负载均衡(Load Balance)- periodic load balance
负载均衡(Load balance),是为了将执行task的工作量较平均地配分到每个cpu上,达到功耗和性能平衡的一种机制。比如很多task都只放在cpu0上执行,既不能保证节省功耗(因为负载中,需要提升cpu频率;整体执行时间长),也不能保证task及时执行,从而导致卡顿,且耗电。而有了负载均衡就会触发task迁移,按照一定的规则,将task较合理地分配给每个cpu,既能保证功耗,也可以提升性能。
负载均衡主要的操作是以下2种:
1、pull:负载轻的CPU,从负载繁重的CPU pull tasks来。这是主要的load balance方式,因为不该让负载本身就繁重的CPU执行负载均衡任务。
2、push:负载重的CPU,向负载轻的CPU。这种操作也叫做active load balance。
负载均衡,在不同的情况下,大致分以下几种:
busy balance(periodic balance):cpu上有task运行,是否需要做load balance。
idle balance:指cpu已经进入idle状态,在tick时做的load balance。如果是NO HZ的话,会尝试做nohz idle balance。
newly idle balance:CPU上没有可运行的task,准备进入idle 的状态。在这种情况下,scheduler会尝试从别的CPU上pull一些进程过来运行。
active load balance:在尝试load balance几次失败后,根据条件判断进行active balance。会从负载重的cpu,向负载轻的cpu,推送(push)task。(执行push的是running的task)
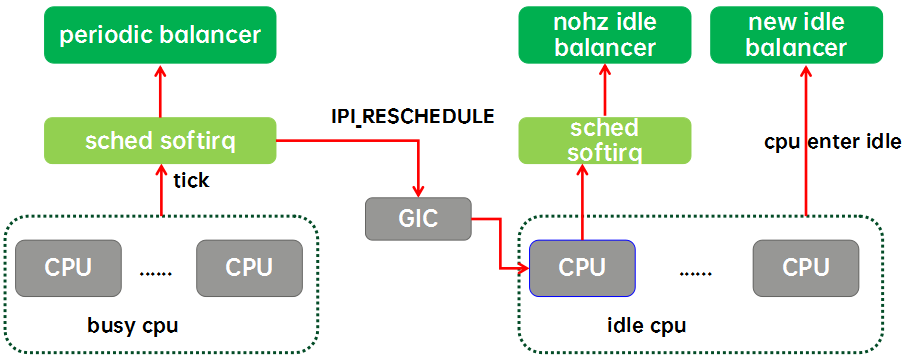
nohz idle balance:检查当前CPU是否负载过高等等情况,是否需要唤醒一个idle CPU让其pull 一些进程过去,分担一下负载压力。唤醒会通过IPI_RESCHEDULE 让 idle cpu退出power collapse。
本来打算一篇文章把所有触发的各种balance都写完,但是发现内容有点多,所以需要拆分一下。目前这篇先主要分析在定时调度触发的load balance(periodic)及其相关调用流程。 其余后续再补充。
本文代码基于CAF-kernel-4.19和CAF-kernel-5.4。由于目前由于理解还不熟,不免有错误之处,烦请指正。
Periodic Load Balance
在scheduler_tick中,会周期性检查和触发load balance:
scheduler_tick() { 。。。 #ifdef CONFIG_SMP rq->idle_balance = idle_cpu(cpu); trigger_load_balance(rq); //触发load balance #endif 。。。 }
在 trigger_load_balance() 中,会触发一个SOFTIRQ。之后的 nohz_balancer_kick()函数为nohz idle balance工作,后面再分析。
/* * Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing. */ void trigger_load_balance(struct rq *rq) { /* Don't need to rebalance while attached to NULL domain or * cpu is isolated. */ if (unlikely(on_null_domain(rq)) || cpu_isolated(cpu_of(rq))) return; if (time_after_eq(jiffies, rq->next_balance)) raise_softirq(SCHED_SOFTIRQ); //触发SOFTIRQ中断 nohz_balancer_kick(rq); //属于nohz idle balance,暂不分析 }
那么 softirq 触发之后,会调用到哪里呢?首先看这个 SOFTIRQ 注册的地方,在fair调度class初始化的时候,有对 SOFTIRQ 中断进行注册,实际会触发run_rebalance_domains()函数。
__init void init_sched_fair_class(void) { #ifdef CONFIG_SMP open_softirq(SCHED_SOFTIRQ, run_rebalance_domains); //注册SOFTIRQ中断处理 #ifdef CONFIG_NO_HZ_COMMON nohz.next_balance = jiffies; nohz.next_blocked = jiffies; zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT); #endif #endif /* SMP */ }
所以触发SOFTIRQ后,就会调用处理函数run_rebalance_domains()。
/* * run_rebalance_domains is triggered when needed from the scheduler tick. * Also triggered for nohz idle balancing (with nohz_balancing_kick set). */ static __latent_entropy void run_rebalance_domains(struct softirq_action *h) { struct rq *this_rq = this_rq(); enum cpu_idle_type idle = this_rq->idle_balance ? CPU_IDLE : CPU_NOT_IDLE; /* * Since core isolation doesn't update nohz.idle_cpus_mask, there * is a possibility this nohz kicked cpu could be isolated. Hence * return if the cpu is isolated. */ if (cpu_isolated(this_rq->cpu)) //过滤已经isolate的cpu return; /* * If this CPU has a pending nohz_balance_kick, then do the * balancing on behalf of the other idle CPUs whose ticks are * stopped. Do nohz_idle_balance *before* rebalance_domains to * give the idle CPUs a chance to load balance. Else we may * load balance only within the local sched_domain hierarchy * and abort nohz_idle_balance altogether if we pull some load. */ if (nohz_idle_balance(this_rq, idle)) //为已经进入idle的所有cpu进行负载均衡,因为idle cpu的调度tick已经停止了。(这块后面分析) return; //同时,可以在做调度域均衡前,先给idle cpu进行负载均衡;否则我们仅仅会在所在的调度域这一层内完成负载均衡,如果我们pull出来一些load的话,也会中止nohz_idle_balance。 /* normal load balance */ update_blocked_averages(this_rq->cpu); //计算当前cpu rq及其中各层cfs rq的相关负载load rebalance_domains(this_rq, idle); //(1)检查各层sd是否要进行load balance }
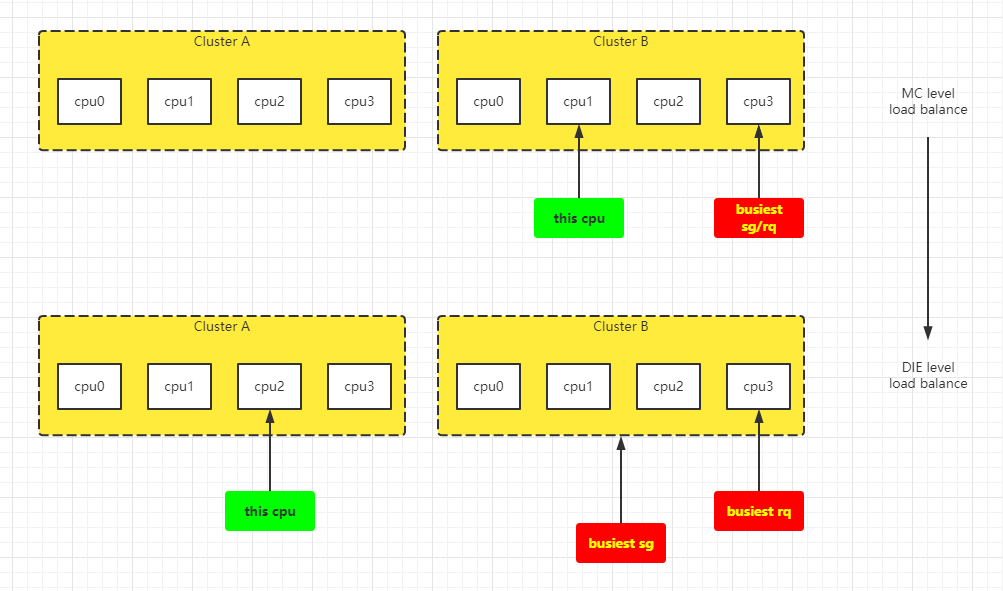
(1)在 rebalance_doamins() 中,遍历当前cpu的sd(从当前sd到sd->parent),并且:
1.对每层sd的newidle_lb_cost进行老化,按照1%/s(每秒衰减1%)的速度。并且把所有sd的值都累加起来,作为rq的newidle_lb_cost,但是它有最小值限制,不会低于50ms。(暂时还不知道newidle_lb_cost这个有什么用??)
2. 对每一层sd判断是否需要进行load balance,并根据结果启动balance动作。遍历顺序:MC->DIE
3. 每个rq级别balance检查间隔,默认为 60s。如果sd的下次检查balance的时间,早于rq的检查时间,那么就会将rq的检查时间对齐到sd的检查时间。(也就是说,sd如果更早,那么rq也要跟着改到与sd一样的时刻检查)
4. 每个sd检查间隔为:sd->last_balance + sd->balance_interval(越高层的domain,间隔时间越大,因为迁移task的代价越大;)
5. 有一些情况会跳过当前sd的load balance检查:
---sd没有overutil,并且没有设置perfer spread idle(没有overutil表示系统没有出现严重过载;prefer spread idle是一个qcom feature,打开后会让task自由地迁移到当前cluster内的idle cpu上,以达到runnable task数量平均)
---sd->flags中没有设置SD_LOAD_BALANCE(表示没有load balance需求)
---continue_balance标志为0(表示sd中其他cpu的load balance更活跃,无需做重复操作)
6. 根据需要,判断是否更新rq的下次balance时间;同时判断:如果当前cpu为idle状态,并且nohz.next_balance晚于rq->next_balance,满足则同时更新nohz.next_balance = rq->next_balance
/* * It checks each scheduling domain to see if it is due to be balanced, * and initiates a balancing operation if so. * * Balancing parameters are set up in init_sched_domains. */ static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle) { int continue_balancing = 1; int cpu = rq->cpu; unsigned long interval; struct sched_domain *sd; /* Earliest time when we have to do rebalance again */ unsigned long next_balance = jiffies + 60*HZ; //下次做负载均衡的deadline,当前时间往后60s int update_next_balance = 0; int need_serialize, need_decay = 0; u64 max_cost = 0; rcu_read_lock(); for_each_domain(cpu, sd) { //遍历当前cpu所在的domain,并向上(parent)遍历domain /* * Decay the newidle max times here because this is a regular * visit to all the domains. Decay ~1% per second. */ if (time_after(jiffies, sd->next_decay_max_lb_cost)) { //对max_newidle_lb_cost每一秒衰减1%:max_newidle_lb_cost*253/256 sd->max_newidle_lb_cost = (sd->max_newidle_lb_cost * 253) / 256; sd->next_decay_max_lb_cost = jiffies + HZ; //HZ表示1s need_decay = 1; } max_cost += sd->max_newidle_lb_cost; //统计所有domain的cost之和 if (!sd_overutilized(sd) && !prefer_spread_on_idle(cpu)) //调度域没有overutil 并且 没有prefer spread on idle,那么直接continue,不需要进行load balance操作 continue; if (!(sd->flags & SD_LOAD_BALANCE)) //没有设置SD_LOAD_BALANCE flag,则表示不需要做load balance操作,当前平台MC、DIE level都有这个flag continue; /* * Stop the load balance at this level. There is another * CPU in our sched group which is doing load balancing more * actively. */ if (!continue_balancing) { //如果continue_balancing == 0,则要停止当前层的load balance操作,因为在sched group中已经有其他cpu在执行load balance操作了 if (need_decay) continue; break; } interval = get_sd_balance_interval(sd, idle != CPU_IDLE); //获取当前调度域load balance所需的时间。越高层的domain,间隔时间越大,因为迁移task的代价越大。 need_serialize = sd->flags & SD_SERIALIZE; //是否要串行化执行load balance,NUMA架构才有带有这个flag,所以这里为0 if (need_serialize) { if (!spin_trylock(&balancing)) goto out; } if (time_after_eq(jiffies, sd->last_balance + interval)) { //时间间隔满足当前调度域的间隔要求后,做实际load balance动作 if (load_balance(cpu, rq, sd, idle, &continue_balancing)) { //(2)load balance核心函数 /* * The LBF_DST_PINNED logic could have changed //遇到dst cpu被拴住(原因可能是cpuset)的情况, * env->dst_cpu, so we can't know our idle //可能会改变env->dst_cpu(会寻找new dst cpu), * state even if we migrated tasks. Update it. //所以我们丢失了当前cpu的idle状态,需要重新获取 */ idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE; //重新更新cpu idle状态 } sd->last_balance = jiffies; //更新load balance的时间戳 interval = get_sd_balance_interval(sd, idle != CPU_IDLE); //获取sd中balance间隔(在load balance中被tune过;如果sd内任一cpu有misfit task,则间隔强制写为1个jiffies == 1个tick) } if (need_serialize) //如上面设置了需要串行执行load balance spin_unlock(&balancing); //则这里就要释放锁 out: if (time_after(next_balance, sd->last_balance + interval)) { //如果sd下一次balance时间在,rq的balance时间之前, 【rq下次执行load balance的时间:next_balance(默认是60s)】 next_balance = sd->last_balance + interval; //那么就需要更新rq下次balance时间,对齐到sd下一次balance时间 【调度域下次执行load balance的时间:sd->last_balance + interval】 update_next_balance = 1; //最终rq下次balance时间会对齐到,多个rq中最近的balance时间 } } if (need_decay) { /* * Ensure the rq-wide value also decays but keep it at a //rq上的值会老化,但是要保证值在一个合理的范围内, * reasonable floor to avoid funnies with rq->avg_idle. //需要有一个最低值限制,以免与rq->avg_idle不匹配,出现笑话 */ rq->max_idle_balance_cost = max((u64)sysctl_sched_migration_cost, max_cost); //max_idle_balance_cost最小值不能低于sysctl_sched_migration_cost(50ms) } rcu_read_unlock(); /* * next_balance will be updated only when there is a need. * When the cpu is attached to null domain for ex, it will not be * updated. */ if (likely(update_next_balance)) { rq->next_balance = next_balance; //更新rq的下次balance时间 #ifdef CONFIG_NO_HZ_COMMON /* * If this CPU has been elected to perform the nohz idle //如果当前cpu被选择做nohz idle balance * balance. Other idle CPUs have already rebalanced with //那么其他idle cpu已经通过nohz_idle_balance()进行了balance和更新nohz.next_balance时间戳 * nohz_idle_balance() and nohz.next_balance has been * updated accordingly. This CPU is now running the idle load //当前cpu正在为自己运行idle load balance * balance for itself and we need to update the //我们应该相应地更新nohz.next_balance时间戳 * nohz.next_balance accordingly. */ if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance)) //如果当前cpu为idle状态,并且nohz.next_balance晚于rq->next_balance nohz.next_balance = rq->next_balance; //更新nohz的下次balance时间 #endif } }
(2)load_balance函数
主要框架:
执行流程示意图:
代码流程:
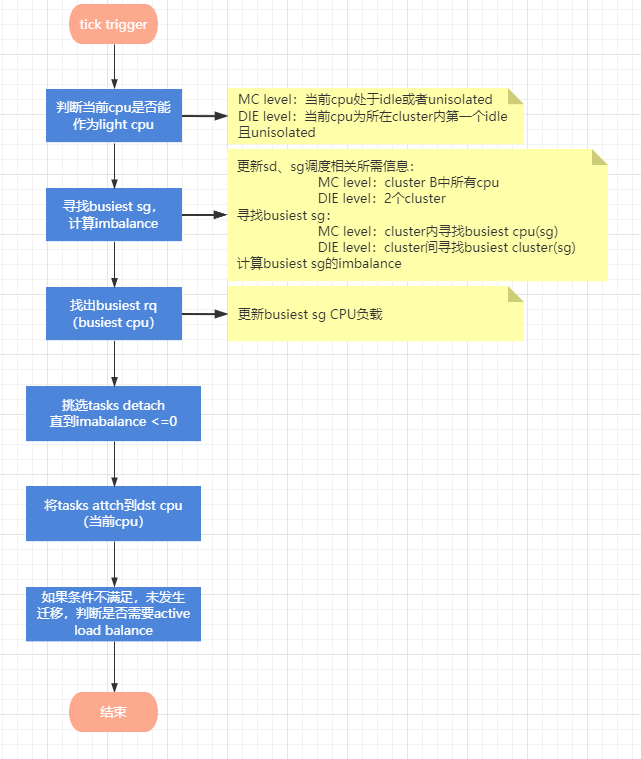
1. 初始化load balance env结构体:其中就是将当前的cpu作为light cpu(dst cpu),为loading重的cpu分担一些任务。确定load balance的调度组范围。
在调度域中的cpu;2、并且也是active的cpu,两者的交集作为env->cpus
redo:(一般这里会重新选择src cpu,即busiest)
2. 判断当前cpu作为dst cpu,是否符合条件做负载均衡 ----should_we_balance();不满足,则goto out_balanced
3. 找到最繁忙的group,并计算出不平衡值imbalance ----find_busiest_group();未找到busiest group,则goto out_balanced
4. 从busiest group中找到busiest rq(即 cpu rq)----find_busiest_queue(),未找到busiest rq,则goto out_balanced
5. 初始化记录迁移的task数量ld_moved = 0
6. 判断busiest rq上是否有超过1个task:
-
- 如果有>1个task
- 初始化flags,限制单次load balance只能遍历32个task
- 如果有>1个task
more_balance:
-
-
- 判断是否不满足条件做balance了?busiest rq上task <=1 或是 task <=2但在active balance,满足则清掉flag:LBF_ALL_PINNED,然后goto no_move
- 更新busiest rq的clock时间信息
- 进行迁移detach操作,从busiest rq剥离要迁移的task
- 将迁移的task attach到dst rq上,并记录本次负载均衡,总的迁移task的数量
- 判断env.flags是否有LBF_NEED_BREAK(该flag表示一次性detach检查的task数量超过了门限,且还没有抹平imbalance),清掉flag:LBF_NEED_BREAK,然后goto more_balance
- 如果出现过由于cpuset限制了dst cpu,并重新选择了dst cpu,而且不平衡仍然存在:使用new dst cpu作为dst cpu,goto more_balance,重新检查detach和attach
- 如果由于cpu亲和度导致不能达到平衡,则设置parent sd的sg type为group_imbalanced,相当于将不平衡传递上去 如果因为cpu亲和度,而导致所有task都不能迁移到dst cpu:
- 则去掉当前dst cpu,判断如果剩下的cpus不在dst cpu所在group内,那还有可能作为busiest,那么goto redo,重新选择busiest
- 如果剩下cpus没有作为busiest的可能了,那么goto out_all_pinned
-
no_move:
-
- 如果到这里迁移的task总数(ld_moved)仍为0
- 统计periodic balance情况下balance 失败的计数
- 判断是否需要active load balance(更激进的balance,从busiest cpu push task出去)
- 如果src cpu或者busiest cpu被标记为reserved了,那就不能进行balance了,goto out
- 如果busiest 的curr进程被cpuset限制而不能迁移到当前cpu;或者busiest上的curr进程是开了boost strcit max,并且在rtg内,并且dst cpu的orig_capacity < src cpu的orig_capacity。则设置env.flags |= LBF_ALL_PINNED,goto out_one_pinned
- 如果busiest不在做active balance,并且busiest cpu不处于isolate。那就设置busiest正在做active balance的标记:busiest->active_balance = 1;再指定push task的dst cpu为当前cpu;标记接下来要唤醒active balance进程(active_balance = 1);并将当前cpu标记为reserved
- 判断是否要唤醒active balance进程(active_balance 是否为 1)
- 满足,则开启busiest上的active_load_balance的工作队列(函数active_load_balance_cpu_stop,其是stop class的进程),设置不需要继续load balance标记:*continue_balancing = 0。-----active load balance主要是对running进程进行迁移,后续再写blog补充,这里不再详述。
- 走到这里,说明我们已经触发了active balance。那就设置当前sd balance失败计数改为cache_nice_tries + 10 -1
- 如果有迁移过task(ld_moved不为0),则清零balance失败的计数
- 如果到这里迁移的task总数(ld_moved)仍为0
7. 如果没触发active load balance,或者没有触发到主动active balance
-
- 上述条件满足,则说明现在还是处于不平衡状态。那就要将触发balance的间隔缩短到最小:sd->min_interval
- 如果条件不满足,说明已经触发了active balance了。如果触发balance间隔 < sd->max_interval,那就再将间隔放大到2倍(*2)
8. goto out
out_balanced:
9. 判断当前是在MC level,并不是所有task都不能迁移的情况(即,尽管遇到了一些亲和度冲突,但是最终还是达到平衡了),则清掉parent sd的imbalance flag:group_imbalance = 0
out_all_pinned:
10. 因为在当前这个level,所有task都被亲和度绑定了,所以我们无法迁移它们。则保留parent sd的imbalance flag。这里会顺便统计负载均衡的次数(以当前cpu idle状态区分统计)。同时,清零balance失败的计数。
