \(T\) 的边一定满流,则 \(\sum\limits_{u \in S, v \in T} f(u, v) - f(v, u) = c(u, v)\),即最大流流量等于最小割容量。因此证明了最小割容量可以取到下界(最大流流量)。
综上所述,对于任意网络 \(G\),总有其最小割容量等于最大流流量。
费用流
简介
给定一个包含 \(n\) 个点 和 \(m\) 条边的有向图(下称网络)\(G = (V, E)\),点编号为 \(1\) 到 \(n\),边编号为 \(1\) 到 \(m\),其中该网络的源点为 \(s\),汇点为 \(t\)。网络上的每一条边都有其流量限制 \(w(u, v)\) 和单位流量的花费 \(c(u, v)\)。
试给每条边 \((u, v)\) 确定其流量 \(f(u, v)\),使得:
-
每条边的流量不超过其流量限制
-
除源点和汇点外,每个点流入的流量和流出的流量相等
-
源点流出的流量等于汇点流入的流量
定义网络 \(G\) 的流量 \(F(G) = \sum\limits_{(s, i) \in E} f(s, i)\),费用 \(C(G) = \sum\limits_{(i, j) \in E} f(i, j) \times c(i, j)\)
求该网络的最小费用最大流,即在 \(F(G)\) 最大的前提下,令 \(C(G)\) 最小。
\(\tt SPFA\)
\(\tt SPFA\) 算法基于 \(\tt EK\) 算法。
对于原图中的边 \((u, v)\),在建反向边时令其容量为 \(0\),单位流量的花费为 \(-c(u, v)\)。以单位流量的花费为边权,求最小费用最大流只需将 \(\tt EK\) 算法中用 \(\tt bfs\) 找增广路改为用 \(\tt SPFA\) 求最短路即可。
原理:
显然增广的顺序不影响最大流的值。因为求最短路实质是找增广路,且算法会在程序中无增广路时结束,因此该算法求出的 \(F(G)\) 是最大流。
该算法每次增广一条残量网络中的最短路,因此总是贪心地做出当前最优的选择。当贪心不影响其后的最短路时,显然局部最优可以导致全局最优。反之,因为建边时反向边的边权(单位流量的花费)为其正向边的相反数,所以之后找到的最短路可以通过这条边返还若干个单位流量,同时相应地撤销其花费。类似于最大流,这些流量实际上是被两条不同的增广路接管了。通过反向边,我们确定贪心可以反悔,因此该算法求出的 \(C(G)\) 是最小费用。
综上所述,该算法求出的是最小费用最大流。
当然,该算法也可以套 \(\tt SPFA\) 的各种优化以及 \(\tt Dinic\)
#include <cstdio>
#include <cstring>
#include <queue>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 5e3 + 5;
const int maxm = 1e5 + 5;
const ll inf = 1e18;
struct node {
int to, nxt;
ll w, c;
} edge[maxm];
int n, m, s, t;
int cnt = 1, mc, mf;
int head[maxn], cur[maxn];
ll dis[maxn];
bool in_queue[maxn], vis[maxn];
void add_edge(int u, int v, ll w, ll c) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
edge[cnt].c = c;
head[u] = cnt;
}
bool spfa() {
queue<int> q;
for (int i = 1; i <= n; i++) {
dis[i] = inf;
}
memset(in_queue, false, (n + 1) * sizeof(bool));
dis[s] = 0;
in_queue[s] = true;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop();
in_queue[u] = false;
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((edge[i].w > 0) && (dis[v] > dis[u] + edge[i].c)) {
dis[v] = dis[u] + edge[i].c;
if (!in_queue[v]) {
in_queue[v] = true;
q.push(v);
}
}
}
}
return (dis[t] != inf);
}
ll dfs(int u, ll flow) {
if (u == t) {
mf += flow;
return flow;
}
ll sum = 0;
vis[u] = true;
for (int &i = cur[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((edge[i].w > 0) && (dis[v] == dis[u] + edge[i].c) && (!vis[v])) {
ll val = dfs(v, min(flow, edge[i].w));
edge[i].w -= val;
edge[i ^ 1].w += val;
mc += edge[i].c * val;
sum += val;
flow -= val;
if (!flow) {
break;
}
}
}
vis[u] = false;
return sum;
}
void dinic() {
while (spfa()) {
memcpy(cur, head, (n + 1) * sizeof(int));
dfs(s, inf);
}
}
int main() {
int u, v;
ll w, c;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%lld%lld", &u, &v, &w, &c);
