
大数据笔记(十六)——Hive的客户端及自定义函数
一.Hive的Java客户端
JDBC工具类:JDBCUtils.java
package demo.jdbc; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; //工具类:(1)获取数据库的链接 (2)释放数据库资源 public class JDBCUtils { //Hive驱动 private static String driver = "org.apache.hive.jdbc.HiveDriver"; //Hive的位置 private static String url = "jdbc:hive2://192.168.153.11:10000/default"; //注册数据库的驱动:Java的反射 static{ try { Class.forName(driver); } catch (ClassNotFoundException e) { throw new ExceptionInInitializerError(e); } } //获取数据库链接 public static java.sql.Connection getConnection(){ try { return DriverManager.getConnection(url); } catch (SQLException e) { e.printStackTrace(); } return null; } //释放资源 public static void release(java.sql.Connection conn,Statement st,ResultSet rs){ if(rs != null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); }finally{ rs = null; } } if(st != null){ try { st.close(); } catch (SQLException e) { e.printStackTrace(); }finally{ st = null; } } if(conn != null){ try { conn.close(); } catch (SQLException e) { e.printStackTrace(); }finally{ conn = null; } } } }
DemoTest.java
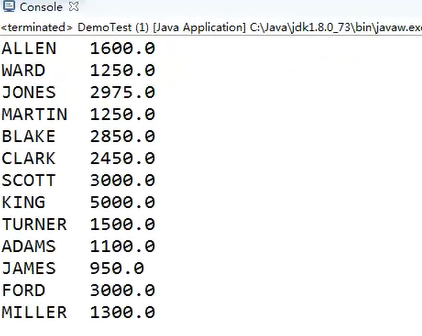
package demo.jdbc; import java.sql.ResultSet; import java.sql.Statement; public class DemoTest { public static void main(String[] args) { String sql = "select * from emp1"; java.sql.Connection conn = null; Statement st = null; ResultSet rs = null; try { conn = JDBCUtils.getConnection(); //得到SQL的运行环境 st = conn.createStatement(); //ִ执行SQL rs = st.executeQuery(sql); while (rs.next()) { //姓名 薪水 String name = rs.getString("ename"); double sal = rs.getDouble("sal"); System.out.println(name + "\t" +sal); } }catch(Exception e){ e.printStackTrace(); }finally { JDBCUtils.release(conn, st, rs); } } }
启动HiveServer:hiveserver2,会报错:
java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException:User:
root is not allowed to impersonate anonymous
在老版本的Hive中,是没有这个问题的
解决:
把Hadoop HDFS的访问用户(代理用户) ---> *
core-site.xml
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
二.Hive的自定义函数
例子:
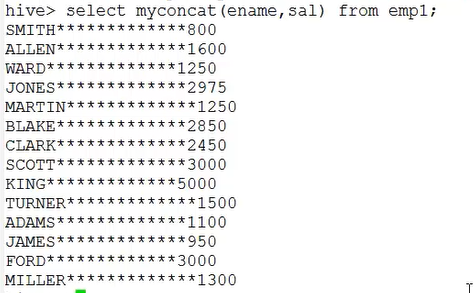
1.concat 拼加两个字符串
package udf; import org.apache.hadoop.hive.ql.exec.UDF; /** * 实现关系型数据库中的concat函数:拼加字符串 * 需要继承的类:UDF * */ public class MyConcatString extends UDF{ //必须重写一个方法,方法名叫: evaluate public String evaluate(String a,String b){ return a + "*************"+b; } }
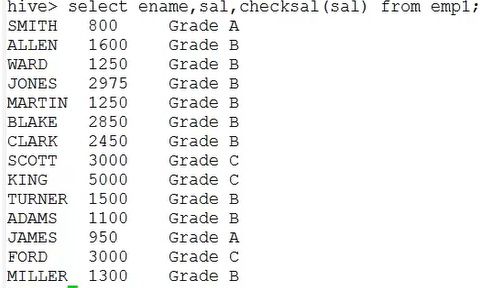
2.判断员工工资的级别
package udf; import org.apache.hadoop.hive.ql.exec.UDF; /** * 根据员工薪水判断级别 * */ public class CheckSalaryGrade extends UDF{ public String evaluate(String salary){ int sal = Integer.parseInt(salary); if (sal<1000) { return "Grade A"; }else if (sal>=1000 && sal<3000) { return "Grade B"; }else { return "Grade C"; } } }
3、打包
将jar包加入hive的classpath
在hive命令行执行:add jar /root/temp/myudf.jar;
创建别名(函数名称)
create temporary function myconcat as 'demo.udf.MyConcatString';
create temporary function checksal as 'demo.udf.CheckSalaryGrade';

结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号