out_one_pinned:
11. 这里会清零总迁移task的计数ld_moved = 0
12. 如果是newly idle的情况,直接goto out
13. 如果出现所有task都由于亲和度都无法迁移,且做balance的间隔时间 < MAX_PINNED_INTERVAL(512);或者做balance的间隔时间 < sd->max_interval。那么就把间隔再放大一倍(*2)
out:
14. return ld_moved,即本次balance总迁移task数;但如果出现了某些异常情况,就return 0。
/* * Check this_cpu to ensure it is balanced within domain. Attempt to move * tasks if there is an imbalance. */ static int load_balance(int this_cpu, struct rq *this_rq, struct sched_domain *sd, enum cpu_idle_type idle, int *continue_balancing) { int ld_moved = 0, cur_ld_moved, active_balance = 0; struct sched_domain *sd_parent = sd->parent; struct sched_group *group = NULL; struct rq *busiest = NULL; struct rq_flags rf; struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask); //这里是唯一使用该mask的地方,边使用边赋值,一个per-cpu变量。用于确定env->cpus struct lb_env env = { //填充load balance所需结构体 .sd = sd, //调度域为当前sd .dst_cpu = this_cpu, //task迁移的目标cpu为当前cpu .dst_rq = this_rq, //task迁移的目标rq为当前cpu rq .dst_grpmask = sched_group_span(sd->groups), //获取要做load balance sd对应的sg范围 .idle = idle, //task迁移的目标cpu(即当前cpu),它的idle状态 .loop_break = sched_nr_migrate_break, .cpus = cpus, .fbq_type = all, .tasks = LIST_HEAD_INIT(env.tasks), //初始化链表,后续要迁移的task会放进这个链表中 .imbalance = 0, .flags = 0, .loop = 0, }; //prefer_spread设置: env.prefer_spread = (prefer_spread_on_idle(this_cpu) && //当前cpu的prefer spread idle是否设置,并且 下面条件不成立: !((sd->flags & SD_ASYM_CPUCAPACITY) && //有SD_ASYM_CPUCAPACITY,且 当前cpu不在asym_cap_sibling_cpus范围内 !cpumask_test_cpu(this_cpu, &asym_cap_sibling_cpus))); cpumask_and(cpus, sched_domain_span(sd), cpu_active_mask); //取出1、在调度域中的cpu;2、并且也是active的cpu,两者的交集作为env->cpus schedstat_inc(sd->lb_count[idle]); //统计sd->lb_count[idle]++ redo: if (!should_we_balance(&env)) { //(2-1)判断目标cpu是否可以作为light cpu进行load balance(light cpu说明任务较少,会从任务较重的cpu上pull任务过来) *continue_balancing = 0; goto out_balanced; //不满足条件的话,就清空continue_balancing = 0,跳过迁移过程 } group = find_busiest_group(&env); //(2-2)如果存在不均衡,那么就找到调度域中,本层级sched_group链表负载最重的(busiest)的sched_group:busiest的group。同时计算出负载均衡所需迁移的load if (!group) { schedstat_inc(sd->lb_nobusyg[idle]); //如果没有找到busiest group,那就统计调度数据,之后退出 goto out_balanced; } busiest = find_busiest_queue(&env, group); //(2-3)找出busiest sched_group中,即负载最重cpu对应的rq if (!busiest) { schedstat_inc(sd->lb_nobusyq[idle]); goto out_balanced; } BUG_ON(busiest == env.dst_rq); //如果迁移目标cpu rq是busiest的话,那就出问题了! schedstat_add(sd->lb_imbalance[idle], env.imbalance); //累计统计不同idle状态下进程调度数据:env.imbalance 不平衡值 env.src_cpu = busiest->cpu; //将上面复杂流程找到的迁移的src cpu和对应src rq,填进env结构体中 env.src_rq = busiest; ld_moved = 0; if (busiest->nr_running > 1) { //判断是否有task可以进行迁移,至少要有1个task /* * Attempt to move tasks. If find_busiest_group has found //尝试迁移task * an imbalance but busiest->nr_running <= 1, the group is //如果find_busiest_group函数找到了不平衡,但是busiest->nr_running <= 1,那这个group还是不平衡的 * still unbalanced. ld_moved simply stays zero, so it is //ld_moved仍保持0,所这种情况当作不平衡是正确的 * correctly treated as an imbalance. */ env.flags |= LBF_ALL_PINNED; //初始化flag,初始状态为:dst cpu上所有task都由于cpu亲和度拴住了,无法迁移 env.loop_max = min(sysctl_sched_nr_migrate, busiest->nr_running); //限制一次load balance遍历task的数量最大不超过32个,因为这个期间是关中断的 more_balance: rq_lock_irqsave(busiest, &rf); /* * The world might have changed. Validate assumptions. //代码运行到这里时,有时状态已经发生了变化,所以需要再check: * And also, if the busiest cpu is undergoing active_balance, //如果busiest cpu在做active balance,但是它的rq上只有 <= 2个task * it doesn't need help if it has less than 2 tasks on it. //那么它不需要进行迁移 */ if (busiest->nr_running <= 1 || //busiest rq只有1个task或没有task (busiest->active_balance && busiest->nr_running <= 2)) { //或者 (busiest rq处于active balance状态 并且 rq有<=2个task) rq_unlock_irqrestore(busiest, &rf); env.flags &= ~LBF_ALL_PINNED; //清flag:LBF_ALL_PINNED goto no_move; //退出,不进行迁移 no_move } update_rq_clock(busiest); //更新busiest rq的clock时间信息 /* * cur_ld_moved - load moved in current iteration //cur_ld_moved:便是本次balance中一次迁移操作的load(task数量) * ld_moved - cumulative load moved across iterations //ld_moved:表示累计本次balance多次迁移,并已经迁移了的总load(总task数量) */ cur_ld_moved = detach_tasks(&env); //(2-4)进行迁移detach操作,从原rq脱离,返回的是迁移的task数量 /* * We've detached some tasks from busiest_rq. Every //我们已经从busest rq上detach了一些task * task is masked "TASK_ON_RQ_MIGRATING", so we can safely //每一个task都标记为:TASK_ON_RQ_MIGRATING * unlock busiest->lock, and we are able to be sure //所以,我们可以安全地进行unlock busiest->lock * that nobody can manipulate the tasks in parallel. //同时,我们可以保证没有人能并行地篡改它 * See task_rq_lock() family for the details. */ rq_unlock(busiest, &rf); if (cur_ld_moved) { //如果有task detach了,那么就需要进行attach到dst cpu上,完成迁移 attach_tasks(&env); //(2-5)将所有task attach到新的rq上 ld_moved += cur_ld_moved; //累加当前完成task迁移的数量,统计总迁移task数 } local_irq_restore(rf.flags); if (env.flags & LBF_NEED_BREAK) { //上面在detach时,loop超过一定门限,就会设置该flag。目前平台该门限设置与loop限制的最大次数相同,所以相当于没有break env.flags &= ~LBF_NEED_BREAK; goto more_balance; } /* * Revisit (affine) tasks on src_cpu that couldn't be moved to //重新再检查src cpu上的那些不能迁移的task, * us and move them to an alternate dst_cpu in our sched_group //将他们迁移到所在调度组内的其他可选dst cpu上, * where they can run. The upper limit on how many times we //在同一个src cpu轮询的次数上限取决于调度组内cpu个数 * iterate on same src_cpu is dependent on number of CPUs in our * sched_group. * * This changes load balance semantics a bit on who can move //这就把load balance搞得有点像:把load迁移到一个given cpu上。 * load to a given_cpu. In addition to the given_cpu itself //加上given cpu其本身(或者是一个兄弟cpu[lib_cpu]代表given cpu,因为given cpu在nohz-idle), * (or a ilb_cpu acting on its behalf where given_cpu is //那么我们现在就是将balance_cpu的load迁移到given cpu上。 * nohz-idle), we now have balance_cpu in a position to move * load to given_cpu. In rare situations, this may cause //在一些较少发生情况下,这可能导致冲突(balance cpu 和 given cpu/ilb_cpu互相是独立挑选出来的, * conflicts (balance_cpu and given_cpu/ilb_cpu deciding //并且也可能在同一时刻触发迁移load到given cpu),从而导致load一下子迁移到given cpu太多 * _independently_ and at _same_ time to move some load to * given_cpu) causing exceess load to be moved to given_cpu. * This however should not happen so much in practice and //但是,这不应该经常发生,并且后续的load balance操作也会纠正这些迁移过多的load。 * moreover subsequent load balance cycles should correct the * excess load moved. */ if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) { //如果出现过由于cpuset限制了dst cpu,并重新选择了dst cpu,而且不平衡仍然存在:使用new dst cpu作为dst cpu重新检查detach和attach /* Prevent to re-select dst_cpu via env's CPUs */ cpumask_clear_cpu(env.dst_cpu, env.cpus); //防止重新又选到不满足cpuset条件的cpu作为dst cpu,这里将cpuset限制的dst cpu从env.cpus中去除 env.dst_rq = cpu_rq(env.new_dst_cpu); //将new dst cpu改为dst cpu,相应rq也改为dst rq env.dst_cpu = env.new_dst_cpu; env.flags &= ~LBF_DST_PINNED; //去掉flag:LBF_DST_PINNED env.loop = 0; //重置loop env.loop_break = sched_nr_migrate_break; /* * Go back to "more_balance" rather than "redo" since we //跳转到more balance,因为src cpu没有发生改变 * need to continue with same src_cpu. */ goto more_balance; } /* * We failed to reach balance because of affinity. //由于cpuset亲和度导致无法达到负载balance */ if (sd_parent) { //如果当前sd是MC level int *group_imbalance = &sd_parent->groups->sgc->imbalance; if ((env.flags & LBF_SOME_PINNED) && env.imbalance > 0) //如果有因cpuset而遗留imbalance的 *group_imbalance = 1; //则设置当前sd的parent sd的 sgc->imbalance,让parent sd做rebalance的概率增高:*group_imbalance = 1 } /* All tasks on this runqueue were pinned by CPU affinity */ if (unlikely(env.flags & LBF_ALL_PINNED)) { //如果dst cpu上所有task都由于cpu亲和度拴住了,无法迁移(flag:LBF_ALL_PINNED) cpumask_clear_cpu(cpu_of(busiest), cpus); //将busiest rq对应的cpu,从cpus集合中去掉 /* * Attempting to continue load balancing at the current //仅当还有剩余的active cpu可能作为busiest cpu,且被pull load的busiest cpu不被包含在接收迁移load的dst group中 * sched_domain level only makes sense if there are * active CPUs remaining as possible busiest CPUs to //尝试继续在当前调度域level进行load balance * pull load from which are not contained within the * destination group that is receiving any migrated * load. */ if (!cpumask_subset(cpus, env.dst_grpmask)) { //如果剩余的cpus都不在dst cpu的调度域中 env.loop = 0; //则重置loop env.loop_break = sched_nr_migrate_break; goto redo; //重新进行是否需要load balance } goto out_all_pinned; } } no_move: if (!ld_moved) { //经过几轮的努力尝试,最终迁移的进程数ld_moved还是0,说明balance失败 /* * Increment the failure counter only on periodic balance. //仅在周期性balance时,累计失败次数。 * We do not want newidle balance, which can be very //我们不想统计newidle balance,它会非常频繁,破坏失败计数, * frequent, pollute the failure counter causing //从而导致激进的cache-hot迁移和active balance * excessive cache_hot migrations and active balances. */ if (idle != CPU_NEWLY_IDLE) { //如果不是newly idle if (env.src_grp_nr_running > 1) //并且src group中的nr_running > 1 sd->nr_balance_failed++; //则统计失败次数 } if (need_active_balance(&env)) { //(2-6)判断是否需要active balance unsigned long flags; raw_spin_lock_irqsave(&busiest->lock, flags); /* * The CPUs are marked as reserved if tasks //cpu中task从其他cpu上pull/push的,这样的cpu会被标记为reserved * are pushed/pulled from other CPUs. In that case, //在这个情况下,就要退出load balance * bail out from the load balancer. */ if (is_reserved(this_cpu) || //当前this cpu是reserved的 is_reserved(cpu_of(busiest))) { //或者busiest cpu是reserved的 raw_spin_unlock_irqrestore(&busiest->lock, flags); *continue_balancing = 0; //那么就要退出load balance,清除flag:*continue_balancing = 0 goto out; } /* * Don't kick the active_load_balance_cpu_stop, //如果在busiest cpu上的curr进程不能迁移到当前cpu(this cpu)上, * if the curr task on busiest CPU can't be //不要触发active_load_balance_cpu_stop * moved to this_cpu: */ if (!cpumask_test_cpu(this_cpu, //this_cpu不在busiest的curr进程的cpuset内 &busiest->curr->cpus_allowed) || !can_migrate_boosted_task(busiest->curr, //或者busiest上的curr进程是开了boost strcit max,并且在rtg内,并且dst cpu的orig_capacity < src cpu的orig_capacity cpu_of(busiest), this_cpu)) { //从而导致不能迁移busiest上的curr进程 raw_spin_unlock_irqrestore(&busiest->lock, flags); env.flags |= LBF_ALL_PINNED; //则设置flag:env.flags |= LBF_ALL_PINNED goto out_one_pinned; } /* * ->active_balance synchronizes accesses to //active_balance标记是与active_balance_work同步的 * ->active_balance_work. Once set, it's cleared //标记只在active load balance完成之后会清除 * only after active load balance is finished. */ if (!busiest->active_balance && //busiest没有处于active balance状态 !cpu_isolated(cpu_of(busiest))) { //并且busiest rq的cpu没有isolate busiest->active_balance = 1; //那么就标记busiest rq的状态为active balance busiest->push_cpu = this_cpu; //push cpu为当前cpu(this_cpu) active_balance = 1; //同时标记active_balance =1,表示active_balance work开始 mark_reserved(this_cpu); //标记this cpu为reserved } raw_spin_unlock_irqrestore(&busiest->lock, flags); if (active_balance) { stop_one_cpu_nowait(cpu_of(busiest), //开启active_load_balance work的工作队列(这个进程调度类是stop class) active_load_balance_cpu_stop, busiest, //工作函数为:active_load_balance_cpu_stop &busiest->active_balance_work); *continue_balancing = 0; } /* We've kicked active balancing, force task migration. */ //已经触发active balance,并强制执行task迁移 sd->nr_balance_failed = sd->cache_nice_tries + //把balance失败计数改为cache_nice_tries + 10 -1 NEED_ACTIVE_BALANCE_THRESHOLD - 1; } } else sd->nr_balance_failed = 0; //load balance成功发生迁移的话,清空失败计数 if (likely(!active_balance)) { //没有触发active balance 或者active balance完成了 /* We were unbalanced, so reset the balancing interval */ sd->balance_interval = sd->min_interval; //重置balance间隔时间为min_interval } else { /* * If we've begun active balancing, start to back off. This //如果我们正在进行active balance,那么就要将间隔搞大点 * case may not be covered by the all_pinned logic if there * is only 1 task on the busy runqueue (because we don't call * detach_tasks). */ if (sd->balance_interval < sd->max_interval) //balance间隔 < max_interval sd->balance_interval *= 2; //则将balance间隔放大成2倍 } goto out; out_balanced: /* * We reach balance although we may have faced some affinity //尽管我们遇到了一些cpu亲和度的限制,但我们已经达到balance了 * constraints. Clear the imbalance flag only if other tasks got //只有当其他task有机会迁移或者解决不平衡,才可以清空不平衡的flag * a chance to move and fix the imbalance. */ if (sd_parent && !(env.flags & LBF_ALL_PINNED)) { //当前调度域并非root doamin,并且flag !=LBF_ALL_PINNED(cpuset仅限制了部分,或没有限制) int *group_imbalance = &sd_parent->groups->sgc->imbalance; if (*group_imbalance) //如果有group不平衡标记 *group_imbalance = 0; //清空group不平衡标记 } out_all_pinned: /* * We reach balance because all tasks are pinned at this level so //由于所有task都被拴住了,无法进行task迁移,所以这个level无法达到真正平衡 * we can't migrate them. Let the imbalance flag set so parent level //让保留不平衡flag,让parent level尝试迁移 * can try to migrate them. */ schedstat_inc(sd->lb_balanced[idle]); //统计load balance计数 sd->nr_balance_failed = 0; //清空load balance失败计数 out_one_pinned: /* tune up the balancing interval */ //把balance间隔放大一些(个人猜测为了延后一段时间,再重新尝试load balance ) if (((env.flags & LBF_ALL_PINNED) && //1. 如果flag有LBF_ALL_PINNED 并且balance间隔 < MAX_PINNED_INTERVAL(512) sd->balance_interval < MAX_PINNED_INTERVAL) || (sd->balance_interval < sd->max_interval)) //2. balance间隔 < max_interval sd->balance_interval *= 2; //将balance间隔放大为2倍(上面条件满足其一) ld_moved = 0; //清空task迁移计数 out: trace_sched_load_balance(this_cpu, idle, *continue_balancing, group ? group->cpumask[0] : 0, busiest ? busiest->nr_running : 0, env.imbalance, env.flags, ld_moved, sd->balance_interval, active_balance, sd_overutilized(sd), env.prefer_spread); return ld_moved; }