add_edge(u, v, w, c);
add_edge(v, u, 0, -c);
}
dinic();
printf("%lld %lld\n", mf, mc);
return 0;
}
\(\tt zkw\) 流
思想
\(\tt zkw\) 流的思想和 \(\tt KM\) 算法类似,且是一种连续最短路算法。
回顾最短路算法中的距离标号。定义 \(D_i\) 为顶点 \(i\) 的距离标号,任何一个最短路算法保证对于任意 \((u, v) \in E\),有:
-
\(D_v \leq D_u + w(u, v)\)
-
对于每一个 \(v\) 一定存在至少一个 \(u\) 使得等号成立。
在 \(\tt zkw\) 流中,我们同样以单位流量的花费为边权。若每次只沿满足 \(D_u = D_v + c(u, v)\) 的边增广,显然条件 \(1\) 仍然成立,但是条件 \(2\) 不一定。在 \(\tt KM\) 算法中,我们通过修改顶标扩大相等子图。类似地,我们可以通过合理地修改顶点的距离标号,使得算法可以继续增广。
对于最后一次找增广路失败的 \(\tt dfs\),令此时可以访问的点集为 \(V\)。找到 \(d = \min\limits_{i \in V, j \notin V} (c(i, j) - D_i + D_j)\),并令所有访问过的顶点距离标号增加 \(d\)
分析
个人理解为 \(\tt zkw\) 流是以汇点为最短路的起点,求 \(d = \min\limits_{i \in V, j \notin V} c(i, j) - D_i + D_j\),实际上是在找最短路上与当前相等子图距离最小的顶点 \(j\)。距离标号 \(D_i\) 实际上保存的是 \(i\) 到 \(j\) 的距离。当 \(d\) 取最小值时,每个顶点都会尽量靠近最短路的起点 \(t\),也就相当于求最短路。当然,如果有多个满足要求的顶点,那么这些顶点都会被拉进子图。
根据上文,当 \(t\) 被加入 \(D_i = D_j + c_{ij}\) 子图时即为找到了一条最短的增广路,显然此时 \(D_i\) 表示从 \(i\) 到 \(t\) 的最短距离,即 \(D_s\) 表示流 \(1\) 个单位流量到 \(t\) 的最小花费。令流量为 \(flow\),最小费用加 \(D_s \times flow\),最大流加 \(flow\) 即可。
经过大量实测,\(\tt zkw\) 流一般在稠密图上比较快,在稀疏图上比较慢。
不妨从算法角度分析一下。\(\tt zkw\) 流的核心优化在于采用了 \(\tt KM\) 算法的重标号方式。每次标号只需要遍历一次边,复杂度比 \(\tt SPFA\) 优。并且,\(\tt zkw\) 流采用多路增广,即一次重标号后可以跑多次找增广路。
\(\tt zkw\) 流的劣势在于 \(\tt KM\) 算法的重标号方式不保证每次重标号后都一定存在增广路。最坏情况下,一次重标号只能往子图中拉进一条边。此时该算法就会反复重标号并且尝试增广,造成了时间的浪费。
由此看来,\(\tt zkw\) 流的时间效率和路径费用有很大关系。对于最终流量较大而费用取值范围较小的图,或者是增广路经比较短的图(如二分图),\(\tt zkw\) 流的效率更优。反之,如果费用取值范围较大且增广路径较长的图,\(\tt zkw\) 流的效率就会显著下降。
#include <cstdio>
#include <cstring>
#include <deque>
using namespace std;
const int maxn = 5e3 + 5;
const int maxm = 1e5 + 5;
const int inf = 2147483647;
struct node {
int to, nxt, w, c;
} edge[maxm];
int n, m, s, t;
int cnt = 1, max_flow, min_cost;
int head[maxn], dis[maxn];
bool vis[maxn];
void add_edge(int u, int v, int w, int c) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
edge[cnt].c = c;
head[u] = cnt;
}
int dfs(int u, int flow) {
if (u == t) {
max_flow += flow;
min_cost += dis[s] * flow;
return flow;
}
vis[u] = true;
int used = 0;
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if ((!vis[v]) && edge[i].w && (dis[u] == dis[v] + edge[i].c)) {
int cur = dfs(v, min(flow, edge[i].w));
if (cur) {
edge[i].w -= cur;
edge[i ^ 1].w += cur;
used += cur;
if (used == flow) {
return flow;
}
}
}
}
return used;
}
bool relabel() {
int d = inf;
for (int u = 1; u <= n; u++) {
if (vis[u]) {
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to;
if (!vis[v] && edge[i].w) {
d = min(d, dis[v] - dis[u] + edge[i].c);
}
}
}
}
if (d == inf) {
return false;
}
for (int i = 1; i <= n; i++) {
if (vis[i]) {
dis[i] += d;
}
}
return true;
}
void zkw() {
do {
do {
memset(vis, false, (n + 1) * sizeof(bool));
