西邮Linux兴趣小组2014级免试挑战题
又到了小组纳新的季节^_^,时间过的真快! 想起去年这会儿自己做免试题的时候根本找不着北@_@ 有幸今年能够在这里和大家分享免试挑战题,也正如我们的纳新宣传语:"在这里,让每一个意想不到成为意料之中"。
免试题共有设五关,分别由小组13级成员:郭遗欢、李林翰、高朴、王博、王伟豪 五位同学负责出的,在此向他们付出的辛苦表示感谢!
计算机的世界是从0和1开始的,正如前两年的免试题一样,都是用一大串的01开头,虽然今年的免试题并不是这样,但几乎每一关都有01的身影~_~。免试题旨在发散同学们的思维,运用计算机方面的基础知识,挑战通关,超越自我 !!下面是前两年的免试题链接:
2012级免试题: 西邮Linux小组免试题揭秘
2013级免试题: 西邮Linux兴趣小组13级纳新免试题浅析
下面由博主来简单分析一下今年的免试题,由于能力有限,有啥不够严谨之处欢迎大家留言交流~
【 第一关】
首先是小组微信公众号(xiyoulinux)上推出了免试题的最新动态,给的是一个链接:orz.xiyoulinux.org。打开后发现是一个伪造的静态页面(下图),之所以说是伪造的,是因为小组官网是www.xiyoulinux.org,而且页面都一样,明显是个克隆品。

随便点了几下,发现上面的链接都失效了,查看一下网页源码,啥都没有提示。注意到推送消息上有明显的这么一句话:“小伙伴们这边瞧 <img src="一张图"/>”结合给的这个页面,可能是在图片里藏了啥吧,试试看咯~将图片下载下来,挺大的,大概有6M,用vim打开这个sign.png文件,往下看看,发现最后面藏了一堆\xXX的字符串: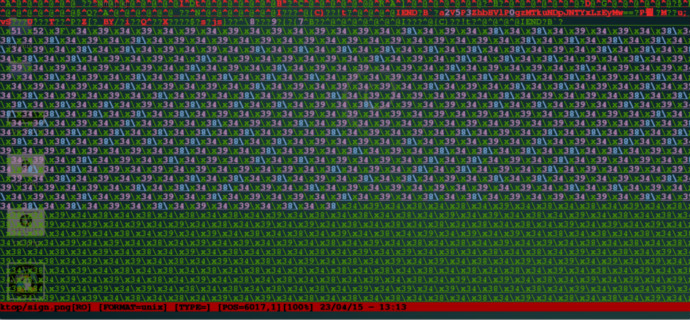
是hex格式的字符串,貌似后面的都是\x34\x38\x39之类的,复制前面一部分出来,找个在线的编码解码工具(http://bianma.911cha.com/)一下看看,在文本格式里发现了些猫腻:

注意到开头的两个字母:“QR”。QR是什么玩意?百度搜一下看看:

发现是二维码,也就是说QR后面的应该是一个二维码。继续分析后面的一堆数字:4948...,容易发现在ASCII码中,ASCII码为48的对应字符是0,49对应的是1.而在二维码中只有黑和白,所以0和1应该对应这两种颜色。现在,根据上面的想法试试:
将sign.png图片末尾\xXX格式的字符串复制到hex.txt,用python写个简单的脚本处理下:
#!/usr/bin/env python
# coding=utf-8
import binascii
# 将\xXX字符串转换为ASCII字符串
f = open('hex.txt')
str = (str(f.readline())).replace('\n','')
f.close()
list = []
for i in str[12:].split('\\x'):
ascii = binascii.a2b_hex(i)
list.append(ascii)
str1 = ''.join(list)
# 将ASCII字符串转换成0,1的字符
i = 0
bin = []
while i < len(str1):
bin_num = "%c" % int(str1[i:i+2])
bin.append(bin_num)
i += 2
bin_str = ''.join(bin)
print 'len(bin_str)=%d' % len(bin_str)
print 'bin_str=%s' % bin_str
上面的脚本运行后结果如下: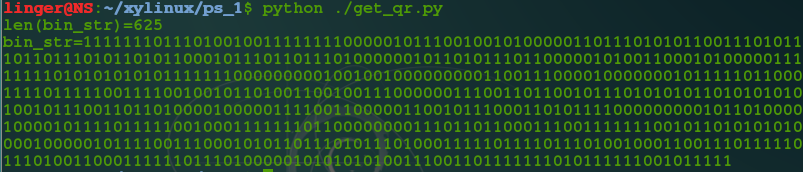
长度是625,正好是25x25的方正,找一个简单的二维码看一下格式就知道上面的分析是对的了^_^,下面就开始转换成二维码了,将上面的bin_str保存成qr_bin.txt,用python写个脚本(由于之前是每个数字生成一个像素点,发现二维码太小,所以将每个数字生成4个像素点):
#!/usr/bin/env python
# coding=utf-8
import Image
MAX = 25
pic = Image.new("RGB",(MAX*2, MAX*2))
f = open('qr_bin.txt')
str = str(f.readlines())
f.close()
i = 2
for y in range (0,MAX):
for x in range (0,MAX):
if(str[i] == '1'):
pic.putpixel([2*x,2*y],(0, 0, 0))
pic.putpixel([2*x+1,2*y],(0, 0, 0))
pic.putpixel([2*x,2*y+1],(0, 0, 0))
pic.putpixel([2*x+1,2*y+1],(0, 0, 0))
else:
pic.putpixel([2*x,2*y],(255,255,255))
pic.putpixel([2*x+1,2*y],(255,255,255))
pic.putpixel([2*x,2*y+1],(255,255,255))
pic.putpixel([2*x+1,2*y+1],(255,255,255))
i = i+1
pic.show()
pic.save("qr_code.png")
扫描二维码得到的结果是“never_give_up.php?key=value”。明显是个链接,访问这个链接发现没反应。看看这个链接,应该是要求找到key、value啥的。可能还有信息没有找到,打开之前的图片发现在\xXX字符串的上面还有一段明显的base64编码的字符串:“a2V5P3ZhbHVlP0gzMTkuNDpJNTYxLzEyMw==”,找个在线的编码一下,得到“key?value?H319.4:I561/123”看到了key和value,后面的就应该有这些信息吧。关键是,这个“H319.4:I561/123”是啥?呵呵,这会儿,就得考考常识了~~去图书馆借过书的同学可能就有意识了,这就是个索书号!!在图书馆官网上查了下,是本《莎士比亚十四行诗》,一共有四本。

