Android系统调用卡顿问题分析(cache计数错误,导致走到slow path耗时)
背景
遇到一个android手机系统卡顿的问题,现象是整体系统都卡顿。
在抓取systrace,log等情况下,并未找到明显root cause。但是发现在抓取syatrace的时候,发现会特别卡顿,之后提示systrace抓取失败,但是卡顿会出现一定缓解。
分析
由于systrace抓取提示失败,但是systrace也可以抓取到。那么就先分析systrace。
1、对于systrace分析,发现卡顿时,CPU栏位很多进程运行对比流畅的运行时间都变长了。那么就怀疑系统性能CPU governor、perflock相关参数是否有异常。
----查看perflock的相关log,并未发现异常。
----尝试让CPU运行至performance模式下:
adb shell stop perfd adb shell stop thermal-engine adb shell 'echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor' adb shell 'echo performance >/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor'"
但是结果并没有缓解。说明这里没有问题。
2、使用strace抓取系统调用的耗时。使用的系统调用是cat d/tracing/tracing_on。
Sluggish:
% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 84.00 48.620000 150061 324 162 wait4 13.98 8.090000 49938 162 clone 0.93 0.540000 3333 162 faccessat 0.85 0.490000 3024 162 newfstatat 0.12 0.070000 216 324 rt_sigprocmask 0.07 0.040000 246 162 162 rt_sigsuspend 0.03 0.020000 61 324 getrusage 0.02 0.010000 61 162 162 rt_sigreturn ------ ----------- ----------- --------- --------- ---------------- 100.00 57.880000 1782 486 total
Normal:
% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 81.58 7.040000 1170 6012 3006 wait4 10.66 0.920000 306 3006 clone 2.20 0.190000 63 3006 3006 rt_sigreturn 1.85 0.160000 53 3006 3006 rt_sigsuspend 1.16 0.100000 16 6012 getrusage 1.04 0.090000 29 3006 newfstatat 0.81 0.070000 11 6012 rt_sigprocmask 0.70 0.060000 19 3006 faccessat ------ ----------- ----------- --------- --------- ---------------- 100.00 8.630000 33066 9018 total
对比看出系统调用耗时确实有差异。
2.1、此时,分析log,发现log中有:写fd失败的情况:
2219 13:58:45.690011 write(5, "B|2219|processInputEventForCompa"..., 40) = -1 EBADF (Bad file descriptor) <0.020251>
2219 13:58:45.731469 write(5, "E|2219", 6) = -1 EBADF (Bad file descriptor) <0.019969>
2219 13:58:45.772600 write(5, "C|2219|aq:pending:com.android.la"..., 83) = -1 EBADF (Bad file descriptor) <0.019893>
2219 13:58:45.813815 write(5, "C|2219|aq:pending:com.android.la"..., 83) = -1 EBADF (Bad file descriptor) <0.020056>
2219 13:58:45.854898 write(5, "S|2219|deliverInputEvent|182314", 31) = -1 EBADF (Bad file descriptor) <0.020034>
-----搜索工程源码,发现与systrace有关,并且时systrace打开之后,才会报着个错误。根据分析,得知自动测试工具在开始测试时,打开了atrace,ftrace(trace event)并且一直处于打开状态。这就导致了debug工具的开销。
并且这也与:问题发送后,adb抓取systrace,出现非常卡顿,并且提示抓取失败。这个对上了。
2.2、根据写fd失败,查看fd是否有leak
Catch the fd size from the problem and normal device whether have fd leak or not, command:
adb shell ls -a -l /proc/<pid>/fd
Note: <pid> use the launch pid when you catch strace find EBADF (Bad file descriptor).
