软工实践寒假作业 (2/2)
总览和相关链接
| 这个作业属于哪个课程 | 2021春/S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 学习使用git以及github,制定自己的代码规范,Fork项目到自己的仓库,代码性能分析改进,学习并进行单元测试 |
| 其他参考文献 | ... |
Part1:阅读《构建之法》并提问
-
问题1:我看了邹欣老师的博客园讲义中有关创新的章节,那么如何持续创新呢?
我的想法: 我认为一个新事物刚出现,一定有很多不足的地方,所以一开始的创新是很容易的,越到后面就越难,需要我们从多方面考虑,比如用户体验方面、使用方法方面等等,一旦停止创新就会被淘汰。 -
问题2:如何在用户体验方面创新呢?(接上一个问题)
我的想法:可以根据自己对产品的期望来,自己体验好了就成功了一半,还要考虑不同类型用户的体验,比如老人、小孩,老人的话可以把字体放大,小孩则可以增加防误触模式 -
问题3:如何进行软件设计?(邹欣老师的博客园讲义)
我的想法:先明确用户期望的功能,实现这些功能所涉及的模块,寻找一个合适的设计模式、框架,可以从比较成熟的项目中学习框架,这样就省了很多时间。 -
问题4:测试要达到什么样的目标才能算通过?(邹欣老师的博客园讲义)
我的想法:我认为当一个软件能够符合几乎全部用户的使用要求时,并且几乎没有bug的时候才能通过。测试一定要仔细认真,不然可能导致很大的问题。 -
问题5:如何得出程序员在工作中的贡献值(邹欣老师的博客园讲义)
我的想法:可以根据程序员实现的功能数量来看,也可以根据程序员认真工作的时间来看(但是这个很难评判)
Part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 2 h | 1.5 h |
| Estimate | 估计这个任务需要多少时间 | 72 h | 72 h |
| Development | 开发 | 24 h | 24 h |
| Analysis | 需求分析 (包括学习新技术) | 4 h | 4 h |
| Design Spec | 生成设计文档 | 1 h | 1 h |
| Design Review | 设计复审 | 1 h | 1 h |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 1 h | 0.5 h |
| Design | 具体设计 | 2 h | 2 h |
| Coding | 具体编码 | 4 h | 4 h |
| Code Review | 代码复审 | 2 h | 2 h |
| Test | 测试(自我测试,修改代码,提交修改) | 5 h | 5 h |
| Reporting | 报告 | 2 h | 2 h |
| Test Repor | 测试报告 | 2 h | 2 h |
| Size Measurement | 计算工作量 | 1 h | 1 h |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 1 h | 1 h |
| 合计 | 124 h | 123 h |
解题思路描述
需要实现的功能:1、统计英文文本中字符的个数,2、统计英文文本中单词的个数,3、统计英文文本的行数,4、统计出现频率最高的10个单词
我的思路:1、按字符读取文本中的内容存到String中,计算String的大小即可,2、将String按空格隔开,拆成String数组,遍历数组,依次与正则表达式进行匹配,匹配成功则加入Map中,其中key为单词,value为单词的数量,并计算Map的大小,即为单词个数,3、将String按'\n'分组,组数即为文本行数,4、将Map进行排序,可以利用优先队列,并重写compare函数,最后将排完序的Entry输出
代码规范制定链接
设计与实现过程
计算模块接口的设计与实现过程
我写了两个类,WordCount类和Calculate类,WordCount类是主类,用来对文件进行读取操作,其只包含一个main函数,
Calculate类是计算的核心类,包括四个函数,分别用来实现统计字符数、统计单词数、行数、高频词汇,并将结果写入输出文件中。
关键函数:
- 计算单词数:利用正则表达式匹配单词,匹配成功则将单词数量+1
for(int i = 0; i < words.length; i++) {
if(words[i].matches("[a-z]{4}[a-z0-9]*")) count++;
}
- 找出高频词汇:利用优先队列对哈希表进行排序,需要重写compare函数
PriorityQueue<Map.Entry<String, Integer>> list = new PriorityQueue<>(cmp);
@Override
public int compare(Map.Entry<String, Integer> item1, Map.Entry<String, Integer> item2){
return item2.getValue().compareTo(item1.getValue()); //降序排序
}
性能改进
1、原先是在每个功能函数中进行文件读取,耗费大量时间。后来改成在主函数中读取文件并存储,其他函数共享已存储的文件内容。
2、认真读了下题目才发现忽略大小写,于是我将读入的大写字母全部变成小写字母存储
3、原本使用选择排序对哈希表排序,后来改成了优先队列,优先队列使用的是堆排序,时间复杂度为O(nlogn)
单元测试
- 使用JUnit4对统计字符数、统计单词数、统计高频词汇函数进行了单元测试
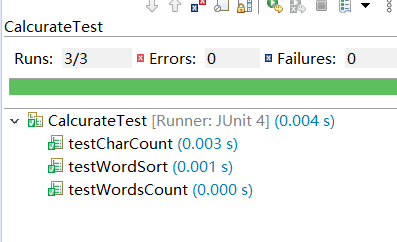
以下是覆盖率截图
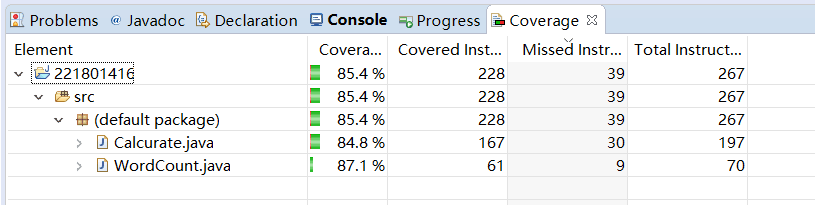
当文件不存在时就新建文件的代码没有被用到,因为我一开始就建了文件,但是为了安全起见还是要写进去
- 测试部分例子截图
数字加字母加大写字母的情况


全中文时


中文加英文时


两万个字符时没有溢出

异常处理说明
测试函数的时候,函数不能包含参数,也不能throws异常
心路历程与收获
一开始看到这个作业要求的时候都看不懂,什么是单元测试也不知道,后来静下心来看题目发现也不是那么难,通过这次作业我学会了github的使用和单元测试,
只是对github的使用还不太熟练,经常会碰到错误,而且github的网站经常连不上,唉。但是现在项目合作都是使用github,还是要硬着头皮学。