(2-1)判断dst cpu(其实就是当前cpu)是否可以作为light cpu进行load balance(light cpu说明任务较少,会从任务较重的cpu上pull任务过来)
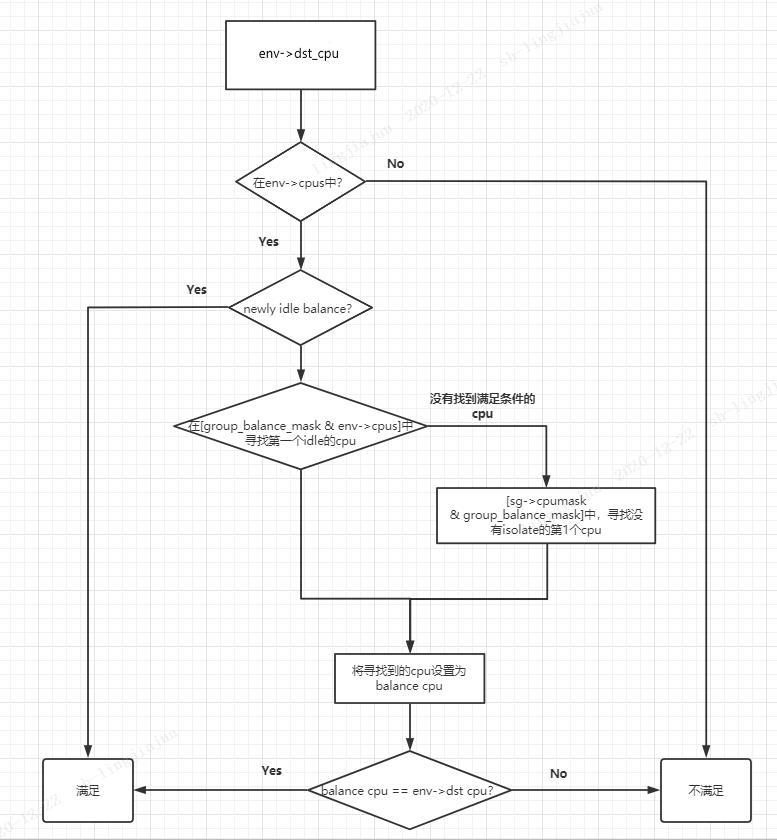
其中,
group_balance_mask(sg)获取的是:sg->sgc->cpumask(sg为发生负载均衡的sd对应的sg)。根据不同level,会代表不同的cpu(获取的是:sg->cpumask)。如果是MC level,则是当前cpu(比如cpu 0,就是0x1);如果是DIE level,则是当前cluster内的所有cpu core(比如cluster-0内的cpu 0 - 4,就是0x0F)。
group_balance_cpu_not_isolated(sg)其实是sched_group_span(sg)和group_balance_mask(sg)的交集(这2者其实是一致的),并且不处于isolate的第1个cpu。sched_group_span(sg):根据不同level,会代表不同的cpu(获取的是:sg->cpumask)。如果是MC level,则是当前cpu(比如cpu 0,就是0x1);如果是DIE level,则是当前cluster内的所有cpu core(比如cluster-0内的cpu 0 - 4,就是0x0F)。这个与上面的sg->sgc->cpumask一样。
static int should_we_balance(struct lb_env *env) { struct sched_group *sg = env->sd->groups; int cpu, balance_cpu = -1; /* * Ensure the balancing environment is consistent; can happen * when the softirq triggers 'during' hotplug. */ if (!cpumask_test_cpu(env->dst_cpu, env->cpus)) //检测目标cpu是否同时满足cpus的条件:1、在env-sd调度域中;2、cpu处于active return 0; /* * In the newly idle case, we will allow all the CPUs * to do the newly idle load balance. */ if (env->idle == CPU_NEWLY_IDLE) //如果是new idle load balance,那么允许所有env->cpus做newly idle load balance return 1; /* Try to find first idle CPU */ for_each_cpu_and(cpu, group_balance_mask(sg), env->cpus) { //从sg范围和env->cpus的交集中,找到第一个idle的cpu if (!idle_cpu(cpu) || cpu_isolated(cpu)) continue; balance_cpu = cpu; //将第一个idle cpu标记到balance_cpu break; } if (balance_cpu == -1) //如果没有找到idle cpu,那么就选择sg范围中unisolate的第一个cpu balance_cpu = group_balance_cpu_not_isolated(sg); /* * First idle CPU or the first CPU(busiest) in this sched group * is eligible for doing load balancing at this and above domains. */ return balance_cpu == env->dst_cpu; //第一个idle cpu或者第一个unisolate的cpu是有资格做load balance的 }
(2-2)如果存在不均衡,那么就找到调度域中,本层级sched_group链表负载最重的(busiest)的sched_group:busiest的group。同时计算出负载均衡所需迁移的load
- 初始化sds结构体
- 更新用于load balance的调度域很多相关数据---update_sd_lb_stats()
- 当开启EAS的情况下,并且pd(性能域)存在且sd不处于overutil时(系统没有进入overutilized状态之前,EAS起作用。如果EAS起作用,那么负载可能就是不均衡的(考虑功耗),这是依赖task placement的结果)因此,这时候要过滤一些不需要进行load banlance的情况:
- 非newly idle情况,不进行load balance-----------这个在其他平台不存在,个人也觉得这个过滤条件有点奇怪,可能要结合qcom平台的EAS一起看
- 迁移dst cpu不在env->sd->groups范围内 或者 没有找到最繁忙的group,那么也不进行load balance。
- 如果busiest group中有超过1个cpu(即现在是DIE level,cluster间迁移),并且local cpu的orig capacity大于busiest cpu的。就不进行load balance---------不允许从小核将task迁移到大核
- 如果local cpu与busiest cpu有同样的orig capacity,或者是cluster内迁移:
- 进一步判断busiest cpu上task数量是否只有1个,如果是,则不进行load balance。------这种明显是1个load大的task,往兄弟cpu或者同capacity cpu迁移,不会改善情况,所以避免迁移。
- 检查ASYM feature,这个功能对应sd->flags为SD_ASYM_PACKING,该flag只会在SMT level带有。所以当前平台不支持,所以这块暂不关注() 判断一些情况,满足则必须进行load balance(force_balanced):
- busiest group type为group_imbalanced
- dst cpu处于空闲,且local group有空闲capacity,且busiest 处于overload状态(group_no_capacity == 1)
- busiest group type为group_misfit_task,即group内有misfit task
- 再判断一些情况,满足则不需要进行load balance(out_balanced):
- 目标cpu所在的local group比busiest group更繁忙(通过比较avg_load)。avg_load计算方法:调度域中所有group的total load * 1024 / 调度域中所有group的total capacity
- 目标cpu所在的local group的avg_load >= 调度域的avg_load,那就不要pull task(因为这个local group肯定不是最空闲的group,兄弟姐妹group中有更空闲的)
- 如果目标cpu处于idle,且busiest group不处于overload状态,且目标cpu所在的local group中的idle cpu个数 <= busiest group的idle cpu个数+1
- 如果目标cpu不是idle状态(newly idle、not idle),使用imbalance_pct来判断是否需要进行load balance。判断计算方法:busiest group的avg_load *100 <= env->sd->imbalance_pct * local group的avg_load,imbalance_pct在sd建立时已确定(MC:117、DIE:125)
- 根据之前的判断进行force_balanced,或者不做load balance直接return NULL
- force_balanced:
- 保存busiest group type到env_src_group_type
- 进一步判断一些条件并计算imbalance值(calculate_imbalance)
- 如果imbalance不为0,则return busiest group;反之return NULL
- out_balanced:
- 设置env->imbalance = 0,并return NULL
- force_balanced:
/** * find_busiest_group - Returns the busiest group within the sched_domain * if there is an imbalance. * * Also calculates the amount of weighted load which should be moved * to restore balance. * * @env: The load balancing environment. * * Return: - The busiest group if imbalance exists. */ static struct sched_group *find_busiest_group(struct lb_env *env) { struct sg_lb_stats *local, *busiest; struct sd_lb_stats sds; init_sd_lb_stats(&sds); //初始化sds结构体 /* * Compute the various statistics relavent for load balancing at * this level. */ update_sd_lb_stats(env, &sds); //(2-2-1)更新用于load balance的调度域很多相关数据 if (static_branch_unlikely(&sched_energy_present)) { //sched_energy_present值作为是否开启EAS选核的开关,当前平台是打开的 struct root_domain *rd = env->dst_rq->rd; if (rcu_dereference(rd->pd) && !sd_overutilized(env->sd)) { //root doamin的perf domain结构体存在?(暂时没理解),并且env->sd不处于overutil int cpu_local, cpu_busiest; unsigned long capacity_local, capacity_busiest; if (env->idle != CPU_NEWLY_IDLE) //非newly idle情况,那么就说明没有imbalance;只考虑newly idle情况做load balance???这里看了下AOSP kernel-5.10没有这个奇怪条件过滤 goto out_balanced; if (!sds.local || !sds.busiest) //迁移目标cpu不在当前env->sd->groups内,或者没有找到busiest group。那么就说明没有imbalance goto out_balanced; cpu_local = group_first_cpu(sds.local); //取出sds.local group中的第一个cpu cpu_busiest = group_first_cpu(sds.busiest); //取出找到的busiest group中的第一个cpu /* TODO:don't assume same cap cpus are in same domain */ capacity_local = capacity_orig_of(cpu_local); //获取上面的2个cpu的capacity capacity_busiest = capacity_orig_of(cpu_busiest); if ((sds.busiest->group_weight > 1) && //busiest的group_weight > 1(group_weight表示sched group中有多少个CPU,MC level:1、DIE level:4) capacity_local > capacity_busiest) { //并且,local capacity > busiest capacity。那么就说明没有imbalance goto out_balanced; } else if (capacity_local == capacity_busiest || //两者capacity相等 asym_cap_siblings(cpu_local, cpu_busiest)) { //或者两个cpu是兄弟cpu if (cpu_rq(cpu_busiest)->nr_running < 2) //如果busiest group中的第一个cpu上只有0个或者1个task goto out_balanced; //那么就无法进行迁移 } } } local = &sds.local_stat; //取出busiest group和local group的数据 busiest = &sds.busiest_stat; /* ASYM feature bypasses nice load balance check */ if (check_asym_packing(env, &sds)) //ASYM feature绕过一些检查,能直接return给出结果 return sds.busiest; /* There is no busy sibling group to pull tasks from */ //没有在group中,找到满足条件的task来pull if (!sds.busiest || busiest->sum_nr_running == 0) //即,没有找到busiest group,或者busiest group中没有运行的task goto out_balanced; /* XXX broken for overlapping NUMA groups */ sds.avg_load = (SCHED_CAPACITY_SCALE * sds.total_load) //计算sds的avg_load = 调度域中所有group的total load * 1024 / 调度域中所有group的total capacity / sds.total_capacity; /* * If the busiest group is imbalanced the below checks don't * work because they assume all things are equal, which typically * isn't true due to cpus_allowed constraints and the like. */ if (busiest->group_type == group_imbalanced) //如果busiest sg低level的group,因为cpu affinity没有balance成功,设置了group_imbalanced标志,强制在当前级别上进行balance goto force_balance; /* * When dst_cpu is idle, prevent SMP nice and/or asymmetric group * capacities from resulting in underutilization due to avg_load. */ if (env->idle != CPU_NOT_IDLE && group_has_capacity(env, local) && //目标cpu处于空闲状态,local group有较多空余capacity,busiest group很繁忙(没有capacity) busiest->group_no_capacity) //这种情况下,强制进行balance goto force_balance; /* Misfit tasks should be dealt with regardless of the avg load */ if (busiest->group_type == group_misfit_task) //如果有misfit task,那么强制进行balance goto force_balance; /* * If the local group is busier than the selected busiest group * don't try and pull any tasks. */ if (local->avg_load >= busiest->avg_load) //如果目标cpu的local group比busiest group更繁忙(通过比较avg_load),那就不要尝试pull task goto out_balanced; /* * Don't pull any tasks if this group is already above the domain * average load. */ if (local->avg_load >= sds.avg_load) //如果目标cpu的local group的avg_load已经高于调度域的avg_load,那就不要pull task(因为这个local group肯定不是最空闲的group) goto out_balanced; if (env->idle == CPU_IDLE) { /* * This CPU is idle. If the busiest group is not overloaded //如果目标cpu处于idle,且busiest group不处于overload状态,且目标cpu所在的local group中的 * and there is no imbalance between this and busiest group //idle cpu个数 <= busiest group的idle cpu个数+1 * wrt idle CPUs, it is balanced. The imbalance becomes //就认为没有imbalance * significant if the diff is greater than 1 otherwise we * might end up to just move the imbalance on another group */ if ((busiest->group_type != group_overloaded) && (local->idle_cpus <= (busiest->idle_cpus + 1))) goto out_balanced; } else { /* * In the CPU_NEWLY_IDLE, CPU_NOT_IDLE cases, use //在newly idle和not idle的case,使用imbalance_pct来计算,并判断是否需要进行load balance * imbalance_pct to be conservative. */ if (100 * busiest->avg_load <= //busiest group的avg_load *100 <= env->sd->imbalance_pct * local group的avg_load env->sd->imbalance_pct * local->avg_load) //满足则不要做balance,反之,要做load balance goto out_balanced; } force_balance: /* Looks like there is an imbalance. Compute it */ //走到force_balance分支,说明应该是有imbalance,所以需要进行计算 env->src_grp_type = busiest->group_type; //保存busiest group type calculate_imbalance(env, &sds); //(2-2-2)计算imbalance的程度 trace_sched_load_balance_stats(sds.busiest->cpumask[0], busiest->group_type, busiest->avg_load, busiest->load_per_task, sds.local->cpumask[0], local->group_type, local->avg_load, local->load_per_task, sds.avg_load, env->imbalance); return env->imbalance ? sds.busiest : NULL; out_balanced: env->imbalance = 0; return NULL; }
(2-2-1)更新用于load balance的调度域(sds)很多相关数据
- 通过do-while循环,遍历所有env->sd->groups一轮(MC level的sd:遍历当前cluster内的每个cpu core;DIE level的sd:遍历2个cluster)
- 先判断dst cpu是否在当前sg范围内(函数 sched_group_span(sg)上面已经解释过,根据不同level有不同的范围,详情见(2-1)),
- 如果在,则置位local_group,并保存local相关信息,local group不会作为sd下busiest group。(local group迁移不会在同一group:所以,发生迁移,要么是MC level下同cluster内的不同cpu;要么DIE level下不同cluster)
- 同时,如果不是newly idle、或者更新间隔满足的情况下会更新sd的sgc(MC level更新cpu capacity;DIE level下更新cluster对应的sched group capacity)。也就是只更新与load balance相关的sgc。
- 更新当前sg中用于load balance的相关数据,记录到sgs结构体中。
- 如果是local group,即需要将task放到local group,那么就跳过对其判断是否是busiest group的过程。local group是task的接收者,那么就不需要对齐判断是否是busiest group,因为busiest group是需要将task送出,因为它太繁忙了。
- 在进行busiest group判断之前,还会进行2个补充更新逻辑:
- (当前平台永不满足)系统会根据child sd是否支持perfer_sibling而重新更新group_no_capacity和group_type。但是当前平台永远不会成立。
- 除非大核没有capacity承担当前load,否则不允许将大核迁移到小核,即满足如下所有条件时,更新group_no_capacity为0、并更新group_type:当前sd时DIE level;当前sds处于group_no_capacity;asym_cap_sibling_group_has_capacity函数条件满足并返回true(实际此函数在当前平台永远返回false)。
