
大数据笔记(三十)——一篇文章读懂SparkSQL
Spark SQL:类似Hive
=======================================================
一、Spark SQL基础
1、什么是Spark SQL?
(*) Spark SQL is Apache Spark's module for working with structured data.
(*) 处理结构化数据的引擎
(*) 底层:依赖RDD,把SQL语句转换成一个个RDD,运行在不同的Worker节点上
(*) 特点:
(1)容易集成:SQL
(2)对于不同的数据源,提供统一的访问方式(DataFrame:表)
(3)兼容Hive
2、核心概念:DataFrame(表):就是“表”,是Spark SQL对结构化数据的抽象集合
表现形式:RDD
”表“ = 表结构 + 数据
DataFrame = schema + RDD
DataSet(新API接口):数据的分布式集合,比DataFrame更抽象,支持Scala和Java
3、创建DataFrame:(create table *****)
(*)测试数据:emp.csv和dept.csv
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
(1)方式一:通过case class定义表
(*)定义一个case class来代表emp表的schema结构
case class Emp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
(*)导入emp.csv文件
val lines = sc.textFile("/root/temp/emp.csv").map(_.split(","))
(*)生成一个表:DataFrame
将case class和RDD(lines)关联起来
Array(7369, SMITH, CLERK, 7902, 1980/12/17, 800, "", 20)
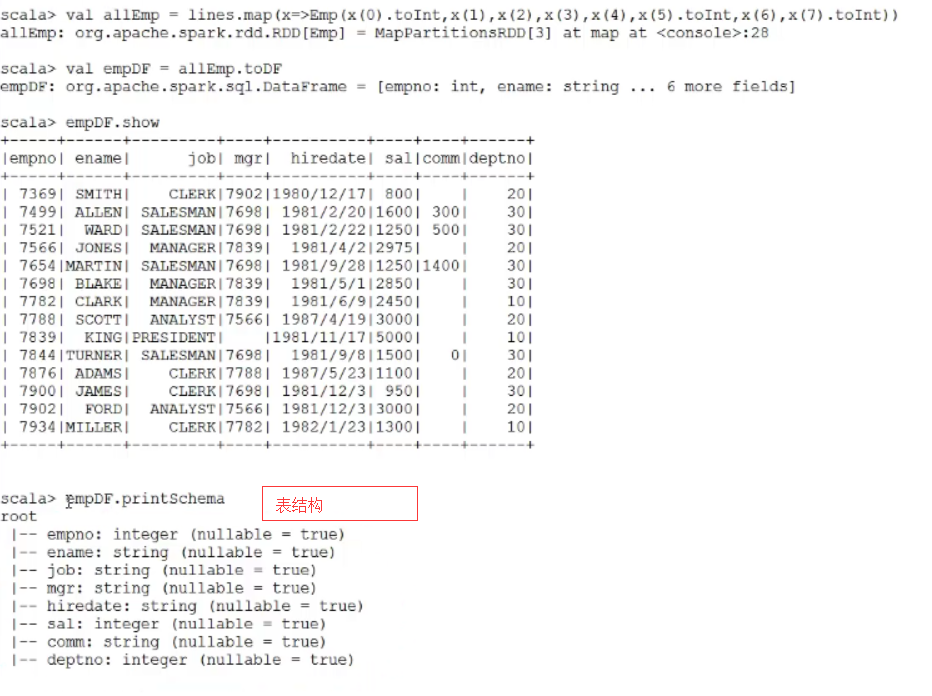
val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
生成表:
val empDF = allEmp.toDF
操作:
empDF.show
empDF.printSchema
结果:
(2)方式二:通过SparkSession.createDataFrame()
(*)什么是Spark Session?
spark shell启动日志:Spark session available as 'spark'.

spark session是spark 2.0后,新的访问接口(统一的访问方式),通过SparkSession对象可以访问Spark的各个模块
(*)数据:
val empCSV = sc.textFile("/root/temp/emp.csv").map(_.split(","))
结构:Schema ----> 类:StructType
import org.apache.spark.sql._ import org.apache.spark.sql.types._
通过StructType定义Schema结构:
val myschema = StructType(List(StructField("empno", DataTypes.IntegerType),
StructField("ename", DataTypes.StringType),
StructField("job", DataTypes.StringType),
StructField("mgr", DataTypes.StringType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm", DataTypes.StringType),
StructField("deptno", DataTypes.IntegerType)))
(*)把读入的数据empCSV映射成表的一行(Row:trait):这里没有带结构
可以通过Spark API 查看:
http://spark.apache.org/docs/2.1.0/api/scala/index.html#package

import org.apache.spark.sql._ val rowRDD = empCSV.map(x=>Row(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
(*)通过SparkSession.createDataFrame(数据,schema结构)创建表
val df = spark.createDataFrame(rowRDD,myschema)
(3)方式三:直接读取一个具有格式的数据文件(例如:json文件,parquet文件)
前提:数据文件本身具有格式
Example数据文件:
/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json
示例:
val peopleDF = spark.read.json("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")