-----而对比正常机器,发现没有区别。所以没有发现fd leak。
2.3、由于systrace和ftrace在测试时,理论上会对性能产生影响。所以尝试关闭atrace和ftrace。
echo 0 > d/tracing/tracing_on
atrace的关闭,由公司自带的log工具关闭。
----关闭之后,发现卡顿有缓解,但是仍然有卡顿。所以,trace的打开,只是加重了问题。并不是问题的root cause。
3、所以,问题仍然回到系统调用慢的点上。首先,我们自己写daemon来验证是否所有系统调用都慢。都循环执行1000次。记录耗时。
normal: ./ljj_test_chmod 1000 time = 0.145072 s sluggish: ./ljj_test_chmod 1000 < time = 1.273793 s
----最后测试发现,read和write都不慢,而chmod慢。
3.1、系统调用有一个上层到底层,底层再执行的流程。需要进一步区别是上层卡顿,还是底层卡顿。使用自己写ko,来模拟调用系统调用函数的功能(fake_chmod),这样就可以不走原始的系统调用上层到底层的切换路径。
发现异常机器运行fake_chmod 10,000次时,耗时约8s;而正常机器耗时约100ms。
正常: [ 441.655999] [ljj]--fake_chmod using time:----111414 us------- [ 444.462106] [ljj]--fake_chmod using time:----97527 us------- [ 445.282546] [ljj]--fake_chmod using time:----97601 us------- [ 445.887255] [ljj]--fake_chmod using time:----104818 us------- 异常: [33441.655999] [ljj]--fake_chmod using time:----847745 us------- [33454.462106] [ljj]--fake_chmod using time:----855120 us-------
所以,可以确定为是底层执行卡顿。
----最后由于调用函数都在kernel/msm-4.4/security目录下,而且没有EXPORT_SYMBOL的情况下,无法从外部驱动模块调用到。
进一步通过代码搬移至ko,并统计执行时间,逐步确定具体函数执行慢。最后定位到的到文件路径:kernel/msm-4.4/security/selinux/avc.c中,函数:
inline int avc_has_perm_noaudit(u32 ssid, u32 tsid, u16 tclass, u32 requested, unsigned flags, struct av_decision *avd) {...}
通过阅读源码,得知该函数主要是获取selinux权限。大概如下图流程:

首先,在avc_lookup中,会从cache中(链表形式)寻找是否有对应的node信息。
如果有,则说明cache中有其所需的node,该node可能是以前使用后,未删除,而暂时留下来的。这种情况为 “cache hit”,即命中。
如果没有,则说明cache中,没有找到对应的node信息。可能是第一次使用,或者之前使用过,但是又因有其他任务,从而将原有的信息删除了,并拿了这块空出来的区域用为他所用。这种情况为 :cache miss,即未命中。
cache命中的情况下,只需要进行memcpy将node相关所需信息拿出来,再进行avc_denied检查等后续操作。
cache miss情况下(图①),就要先数据库中计算node信息,再通过avc_insert将node信息插入到cache中。而在avc_insert时,需要alloc一块cache空间;特别地,当alloc后,如果发现cache占用过高,那么就会释放一部分空间(图②)。
明显地,cache miss所走的path,耗时会更久,所以称之为slow path。
在review代码之后,查看问题机器执行fake_chmod 10,000次的cache命中情况: cat /sys/fs/selinux/avc/cache_stats
//正常机器运行前: lookups hits misses allocations reclaims frees 23187537 23124553 62984 63150 62454 60260 20434969 20374575 60394 60566 60216 50517 18330847 18280869 49978 50182 49977 50264 17317682 17272289 45393 45569 45657 49079 430515 423863 6652 6675 6672 7343 265785 261269 4516 4533 4480 6409 201131 197895 3236 3249 3008 6487 172877 169515 3362 3483 3312 6543 ljj_test_fake_chmod < time = 0.112603 s //执行耗时统计 //正常机器运行后: at cache_stats < lookups hits misses allocations reclaims frees 23194982 23131885 63097 63269 62566 60264 20469561 20409126 60435 60614 60248 50550 18334425 18284421 50004 50208 50025 50335 17320975 17275539 45436 45613 45689 49191 430526 423873 6653 6676 6672 7343 265785 261269 4516 4533 4480 6409 201131 197895 3236 3249 3008 6487 172877 169515 3362 3483 3312 6543 //异常机器运行前: lookups hits misses allocations reclaims frees 971289729 656353670 314936059 339178248 310834367 342811215 972377800 651582180 320795620 344829862 316471384 311197215 915458450 618594490 296863960 