- 判断当前sg是否是busiest group,通过循环找到busiest sg和sgs。
- 更新load balance调度域sd_lb_stats相关数据:
- total_running
- total_load
- total_capacity
- total_util
- sds中busiest group的task数到env->src_grp_nr_running
- 判断是否更新overload flag标记到root domain
- 更新overutil flag标记
- 如果因MC level有misfit task,那么同时设置DIE level为overutil(将misfit的状态,以overutil flag的方式逐层向parent传递给有不同capcity核的parent level以及 grand parent level等)
- 如果sd total util *105% > sd total capacity,那么同时要设置parent level overutil标记
/** * update_sd_lb_stats - Update sched_domain's statistics for load balancing. * @env: The load balancing environment. * @sds: variable to hold the statistics for this sched_domain. */ static inline void update_sd_lb_stats(struct lb_env *env, struct sd_lb_stats *sds) { struct sched_domain *child = env->sd->child; struct sched_group *sg = env->sd->groups; struct sg_lb_stats *local = &sds->local_stat; struct sg_lb_stats tmp_sgs; bool prefer_sibling = child && child->flags & SD_PREFER_SIBLING; //这里当前平台不会满足,因为只有在DIE level才有child sd,但是flag:SD_PREFER_SIBLING在MC level上并没有包含。所以这里永远为false int sg_status = 0; #ifdef CONFIG_NO_HZ_COMMON if (env->idle == CPU_NEWLY_IDLE && READ_ONCE(nohz.has_blocked)) //当此次是newly idle的情况,并且nohz.has_blocked为true(has_blocked表示上次pelt更新时,还有blocked load没有更新完整) env->flags |= LBF_NOHZ_STATS; //置位flag:LBF_NOHZ_STATS #endif do { struct sg_lb_stats *sgs = &tmp_sgs; int local_group; local_group = cpumask_test_cpu(env->dst_cpu, sched_group_span(sg)); //判断目标cpu是否在当前调度组中 if (local_group) { sds->local = sg; sgs = local; if (env->idle != CPU_NEWLY_IDLE || time_after_eq(jiffies, sg->sgc->next_update)) //如果不是newly idle case,或者更新sgc(Sched Group Capacity调度组的cpu capacity)的间隔满足了。那么就需要更新group capacity update_group_capacity(env->sd, env->dst_cpu); //(2-2-1-1)更新sched group capacity(sgc)相关数据 } update_sg_lb_stats(env, sg, sgs, &sg_status); //(2-2-1-2)更新用于load balance的调度组相关数据 if (local_group) //如果dst_cpu在当前调度组中(local group),那么就不需要判断这个sg是否是busiest的sg goto next_group; /* * In case the child domain prefers tasks go to siblings //假如子调度域中的task满足条件下,优先迁移到兄弟cpu * first, lower the sg capacity so that we'll try //那么,就会尝试将所有超额的task迁移走,来降低调度组的capacity * and move all the excess tasks away. We lower the capacity //只要local group有capacity能容纳这些超额的task,那么就会执行迁移操作 * of a group only if the local group has the capacity to fit * these excess tasks. The extra check prevents the case where //此外,还要防止一个case:当load最重的group已经利用不足(可能有一个超过所有其他任务之和的超大任务),然后不断地从负载最重的group中pull task * you always pull from the heaviest group when it is already * under-utilized (possible with a large weight task outweighs * the tasks on the system). */ if (prefer_sibling && sds->local && //因为prefer_sibling永远为false,所以这里条件永远不会满足 group_has_capacity(env, local) && //has capacity的判断与group_no_capacity的逻辑相反 (sgs->sum_nr_running > local->sum_nr_running + 1)) { sgs->group_no_capacity = 1; sgs->group_type = group_classify(sg, sgs); //更新group的状态:overload、imbalance、misfit_task } /* * Disallow moving tasks from asym cap sibling CPUs to other //不允许将task从大核迁移到小核,除非大核没有capacity承担当前的load * CPUs (lower capacity) unless the asym cap sibling group has * no capacity to manage the current load. */ if ((env->sd->flags & SD_ASYM_CPUCAPACITY) && sgs->group_no_capacity && asym_cap_sibling_group_has_capacity(env->dst_cpu, //(2-2-1-3)这行的判断条件在当前平台永远返回false,永不满足 env->sd->imbalance_pct)) { sgs->group_no_capacity = 0; //更新group_no_capacity sgs->group_type = group_classify(sg, sgs); //更新group_type } if (update_sd_pick_busiest(env, sds, sg, sgs)) { //(2-2-1-4)判断当前sg是否是busiest group;通过不断循环判断来找到busiest group sds->busiest = sg; sds->busiest_stat = *sgs; } next_group: /* Now, start updating sd_lb_stats */ //统计调度域中相关数据用于load balance sds->total_running += sgs->sum_nr_running; sds->total_load += sgs->group_load; sds->total_capacity += sgs->group_capacity; sds->total_util += sgs->group_util; trace_sched_load_balance_sg_stats(sg->cpumask[0], sgs->group_type, sgs->idle_cpus, sgs->sum_nr_running, sgs->group_load, sgs->group_capacity, sgs->group_util, sgs->group_no_capacity, sgs->load_per_task, sgs->group_misfit_task_load, sds->busiest ? sds->busiest->cpumask[0] : 0); sg = sg->next; //遍历下一份group } while (sg != env->sd->groups); //直到调度域内的所有group都遍一轮 #ifdef CONFIG_NO_HZ_COMMON if ((env->flags & LBF_NOHZ_AGAIN) && //LBF_NOHZ_AGAIN是否置位,其实就是看本函数上面置位的flag:LBF_NOHZ_STATS,后面在update_sg_lb_stats函数中是否都更新掉所有blocked load。如果还有遗留,则会有LBF_NOHZ_AGAIN的flag cpumask_subset(nohz.idle_cpus_mask, sched_domain_span(env->sd))) { //nohz.idle是否在env->sd的调度域中?是的话,返回true WRITE_ONCE(nohz.next_blocked, jiffies + msecs_to_jiffies(LOAD_AVG_PERIOD)); //更新next_blocked的时间戳,应该是为了确定把遗留的blocked load更新掉 } #endif if (env->sd->flags & SD_NUMA) //numa balance的情况,我们平台不属于numa架构,暂不考虑 env->fbq_type = fbq_classify_group(&sds->busiest_stat); env->src_grp_nr_running = sds->busiest_stat.sum_nr_running; //保存busiest group中的 sum_nr_running task数量 if (!env->sd->parent) { //如果env->sd位于root domain(即env->sd是DIE level) struct root_domain *rd = env->dst_rq->rd; /* update overload indicator if we are at root domain */ WRITE_ONCE(rd->overload, sg_status & SG_OVERLOAD); //更新是否overload的flag到root domain } if (sg_status & SG_OVERUTILIZED) //根据当前状态,更新调度组的overutil flag set_sd_overutilized(env->sd); //sd->shared->overutilized = true else clear_sd_overutilized(env->sd); //sd->shared->overutilized = false /* * If there is a misfit task in one cpu in this sched_domain //如果调度域中有一个misfit task, * it is likely that the imbalance cannot be sorted out among //而且在调度域的多个cpu中迁移,不能解决imbalance问题, * the cpu's in this sched_domain. In this case set the //那么就需要设置overutil的flag到parent调度域中 * overutilized flag at the parent sched_domain. */ if (sg_status & SG_HAS_MISFIT_TASK) { struct sched_domain *sd = env->sd->parent; /* * In case of a misfit task, load balance at the parent //在上面所述情况下,要在parent调度域中进行load balance, * sched domain level will make sense only if the the cpus //那么parent调度中必须要有不同的capacity的cpu,这样load balance才有意义。 * have a different capacity. If cpus at a domain level have //如果parent调度域中只有相同capacity的cpu,那么misfit task不会很好的适应这样的场景, * the same capacity, the misfit task cannot be well //所以,在这样的domain做load balance是没有一亿元的 * accomodated in any of the cpus and there in no point in * trying a load balance at this level */ while (sd) { //遍历层层调度域 if (sd->flags & SD_ASYM_CPUCAPACITY) { //找到有不同cpu capacity的调度域 set_sd_overutilized(sd); //然后设置overutil flag:sd->shared->overutilized = true break; } sd = sd->parent; } } /* * If the domain util is greater that domain capacity, load balancing * needs to be done at the next sched domain level as well. */ if (env->sd->parent && sds->total_capacity * 1024 < sds->total_util * //如果当前sds的total_capacity * 1024 < sds的total_util * 1078(大约105%) sched_capacity_margin_up[group_first_cpu(sds->local)]) set_sd_overutilized(env->sd->parent); //那么在上一层level也要做load balance,即在parent调度域设置overutil flag }
(2-2-1-1)更新sched group capacity(sgc)相关数据
- 如果当前sd没有child,即这个sd为最底层的sd(MC level),那么只要更新cpu capacity。因为这个group只有一个cpu,所以capacity就是cpu capacity本身。cpu capacity由其max freq决定,同时也会受thermal限制影响。
- 当前平台big.LITTLE 8核(4+4),所以group capacity大致应该是这样的:(关于SD_OVERLAP:调度域是否有重叠,当前平台是没有重叠的)
MC level:由于是最底层sd,所以sgc->capacity就是对应每个cpu capacity。
这部分的代码中MC level的group capacity详细计算,参考CPU调度域/组建立中的流程,其中同样调用了该函数,因此不再赘述:CPU拓扑结构和调度域/组--更新对应group的capacity
DIE level:sgc->capacity为child->group的所有sgc->capacity之和。可以认为是cluster内所有cpu的capacity之和。
而最后,统计出每层sgc的group capacity,并记录最小和最大的capacity。
void update_group_capacity(struct sched_domain *sd, int cpu) { struct sched_domain *child = sd->child; struct sched_group *group, *sdg = sd->groups; unsigned long capacity, min_capacity, max_capacity; unsigned long interval; interval = msecs_to_jiffies(sd->balance_interval); //sgc的更新有间隔限制:1 ~ HZ/10 interval = clamp(interval, 1UL, max_load_balance_interval); sdg->sgc->next_update = jiffies + interval; if (!child) { //如果是MC level的sd更新sgc,那么就只要更新cpu capacity,因为MC level的sg只有单个cpu在内 update_cpu_capacity(sd, cpu); //(2-6-1-1)更新cpu capacity return; } capacity = 0; min_capacity = ULONG_MAX; max_capacity = 0; if (child->flags & SD_OVERLAP) { //这个是sd有重叠的情况,当前平台没有sd重叠 /* * SD_OVERLAP domains cannot assume that child groups * span the current group. */ for_each_cpu(cpu, sched_group_span(sdg)) { struct sched_group_capacity *sgc; struct rq *rq = cpu_rq(cpu); if (cpu_isolated(cpu)) continue; /* * build_sched_domains() -> init_sched_groups_capacity() * gets here before we've attached the domains to the * runqueues. * * Use capacity_of(), which is set irrespective of domains * in update_cpu_capacity(). * * This avoids capacity from being 0 and * causing divide-by-zero issues on boot. */ if (unlikely(!rq->sd)) { capacity += capacity_of(cpu); } else { sgc = rq->sd->groups->sgc; capacity += sgc->capacity; } min_capacity = min(capacity, min_capacity); max_capacity = max(capacity, max_capacity); } } else { /* * !SD_OVERLAP domains can assume that child groups 因为没有sd重叠,那么所有child sd的groups合在一起,就是当前的group * span the current group. */ group = child->groups; do { //do-while遍历child sd的sg环形链表;当前平台为例,走到这里是DIE level,那么child sd就是MC level的groups struct sched_group_capacity *sgc = group->sgc; //获取对应sgc __maybe_unused cpumask_t *cpus = sched_group_span(group); //因为group是处于MC level,所以范围就是sg对应的cpu if (!cpu_isolated(cpumask_first(cpus))) { //排除isolate状态的cpu capacity += sgc->capacity; //将每个sgc(cpu)的capacity累加起来 min_capacity = min(sgc->min_capacity, //保存最小的sgc->capacity min_capacity); max_capacity = max(sgc->max_capacity, //保存最大的sgc->capacity max_capacity); } group = group->next; } while (group != child->groups); } sdg->sgc->capacity = capacity; //将MC level中每个sgc->capacity累加起来,其总和作为DIE level中groups sdg->sgc->min_capacity = min_capacity; //并保存最大、最小capacity sdg->sgc->max_capacity = max_capacity; }
在MC level时,只需更新cpu capacity即可:
static void update_cpu_capacity(struct sched_domain *sd, int cpu) { unsigned long capacity = arch_scale_cpu_capacity(cpu); //获取per_cpu变量cpu_scale struct sched_group *sdg = sd->groups; capacity *= arch_scale_max_freq_capacity(sd, cpu); //获取per_cpu变量max_freq_scale,参与计算 capacity >>= SCHED_CAPACITY_SHIFT; //这2步计算为:cpu_scale * max_freq_scale / 1024 capacity = min(capacity, thermal_cap(cpu)); //计算得出的capacity不能超过thermal限制中的cpu的capacity cpu_rq(cpu)->cpu_capacity_orig = capacity; //将计算得出的capacity作为当前cpu rq的cpu_capacity_orig capacity = scale_rt_capacity(cpu, capacity); //(2-6-1-1-1)计算cfs rq剩余的cpu capacity if (!capacity) //如果没有剩余cpu capacity给cfs了,那么就强制写为1 capacity = 1; cpu_rq(cpu)->cpu_capacity = capacity; //更新相关sgc capacity:cpu rq的cpu_capacity、sgc的最大/最小的capacity sdg->sgc->capacity = capacity; sdg->sgc->min_capacity = capacity; sdg->sgc->max_capacity = capacity; }
(2-2-1-2)更新用于load balance的调度组(sg)相关数据
- 遍历在env->cpus中,且在当前sg范围的每个cpu,但忽略isolate的cpu。获取cpu对应的负载均线(cpu负载相关分析,见:https://www.cnblogs.com/lingjiajun/p/14034896.html)。不同 level下,对应获取cpu负载均线会有差别,具体信息(包括flags、imbalance_pct等)如下:


- 首先,根据balance的类别:idle、newly idle、busy,来使用对应特定的cpu负载均线。再次,根据是否为local group,还会有不同的bias:local group【负载均线值和实时值,取其较大】,非local group【负载均线值和实时值,取其较小】。将最后的结果作为该cpu的balance load。 需要注意的是对应的cpu_load需要将idx减1,例如busy balance情况下,busy_idx = 2,而均线对应的是cpu_load[1],即(old_load + new_load)/ 2 的那条均线。(注意:target_load() 和 source_load() 两个函数的实现)
- cpu load这部分,我看了kernel-5.4以后就不再使用这种bias了,而是直接使用cpu_load[0]的数据。
- 统计用于load balance的sched group的相关数据【sgs结构中的数据】,包括:
- group_load:group内上面获取的balance load之和
- group_util:group内总cpu_util,即WALT或者PELT统计出来的cpu utilization。
- sum_nr_running:group内所有cfs rq上的总runnable task数
- sg_status:group的当前是否处于特殊状态:overload、overutil、misfit
- sum_weighted_load:group内所有cpu实时负载之和
- idle_cpus:group内idle cpu的个数