4、操作DataFrame: DSL语句和SQL语句
DF常用操作命令:

(1)DSL(不常用)
查询所有的员工信息:
df.show
查询员工信息:姓名
df.select("ename").show
df.select($"ename").show //$当作变量
查询员工信息: 姓名 薪水 薪水+100
df.select($"ename",$"sal",$"sal"+100).show
查询工资大于2000的员工
df.filter($"sal" > 2000).show
分组:
df.groupBy($"deptno").count.show
(2)SQL: 注意:需要将DataFrame注册成一个视图(view)
df.createOrReplaceTempView("emp")
spark.sql("select * from emp").show
spark.sql("select * from emp where deptno=10").show
spark.sql("select deptno,sum(sal) from emp group by deptno").show
5、临时视图view:2种
(1)只在当前会话中有效:
df.createOrReplaceTempView("emp")
(2)Global Temporay View 在全局范围都有效(不同的会话中)
df.createGlobalTempView("empG") ----> 相当于:在Spark SQL的"全局数据库"上创建的: 前缀: global_temp
(3)示例
在当前会话中:
spark.sql("select * from emp").show
spark.sql("select * from global_temp.empG").show
开启一个新的会话,重新查询
spark.newSession.sql("select * from emp").show ----> 出错
spark.newSession.sql("select * from global_temp.empG").show ---->正常运行
6、DataSet
DataSet是的DataFrame的类型扩展,它可以更好的保证编译期的运行安全。
二、使用数据源
1、load和save函数: 默认都是Parquet文件
(*)使用load函数加载数据,自动生成表(DataFrame)
(*)注意:load函数默认的数据源是Parquet文件
val usersDF = spark.read.load("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/users.parquet")
查询:
usersDF.show
(*)使用save函数保存结果
需求:查询用户的名字和喜欢的颜色,并保存
scala> usersDF.select($"name",$"favorite_color").write.save("/root/temp/result")

