
Java IO(十一) DataInputStream 和 DataOutputStream
Java IO(十一) DataInputStream 和 DataOutputStream
一、介绍
DataInputStream 和 DataOutputStream 是数据字节流,分别继承自 FilterInputStream 和 FilterOutputStream 和 实现了 DataInput 和 DataOutput。用来装饰其他的字节流。
- DataInputStream:数据字节输入流,用来装饰其他的输入流,允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。应用程序可以使用 DataOutputStream (数据字节输出流)写入由 DataInputStream (数据字节输入流)读取的数据。
- DataOutputStream :数据字节输出流,用来装饰其他输出流,将 DataOutputStream 和 DataInputStream 输入流配合使用,允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型。
二、构造方法
(一)、DataInputStream
public DataInputStream(InputStream in) //创建使用指定的底层 InputStream 的输入数据流
(二)、DataOutputStream
public DataOutputStream(OutputStream out) // 创建一个使用指定底层 OutputStream 的数据输出流,以将数据写入指定的底层输出流。
三、常用API
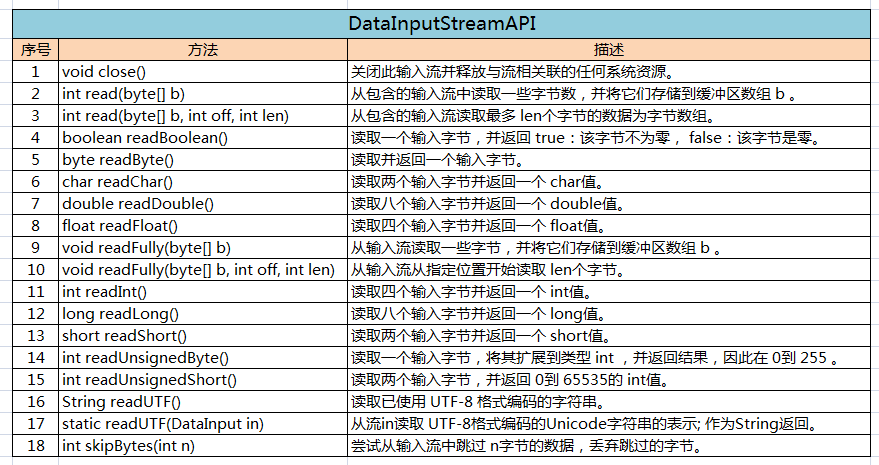
(一)、DataInputStream
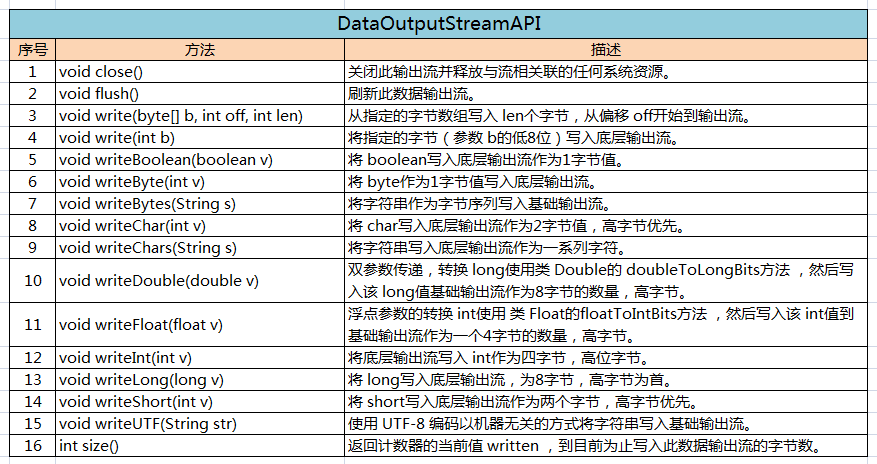
(二)、DataOutputStream
四、DataInputStream 和 DataOutputStream 的编码问题
DataInputStream 和 DataOutputStream 关于编码有关的方法,分别是 String readUTF() 和 void writeUTF(String str)。下面就这个两个方法说明一下编码问题
(一)、DataOutputStream 的 void writeUTF(String str)
DataOutputStream 的 writeUTF 方法是将以 UTF-8 的编码格式的数据写入底层输出流中。具体流程如下:
①、定义一个 strlen 变量,存储字符串的长度 int strlen = str.length();
②、通过 for 循环遍历 str ,根据c的大小决定存储长度utflen的大小,最大65535字节,也就是64kb,超出最大字节会抛出 UTFDataFormatException 异常。
for (int i = 0; i < strlen; i++) {
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
utflen++; // 单字节
} else if (c > 0x07FF) {
utflen += 3;// 三字节
} else {
utflen += 2; // 两字节
}
}
③、定义一个byte数组类型的变量 bytearr,判断该数据输出流是否是 DataOutputStream,若是则: 设置bytearr的大小。+2是需要在 bytearr 前两字节中存储数据长度 utflen。
byte[] bytearr = null; if (out instanceof DataOutputStream) { DataOutputStream dos = (DataOutputStream)out; if(dos.bytearr == null || (dos.bytearr.length < (utflen+2))) dos.bytearr = new byte[(utflen*2) + 2]; bytearr = dos.bytearr; } else { bytearr = new byte[utflen+2]; }
④、根据字符串的字符的字节数分别放入 bytearr 数组中
int i=0;
// 如果是ascii码就直接存在 bytearr 数组中 for (i=0; i<strlen; i++) { c = str.charAt(i); if (!((c >= 0x0001) && (c <= 0x007F))) break; bytearr[count++] = (byte) c; } for (;i < strlen; i++){ c = str.charAt(i); if ((c >= 0x0001) && (c <= 0x007F)) {
// 如果是单字节 bytearr[count++] = (byte) c; } else if (c > 0x07FF) {