- group_misfit_task_load:如果当前是在DIE level,判断是否有出现overload的情况,如有,则将所有rq中最大的misfit_task_load记录下来
- group_capacity:对应了group->sgc->capacity。MC level下就是每个cpu的capacity;DIE level下就是每个cluster内cpu capacity之和。
- avg_load:计算得出,计算公式为:group_load *1024 / group_capacity
- group_weight:就是group->group_weight;MC level下 = 1;DIE level下= 4。
- group_no_capacity:表示group是否还有剩余capacity,其实是记录group是否overload,如果已经overload,那么自然就没有剩余capacity了。overload的条件为:group_capacity * 100 < group_util * imbalance_pct (当前sd的不平衡百分比门限,MC:117、DIE:125)
- group_type:也是根据group的相关参数,记录group处于什么状态的。主要类型由:
-
-
- group_other(0,正常状态),
- group_misfit_task(1,有misfit task),
- group_imbalanced(2,不平衡,group_sgc_imbalance有值),
- group_overloaded(3,过载,也就是group_no_capacity为true)。
-
有点类似sd_status,但是group type中多了"group_imbalance",而没有overutil。
-
- load_per_task:计算得出,计算公式为:sum_weighted_load / sum_nr_running
在每次遍历在env->cpus中,且在当前sg范围的每个cpu的循环中,统计累加了sgs的一些数据,如上红色部分。
本函数根据(2-2-1)的循环,就是更新2轮:第1轮是cluster内的每个cpu sg;第2轮,是更新2个cluster sg。
/** * update_sg_lb_stats - Update sched_group's statistics for load balancing. * @env: The load balancing environment. * @group: sched_group whose statistics are to be updated. * @sgs: variable to hold the statistics for this group. * @sg_status: Holds flag indicating the status of the sched_group */ static inline void update_sg_lb_stats(struct lb_env *env, struct sched_group *group, struct sg_lb_stats *sgs, int *sg_status) { int local_group = cpumask_test_cpu(env->dst_cpu, sched_group_span(group)); //flag:local_group,表示迁移的目标cpu是否在当前调度组中 int load_idx = get_sd_load_idx(env->sd, env->idle); //(2-2-1-2-1)获取使用哪组cpu负载数据来用于load balance。分别由idle、newly idle、busy三组。 unsigned long load; int i, nr_running; memset(sgs, 0, sizeof(*sgs)); for_each_cpu_and(i, sched_group_span(group), env->cpus) { //遍历每个满足:在group范围内,且又在env->cpus(load_balance_mask)范围内 的cpu struct rq *rq = cpu_rq(i); if (cpu_isolated(i)) //过滤isolate cpu continue; if ((env->flags & LBF_NOHZ_STATS) && update_nohz_stats(rq, false)) //因为更新pelt时,有遗留的blocked load未更新掉;所以,在这里尝试通过update_nohz_stats函数来更新掉 env->flags |= LBF_NOHZ_AGAIN; //更新flag,因为此次update_nohz_stats还是没有完全更新掉blocked load,置位flag后,在流程后面启动周期来完成还遗留的blocked load /* Bias balancing toward CPUs of our domain: */ if (local_group) load = target_load(i, load_idx); //获取cpu[i]的负载,loacal group情况:idx非0情况下,会在[cpu负载均线值]和[cpu当前实时负载]两者中,选更【大】的 else load = source_load(i, load_idx); //获取cpu[i]的负载,非local group情况:idx非0情况下,会[cpu负载均线值]和[cpu当前实时负载]在两者中,选更【小】的 sgs->group_load += load; //统计调度组中所有cpu的总负载(会有bias) sgs->group_util += cpu_util(i); //统计调度组总util sgs->sum_nr_running += rq->cfs.h_nr_running; //统计所有group内cpu rq总的runnable task数量 nr_running = rq->nr_running; //当前层se内的runnable task数量(不包含子se的runnable task);区别于h_nr_running,h_nr_running会包含所有子se的runnable task 数量 if (nr_running > 1) *sg_status |= SG_OVERLOAD; //标记这个cpu上有 >1 个runnable task if (cpu_overutilized(i)) { *sg_status |= SG_OVERUTILIZED; //标记这个cpu已经overutil if (rq->misfit_task_load) *sg_status |= SG_HAS_MISFIT_TASK; //标记rq中是否有misfit taskt } #ifdef CONFIG_NUMA_BALANCING sgs->nr_numa_running += rq->nr_numa_running; sgs->nr_preferred_running += rq->nr_preferred_running; #endif sgs->sum_weighted_load += weighted_cpuload(rq); //统计sg调度组中所有cpu实时的总负载:累加每个cpu rq的cfs_rq->avg.runnable_load_avg /* * No need to call idle_cpu() if nr_running is not 0 */ if (!nr_running && idle_cpu(i)) sgs->idle_cpus++; //统计idle cpu个数 if (env->sd->flags & SD_ASYM_CPUCAPACITY && sgs->group_misfit_task_load < rq->misfit_task_load) { sgs->group_misfit_task_load = rq->misfit_task_load; *sg_status |= SG_OVERLOAD; //判断是否有overload(DIE level),并且会把rq更大的misfit task load作为group_misift_task_load } } /* Isolated CPU has no weight */ if (!group->group_weight) { sgs->group_capacity = 0; //isolate cpu的参数初始化 sgs->avg_load = 0; sgs->group_no_capacity = 1; sgs->group_type = group_other; sgs->group_weight = group->group_weight; } else { /* Adjust by relative CPU capacity of the group */ sgs->group_capacity = group->sgc->capacity; //active cpu的相关参数计算 sgs->avg_load = (sgs->group_load*SCHED_CAPACITY_SCALE) / sgs->group_capacity; sgs->group_weight = group->group_weight; sgs->group_no_capacity = group_is_overloaded(env, sgs); //判断group是否overload sgs->group_type = group_classify(group, sgs); //获取group type } if (sgs->sum_nr_running) sgs->load_per_task = sgs->sum_weighted_load / sgs->sum_nr_running; }
(2-2-1-2-1)获取使用哪组cpu负载数据来用于load balance。根据当前cpu的状态,分别对应idle balance(idle_idx)、newly idle balance(newidle_idx)、busy balance(busy_idx)三组负载idx
通过上面的表格看到:
busy_idx:2
newidle_idx:0
idle_idx:区分MC/DIE level。分别是MC:0,DIE:1
/** * get_sd_load_idx - Obtain the load index for a given sched domain. * @sd: The sched_domain whose load_idx is to be obtained. * @idle: The idle status of the CPU for whose sd load_idx is obtained. * * Return: The load index. */ static inline int get_sd_load_idx(struct sched_domain *sd, enum cpu_idle_type idle) { int load_idx; switch (idle) { case CPU_NOT_IDLE: load_idx = sd->busy_idx; break; case CPU_NEWLY_IDLE: load_idx = sd->newidle_idx; break; default: load_idx = sd->idle_idx; break; } return load_idx; }
target_load() 和 source_load() 两个函数的实现
/* * Return a low guess at the load of a migration-source CPU weighted * according to the scheduling class and "nice" value. * * We want to under-estimate the load of migration sources, to * balance conservatively. */ static unsigned long source_load(int cpu, int type) { struct rq *rq = cpu_rq(cpu); unsigned long total = weighted_cpuload(rq); //total:cfs_rq->avg.runnable_load_avg if (type == 0 || !sched_feat(LB_BIAS)) return total; return min(rq->cpu_load[type-1], total); } /* * Return a high guess at the load of a migration-target CPU weighted * according to the scheduling class and "nice" value. */ static unsigned long target_load(int cpu, int type) { struct rq *rq = cpu_rq(cpu); unsigned long total = weighted_cpuload(rq); //total:cfs_rq->avg.runnable_load_avg if (type == 0 || !sched_feat(LB_BIAS)) return total; return max(rq->cpu_load[type-1], total); }
cpu_util:注意WALT、PELT的最终使用的数据有不同。
static inline unsigned long cpu_util(int cpu) { struct cfs_rq *cfs_rq; unsigned int util; #ifdef CONFIG_SCHED_WALT u64 walt_cpu_util = cpu_rq(cpu)->wrq.walt_stats.cumulative_runnable_avg_scaled; return min_t(unsigned long, walt_cpu_util, capacity_orig_of(cpu)); #endif cfs_rq = &cpu_rq(cpu)->cfs; util = READ_ONCE(cfs_rq->avg.util_avg); if (sched_feat(UTIL_EST)) util = max(util, READ_ONCE(cfs_rq->avg.util_est.enqueued)); return min_t(unsigned long, util, capacity_orig_of(cpu)); }
group_no_capacity的判断:
- 如果task数量 < group中cpu数量,则必定不是overload
- 上面条件不满足的话,如果使用WALT负载计算,本次load balance是busy balance或者newly idle balance的情况下,打开了walt rotation。则属于overload
- 上面条件不满足的话,判断:group_capacity *100 < group_util * 当前sd的imbalance_pct。如果满足,则属于overload
- 以上条件都不满足,则不是overload
/* * group_is_overloaded returns true if the group has more tasks than it can * handle. * group_is_overloaded is not equals to !group_has_capacity because a group * with the exact right number of tasks, has no more spare capacity but is not * overloaded so both group_has_capacity and group_is_overloaded return * false. */ static inline bool group_is_overloaded(struct lb_env *env, struct sg_lb_stats *sgs) { if (sgs->sum_nr_running <= sgs->group_weight) return false; #ifdef CONFIG_SCHED_WALT if (env->idle != CPU_NOT_IDLE && walt_rotation_enabled) return true; #endif if ((sgs->group_capacity * 100) < (sgs->group_util * env->sd->imbalance_pct)) return true; return false; }
group_type的判断:
static inline enum group_type group_classify(struct sched_group *group, struct sg_lb_stats *sgs) { if (sgs->group_no_capacity) //如果group_no_capacity == 1,则说明group overload return group_overloaded; if (sg_imbalanced(group)) //判断是否有group->sgc->imbalance,如有,则说明group处于不平衡状态(暂时还没有找到sgc->imbalance赋值的地方???) return group_imbalanced; if (sgs->group_misfit_task_load) //如果有misfit task load,则说明group处于有misfit task的状态 return group_misfit_task; return group_other; //以上条件都不满足,则处于正常状态 }
(2-2-1-3)因为asym_cap_sibling_cpus只会在WALT逻辑中进行赋值,并且以当前平台的架构:4+4、6+2,甚至4+3+1的架构,都不会被赋有效值,一直是0。所以此函数永远返回false
static inline bool asym_cap_sibling_group_has_capacity(int dst_cpu, int margin) { int sib1, sib2; int nr_running; unsigned long total_util, total_capacity; if (cpumask_empty(&asym_cap_sibling_cpus) || cpumask_test_cpu(dst_cpu, &asym_cap_sibling_cpus)) return false; sib1 = cpumask_first(&asym_cap_sibling_cpus); sib2 = cpumask_last(&asym_cap_sibling_cpus); if (!cpu_active(sib1) || cpu_isolated(sib1) || !cpu_active(sib2) || cpu_isolated(sib2)) return false; nr_running = cpu_rq(sib1)->cfs.h_nr_running + cpu_rq(sib2)->cfs.h_nr_running; if (nr_running <= 2) return true; total_capacity = capacity_of(sib1) + capacity_of(sib2); total_util = cpu_util(sib1) + cpu_util(sib2); return ((total_capacity * 100) > (total_util * margin)); }
(2-2-1-4)判断当前sg是否是busiest group;通过不断循环判断来找到busiest group
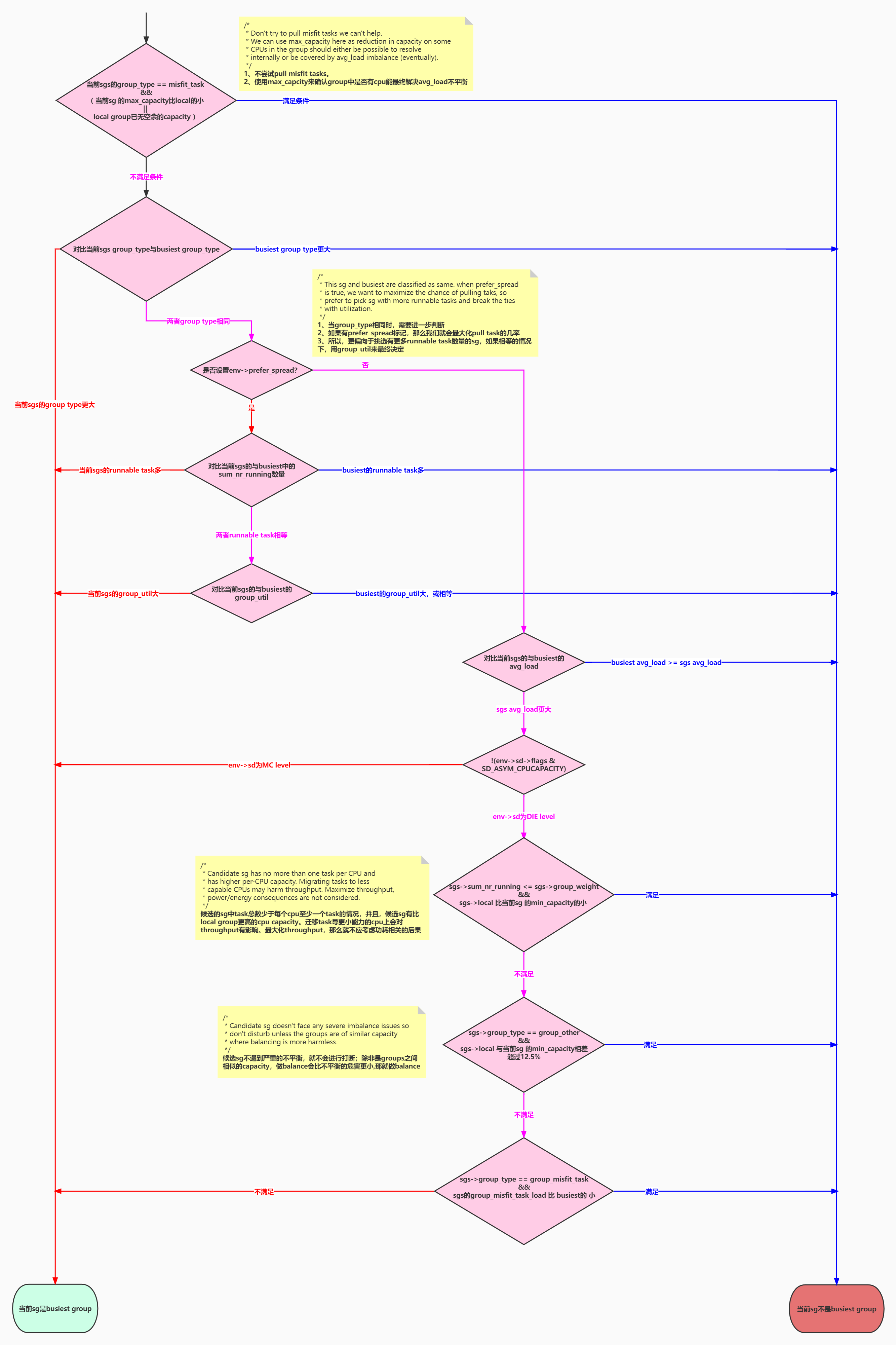
/** * update_sd_pick_busiest - return 1 on busiest group * @env: The load balancing environment. * @sds: sched_domain statistics * @sg: sched_group candidate to be checked for being the busiest * @sgs: sched_group statistics * * Determine if @sg is a busier group than the previously selected * busiest group. * * Return: %true if @sg is a busier group than the previously selected * busiest group. %false otherwise. */ static bool update_sd_pick_busiest(struct lb_env *env, struct sd_lb_stats *sds, struct sched_group *sg, struct sg_lb_stats *sgs) { struct sg_lb_stats *busiest = &sds->busiest_stat; /* * Don't try to pull misfit tasks we can't help. 1、不尝试pull misfit tasks * We can use max_capacity here as reduction in capacity on some 2、使用max_capacity来确认group中是否有cpu能最终解决avg_load不平衡 * CPUs in the group should either be possible to resolve * internally or be covered by avg_load imbalance (eventually). */ if (sgs->group_type == group_misfit_task && //如果是有misfit task的group (!group_smaller_max_cpu_capacity(sg, sds->local) || //当前sg的max_capacity * margin_up >= local_sg的max_capacity *1024;其中margin_up为1078,大约5%的up !group_has_capacity(env, &sds->local_stat))) //或者group是否不满足has capacity return false; //按照group_type判断 if (sgs->group_type > busiest->group_type) //group_type更大的才是busiest group return true; if (sgs->group_type < busiest->group_type) //如果group_type小于busiest group的group_type,那必定不是busiest group return false; /* * This sg and busiest are classified as same. when prefer_spread //当group_type相同时,需要进一步判断 * is true, we want to maximize the chance of pulling taks, so //如果有prefer_spread标记,那么我们就会最大化pull task的几率 * prefer to pick sg with more runnable tasks and break the ties //所以,更偏向于挑选有更多runnable task数量的sg,如果相等的情况下,用group_util来最终决定 * with utilization. */ if (env->prefer_spread) { if (sgs->sum_nr_running < busiest->sum_nr_running) return false; if (sgs->sum_nr_running > busiest->sum_nr_running) return true; return sgs->group_util > busiest->group_util; } if (sgs->avg_load <= busiest->avg_load) //当上述条件无法找出差别时,再对比avg_load;如果<= busiets group,那就认为其肯定不是busiest group return false; if (!(env->sd->flags & SD_ASYM_CPUCAPACITY)) //如果当前sd是MC level(只有DIE level才有asym_cpucapacity flag) goto asym_packing; //那么执行goto /* * Candidate sg has no more than one task per CPU and //候选的sg中task总数少于每个cpu至少一个task的情况 * has higher per-CPU capacity. Migrating tasks to less //并且,候选sg有比local group更高的cpu capacity * capable CPUs may harm throughput. Maximize throughput, //迁移task导更小能力的cpu上会对throughput有影响 * power/energy consequences are not considered. //最大化throughput,那么就不应考虑功耗相关的后果 */ if (sgs->sum_nr_running <= sgs->group_weight && //group_weight其实就是sgs内cpu个数 group_smaller_min_cpu_capacity(sds->local, sg)) //满足返回true:local sg->min_capacity * margin_up < 当前sg->min_capacity * 1024,其中margin_up为1078,大约5%的up return false; //满足上述2个条件,则认为当前sg不是busiest group /* * Candidate sg doesn't face any severe imbalance issues so //候选sg不遇到严重的不平衡,就不会进行打断;除非是groups之间相似的capacity,做balance会比不平衡的危害更小,那就做balance * don't disturb unless the groups are of similar capacity * where balancing is more harmless. */ if (sgs->group_type == group_other && //当前sg是普通sg(不是不平衡较严重的sg) !group_similar_cpu_capacity(sds->local, sg)) //满足条件返回true:2个group对比min_capacity,差距<12.5% return false; //满足上述2个条件,则认为当前sg不是busiest group /* * If we have more than one misfit sg go with the biggest misfit. //如果有多个misfit sg,那么就选misfit最严重的sg为busiest;即过滤不严重的misfit */ if (sgs->group_type == group_misfit_task && //当前sg是misfit task的sg sgs->group_misfit_task_load < busiest->group_misfit_task_load) //比较group_misfit_task_load,更大的才是busiest group return false; asym_packing: /* This is the busiest node in its class. */ if (!(env->sd->flags & SD_ASYM_PACKING)) //当前平台不支持这个flag,所以,这里必然返回true return true; //下面的流程,就暂不分析了。 /* No ASYM_PACKING if target CPU is already busy */ if (env->idle == CPU_NOT_IDLE) return true; /* * ASYM_PACKING needs to move all the work to the highest * prority CPUs in the group, therefore mark all groups * of lower priority than ourself as busy. */ if (sgs->sum_nr_running && sched_asym_prefer(env->dst_cpu, sg->asym_prefer_cpu)) { if (!sds->busiest) return true; /* Prefer to move from lowest priority CPU's work */ if (sched_asym_prefer(sds->busiest->asym_prefer_cpu, sg->asym_prefer_cpu)) return true; } return false; }