再load进来
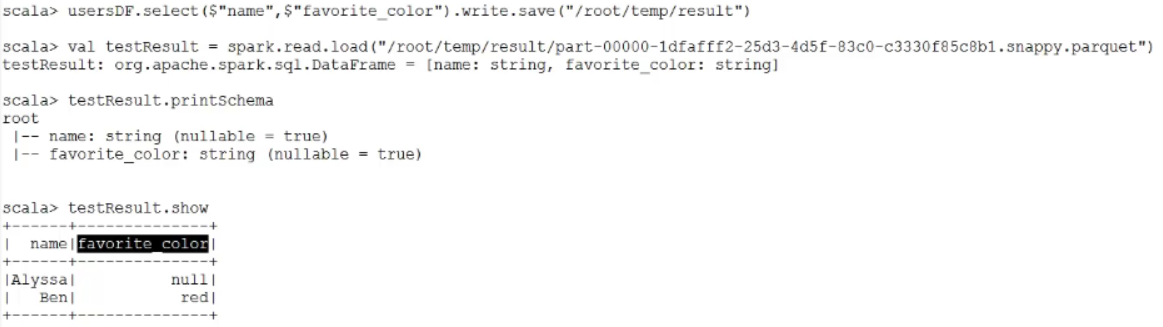
2、Parquet文件:是Spark SQL的Load函数默认的数据源
(*)特点:列式存储文件
(*)把其他文件格式转成Parquet文件 json文件 ----> parquet文件
val empJSON = spark.read.json("/root/temp/emp.json") ---->dataFrame
empJSON.write.mode("overwrite").parquet("/root/temp/result") ---->把这个dataFrame写出去
(*)功能:支持Schema的合并
第一个文件
val df1 = sc.makeRDD(1 to 5).map(i=>(i,i*2)).toDF("single","double") ---->做一个操作,转换成一个元组,第一个参数是1,2,3,4,5,第二个参数是乘以2之后的数
df1.write.parquet("/root/temp/test_table/key=1")
第二个文件
val df2 = sc.makeRDD(6 to 10).map(i=>(i,i*3)).toDF("single","triple")
df2.write.parquet("/root/temp/test_table/key=2")
合并上面的文件
val df3 = spark.read.option("mergeSchema","true").parquet("/root/temp/test_table")
查看结果:
scala> df3.printSchema root |-- single: integer (nullable = true) |-- double: integer (nullable = true) |-- triple: integer (nullable = true) |-- key: integer (nullable = true) scala> df3.show +------+------+------+---+ |single|double|triple|key| +------+------+------+---+ | 8| null| 24| 2| | 9| null| 27| 2| | 10| null| 30| 2| | 3| 6| null| 1| | 4| 8| null| 1| | 5| 10| null| 1| | 6| null| 18| 2| | 7| null| 21| 2| | 1| 2| null| 1| | 2| 4| null| 1| +------+------+------+---+
3、JSON文件
示例:
spark.read.json("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
另一种写法:
val df4 = spark.read.format("json").load("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
4、JDBC方式: 读取关系型数据库中的数据(Oracle)
(*)需要把JDBC的驱动加入
bin/spark-shell --master spark://bigdata11:7077 --jars /root/temp/ojdbc14.jar --driver-class-path /root/temp/ojdbc14.jar
(*)读取Oracle
val oracleEmp = spark.read.format("jdbc").option("url","jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com").option("dbtable","scott.emp").option("user","scott").option
windows上:
val oracleEmp = spark.read.format("jdbc").option("driver","oracle.jdbc.OracleDriver").option("url","jdbc:oracle:thin:@192.168.153.135:1521/orcl").option("dbtable","scott.emp").option("user","scott").option("password","tiger").load
使用Properties类
scala> import java.util.Properties import java.util.Properties scala> val prop = new Properties() prop: java.util.Properties = {} scala> prop.setProperty("user","scott") res1: Object = null scala> prop.setProperty("password","tiger") res2: Object = null scala> val oracleDF1 = spark.read.jdbc("jdbc:oracle:thin:@192.168.153.135:1521/orcl.example.com","scott.emp",prop) val oracleDF1 = spark.read.jdbc("jdbc:oracle:thin:@192.168.153.135:1521/orcl","scott.emp",prop) oracleDF1: org.apache.spark.sql.DataFrame = [EMPNO: decimal(4,0), ENAME: string ... 6 more fields]

5、操作Hive的表(需要配置)
(*)复习Hive
(1)基于HDFS之上的数据仓库
表(分区) ---> HDFS目录
数据 ---> HDFS文件
(2)是一个数据分析引擎,支持SQL
(3)翻译器:SQL ---> MapReduce程序
注意:从Hive 2.x开始,推荐使用Spark作为执行引擎(目前不成熟,还在开发)
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
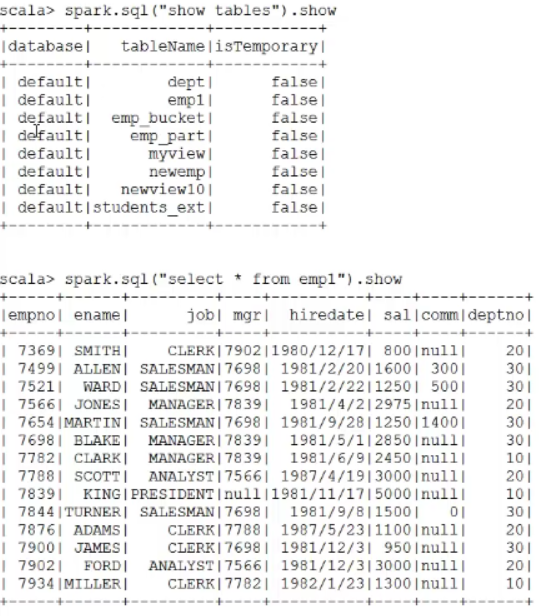
(*)如何使用Spark SQL加载Hive的数据?
文档:http://spark.apache.org/docs/latest/sql-programming-guide.html#hive-tables
步骤:
(1)把Hive的配置文件和Hadoop的配置文件 ----> $SPARK_HOME/conf
hive-site.xml core-site.xml hdfs-site.xml cp hadoop-2.7.3/etc/hadoop/core-site.xml spark-2.1.0-bin-hadoop2.7/conf/ cp hadoop-2.7.3/etc/hadoop/hdfs-site.xml spark-2.1.0-bin-hadoop2.7/conf/ cp apache-hive-2.3.0-bin/conf/hive-site.xml spark-2.1.0-bin-hadoop2.7/conf/
(2)启动spark-shell的时候,加入mysql的驱动
cd ~/training/apache-hive-2.3.0-bin/lib/ cp mysql-connector-java-5.1.43-bin.jar ~/temp/ bin/spark-shell --master spark://bigdata11:7077 --jars /root/temp/mysql-connector-java-5.1.43-bin.jar
三、在IDEA中开发Spark SQL程序

