基于模糊K均值FuzzyKMeans聚类的协同过滤推荐算法代码实现(输出聚类计算过程,分布图展示)
基于模糊K均值FuzzyKMeans聚类的协同过滤推荐算法代码实现(输出聚类计算过程,分布图展示)
聚类(Clustering)就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。
一、FuzzyKMeans聚类算法实现原理
模糊K均值聚类算法是K均值(KMeans)聚类的扩展,它的基本原理和K均值一样,只是它的聚类结果允许存在对象属于多个簇,也就是说:它属于可重叠聚类算法。为了深入理解模糊K均值和K均值的区别,这里我们得花些时间了解一个概念:模糊参数(Fuzziness Factor)。
与K均值聚类原理类似,模糊K均值也是在待聚类对象向量集合上循环,但是它并不是将向量分配给距离最近的簇,而是计算向量与各个簇的相关性(Association)。假设有一个向量v,有k个簇,v到k个簇中心的距离分别是d1,d2…dk,那么V到第一个簇的相关性u1可以通过下面的算式计算:
计算v到其他簇的相关性只需将d1替换为对应的距离。
从上面的算式,我们看出,当m近似2时,相关性近似1;当m近似1时,相关性近似于到该簇的距离,所以m 的取值在(1,2)区间内,当m越大,模糊程度越大,m 就是我们刚刚提到的模糊参数。
本文主要是java语言实现,1000个点(本文是二维向量,也可以是多维,实现原理和程序一样),程序运行过程中会输出每一次遍历点的簇中心,和簇中包含的点,并将最终结果通过插件在html中显示。
二、FuzzyKMeans聚类算法实现部分步骤
将本地文件读取到点集合中:
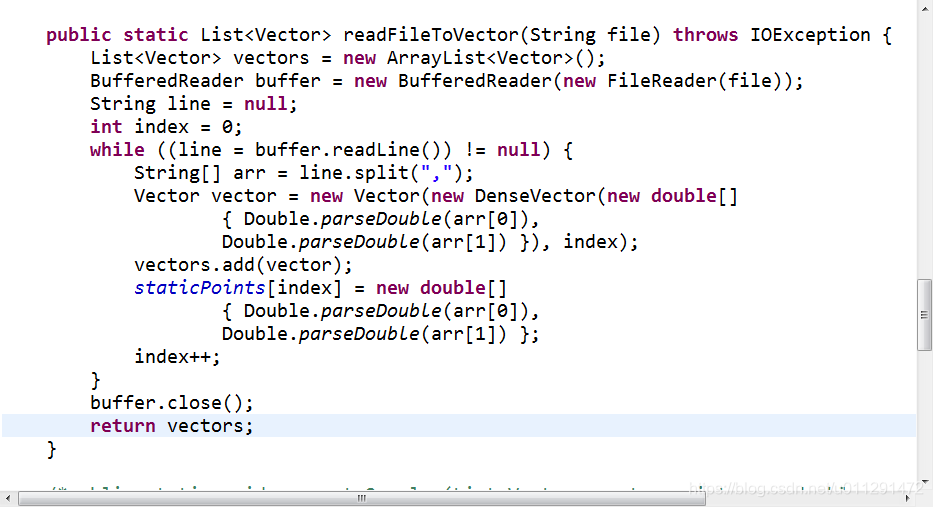
三、FuzzyKMeans聚类算法实现结果
1、运算结果:

2、分布图:
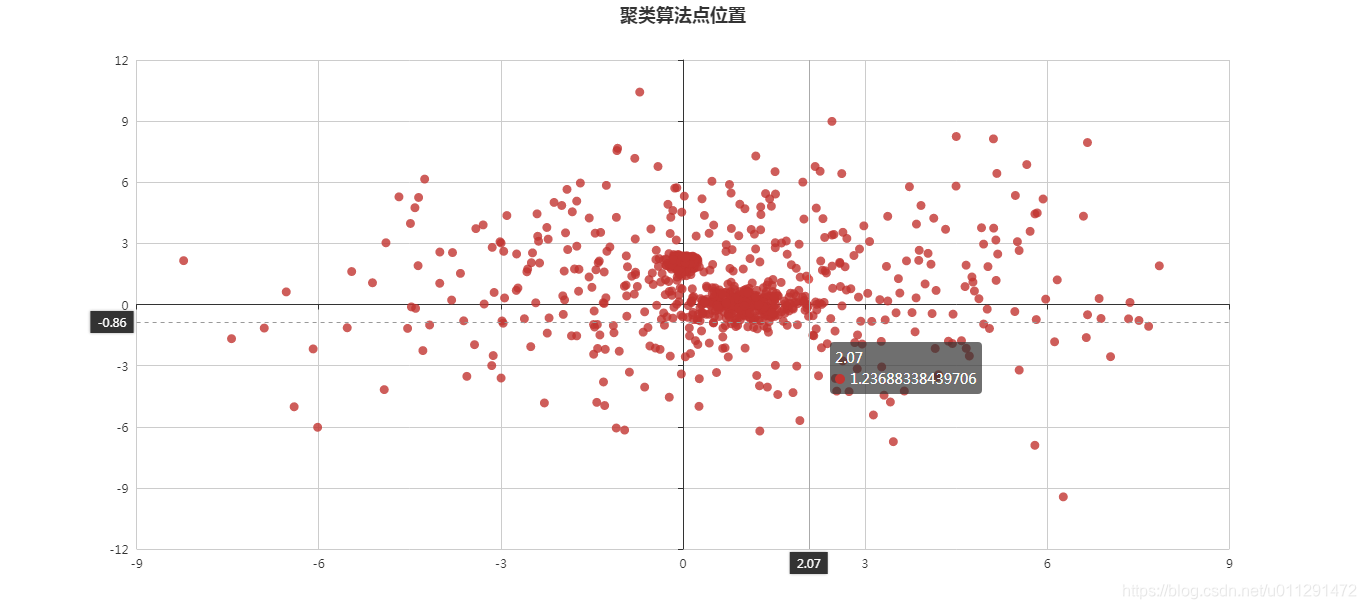
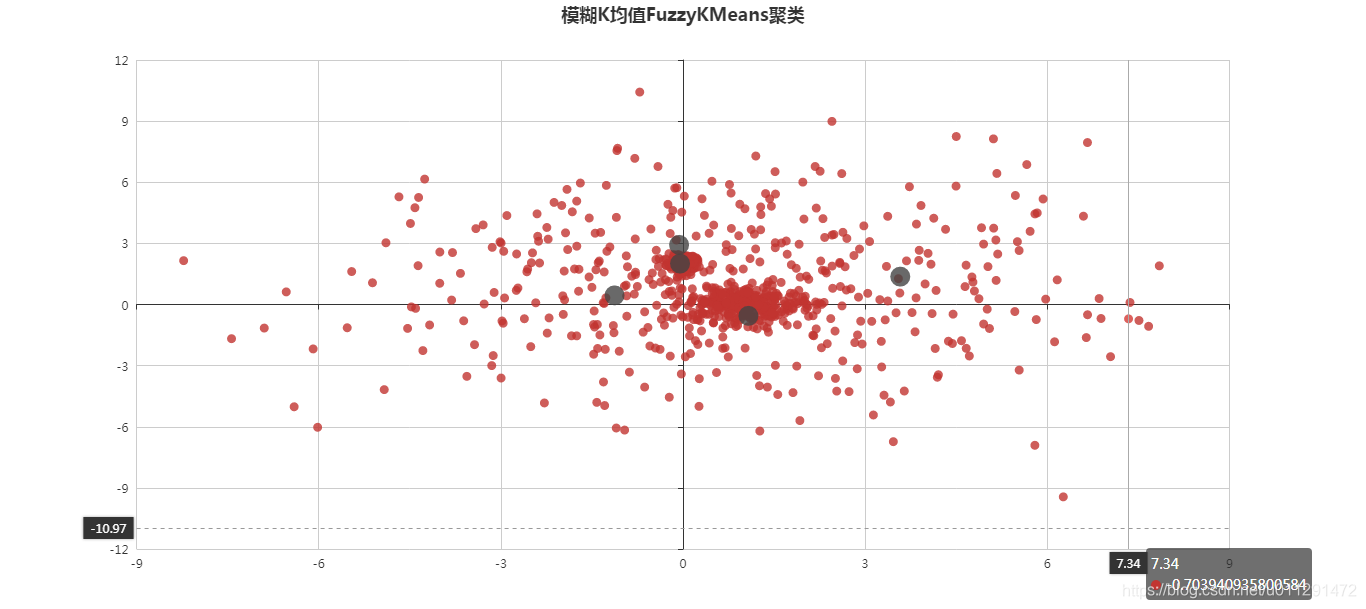
需要源代码的朋友可联系我们,也可以留言、私信交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号