莫非在书里有标记啥的?有个key、value?这是个坑么@_@?仔细想想,书上的统一编号(ISBN号)不就是个键-值对么!!当然,能想到这个,也是智力思维啊。替换key和value,访问链接:http://orz.xiyoulinux.org/never_give_up.php?ISBN=978-7-5135-1730-0 成功跳到第二关的页面^_^
【 第二关】

网页迷宫,有点意思哈,点进去试试,这尼玛分支咋越点越多,每个链接下面还有个0或者1,还是黑体加粗的,看来上面图片上说的很重要啊!既然是迷宫,就是要找到终点的那个出口嘛,当然走的路径很多,那估计也只有一个才是正确的吧。如果用0或者1表示通路或者障碍的话,点几个链接后发现不对:存在对应多个链接的情况哎。迷宫的常用算法是深度优先,广度优先等等。这些算法就是求最短路径的。所以,尝试着跑跑吧~~用深度优先试试发现不对。改用广度优先后跑了一分多钟发现可以到达终点:888888.html,下面是python写的脚本:
#!/usr/bin/env python
# coding=utf-8
import re
import urllib
from collections import deque
queue = deque()
visited = set()
url = '101223.html'
re_href = re.compile('href="(\d+\.html)"')
queue.append(url)
cnt = 1
while queue:
url = queue.popleft()
visited = visited | {url}
print(str(cnt) + ' Running: ' + url),
cnt += 1
urlop = urllib.urlopen('http://lewin.aliapp.com/'+url)
try:
data = urlop.read().decode('utf-8')
except:
continue
for x in re_href.findall(data):
if (x not in visited) and (x not in queue):
queue.append(x)
但是,到达888888.html页面后,发现还需要提交key,联想到去年与这类似的题,就算手动点到的终点,没有key不是白费的么?是不是有种想剁手的感觉!!好吧,不是说页面上的数字很重要么,全部记录下来吧,稍微改一下上面的代码:
#!/usr/bin/env python
# coding=utf-8
import re
import urllib
from collections import deque
queue = deque()
visited = set()
bin = []
url = '101223.html'
re_href = re.compile('href="(\d+\.html)"')
re_bin = re.compile('<h1>(\d)')
queue.append(url)
cnt = 1
while queue:
url = queue.popleft()
visited = visited | {url}
print(str(cnt) + ' Running: ' + url),
cnt += 1
urlop = urllib.urlopen('http://lewin.aliapp.com/'+url)
try:
data = urlop.read().decode('utf-8')
except:
continue
try:
bin_num = re_bin.search(data).group(1)
print bin_num
bin.append(bin_num)
except:
print '\nMaybe got the last!'
break
for x in re_href.findall(data):
if (x not in visited) and (x not in queue):
queue.append(x)
str = ''.join(bin)
print "\nbin_str= %s" % str
跑出来是下面的结果,将没一个页面的数字加起来又是一个长长的01字符串:

莫非又要进行啥转换?先试试直接提交看看吧,把这个长字符串提交,发现居然直接挑到下一关^_^,看来没啥要处理的。
【 第三关】
第三关的页面上有两张一样的图片:

查看一下网页源码,也没发现啥的,看看URL(http://www.geekgao.org/new/guess.html)注意到guess,那是叫咋猜啥呢?先把这两张图片down下来看看吧。既然是两张一样的图片肯定有啥区别,用binwalk(ps:binwalk是一个强大的文件格式分析工具,见FreeBuf介绍)分析一下这两张图片:
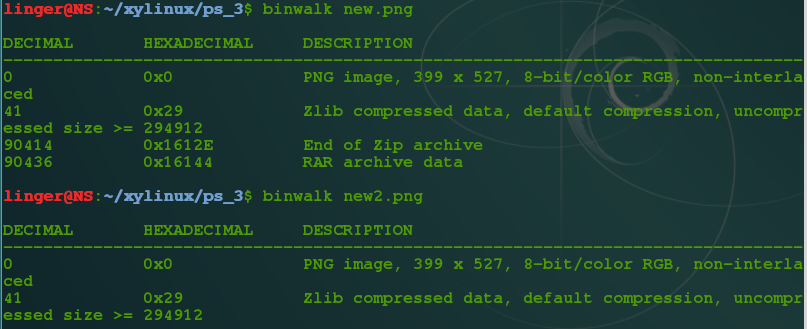
呵呵,第一张图片结尾藏了个zip文件,还藏了个rar文件,解压zip压缩包:unzip new.png 生成了一个???.txt文件,在linux下中文乱码,放到windows下可以看到“新建文本文档.txt”,看了下大小,居然是0,那就啥也没有咯,再看看那个rar文件吧,解压:unrar x new.png 提示需要密码,看来需要找密码了。不是还有一张对比的图片么,但是发现没藏啥的。看到上面两图片的Zlib数据包(ps:zlib是一种数据压缩的格式,在图片中存储图片像素点的数据块),通过神器Stegsolve(ps:Stegsolve是图片通道查看器,图片隐写必备工具,下载)来分析一下张两张图片的IDAT数据块吧。对比IDAT块的CRC(数据块校验和),发现有两张图片中有明显的的两个数据块不一样:
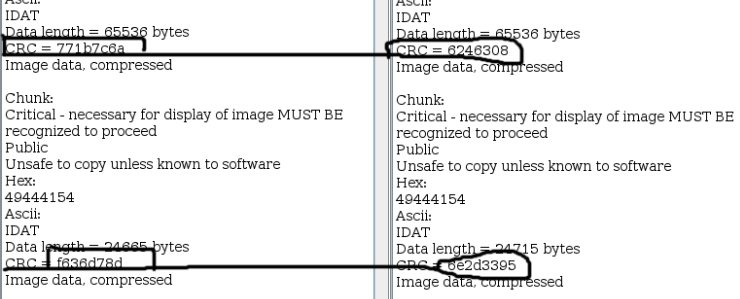
那就是像素点有不同了,用PS试试?不太会唉,好吧,写个python脚本对比一下像素点吧:
#!/usr/bin/env python
# coding=utf-8
from PIL import Image
list = []
img1 = Image.open("new2.png")
img2 = Image.open("new.png")
img1_array = img1.load()
img2_array = img2.load()
count = 0
for j in range(527):
for i in range(399):
if (img1_array[i,j]) != (img2_array[i,j]):
print i, j, img1_array[i,j],img2_array[i,j]
list.append(str(i))
list.append(str(j))
count += 1
print 'count= %d' % count
print 'pwd = '+''.join(list)
分析的结果如下,居然有20个不同的像素点(之后用PS之类的在放大之后发现也能看见图片的小点点~_~):
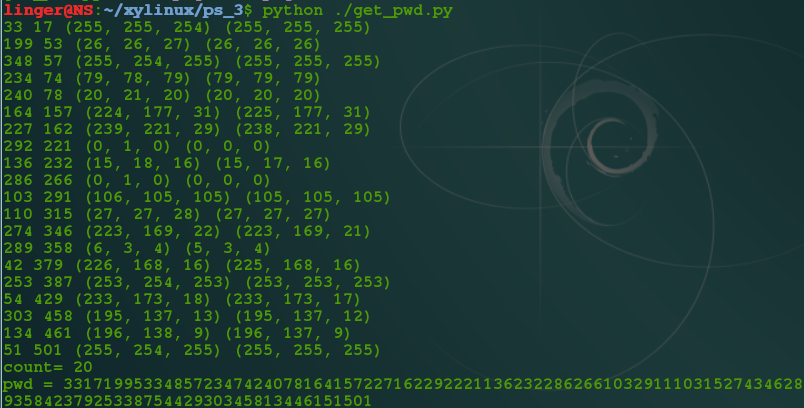
将各点的坐标连接起来之后,就是上面的pwd了,好吧,把这个字符串当密码来解压那个含有rar文件的图片,发现解压成功。至此第三关算是解出来了~~
在下一篇的博客中将继续分享:西邮Linux兴趣小组2014级免试挑战题(续)