319042163 295077970 326028798 896110657 607686470 288424187 310257397 287423325 302467740 106258222 60765514 45492708 50898382 46644872 63577420 88490287 48868990 39621297 44798236 41082299 52686525 75120396 40132999 34987397 39692446 36400656 45221533 64284038 33280908 31003130 35287157 32380719 39992301 ljj_test_fake_chmod < time = 8.423614 s //执行耗时统计 //异常机器运行后: at cache_stats < lookups hits misses allocations reclaims frees 971303164 656355395 314947769 339192245 310845654 342829606 972398523 651583389 320815134 344854768 316491378 311205305 915465486 618595626 296869860 319048945 295084119 326042782 896121748 607687931 288433817 310268808 287432647 302482901 106258925 60765624 45493301 50899013 46645498 63579027 88490912 48869115 39621797 44798736 41082748 52687127 75120822 40133080 34987742 39692791 36400963 45221953 64284298 33280952 31003346 35287373 32380903 39992851
结果是cache命中和miss统计对比:
----每一行代表每个CPU的cache动作统计情况;从对比可以看出,问题机器的cache的miss异常多。
3.2、接着做一个实验,验证是否是由cache miss多导致耗时:修改代码,强制让cache每次都miss。在此条件下,执行fake_chmod。并将统计结果进行对比。
代码修改如下:
inline int avc_has_perm_noaudit(u32 ssid, u32 tsid, u16 tclass, u32 requested, unsigned flags, struct av_decision *avd) { struct avc_node *node; struct avc_xperms_node xp_node; int rc = 0; u32 denied; BUG_ON(!requested); rcu_read_lock(); node = avc_lookup(ssid, tsid, tclass); // if (unlikely(!node)) if (true) //强制走slow path node = avc_compute_av(ssid, tsid, tclass, avd, &xp_node); else memcpy(avd, &node->ae.avd, sizeof(*avd)); denied = requested & ~(avd->allowed); if (unlikely(denied)) rc = avc_denied(ssid, tsid, tclass, requested, 0, 0, flags, avd); rcu_read_unlock(); return rc; }
在正常机器上同样条件下,运行fake_chmod 10,000次。
正常机器在此情况下运行fake_chmod的耗时约345ms左右。原先为100ms左右。 htc_ocla1_sprout:/ # ljj_test_fake_chmod time = 0.344776 s htc_ocla1_sprout:/ # ljj_test_fake_chmod time = 0.352717 s htc_ocla1_sprout:/ # ljj_test_fake_chmod time = 0.347103 s
avc lookup每次都失败的cache结果: lookups hits misses allocations reclaims frees 1746506 1728213 18293 1575327 18680 1410091 1637454 1621261 16193 1497606 15904 1090521 1394521 1378308 16213 1266932 16232 1302659 1301033 1285008 16025 1173210 16016 1137053 315223 308678 6545 288375 6128 391818 227894 222486 5408 202401 5072 398590 215968 211463 4505 197030 4464 316184 164899 161452 3447 147490 3728 299837 ljj_test_fake_chmod < time = 0.347440 s cat cache_stats < lookups hits misses allocations reclaims frees 1754216 1735909 18307 1583000 18680 1451010 1671116 1654917 16199 1540734 15904 1096622 1396101 1379885 16216 1268411 16248 1308467 1303259 1287232 16027 1175333 16032 1138721 315223 308678 6545 288375 6128 391818 227894 222486 5408 202401 5072 398590 215968 211463 4505 197030 4464 316184 164899 161452 3447 147490 3728 299837
----看到cache miss会产生部分耗时,执行fake_chmod 10,000次耗时340多ms。但是并没有那么严重。单单cache miss不足以造成 8s左右的卡顿。
