

专利阅读 一种学术资源推荐服务系统与方法
一种学术资源推荐服务系统与方法
本篇专利是实验室师兄师姐完成的,最近想到学术会议推荐其实也是学术资源推荐的一种, 因此将所看论文范围扩大到了学术资源推荐,正巧,实验室往届师姐有做这个方向。现将看到的一篇相关专利笔记记录下来。
该专利于2016年12月9日申请,发明名称为“一种学术资源推荐服务系统与方法”该方法示意图如下所示:
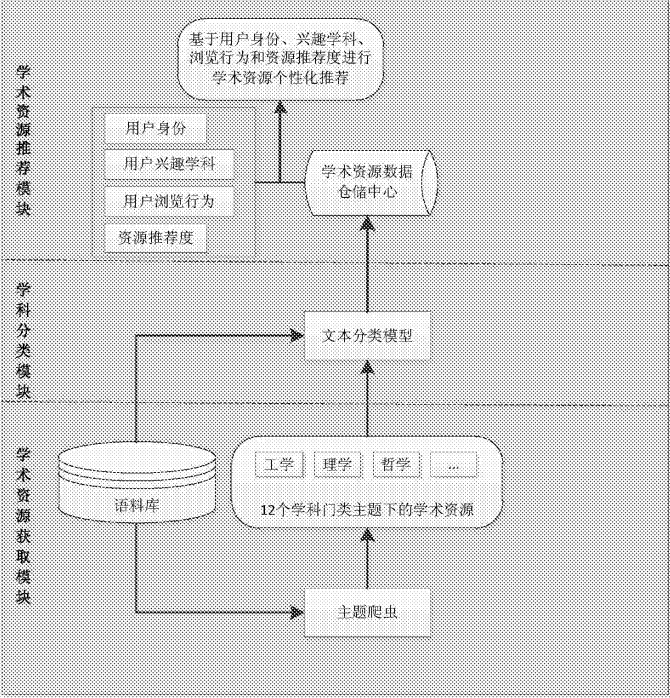
本方法采用LDA主题爬虫获取学术资源,用LDA文本分类模型费雷学术资源数据库,结合用户的身份、兴趣学科和历史浏览行为数据进行学术资源的个性化推荐。学术资源推荐服务系统包括学术资源模型、资源质量值计算模型、用户兴趣模型。
网络爬虫为主题爬虫,包括LDA主题模型。本部分介绍看不是太懂,暂不多做介绍。向用户推荐过程包括冷启动推荐阶段与二次推荐阶段,冷启动推荐基于兴趣学科为用户推荐符合兴趣学科的的优质资源,优质资源可用资源质量值表示,资源质量值为资源权威度、资源热度和资源时新度的算数平均值或加权平均值;二次推荐,分别对用户兴趣模型和资源模型建模,计算用户兴趣模型与资源模型二者的相似性,然后结合资源质量值计算推荐度。
1、资源质量Quality由以下几部分组成:
资源权威Authority:
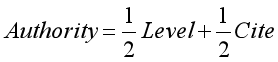
其中,Level为资源发刊物的等级(1、0.8、0.6、0.4和0.2)。Cite为引用情况,公式如下:
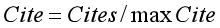
其中,Cites为被引量,maxCite为数据库中最大被引量。
资源热度Popularity:
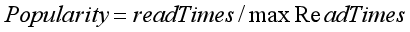
其中,readTimes为资源阅读次数,maxReadTimes为数据库中最大阅读次数。
资源时新度Recentness:
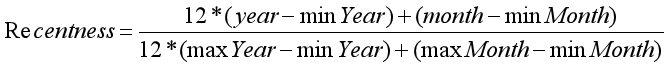
year和month为该资源发布年份和月份,minYear和maxYear为数据路中最早和最晚发表的年份。
所以,资源质量值Quality可表示为:
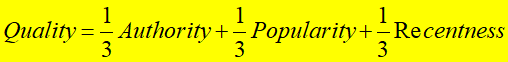
2、学术资源模型表示:Mr={Tr,Kr,Ct,Lr}。
Tr表示学术资源学科分布向量,表示该资源分布在A个学科类别的概率,由贝叶斯多项式模型得到。
Kr={(kr1,ωr1),(kr2,ωr2),...,(krm,ωrm)},m表示关键词个数,kri表示单条学术资源第i个关键词,ωri为关键词kri的权重。
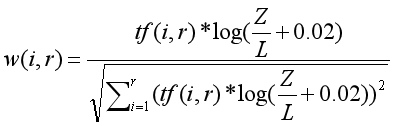
w(i,r)表示第i个关键词的权重,采用了该进后的tf-idf算法,tf(i,r)表示第i个关键词在文档r中出现的频度,Z表示文档及的总篇数,L表示包含关键词i的文档书。
