
在线学习和离线学习
在线学习和离线学习
一、简介
在机器学习领域,可以将学习算法分为离线学习和在线学习两种,需要根据数据选择不同的线性可分和线性不可分的核函数。
二、离线学习
离线学习通常称为批学习,是指对独立的数据进行训练,将训练所得的模型用于预测任务中。将全部数据放入模型中进行计算,一旦出现需要变更的部分,就需要通过再训练(retraining)的方式,如此一来将花费更长的时间,并且将全部数据全部存在服务器上非常占地方,对内存要求很高。离线学习的目标是根据训练样本构造一个分类器,使得真正训练的错误最小化。

离线学习存在的问题:
1、 离线学习需要多次传递训练数据,由于数据量的二次尸检复杂度,导致处理效率太低;
2、离线学习需要分别在训练集和验证集上训练和选择,但在线学习不将训练与选择分离,不分割训练数据;
3、在批量学习设置中,通常假设数据是根据独立同分布设置的,但是在在线学习设置中,对训练数据的假设是宽松的或几乎没有的。
离线学习优点:简单
解决方案:定时重新批量学习,来适应环境的整体变换。
三、在线学习
在线学习也成为增量学习或适应性学习,是指对一定顺序下接收数据,每接收一个数据模型就会对它进行预测并对当前模型进行更新,然后处理下一个数据。这对模型的选择是一个完全不同的,更复杂的问题,需要混合假设更新和对每轮新到达示例的假设评估。换言之,只能访问之前的数据来回答当前的问题。
在在线学习算法中,我们不假设训练数据来自于某个概率分布或者随机过程。当有个训练实例x过来时,利用分类器对其进行分类。假设分类器输出的类别标签为l。那么当l不是实例x真正的类别标签,也即分类出错时,会产生一个罚值。分类器根据实例x的真正的类别标签以及罚值对分类器参数进行相应地调整,以更好地预测新的实例。目标是,在整个预测过程中,实例的罚值和尽可能小。
在下算法对数据的要求更加宽松,因此是更实用的算法。同时,它也是更实用的训练算法。例如,当我们区分一个邮件是否是紧急邮件时,在线算法显得更加合适。
在线算法比离线算法难度更大。事实上,一个好的在线算法可以很容易转换成一个同样好的离线算法,反之则不然。最后还需要指出的是,在线算法有时候在设计和分析上比离线算法更加简洁明了。

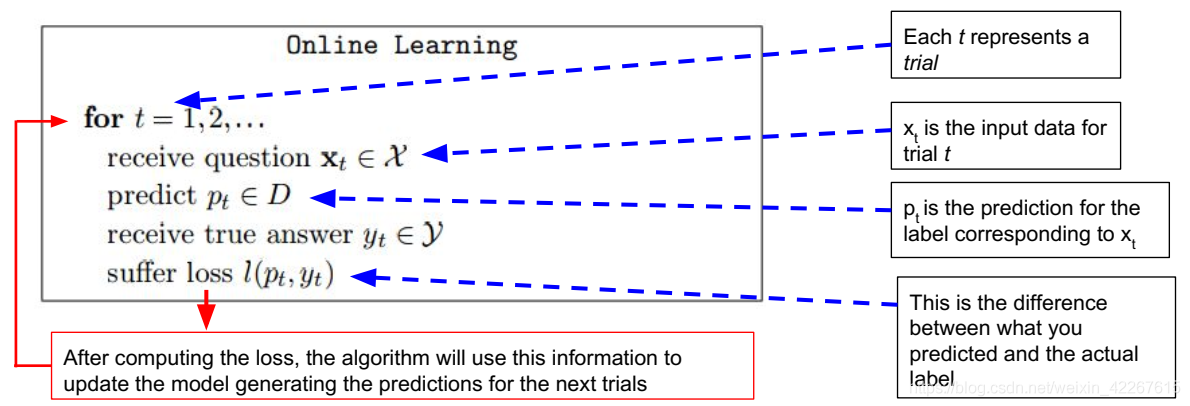
在线学习:
优点:及时反映新的数据环境变换
问题:新的数据会带来不好的变化
解决方案:需要加强对数据的监控,比如异常检测。
适用范围:数据巨大、无法批量学习的环境。
致谢:
1、https://blog.csdn.net/weixin_42267615/article/details/102973252 在线学习和离线学习(详细)
2、https://blog.csdn.net/hedan2013/article/details/78011600 在线学习和离线学习(概括)
3、https://blog.csdn.net/yushiyin1314/article/details/105602285 离线训练和在线训练模式
4、https://www.cnblogs.com/zhangkanghui/p/11241807.html 机器学习的经典算法与应用
5、https://www.cnblogs.com/daiyl0320/articles/3344796.html 在线算法和离线算法的概念