(2-2-2)计算imbalance值
/** * calculate_imbalance - Calculate the amount of imbalance present within the * groups of a given sched_domain during load balance. * @env: load balance environment * @sds: statistics of the sched_domain whose imbalance is to be calculated. */ static inline void calculate_imbalance(struct lb_env *env, struct sd_lb_stats *sds) { unsigned long max_pull, load_above_capacity = ~0UL; struct sg_lb_stats *local, *busiest; bool no_imbalance = false; local = &sds->local_stat; busiest = &sds->busiest_stat; if (busiest->group_type == group_imbalanced) { //如果busiest group处于imbalnace状态 /* * In the group_imb case we cannot rely on group-wide averages //不能再使用group等级的avg load来保证cpu load平衡 * to ensure CPU-load equilibrium, look at wider averages. XXX //所以需要更宽等级的avg load,即sds->avg_load */ busiest->load_per_task = min(busiest->load_per_task, sds->avg_load); //busiest->load_per_task和sds->avg_load两者取小作为busiest的load_per_task } /* * Avg load of busiest sg can be less and avg load of local sg can //sds/busiest/local avg load的计算除以的group cacacity的值可能不同 * be greater than avg load across all sgs of sd because avg load //并且当更新busiest sg时,busiest有更小group type的sgs,则直接return,不计算imbalance * factors in sg capacity and sgs with smaller group_type are * skipped when updating the busiest sg. */ if (busiest->avg_load <= sds->avg_load || //busiest avg load <= sds avg load local->avg_load >= sds->avg_load) //或者local avg load >= sds avg load no_imbalance = true; //设置no_imbalance为 true,下面进一步判断 if (busiest->group_type != group_misfit_task && no_imbalance) { //如果busiest group没有misfit task且no_imbalance == true env->imbalance = 0; //那么先强制设置imbalance为0 if (busiest->group_type == group_overloaded && //再判断busiest处于overload 且local的group type<= group_misfit_task(local相当于只有很小或者没有负载问题) local->group_type <= group_misfit_task) { env->imbalance = busiest->load_per_task; //上述那条满足,设置imbalance为busiest load_per_task return; //并直接return } return fix_small_imbalance(env, sds); //(2-2-2-1)如果上述条件不满足,则再计算小的imbalance } /* * If there aren't any idle CPUs, avoid creating some. //如果没有任何idle cpu,避免迁移产生idle */ if (busiest->group_type == group_overloaded && //当busiest和local都处于overload时 local->group_type == group_overloaded) { load_above_capacity = busiest->sum_nr_running * SCHED_CAPACITY_SCALE; //初步计算load_above_capacity = busiest中task数*1024 if (load_above_capacity > busiest->group_capacity) { //如果load_above_capacity > busiest的group capacity load_above_capacity -= busiest->group_capacity; load_above_capacity *= scale_load_down(NICE_0_LOAD); //则计算(load_above_capcity - busiest group capcity)*1024/busiestde group capacity。实际结果就是计算超过busiest group capcity的部分 load_above_capacity /= busiest->group_capacity; //如果busiest有只有1个task,那么这里计算得出的load_above_capacity也是0 } else load_above_capacity = ~0UL; //如果有idle cpu,则不考虑load_above_capacity } /* * In case of a misfit task, independent of avg loads we do load balance //万一有1个misfit task,独立于当前做load balance的sd level * at the parent sched domain level for B.L systems, so it is possible //所以,有可能busiest的avg load < sd avg load * that busiest group avg load can be less than sd avg load. * So skip calculating load based imbalance between groups. //这种情况下,跳过计算group之间的imbalance */ if (!no_imbalance) { /* * We're trying to get all the cpus to the average_load, //我们正在尝试获取所有cpu的avg load,所以我们不想把自己搞成高于avg load * so we don't want to push ourselves above the average load, * nor do we wish to reduce the max loaded cpu below the average //也不想将最大负载的cpu降到低于avg load * load. At the same time, we also don't want to reduce the //同时,我们也不希望将group load降低到group capacity以下 * group load below the group capacity. * Thus we look for the minimum possible imbalance. //因此,我们使用尽可能小的作为imbalance */ max_pull = min(busiest->avg_load - sds->avg_load, //取busiest->avg_load - sds->avg_load和load_above_capacity中较小的 load_above_capacity); /* How much load to actually move to equalise the imbalance */ //然后再计算local avg load与sds avg load的差值,并归一化 env->imbalance = min(max_pull * busiest->group_capacity, //同样取max_pull和上一行注释计算出的差值,乘上各自group capacity后的较小值。作为imbalance (sds->avg_load - local->avg_load) * local->group_capacity) / SCHED_CAPACITY_SCALE; } else { /* * Skipped load based imbalance calculations, but let's find //如果满足上面的skip条件,则跳过基于load计算imbalance * imbalance based on busiest group type or fix small imbalance. //但是要计算基于busiest group type的imbalance或者计算小的imbalance */ env->imbalance = 0; } /* Boost imbalance to allow misfit task to be balanced. //boost imbalance可以运行对misfit task进行均衡 * Always do this if we are doing a NEWLY_IDLE balance //只要满足:我们是在做newly idle balance,且所有task都不会长时间运行(因此我们不能依靠load) * on the assumption that any tasks we have must not be * long-running (and hence we cannot rely upon load). * However if we are not idle, we should assume the tasks //但是如果我们不是处于idle, * we have are longer running and not override load-based //那我们应该假设task是长时间运行的,并且不会覆盖上面代码中基于load的计算 * calculations above unless we are sure that the local //除非我们保证local group没充分利用 * group is underutilized. */ if (busiest->group_type == group_misfit_task && //如果busiest有misfit task,并且满足下面的条件: (env->idle == CPU_NEWLY_IDLE || //现在是newly idle balance,或者local的task数小于local拥有的cpu数 local->sum_nr_running < local->group_weight)) { env->imbalance = max_t(long, env->imbalance, //那么就取之前基于load的imbalance,与busiest->group_misfit_task_load中的较大值,作为imbalance busiest->group_misfit_task_load); } /* * if *imbalance is less than the average load per runnable task //如果imbalance小于avg load per runnable task * there is no guarantee that any tasks will be moved so we'll have //那么不能保证有task会被迁移 * a think about bumping its value to force at least one task to be //所以,我们会考虑提高一下imbalance值,来确保至少有一个task会被迁移 * moved */ if (env->imbalance < busiest->load_per_task) { //判断imbalance是否小于busiest->load_per_task /* * The busiest group is overloaded so it could use help //busiest处于overload的话,它可以从其他group得到帮助 * from the other groups. If the local group has idle CPUs //如果local有idle cpu,并且local没有overload,所在group也没有imbalance * and it is not overloaded and has no imbalance with in //那么允许提高imbalance来触发load balance * the group, allow the load balance by bumping the * imbalance. */ if (busiest->group_type == group_overloaded && local->group_type <= group_misfit_task && env->idle != CPU_NOT_IDLE) { env->imbalance = busiest->load_per_task; //最终提高imbalance = busiest->load_per_task(估计至少会迁移1个task) return; } return fix_small_imbalance(env, sds); //上述条件不满足,则计算小的imbalance } }
(2-2-2-1)计算小的、次要的imbalance。实际满足条件就是将busiest->load_per_task作为imbalance,类似是触发load balance的二次机会
/** * fix_small_imbalance - Calculate the minor imbalance that exists * amongst the groups of a sched_domain, during * load balancing. * @env: The load balancing environment. * @sds: Statistics of the sched_domain whose imbalance is to be calculated. */ static inline void fix_small_imbalance(struct lb_env *env, struct sd_lb_stats *sds) { unsigned long tmp, capa_now = 0, capa_move = 0; unsigned int imbn = 2; unsigned long scaled_busy_load_per_task; struct sg_lb_stats *local, *busiest; local = &sds->local_stat; busiest = &sds->busiest_stat; if (!local->sum_nr_running) //如果local group没有task local->load_per_task = cpu_avg_load_per_task(env->dst_cpu); //则设置local->load_per_task = dst_cpu的pelt负载 / dst_cpu的cfs task总数 else if (busiest->load_per_task > local->load_per_task) //如果busiest load_per_task > local的 imbn = 1; //则设置imbn = 1 scaled_busy_load_per_task = //归一化busiest的load_per_task(scaled_busy_load_per_task) = busiest->load_per_task *1024 / busiest的group_capacity (busiest->load_per_task * SCHED_CAPACITY_SCALE) / //这个应该就是相当于迁移走的busy load部分(归一化) busiest->group_capacity; if (busiest->avg_load + scaled_busy_load_per_task >= //如果busiest->avg_load + scaled_busy_load_per_task >= local->avg_load +scaled_busy_load_per_task *imbn(倍数) local->avg_load + (scaled_busy_load_per_task * imbn)) { env->imbalance = busiest->load_per_task; //设imbalance为busiest->load_per_task return; } /* * OK, we don't have enough imbalance to justify moving tasks, //如果,我们没有足够的imbalance来决定迁移task * however we may be able to increase total CPU capacity used by //但我们可以通过迁移他们来提高总的被使用的cpu capacity * moving them. */ //下面这3次capa_now的计算统计了busiest和local的用量总和 capa_now += busiest->group_capacity * //如果用的是avg load,相当于计算回原来的group load min(busiest->load_per_task, busiest->avg_load); //如果用的是load_per_task,那计算的是load_per_task * group_capacity /1024 capa_now += local->group_capacity * min(local->load_per_task, local->avg_load); capa_now /= SCHED_CAPACITY_SCALE; /* Amount of load we'd subtract */ //我们要减去的量(capa_move) if (busiest->avg_load > scaled_busy_load_per_task) { //如果avg_load > scaled_busy_load,说明有可以迁移的load capa_move += busiest->group_capacity * //计算可以迁移的load = busiest group_capacity * (load_per_task和avg_load- scaled_busy_load的较小者) min(busiest->load_per_task, busiest->avg_load - scaled_busy_load_per_task); //选较小的作为迁移量 } /* Amount of load we'd add */ //我们要增加的量(tmp) if (busiest->avg_load * busiest->group_capacity < //判断 group_load 是否小于 load_per_task?(也是选择较小者) busiest->load_per_task * SCHED_CAPACITY_SCALE) { tmp = (busiest->avg_load * busiest->group_capacity) / //busiest->group_load / local->group_capacity local->group_capacity; } else { tmp = (busiest->load_per_task * SCHED_CAPACITY_SCALE) / //busiest->load_per_task *1024 / local->group_capacity local->group_capacity; } capa_move += local->group_capacity * //计算迁移之后的用量总和(capa_move) min(local->load_per_task, local->avg_load + tmp); //计算方法:local->group_capacity * (load_per_task和avg_load+tmp的较小者) / 1024 capa_move /= SCHED_CAPACITY_SCALE; /* Move if we gain throughput */ if (capa_move > capa_now) { //判断移动之后,是否会将整体的用量总和是否会提高(目标看上去是尽量提高使用率) env->imbalance = busiest->load_per_task; return; } /* We can't see throughput improvement with the load-based //我们不能用基于load的方法看到提高用量的话, * method, but it is possible depending upon group size and //但是依赖group size和capacity范围,在有不同cpu capacity的系统上, * capacity range that there might still be an underutilized //仍可能有一个没有充分利用的cpu。 * cpu available in an asymmetric capacity system. Do one last //所以,再做最后一次case检查 * check just in case. */ if (env->sd->flags & SD_ASYM_CPUCAPACITY && //当前是DIE level busiest->group_type == group_overloaded && //busiest group处于overload busiest->sum_nr_running > busiest->group_weight && //busiest上task数量超过group内cpu核数 local->sum_nr_running < local->group_weight && //local上task数量小于group内cpu核数 local->group_capacity < busiest->group_capacity) //local的group capacity < busiest的group capacity env->imbalance = busiest->load_per_task; }
