基于树莓派与YOLOv3模型的人体目标检测小车(二)
上篇文章介绍了如何搭建深度学习环境,在Ubuntu18.04TLS上搭建起了 CUDA:9.0+cuDNN7.0+tensorflow-gpu 1.9 的训练环境。本篇文章将介绍如何制作自己的数据集,并训练模型。
本文训练数据集包括从VOC数据集中提取出6095张人体图片,以及使用LabelImg工具标注的200张python爬虫程序获取的人体图片作为补充。
一、爬取人体图片并标记
# coding=utf-8
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def getPage(keyword, page, n):
page = page * n
keyword = urllib.parse.quote(keyword, safe='/')
url_begin = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="
url = url_begin + keyword + "&pn=" + str(page) + "&gsm=" + str(hex(page)) + "&ct=&ic=0&lm=-1&width=0&height=0"
return url
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
return pic_urls
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '行人图片' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
page_begin = 0
page_number = 100
image_number = 3
all_pic_urls = []
while 1:
if page_begin > image_number:
break
print("第%d次请求数据", [page_begin])
url = getPage(keyword, page_begin, page_number)
onepage_urls = get_onepage_urls(url)
page_begin += 1
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
使用labelimg标记图片

二、从VOC数据集里提取出人体图片
import os
import os.path
import shutil
fileDir_ann = "D:\\VOC\\VOCdevkit\\VOC2012\\Annotations"
fileDir_img = "D:\\VOC\\VOCdevkit\\VOC2012\\JPEGImages\\"
saveDir_img = "D:\\VOC\\VOCdevkit\\VOC2012\\JPEGImages_ssd\\"
if not os.path.exists(saveDir_img):
os.mkdir(saveDir_img)
names = locals()
for files in os.walk(fileDir_ann):
for file in files[2]:
saveDir_ann = "D:\\VOC\\VOCdevkit\\VOC2012\\Annotations_ssd\\"
if not os.path.exists(saveDir_ann):
os.mkdir(saveDir_ann)
fp = open(fileDir_ann + '\\' + file)
saveDir_ann = saveDir_ann + file
fp_w = open(saveDir_ann, 'w')
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', '>cat<', 'chair', 'cow',
'diningtable', \
'dog', 'horse', 'motorbike', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor', 'person']
lines = fp.readlines()
ind_start = []
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
while "\t<object>\n" in lines_id_start:
a = lines_id_start.index("\t<object>\n")
ind_start.append(a)
lines_id_start[a] = "delete"
while "\t</object>\n" in lines_id_end:
b = lines_id_end.index("\t</object>\n")
ind_end.append(b)
lines_id_end[b] = "delete"
i = 0
for k in range(0, len(ind_start)):
for j in range(0, len(classes)):
if classes[j] in lines[ind_start[i] + 1]:
a = ind_start[i]
names['block%d' % k] = [lines[a], lines[a + 1], \
lines[a + 2], lines[a + 3], lines[a + 4], \
lines[a + 5], lines[a + 6], lines[a + 7], \
lines[a + 8], lines[a + 9], lines[a + 10], \
lines[ind_end[i]]]
break
i += 1
classes1 = '\t\t<name>person</name>\n'
string_start = lines[0:ind_start[0]]
string_end = [lines[len(lines) - 1]]
a = 0
for k in range(0, len(ind_start)):
if classes1 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
string_start += string_end
for c in range(0, len(string_start)):
fp_w.write(string_start[c])
fp_w.close()
if a == 0:
os.remove(saveDir_ann)
else:
name_img = fileDir_img + os.path.splitext(file)[0] + ".jpg"
shutil.copy(name_img, saveDir_img)
fp.close()
三、修改YOLOv3 tiny 配置文件
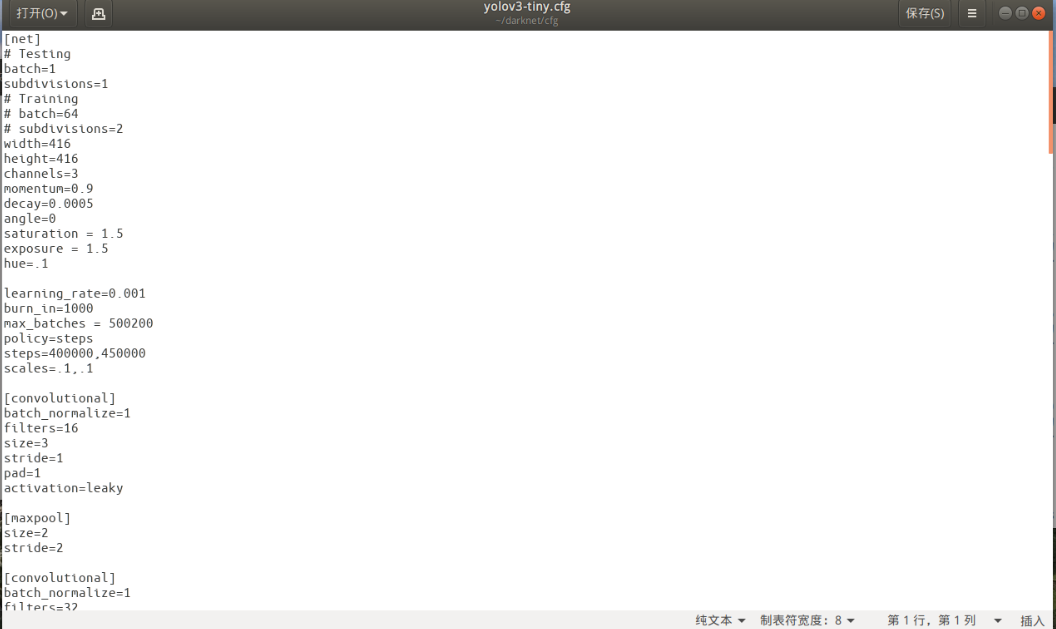
- yolov3-tiny.cfg
batch = 64
max_batchs=500200 迭代次数
learning_rate = 0.001
steps = 400000,450000 scales =.1,.1 学习率在400000和450000次时缩小10倍
class = 1 设置单类别
- 删除voc.names中其余名字,只保留person
- 修改voc.data中classes值为1
四、下载预训练权重开始训练
预训练权重可以减少前期的迭代次数,加速训练过程。
wget https://pjreddie.com/media/files/darknet53.conv.74
开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc-tiny.cfg darknet53.conv.74
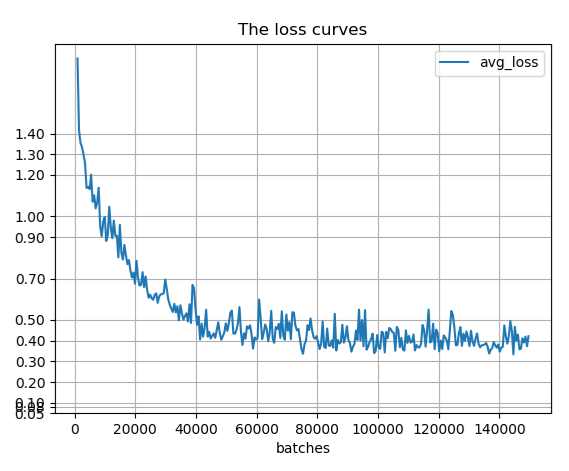
通过绘制训练过程的loss曲线可知,开始时loss下降较快,之后开始在一水平线上波动。
训练结束得到yolov3-voc_final.weights模型文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号