Ct为资源类型,t=1,2,3,4,5,表示五大类学术资源:论文、专利、新闻、会议和图书。
Lr为潜在主题分布向量,Lr={lr1,lr2,...,lrN1},N1是潜在主题数量。
用户兴趣模型表示:Mu={Tu,Ku,Ct,Lu}。
将用户对学术资源的操作行为非为打开、阅读、星级评价、分享和收藏,根据用户不同的浏览行为,结合学术资源模型,构建用户兴趣模型。
Tu是用户学科偏好分布向量:
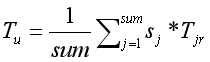
其中,sum为用户行为产生的总学术资源数,sj为用户对学术资源j产生的行为系数,该值越大,表明越喜欢。Tjr表示第j篇资源的学科分布向量。
Ku={(ku1,ωu1),(ku2,ωu2),...,(kuN2,ωuN2)}表示用户关键词偏好分布向量,N2为关键词个数,kui表示第i个用户偏好关键词,ωui为关键词kui的权重。
计算每篇资源新关键词分布向量,再取所有关键词分布项链的TOP-N2作为用户关键词偏好分布向量Ku:
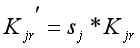
Lu为用户LDA潜在主题偏好分布向量,由学术i资源的LDA潜在主题分布向量Lr={lr1,lr2,...,lrN1}计算得到:
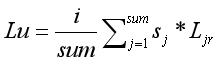
3、计算用户与学科资源相似性:
用户学科偏好分布向量Tu与学术资源学科分布向量Tr的相似度(余弦相似度):
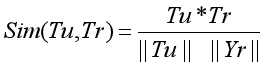
用户LDA潜在主题偏好分布量Lu与学术资源LDA潜在主题分布量Lr的相似度(余弦相似度):
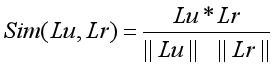
用户关键词拼啊好分布向量Ku与学术资源关键词分布向量Kr相似度(Jaccard Similarity):
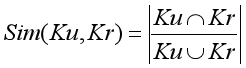
所有,用户兴趣模型与学术资源模型相似度为:
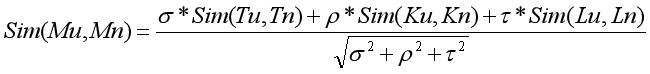
![]() ,具体权重由实验训练得到。
,具体权重由实验训练得到。
4、推荐度Recommendation_degree:
![]()
其中,λ1+λ2=1。
二次推荐便是根据学术资源的推荐度进行Top-N推荐。

另:
相同思路下的两篇论文(中文+英文),师姐使用一样的方法。实验部分数据集为自己构造和使用OPEC图书馆数据集。、
本质上,论文主要分为三个部分:
1、根据学术资源类型、学科分类、关键词分布和LDA主题分布建模学术资源;
2、根据用户历史行为建模用户模型:主要包含学术资源类型、学科偏好、关键词偏好和LDA主题分布偏好。(此外,需要由用户行为,如:收藏、点赞等计算用户行为系数)
最后,分别计算模型相似度,并综合获取用户兴趣得分,并按Top-N方式排列。
注意:筛选的新闻为当天新闻;会议为当天之后举办的会议;其他资源如论文、专利和书籍未用户尚未交互过的资源。