3.3、cache miss的耗时不够多,但是在avc_alloc_node的时候,还有一种情况可能会增加更多耗时。那就是avc_reclaim_node。
首先,我们走reclaim的条件是active_nodes的计数超过512:
#define AVC_DEF_CACHE_THRESHOLD 512 unsigned int avc_cache_threshold = AVC_DEF_CACHE_THRESHOLD; static struct avc_node *avc_alloc_node(void) { struct avc_node *node; node = kmem_cache_zalloc(avc_node_cachep, GFP_NOWAIT); if (!node) goto out; INIT_HLIST_NODE(&node->list); avc_cache_stats_incr(allocations); if (atomic_inc_return(&avc_cache.active_nodes) > avc_cache_threshold) //这个条件 avc_reclaim_node(); out: return node; }
reclaim的工作是:avc_node_delete(node),最终会调用avc_node_free释放cache中的node;通过执行 AVC_CACHE_SLOTS(512)个循环,每个循环中都会释放 AVC_CACHE_RECLAIM(16)个node区域的cache。
#define AVC_CACHE_SLOTS 512 #define AVC_CACHE_RECLAIM 16 static inline int avc_reclaim_node(void) { struct avc_node *node; int hvalue, try, ecx; unsigned long flags; struct hlist_head *head; spinlock_t *lock; for (try = 0, ecx = 0; try < AVC_CACHE_SLOTS; try++) { //512个slots hvalue = atomic_inc_return(&avc_cache.lru_hint) & (AVC_CACHE_SLOTS - 1); head = &avc_cache.slots[hvalue]; lock = &avc_cache.slots_lock[hvalue]; if (!spin_trylock_irqsave(lock, flags)) continue; rcu_read_lock(); hlist_for_each_entry(node, head, list) { avc_node_delete(node); //释放node avc_cache_stats_incr(reclaims); ecx++; if (ecx >= AVC_CACHE_RECLAIM) { //释放 >= 16个node rcu_read_unlock(); spin_unlock_irqrestore(lock, flags); goto out; } } rcu_read_unlock(); spin_unlock_irqrestore(lock, flags); } out: return ecx; }
static void avc_node_delete(struct avc_node *node) { hlist_del_rcu(&node->list); call_rcu(&node->rhead, avc_node_free); atomic_dec(&avc_cache.active_nodes); }
3.4、同样,我们修改代码,强制每次都会走reclaim,在正常机器上同样条件下,再运行fake_chmod 10,000次,对比结果。(这种情况下,开机也会变慢)
强制每次都miss,并且每次都reclaim的情况下,使用正常机器运行fake_chmod的耗时升至8s~10s左右。 结果: ljj_test_fake_chmod < time = 10.581583 s ljj_test_fake_chmod < time = 8.768812 s ljj_test_fake_chmod < time = 8.605706 s ljj_test_fake_chmod < time = 8.736812 s 运行前cache的状态: at cache_stats < lookups hits misses allocations reclaims frees 808029 1 808028 808824 804804 560827 774148 4294967289 774155 774755 767816 558873 736701 4294967295 736702 737697 741580 682063 701313 4294967293 701316 702657 705379 560204 348709 12 348697 349180 338592 438551 321032 0 321032 322125 314029 494335 299315 1 299314 299889 293578 484229 284034 4294967293 284037 284500 280105 499697 运行后cache的状态: at cache_stats < lookups hits misses allocations reclaims frees 832271 2 832269 833175 827599 599088 800831 4294967287 800840 801536 792799 601820 772677 4294967295 772678 783641 782626 702908 744729 4294967294 744731 746074 747821 585720 353841 12 353829 354312 343192 449580 325184 0 325184 326313 317807 503468 302466 1 302465 303112 296559 487904 286127 4294967293 286130 286606 282152 503592
----可以看到各个CPU cache 命中几乎没有增长。而执行耗时已经与异常机器相近。
那么真实情况下,是否会出现每次都reclaim呢?再次review代码,reclaim的条件是active_nodes > 512,那么再异常机器上是否满足了这个条件了呢?