1、指定schema的格式(表结构)
package main.scala.demo import java.util.Properties import org.apache.spark.sql.{Row, SparkSession} import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType} /** * Created by YOGA on 2018/2/27. */ object SpecifyingSchema { def main(args: Array[String]) { //这一步不能忘了加 Class.forName("oracle.jdbc.OracleDriver") //创建一个Spark Session对象 val spark = SparkSession.builder() .master("local") .appName("SpecifyingSchema") .getOrCreate() //在Spark Session中包含一个Spark Context,读取数据 val data = spark.sparkContext.textFile("D:\\temp\\students.txt") .map(_.split(" ")) //创建Schema的结构 val schema = StructType( List( StructField("id",IntegerType,true), StructField("name",StringType,true), StructField("age",IntegerType,true) ) ) //将数据RDD映射成Row val rowRDD = data.map(p => Row(p(0).toInt,p(1).trim,p(2).toInt)) //关联Schema val studentDF = spark.createDataFrame(rowRDD,schema) //生成表 studentDF.createOrReplaceTempView("student") //执行sql val result = spark.sql("select * from student") result.show() //保存到Oracle中 /*val props = new Properties() props.setProperty("user","scott") props.setProperty("password","tiger") //.mode("append") 表已存在采用追加模式 result.write.mode("append").jdbc("jdbc:oracle:thin:@192.168.153.135:1521/orcl","scott.student",props)*/ spark.stop() } }
运行:

2、使用case class
package main.scala.demo import org.apache.spark.sql.SparkSession object UseCaseClass { def main(args: Array[String]): Unit = { //创建一个Spark Session对象 val sparkSession = SparkSession.builder().master("local").appName("SpecifyingSchema").getOrCreate() //读取数据,生成对应的RDD val lineRDD = sparkSession.sparkContext.textFile("D:\\temp\\students.txt").map(_.split(" ")) val studentRDD = lineRDD.map(x => Student(x(0).toInt,x(1),x(2).toInt)) //生成DataFrame, 需要导入隐式转换 import sparkSession.sqlContext.implicits._ val studentDF = studentRDD.toDF //生成表 studentDF.createOrReplaceTempView("mystudent") //执行SQl sparkSession.sql("select * from mystudent").show() sparkSession.stop() } } //定义样本类: schema case class Student(stuID:Int,stuName:String,stuAge:Int)
3、保存到关系型数据库中
把定义Schema的保存到数据库注释去掉。
去Oracle数据库查询:

四、性能的优化:缓存的方式(内存)
1、如何缓存数据(表的数据、DataFrame的数据)
举例:读取Oracle数据库
Linux上: val oracleEmp = spark.read.format("jdbc").option("url","jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com").option("dbtable","scott.emp").option("user","scott").option("password","tiger").load windows上: val oracleEmp = spark.read.format("jdbc").option("driver","oracle.jdbc.OracleDriver").option("url","jdbc:oracle:thin:@192.168.153.135:1521/orcl").option("dbtable","scott.emp").option("user","scott").option("password","tiger").load 注册表:oracleEmp.registerTempTable("emp") 因为是:视图不能存储数据 执行查询: spark.sql("select * from emp").show 缓存数据: spark.sqlContext.cacheTable("emp") 执行查询(两次): spark.sql("select * from emp").show spark.sql("select * from emp").show
![]()
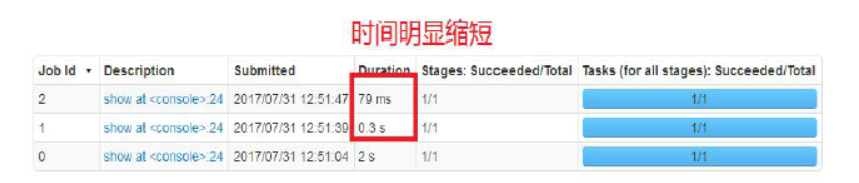
性能优化相关参数:
![]()

![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号