(2-3)从busiest group与env->cpus交集中,遍历找出busiest rq中,即负载最重cpu对应的rq。
/* * find_busiest_queue - find the busiest runqueue among the CPUs in the group. */ static struct rq *find_busiest_queue(struct lb_env *env, struct sched_group *group) { struct rq *busiest = NULL, *rq; unsigned long busiest_load = 0, busiest_capacity = 1; int i; for_each_cpu_and(i, sched_group_span(group), env->cpus) { //从busiest group与env->cpus的交集中遍历cpu unsigned long capacity, load; enum fbq_type rt; rq = cpu_rq(i); rt = fbq_classify_rq(rq); //我们没有打开numa balancing,所以这里永远为regular(0) /* * We classify groups/runqueues into three groups: * - regular: there are !numa tasks * - remote: there are numa tasks that run on the 'wrong' node * - all: there is no distinction * * In order to avoid migrating ideally placed numa tasks, * ignore those when there's better options. * * If we ignore the actual busiest queue to migrate another * task, the next balance pass can still reduce the busiest * queue by moving tasks around inside the node. * * If we cannot move enough load due to this classification * the next pass will adjust the group classification and * allow migration of more tasks. * * Both cases only affect the total convergence complexity. */ if (rt > env->fbq_type) //这里永远不会满足,不会continue continue; /* * For ASYM_CPUCAPACITY domains with misfit tasks we simply //如果busiest是misfit的情况,那只要找最大的misfit task * seek the "biggest" misfit task. */ if (env->src_grp_type == group_misfit_task) { //判断busiest if (rq->misfit_task_load > busiest_load) { //如果rq的misfit_task_load 大于busiest_load(初始为0) busiest_load = rq->misfit_task_load; //则将misfit task load赋值给busiest_load busiest = rq; //拥有最大的misift load的rq也就是最繁忙的 } continue; } /* * Ignore cpu, which is undergoing active_balance and doesn't //cpu如果处于active load balance而且task数<=2 * have more than 2 tasks. //就直接跳过,肯定不是busiest rq */ if (rq->active_balance && rq->nr_running <= 2) continue; capacity = capacity_of(i); //获取cpu_capacity,即留给CFS task的cpu capacity /* * For ASYM_CPUCAPACITY domains, don't pick a CPU that could //对于拥有大小核的DIE level,不要选择最终导致 * eventually lead to active_balancing high->low capacity. //active balance 从high capcity到low 迁移 * Higher per-CPU capacity is considered better than balancing //因为越高per-cpu的capacity比做平均load balance更好 * average load. */ if (env->sd->flags & SD_ASYM_CPUCAPACITY && //如果是在DIE level,而且 capacity_of(env->dst_cpu) < capacity && //目标cpu的cpu capacity < 该循环遍历到的cpu capacity,而且满足: (rq->nr_running == 1 || //rq只有一个task 或者 rq有2个task但rq上curr的task util < sched_small_task_threshold(102,约等于10%最大cpu capacity) (rq->nr_running == 2 && task_util(rq->curr) < sched_small_task_threshold))) continue; load = cpu_runnable_load(rq); //获取该循环遍历的cpu负载 /* * When comparing with imbalance, use cpu_runnable_load() //用没有基于cpu capacity归一化后的cpu负载与imbalance对比 * which is not scaled with the CPU capacity. */ if (rq->nr_running == 1 && load > env->imbalance && //如果rq只有1个task,并且load > imbalance !check_cpu_capacity(rq, env->sd)) //并且是否因副作用导致capacity减少:rq的cpu_capacity * 对应sd的imbalance_pct >= cpu_capacity_orig *100 continue; /* * For the load comparisons with the other CPU's, consider //对于对于不同cpu之间比较负载的情况,考虑 * the cpu_runnable_load() scaled with the CPU capacity, so //使用经过cpu capacity归一化后的cpu负载, * that the load can be moved away from the CPU that is //这样就能把负载从更低capacity的cpu上迁移走 * potentially running at a lower capacity. * * Thus we're looking for max(load_i / capacity_i), crosswise //因此我们寻找(load/capacity)的最大值 * multiplication to rid ourselves of the division works out //利用交叉相乘:a/b > c/d ---> a*d > c*b * to: load_i * capacity_j > load_j * capacity_i; where j is //最终a/b对应的cpu rq就是最大值 * our previous maximum. */ if (load * busiest_capacity >= busiest_load * capacity) { //如上面所述,进行比较 busiest_load = load; //遍历将busiest load保存 busiest_capacity = capacity; //将busiest cpu_capacity保存 busiest = rq; //保存busiest rq } } return busiest; }
(2-4)进行迁移detach操作,从原rq脱离,返回的是迁移的task数量
/* * detach_tasks() -- tries to detach up to imbalance runnable load from * busiest_rq, as part of a balancing operation within domain "sd". * * Returns number of detached tasks if successful and 0 otherwise. */ static int detach_tasks(struct lb_env *env) { struct list_head *tasks = &env->src_rq->cfs_tasks; //取出繁忙的rq中取出cfs rq队列 struct task_struct *p; unsigned long load = 0; int detached = 0; int orig_loop = env->loop; lockdep_assert_held(&env->src_rq->lock); if (env->imbalance <= 0) //过滤没有imbalance的情况,不进行task迁移 return 0; if (!same_cluster(env->dst_cpu, env->src_cpu)) //如果迁移是跨cluster的 env->flags |= LBF_IGNORE_PREFERRED_CLUSTER_TASKS; //置位flag:LBF_IGNORE_PREFERRED_CLUSTER_TASKS if (capacity_orig_of(env->dst_cpu) < capacity_orig_of(env->src_cpu)) //如果是从orig cpu capacity大的cpu迁移到小的cpu env->flags |= LBF_IGNORE_BIG_TASKS; //置位flag:LBF_IGNORE_BIG_TASKS redo: while (!list_empty(tasks)) { //遍历cfs task /* * We don't want to steal all, otherwise we may be treated likewise, //我们不想移动所有task,否则我们同样可能被欺骗 * which could at worst lead to a livelock crash. //从而最差可能导致活锁crash */ if (env->idle != CPU_NOT_IDLE && env->src_rq->nr_running <= 1) //idle或者newly idle 并且src rq中cfs task <=1,就跳出 break; p = list_last_entry(tasks, struct task_struct, se.group_node); //取队列中最后一个task p env->loop++; //detach task的循环检查遍历统计(并不一定真正detach) /* We've more or less seen every task there is, call it quits */ if (env->loop > env->loop_max) //如果遍历次数超过了最大限制,就跳出 break; /* take a breather every nr_migrate tasks */ if (env->loop > env->loop_break) { //当迁移检查task的数量超过sched_nr_migrate_break env->loop_break += sched_nr_migrate_break; //则需要休息一会 env->flags |= LBF_NEED_BREAK; //置位flag:LBF_NEED_BREAK break; } if (!can_migrate_task(p, env)) //(2-4-1)判断task p是否能迁移到当前this cpu上 goto next; /* * Depending of the number of CPUs and tasks and the //根据cpu、task和cgroup的层级, * cgroup hierarchy, task_h_load() can return a null //task_h_load()可以返回NULL。 * value. Make sure that env->imbalance decreases //所以,为了确保env->imbalance能下降, * otherwise detach_tasks() will stop only after //否则detach_tasks()会知道loop_max才能停下来 * detaching up to loop_max tasks. */ load = max_t(unsigned long, task_h_load(p), 1); //限制最小load = 1 if (sched_feat(LB_MIN) && load < 16 && !env->sd->nr_balance_failed) //LB_MIN特性用于限制迁移小任务,如果LB_MIN等于true,那么task load小于16的任务将不参与负载均衡。目前LB_MIN系统缺省设置为false goto next; /* * p is not running task when we goes until here, so if p is one //当跑到这里时,task p就不处于running了 * of the 2 task in src cpu rq and not the running one, //所以,task p是src rq其中之一,并且是处于非running的一个 * that means it is the only task that can be balanced. //这意味着只有这个tasky p可以进行均衡迁移。 * So only when there is other tasks can be balanced or //所以,仅当有其他task能迁移(task数量>2), * there is situation to ignore big task, it is needed //或者需要忽略big task的场景, * to skip the task load bigger than 2*imbalance. //满足上述条件后,如果task load 大于 2倍的imbalance,那么就skip,不考虑task p * * And load based checks are skipped for prefer_spread in //并且对于prefer_spread,会跳过基于load的busiest group寻找检查 * finding busiest group, ignore the task's h_load. //这部分也会忽略 */ if (!env->prefer_spread && //1.没有设置prefer_spread ((cpu_rq(env->src_cpu)->nr_running > 2) || //2.src rq的cfs task超过2 (env->flags & LBF_IGNORE_BIG_TASKS)) && // 或者 设置了忽略big task的flag ((load / 2) > env->imbalance)) //3.load > 2倍imbalance goto next; //同事满足1.2.3.条件,则跳过该task p detach_task(p, env); //(2-4-2)根据迁移env,进行task剥离 list_add(&p->se.group_node, &env->tasks); //剥离后的task,同时先挂在env->tasks链表上 detached++; //task剥离的计数统计 env->imbalance -= load; //剥离之后,计算剩余的imbalance #ifdef CONFIG_PREEMPTION /* * NEWIDLE balancing is a source of latency, so preemptible //newly idle的情况,对latency要求高。如果有抢占功能的kernel, * kernels will stop after the first task is detached to minimize //则当第一个task剥离之后,需要停止进一步的剥离。 * the critical section. */ if (env->idle == CPU_NEWLY_IDLE) break; #endif /* * We only want to steal up to the prescribed amount of //我们只想平衡之前提到的load量,不要过度迁移 * runnable load. */ if (env->imbalance <= 0) //imbalance消除后,就不再需要过度detach了 break; continue; //如果imbalance没有抹平,或者没有达到跳出循环的条件,就继续进行下一个task检查尝试detach next: #ifdef CONFIG_SCHED_WALT trace_sched_load_balance_skip_tasks(env->src_cpu, env->dst_cpu, env->src_grp_type, p->pid, load, task_util(p), cpumask_bits(&p->cpus_mask)[0]); #endif list_move(&p->se.group_node, tasks); //走到这里说明上面走到了skip的条件,把检查过的task p塞回tasks队列head(因为检查是从list尾开始的) } if (env->flags & (LBF_IGNORE_BIG_TASKS | //如果env->flags中设置了ignore bit task或者ignore perferred cluster task LBF_IGNORE_PREFERRED_CLUSTER_TASKS) && !detached) { //并且此次没有满足条件的task detach(detach task数量为0) tasks = &env->src_rq->cfs_tasks; //重新赋值src rq上的cfs task链表 env->flags &= ~(LBF_IGNORE_BIG_TASKS | //去掉这2个flag LBF_IGNORE_PREFERRED_CLUSTER_TASKS); env->loop = orig_loop; //重新赋值原始的loop计数,之前的遍历计数不算 goto redo; } /* * Right now, this is one of only two places we collect this stat * so we can safely collect detach_one_task() stats here rather * than inside detach_one_task(). */ schedstat_add(env->sd->lb_gained[env->idle], detached); //统计调度相关统计数据:detach task的数量 return detached; //返回的是detach的task数量 }
(2-4-1)判断task p是否能迁移到当前this cpu上
/* * can_migrate_task - may task p from runqueue rq be migrated to this_cpu? */ static int can_migrate_task(struct task_struct *p, struct lb_env *env) { int tsk_cache_hot; int can_migrate = 1; lockdep_assert_held(&env->src_rq->lock); trace_android_rvh_can_migrate_task(p, env->dst_cpu, &can_migrate); //GKI的trace hook,当作没有即可 if (!can_migrate) return 0; /* * We do not migrate tasks that are: //我们有以下这几种情况是不会迁移task的: * 1) throttled_lb_pair, or //1.throttled_lb_pair * 2) cannot be migrated to this CPU due to cpus_ptr, or //2.cpuset限制不能迁移 * 3) running (obviously), or //3.task正处于running * 4) are cache-hot on their current CPU. //4.在当前cpu上是cache hot */ if (throttled_lb_pair(task_group(p), env->src_cpu, env->dst_cpu)) //判断src rq、dst rq是否处于cfs带宽限制状态?