} while (dfs(s, inf));
} while (relabel());
}
int main() {
int u, v, w, c;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%d%d", &u, &v, &w, &c);
add_edge(u, v, w, c);
add_edge(v, u, 0, -c);
}
zkw();
printf("%d %d\n", max_flow, min_cost);
return 0;
}
原始对偶
当 \(h(u_1)\) 和 \(h(u_k)\) 确定时,新图中长度为 \(l\) 的最短路可以对应一条原图中长度为 \(l - h(u_1) + h(u_k)\) 的最短路。
考虑势函数 \(h\) 的维护。当原图中不存在负权边时,初始可以 \(\forall 1 \leq i \leq n, h(i) = 0\)。反之,应该跑一次 \(\tt SPFA\),令 \(h\) 初始值为该顶点的距离标号。
每次找最短路结束后,令新图上从源点 \(s\) 到顶点 \(i\) 的距离为 \(dis_i\),则 \(\forall 1 \leq i \leq n\) 且 \(i\) 为访问过的顶点,令 \(h(i) = h(i) + dis_i\)
每次增广结束后原图中会加入一些边 \((v, u)\),而这些边的反向边在被增广的最短路上,所以必定有 \(dis_u + w^{\prime}(u, v) = dis_v\)。对上式进行一些简单变形:
因此对于新加入的边,这样修改势函数仍然满足势函数的性质。
对于 \(G^{\prime}\) 原本存在的边 \((u, v)\),根据最短路的性质有 \(dis_u + w^{\prime}(u, v) \geq dis_v\),简单变形:
因此对于 \(G^{\prime}\) 中原本存在的边,这样修改势函数也满足势函数的性质。
由此可以得到算法的流程:
-
初始化 \(h\)
-
在根据残量网络构建的新图中跑 \(\tt Dijkstra\)
-
若 \(s\) 到 \(t\) 存在可行路径,增广该路径并修改势函数,转 \(2\);反之,算法结束。
#include <cstdio>
#include <cstring>
#include <queue>
#include <algorithm>
using namespace std;
const int maxn = 5e3 + 5;
const int maxm = 1e5 + 5;
const int inf = 0x3f3f3f3f;
struct node {
int to, nxt, w, c;
} edge[maxm];
int n, m, s, t;
int cnt = 1, mf, mc;
int head[maxn], pre[maxn];
int dis[maxn], h[maxn], flow[maxn];
void add_edge(int u, int v, int w, int c) {
cnt++;
edge[cnt].to = v;
edge[cnt].nxt = head[u];
edge[cnt].w = w;
edge[cnt].c = c;
head[u] = cnt;
}
bool dijkstra() {
priority_queue<pair<int, int>, vector<pair<int, int> >, greater<pair<int, int> > > pq;
memset(pre, 0, (n + 1) * sizeof(int));
memset(flow, 0, (n + 1) * sizeof(int));
memset(dis, 0x3f, (n + 1) * sizeof(int));
dis[s] = 0;
flow[s] = inf;
pq.push(make_pair(0, s));
while (!pq.empty()) {
int d = pq.top().first;
int u = pq.top().second;
pq.pop();
if (d > dis[u]) {
continue;
}
if (u == t) {
break;
}
for (int i = head[u]; i; i = edge[i].nxt) {
int v = edge[i].to, w = edge[i].c + h[u] - h[v];
if (edge[i].w && (dis[v] > dis[u] + w)) {
dis[v] = dis[u] + w;
pre[v] = i;
flow[v] = min(flow[u], edge[i].w);
pq.push(make_pair(dis[v], v));
}
}
}
return (dis[t] < inf);
}
void primal_dual() {
while (dijkstra()) {
mf += flow[t];
mc += (dis[t] - h[s] + h[t]) * flow[t];
for (int i = 1; i <= n; i++) {
h[i] = min(h[i] + dis[i], inf);
}
for (int i = t; i != s; i = edge[pre[i] ^ 1].to) {
edge[pre[i]].w -= flow[t];
edge[pre[i] ^ 1].w += flow[t];
}
}
}
int main() {
int u, v, w, c;
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++) {
scanf("%d%d%d%d", &u, &v, &w, &c);
add_edge(u, v, w, c);
add_edge(v, u, 0, -c);
}
primal_dual();
printf("%d %d\n", mf, mc);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号