// 三字节 bytearr[count++] = (byte) (0xE0 | ((c >> 12) & 0x0F)); bytearr[count++] = (byte) (0x80 | ((c >> 6) & 0x3F)); bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F)); } else {
// 两字节 bytearr[count++] = (byte) (0xC0 | ((c >> 6) & 0x1F)); bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F)); } } out.write(bytearr, 0, utflen+2); return utflen + 2; // 返回 bytearr 数组大小
源码基于JDK1.8,上面只贴出主要源码,详细源码自行查看 DataOutputStream 类。
(二)、DataInputStream 的 String readUTF()
上面知道了写入的规则,DataInputStream 的 String readUTF() 读取的规则与写入的规则相反。
①、定义 utflen 变量读取输入流中UTF-8数据的长度: int utflen = in.readUnsignedShort();
②、创建字符数组 bytearr 和 字节数组 chararr
byte[] bytearr = null; char[] chararr = null;
③、判断该数据输入流是否是 DataInputStream ,若是,则:
- 设置字节数组bytearr = "数据输入流"的成员bytearr
- 设置字符数组chararr = "数据输入流"的成员chararr
否则,新建数组 bytearr 和 chararr。
if (in instanceof DataInputStream) { DataInputStream dis = (DataInputStream)in; if (dis.bytearr.length < utflen){ dis.bytearr = new byte[utflen*2]; dis.chararr = new char[utflen*2]; } chararr = dis.chararr; bytearr = dis.bytearr; } else { bytearr = new byte[utflen]; chararr = new char[utflen]; }
④、将UTF-8数据全部读取到字节数组 bytearr 中通过 readFully() 方法: in.readFully(bytearr, 0, utflen);
⑤、对UTF-8中单字节数据进行预处理,UTF-8的数据是变长的,可以是1-4个字节;在readUTF()中,我们最终是将全部的UTF-8数据保存到字符数组(而不是字节数组)中,再将其转换为String字符串。
由于UTF-8的单字节和ASCII相同,所以这里就将它们进行预处理,直接保存到字符数组 chararr 中。对于其它的UTF-8数据,则在后面进行处理。
while (count < utflen) { c = (int) bytearr[count] & 0xff; // 将每字节转成 int 值 if (c > 127) break; // UTF-8单子节数据不会超过127,超过则退出 count++; chararr[chararr_count++]=(char)c;// 将int转成char存入字符数组 }
⑥、对预处理后的数据进行再处理
while (count < utflen) { c = (int) bytearr[count] & 0xff; // 将字节有 byte 转成 int switch (c >> 4) { // 将 int 类型左移 4 位 case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7: /* 若UTF-8是单字节数据,则 bytearr[count] 的格式:0xxxxxxx,对应 int 类型的字符 c 取值范围:0-7 */ count++; chararr[chararr_count++]=(char)c; break; case 12: case 13: /* 若UTF-8是两字节数据,则 bytearr [count]的格式:110x xxxx 10xx xxxx,对应 int 类型的字符 c 的取值范围:12-13*/ count += 2; if (count > utflen) throw new UTFDataFormatException("malformed input: partial character at end"); char2 = (int) bytearr[count-1]; if ((char2 & 0xC0) != 0x80) throw new UTFDataFormatException("malformed input around byte " + count); chararr[chararr_count++]=(char)(((c & 0x1F) << 6) |(char2 & 0x3F)); break; case 14: /* 若UTF-8是三字节数据,则 bytearr[count] 的格式:1110 xxxx 10xx xxxx 10xx xxxx,对应 int 类型的字符 c 的取值范围是:14 */ count += 3; if (count > utflen) throw new UTFDataFormatException("malformed input: partial character at end"); char2 = (int) bytearr[count-2]; char3 = (int) bytearr[count-1]; if (((char2 & 0xC0) != 0x80) || ((char3 & 0xC0) != 0x80)) throw new UTFDataFormatException("malformed input around byte " + (count-1)); chararr[chararr_count++]=(char)(((c & 0x0F) << 12) | ((char2 & 0x3F) << 6) | ((char3 & 0x3F) << 0)); break;
default: /* 若UTF-8是四字节的数据,则bytearr[count] 的格式:10xx xxxx,1111 xxxx,对应 int 类型的字符 c 的取值范围是:15 */ throw new UTFDataFormatException("malformed input around byte " + count); } }
⑦、将字符数组 chararr 转成 String类型返回: return new String(chararr, 0, chararr_count);
五、实例
public static void main(String[] args) { write(); read(); } /** * DataInputStream 测试 */ public static void read() { DataInputStream in = null; try { in = new DataInputStream(new FileInputStream("data.txt")); System.out.println("readUTF : " + in.readUTF()); System.out.println("read : " + (char)in.read()); System.out.println("readBoolean : " + in.readBoolean()); System.out.println("readDouble : " + in.readDouble()); System.out.println("readFloat : " + in.readFloat()); System.out.println("readByte : " + in.readByte()); System.out.println("readChar : " + in.readChar()); System.out.println("readLong : " + in.readLong()); System.out.println("readLong : " + in.readLong()); }catch(Exception e) { e.printStackTrace(); }finally { try { if (in != null) in.close(); }catch (Exception e) { e.printStackTrace(); } } } /** * DataOutputStream 测试 */ public static void write() { DataOutputStream out = null; try { out = new DataOutputStream(new FileOutputStream("data.txt")); out.writeUTF("Java IO 入门"); out.write('A'); out.writeBoolean(true); out.writeDouble(3.14D); out.writeFloat(0.69F); out.write("abcdefg".getBytes()); out.writeByte(99); out.writeChars("Hello World"); out.writeLong(46L); out.writeBytes("data input stream"); }catch(Exception e) { e.printStackTrace(); }finally { try { if (out != null) out.close(); }catch (Exception e) { e.printStackTrace(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号