如果是,则不迁移 return 0; /* * don't allow pull boost task to smaller cores. //不允许把boost task从大核迁移到小核 */ if (!can_migrate_boosted_task(p, env->src_cpu, env->dst_cpu)) //task处于task boost,且task处于rtg中,且dst cpu的orig_capacity < src cpu的 return 0; #ifdef CONFIG_SCHED_WALT if (p->wts.iowaited && is_min_capacity_cpu(env->dst_cpu) && //task处于iowait,且dst cpu是最小核,且src cpu不是最小核 !is_min_capacity_cpu(env->src_cpu)) return 0; #endif if (!cpumask_test_cpu(env->dst_cpu, p->cpus_ptr)) { //受cpuset限制,dst cpu不能运行task p int cpu; schedstat_inc(p->se.statistics.nr_failed_migrations_affine); //统计因亲和度导致迁移失败的调度信息统计 env->flags |= LBF_SOME_PINNED; //flag记录 some pinned /* * Remember if this task can be migrated to any other CPU in //记住如果这个task能被迁移到我们sg的任一cpu * our sched_group. We may want to revisit it if we couldn't //而且如果从src cpu上pull其他task不能解决imbalance * meet load balance goals by pulling other tasks on src_cpu. //那么我们可以再尝试这个task * * Avoid computing new_dst_cpu for NEWLY_IDLE or if we have //避免考虑newly idle情况下设置new_dst_cpu * already computed one in current iteration. //或者如果我们已经在当前这次遍历中已经设置过了(通过判断LBF_DST_PINNED) */ if (env->idle == CPU_NEWLY_IDLE || (env->flags & LBF_DST_PINNED)) return 0; /* Prevent to re-select dst_cpu via env's CPUs: */ //防止通过env->cpus重新选择dst cpu for_each_cpu_and(cpu, env->dst_grpmask, env->cpus) { //遍历dst_grpmask与env->cpus的交集 if (cpumask_test_cpu(cpu, p->cpus_ptr)) { //判断新cpu是否满足task p的cpuset限制 env->flags |= LBF_DST_PINNED; //如满足,则设置flag:LBF_DST_PINNED env->new_dst_cpu = cpu; //并将其设置为new_dst_cpu break; } } return 0; } /* Record that we found atleast one task that could run on dst_cpu */ env->flags &= ~LBF_ALL_PINNED; //跑到这里,说明至少有一个task而已跑到dst cpu上 #ifdef CONFIG_SCHED_WALT if (static_branch_unlikely(&sched_energy_present)) { //如果开启了EAS struct root_domain *rd = env->dst_rq->rd; if ((rcu_dereference(rd->pd) && !sd_overutilized(env->sd)) && //perf domain存在,且env->sd不处于overutil env->idle == CPU_NEWLY_IDLE && !env->prefer_spread && //且是newly idle,且没有设置prefer_spread !task_in_related_thread_group(p)) { //且task p处于rtg long util_cum_dst, util_cum_src; unsigned long demand; demand = task_util(p); //获取task p的util util_cum_dst = cpu_util_cum(env->dst_cpu, 0) + demand; //计算迁移task p后的dst cumlative_cpu_util util_cum_src = cpu_util_cum(env->src_cpu, 0) - demand; //计算迁移task p后的src cumlative_cpu_util if (util_cum_dst > util_cum_src) //不能迁移后,dst cumlative_cpu_util > src cumlative_cpu_util return 0; } } if (env->flags & LBF_IGNORE_PREFERRED_CLUSTER_TASKS && //如果是跨cluster的迁移, !preferred_cluster( //且task p设置的优先调度cluster与dst cpu所在cluster不匹配 cpu_rq(env->dst_cpu)->wrq.cluster, p)) return 0; /* Don't detach task if it doesn't fit on the destination */ if (env->flags & LBF_IGNORE_BIG_TASKS && //从orig cpu capacity大的cpu迁移到小的cpu的情况 !task_fits_max(p, env->dst_cpu)) //且task不适合dst cpu capacity return 0; /* Don't detach task if it is under active migration */ if (env->src_rq->wrq.push_task == p) //task p正在处于active migration return 0; #endif if (task_running(env->src_rq, p)) { //task p正处于running schedstat_inc(p->se.statistics.nr_failed_migrations_running); //统计因task处于running导致迁移失败的调度信息统计 return 0; } #ifdef CONFIG_SCHED_WALT if ((env->idle == CPU_NEWLY_IDLE) && //newly idle的情况 is_min_capacity_cpu(env->dst_cpu) && //且dst是小核 !is_min_capacity_cpu(env->src_cpu) && //且src是大核 walt_get_rtg_status(p)) { //且task p在rtg内,同时设置了大核cluster的偏好 bool pull_to_silver_allowed = false; unsigned int cpu; for_each_cpu(cpu, env->cpus) { //遍历env->cpus if (!is_min_capacity_cpu(cpu) && //不是小核,且 cpu_overutilized(cpu)) { //cpu处于overutil pull_to_silver_allowed = true; //那么可以考虑从大核迁移到小核 break; } } if (!pull_to_silver_allowed) //如果上面条件判断不满足,则跳出 return 0; } #endif /* * Aggressive migration if: //同意激进地迁移task的条件,满足一下任一: * 1) IDLE or NEWLY_IDLE balance. //1.idle或者newly idle balance * 2) destination numa is preferred //2.dst满足是numa偏向(当前平台UMA,永不满足这一条) * 3) task is cache cold, or //3.task处于cache cold(其实是task hot) * 4) too many balance attempts have failed.//4.有太多balance尝试失败了 */ tsk_cache_hot = migrate_degrades_locality(p, env); //因为当前平台是UMA架构,所以永远返回-1 if (tsk_cache_hot == -1) tsk_cache_hot = task_hot(p, env); //判断是否task p是否task_hot if (env->idle != CPU_NOT_IDLE || tsk_cache_hot <= 0 || //idle或者newly idle,或者task是cold env->sd->nr_balance_failed > env->sd->cache_nice_tries) { //或者失败balance的次数超过了阈值(每个sd不同) if (tsk_cache_hot == 1) { //如果该task是task-hot schedstat_inc(env->sd->lb_hot_gained[env->idle]); //则记录相关统计信息:lb_hot_gained[env->idle] schedstat_inc(p->se.statistics.nr_forced_migrations); //nr_forced_migrations } return 1; } schedstat_inc(p->se.statistics.nr_failed_migrations_hot); //如果最终失败了,则记录统计信息:nr_failed_migrations_hot return 0; }
这里简单看一下task hot的判断过程:
- 不是cfs task,不是hot
- task的调度policy为idle policy,不是hot
- task在原cpu上即将被调度到(已经设置为next或last buddy),是hot。------注意这里是CFS Buddy的概念,不是内存管理的伙伴系统。
- 迁移阈值sysctl_sched_migration_cost为-1,则是hot
- 迁移阈值sysctl_sched_migration_cost为0,则不是hot
- 运行时间 < 迁移阈值sysctl_sched_migration_cost,是task_hot;反之,不是hot
/* * Is this task likely cache-hot: */ static int task_hot(struct task_struct *p, struct lb_env *env) { s64 delta; lockdep_assert_held(&env->src_rq->lock); if (p->sched_class != &fair_sched_class) return 0; if (unlikely(task_has_idle_policy(p))) return 0; /* * Buddy candidates are cache hot: */ if (sched_feat(CACHE_HOT_BUDDY) && env->dst_rq->nr_running && (&p->se == cfs_rq_of(&p->se)->next || &p->se == cfs_rq_of(&p->se)->last)) return 1; if (sysctl_sched_migration_cost == -1) return 1; if (sysctl_sched_migration_cost == 0) return 0; delta = rq_clock_task(env->src_rq) - p->se.exec_start; return delta < (s64)sysctl_sched_migration_cost; }
(2-4-2)根据迁移env,进行task剥离
/* * detach_task() -- detach the task for the migration specified in env */ static void detach_task(struct task_struct *p, struct lb_env *env) { lockdep_assert_held(&env->src_rq->lock); deactivate_task(env->src_rq, p, DEQUEUE_NOCLOCK); //(2-4-2-1)dequeue task出队 lockdep_off(); double_lock_balance(env->src_rq, env->dst_rq); //两个rq一起上锁 if (!(env->src_rq->clock_update_flags & RQCF_UPDATED)) update_rq_clock(env->src_rq); //更新src rq的rq clock set_task_cpu(p, env->dst_cpu); //(2-4-2-2)迁移工作 double_unlock_balance(env->src_rq, env->dst_rq); //两个rq一起解锁 lockdep_on(); }
(2-4-2-1)dequeue task出队
void deactivate_task(struct rq *rq, struct task_struct *p, int flags) { p->on_rq = (flags & DEQUEUE_SLEEP) ? 0 : TASK_ON_RQ_MIGRATING; //当前detach task的路径走到这里,on_rq会置为TASK_ON_RQ_MIGRATING(2) if (task_contributes_to_load(p)) //根据task->state确认处于uninterruptible,且flags不处于freeze,且state不处于TASK_NOLOAD rq->nr_uninterruptible++; //则增加rq上阻塞task计数+1(说明task迁移的中途是算处于uninterrupted) #ifdef CONFIG_SCHED_WALT if (flags & DEQUEUE_SLEEP) //当前没有这个flag,所以不会走清理ed task clear_ed_task(p, rq); #endif dequeue_task(rq, p, flags); //将task出rq }
(2-4-2-2)迁移工作:
- 更新src rq、dst rq、task p的walt负载。并从src rq上减去p的负载,再把p的负载加到dst rq上
- 改变task p的cfs rq和parent entity
- 设置p->cpu、->wake_cpu为dst cpu
void set_task_cpu(struct task_struct *p, unsigned int new_cpu) { ...(这里去掉了一些debug的代码) trace_sched_migrate_task(p, new_cpu); if (task_cpu(p) != new_cpu) { //判断是迁移task的情况 if (p->sched_class->migrate_task_rq) p->sched_class->migrate_task_rq(p, new_cpu); //cfs task调用migrate_task_rq_fair p->se.nr_migrations++; //调度统计task p迁移的次数 rseq_migrate(p); //设置rseq状态:RSEQ_EVENT_MIGRATE_BIT、task flag:TIF_NOTIFY_RESUME perf_event_task_migrate(p); //设置task->sched_migrated = 1 fixup_busy_time(p, new_cpu); //更新walt负载,并从src rq中去掉,加到dst rq上。较复杂,暂不展开了 } __set_task_cpu(p, new_cpu); //通过set_task_rq改变所在的cfs_rq和parent entity,并设置p->cpu、wake_cpu为dst cpu }
set_task_rq就是更新pelt,更改cfs rq/rt rq和parent se/parent rt_se
/* Change a task's cfs_rq and parent entity if it moves across CPUs/groups */ static inline void set_task_rq(struct task_struct *p, unsigned int cpu) { #if defined(CONFIG_FAIR_GROUP_SCHED) || defined(CONFIG_RT_GROUP_SCHED) struct task_group *tg = task_group(p); #endif #ifdef CONFIG_FAIR_GROUP_SCHED set_task_rq_fair(&p->se, p->se.cfs_rq, tg->cfs_rq[cpu]); //以src rq的时间戳更新task p的pelt负载,然后再设置task p的pelt最后更新的时间戳为dst rq的时间戳 p->se.cfs_rq = tg->cfs_rq[cpu]; //修改task p的cfs rq为tg中的dst cpu对应的cfs_rq p->se.parent = tg->se[cpu]; //修改task p的parent se为tg中的dst cpu对应的se #endif #ifdef CONFIG_RT_GROUP_SCHED p->rt.rt_rq = tg->rt_rq[cpu]; //修改task p的rt rq为tg中的dst cpu对应的rt_rq p->rt.parent = tg->rt_se[cpu]; //修改task p的parent rt se为tg中的dst cpu对应的rt_se #endif }
(2-5)将所有task attach到新的rq上
/* * attach_tasks() -- attaches all tasks detached by detach_tasks() to their * new rq. */ static void attach_tasks(struct lb_env *env) { struct list_head *tasks = &env->tasks; //取出detach的所有task的链表 struct task_struct *p; struct rq_flags rf; rq_lock(env->dst_rq, &rf); update_rq_clock(env->dst_rq); //更新dst rq的clock while (!list_empty(tasks)) { p = list_first_entry(tasks, struct task_struct, se.group_node); //从head取一个task list_del_init(&p->se.group_node); //释放group_node attach_task(env->dst_rq, p); //(2-5-1)将task p attach到dst cpu的rq上 } /* * The enqueue_task_fair only updates the overutilized status //enqueue_task_fair函数只会为唤醒的task更新overutil 状态 * for the waking tasks. Since multiple tasks may get migrated //因为复数task触发迁移,若不是在那运行 * from load balancer, instead of doing it there, update the //所以要在最终阶段更新overutil状态 * overutilized status here at the end. */ update_overutilized_status(env->dst_rq); //(2-5-2)更新迁移过后的dst rq的overutil状态 rq_unlock(env->dst_rq, &rf); }
(2-5-1)将task p attach到dst cpu的rq上
/* * attach_task() -- attach the task detached by detach_task() to its new rq. */ static void attach_task(struct rq *rq, struct task_struct *p) { lockdep_assert_held(&rq->lock); BUG_ON(task_rq(p) != rq); activate_task(rq, p, ENQUEUE_NOCLOCK); //(2-5-1-1)以不更新rq clock的flag,将task p压入rq check_preempt_curr(rq, p, 0); //最终调用cfs class的check_preempt_wakeup函数来判断是否要抢占dst rq上的curr进程 }
(2-5-1-1)以不更新rq clock的flag,将task p压入rq
void activate_task(struct rq *rq, struct task_struct *p, int flags) { if (task_contributes_to_load(p)) //根据task->state确认处于uninterruptible,且flags不处于freeze,且state不处于TASK_NOLOAD rq->nr_uninterruptible--; //则增加rq上阻塞task计数11(说明task迁移的中途是算处于uninterrupted) enqueue_task(rq, p, flags); //将task入rq p->on_rq = TASK_ON_RQ_QUEUED; //on_rq设为1 }
(2-5-2)更新迁移过后的dst rq的overutil状态
static inline void update_overutilized_status(struct rq *rq) { #ifdef CONFIG_SCHED_WALT struct sched_domain *sd; rcu_read_lock(); sd = rcu_dereference(rq->sd); //获取dst rq->sd,即MC level的sd if (sd && !sd_overutilized(sd) && //判断sd存在,且sd没有设置overutil flag:sd->shared->overutilized cpu_overutilized(rq->cpu)) //且dst cpu处于overutil:orig_cpu_capcity * 1024 < cpu_util *1078 (相当于105%) set_sd_overutilized(sd); //设置sd over util flag:sd->shared->overutilized = true rcu_read_unlock(); #else if (!READ_ONCE(rq->rd->overutilized) && cpu_overutilized(rq->cpu)) { WRITE_ONCE(rq->rd->overutilized, SG_OVERUTILIZED); trace_sched_overutilized_tp(rq->rd, SG_OVERUTILIZED); } #endif }
(2-6)判断是否需要active balance
static int need_active_balance(struct lb_env *env) { struct sched_domain *sd = env->sd; if (voluntary_active_balance(env)) //(2-6-1)判断是否满足主动触发active balance的条件 return 1; if ((env->idle != CPU_NOT_IDLE) && //src cpu处于idle状态 (capacity_of(env->src_cpu) < capacity_of(env->dst_cpu)) && //src cpu_capacity < dst cpu_capacity ((capacity_orig_of(env->src_cpu) < //且src orig_cpu_capacity < dst orig_cpu_capacity capacity_orig_of(env->dst_cpu))) && env->src_rq->cfs.h_nr_running == 1 && //且src cpu只有一个cfs task cpu_overutilized(env->src_cpu) && //且src cpu处于overutil状态 !cpu_overutilized(env->dst_cpu)) { //且dst cpu不处于overutil状态 return 1; } if (env->src_grp_type == group_overloaded && env->src_rq->misfit_task_load) //src cpu所在group处于overload,且src cpu有misfit task load return 1; return unlikely(sd->nr_balance_failed > sd->cache_nice_tries+2); //当前sd balance fail的失败计数 > 当前sd->cache_nice_tries+2 }
(2-6-1)判断是否满足主动触发active balance的条件
static inline bool voluntary_active_balance(struct lb_env *env) { struct sched_domain *sd = env->sd; if (asym_active_balance(env)) //平台不支持SMT level,也就不会有flag:SD_ASYM_PACKING。所以这里永远为false return 1; /* * The dst_cpu is idle and the src_cpu CPU has only 1 CFS task. //dst cpu处于idle,src cpu只有1个cfs task * It's worth migrating the task if the src_cpu's capacity is reduced //如果src cpu的capacity由于其他sched class或者irq * because of other sched_class or IRQs if more capacity stays //并且dst cpu有更大的capacity,那么是值得迁移task的 * available on dst_cpu. */ if ((env->idle != CPU_NOT_IDLE) && //src cpu处于idle (env->src_rq->cfs.h_nr_running == 1)) { //src cpu只有一个cfs task if ((check_cpu_capacity(env->src_rq, sd)) && //满足src cpu_capacity * sd->imbalance_pct < src cpu_capacity_orig*100 (capacity_of(env->src_cpu)*sd->imbalance_pct < capacity_of(env->dst_cpu)*100)) //满足src cpu_capacity * sd->imbalance_pct < dst cpu_capacity*100 return 1; } if (env->idle != CPU_NOT_IDLE && //如果src cpu处于idle env->src_grp_type == group_misfit_task) //src cpu所在group type == group_misfit_task return 1; return 0; }
参考:
http://blog.chinaunix.net/uid-23141914-id-5767451.html
https://blog.csdn.net/pwl999/article/details/78817905
https://blog.csdn.net/wukongmingjing/article/details/81664820
https://www.cnblogs.com/hellokitty2/p/15673073.html
https://blog.csdn.net/feelabclihu/article/details/112057633?spm=1001.2014.3001.5502

 浙公网安备 33010602011771号
浙公网安备 33010602011771号