我们有抓取一台机器的ramdump,使用trace32解析,查看active_nodes的计数:

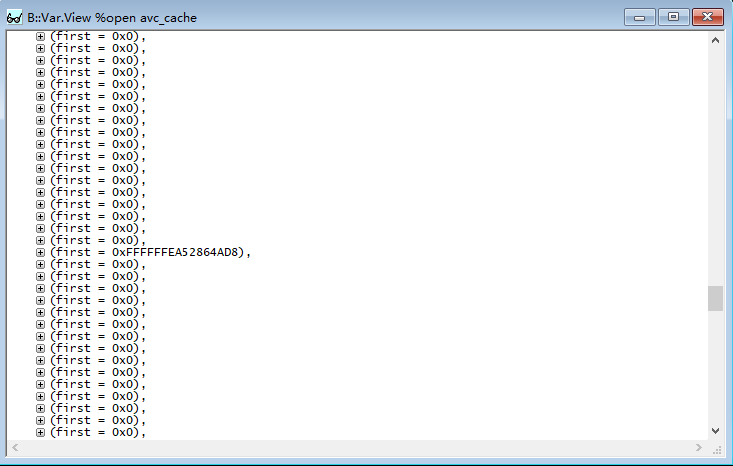
发现计数超过512,并且达到了1626(十进制)!但是这种情况,根据代码逻辑,正常情况下理论上不可能出现的。(因为正常情况下,每当计数超过512,就会reclaim,而reclaim中会释放node,此时计数就会减少。所以正常情况计数不会超过512)
并且在数据中,仅发现一个有效数据!
那么,我们review所有与计数相关的代码。发现在执行 avc_insert 的 avc_alloc_node 中,计数会增加1;而当 avc_xperms_populate 出错时,直接return NULL,并没有将计数减1。同样地,在 avc_update_node 中也是同样的问题。
分析之前抓取的log,发现确实有出现分配cache失败的一些log,那么也就证实了我们所猜测的代码逻辑。
11-29 19:52:50.393 10114 24627 24627 W SLUB : Unable to allocate memory on node -1 (gfp=0x2008000) 11-29 19:52:50.393 10114 24627 24627 W cache : avc_xperms_node, object size: 56, buffer size: 56, default order: 0, min order: 0 11-29 19:52:50.393 10114 24627 24627 W node 0 : slabs: 122, objs: 8906, free: 0 11-29 19:52:50.393 10114 24627 24627 W Thread-1561: page allocation failure: order:0, mode:0x2200000
----所以,我们在代码中添加上减1,确保计数准确。
static struct avc_node *avc_insert(u32 ssid, u32 tsid, u16 tclass, struct av_decision *avd, struct avc_xperms_node *xp_node) { struct avc_node *pos, *node = NULL; int hvalue; unsigned long flag; if (avc_latest_notif_update(avd->seqno, 1)) goto out; node = avc_alloc_node(); if (node) { struct hlist_head *head; spinlock_t *lock; int rc = 0; hvalue = avc_hash(ssid, tsid, tclass); avc_node_populate(node, ssid, tsid, tclass, avd); rc = avc_xperms_populate(node, xp_node); if (rc) { + atomic_dec(&avc_cache.active_nodes); //需要将计数减1 kmem_cache_free(avc_node_cachep, node); return NULL; } head = &avc_cache.slots[hvalue]; lock = &avc_cache.slots_lock[hvalue]; spin_lock_irqsave(lock, flag); hlist_for_each_entry(pos, head, list) { if (pos->ae.ssid == ssid && pos->ae.tsid == tsid && pos->ae.tclass == tclass) { avc_node_replace(node, pos); goto found; } } hlist_add_head_rcu(&node->list, head); found: spin_unlock_irqrestore(lock, flag); } out: return node; }
最后修改代码之后,压力测试没有再出现卡顿。
最后查看了一下最新的linux kernel mainline,这个问题果然已经被大神们解决了:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=d8db60cb23e49a92cf8cada3297395c7fa50fdf8
总结
这个卡顿问题是一个linux kernel通用的bug,目前证实4.4,4.9版本都有这个问题。并且在内存紧张时,会容易触发。(同时联想到之前出现问题的机器都是运存3G的,而4G的没有出现过卡顿)
在这个问题中,使用了systrace、strace、trace32等分析卡顿的工具。同时,也使用了一些非常规的调试方法,例如写fake_chmod.ko以及对应的daemon。最后还是通过非常规的方法才找到了问题所在。
遇到卡顿问题,不能急躁。按部就班,一步一步来。最后还是要自信一点,没有哪个软件bug是解不掉的!
后续可能要利用ftrace的function_graph来尝试分析这个问题,看看是否会更简单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号