
Datawhale X 魔搭 AI夏令营-第四期(AIGC方向)-Task03-可图Kolors-进阶上分 实战优化
Datawhale X 魔搭 AI夏令营-第四期(AIGC方向)-Task02-可图Kolors-精读代码 实战进阶
Datawhale X 魔搭 AI夏令营-第四期(AIGC方向)-Task01-可图Kolors-LoRA风格故事挑战赛
本期主要的学习内容为:
- 使用ComfyUI工具来可视化文生图的工作流程界面,并基于Task01中LoRA微调得到的模型进行图像生成;
- 解读lora的工作原理;
- 了解文生图数据集的准备、规格等;
- 运用魔搭官方提供数据集跑一些lora训练。
一、使用ComfyUI可视化文生图的工作流程
1、根据Datawhale给出的代码,进行环境设置和相关库的安装。
完成安装后,启动ComfyUI服务。通过给出的URL链接,在浏览器中访问ComfyUI。
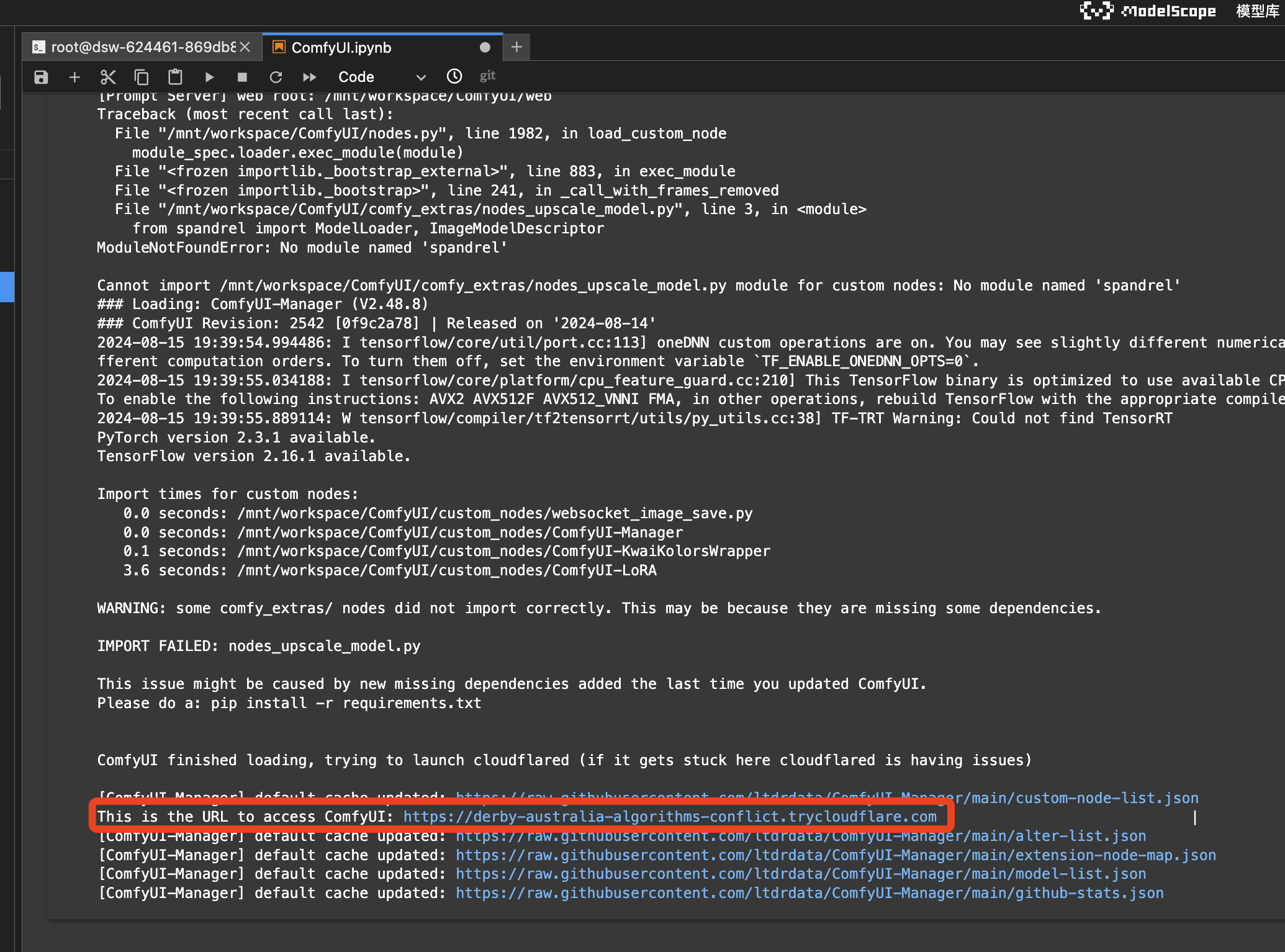
初始界面如上图,可以看到核心构件有4个:
(1)Load Checkpoint (模型加载器): 用于载入基础模型,这里分三种,分别是MODEL、CLIP、VAE;
(2)CLIP Text Encoder (CLIP文本编码器): 用于将给出的文本提示词转化为latent embedding (隐式嵌入),作为扩散模型的输入之一。此界面中有两个Text Encoder,分别对应正向提示词和负向提示词;
(3)VAE Decoder (解码器): 将Latent Image (Latent Space中的embedding) 解码为像素级别的图像;
(4)KSampler (采样器): 对应扩散模型的采样过程,通常包含若干个步长的降噪过程,这也是扩散模型中的核心部分,其本质的Backbone Network是一个UNet。
在采样过程的每一步中,输入为Latent Text Embedding、和上一步输出的Latent Image (如果是第一步,那就是纯Noise,对应上面Empty Latent Image的框),输出为降噪后的Latent Image。
最后一步输出的Latent Image,会由VAE Decoder进行解码,输出一张像素级别的图像,即采样结果 (生成结果);
2、加载工作流脚本 .json 文件
点击界面右下角框中的“Load”选项,选择“带lora训练的工作流”脚本。
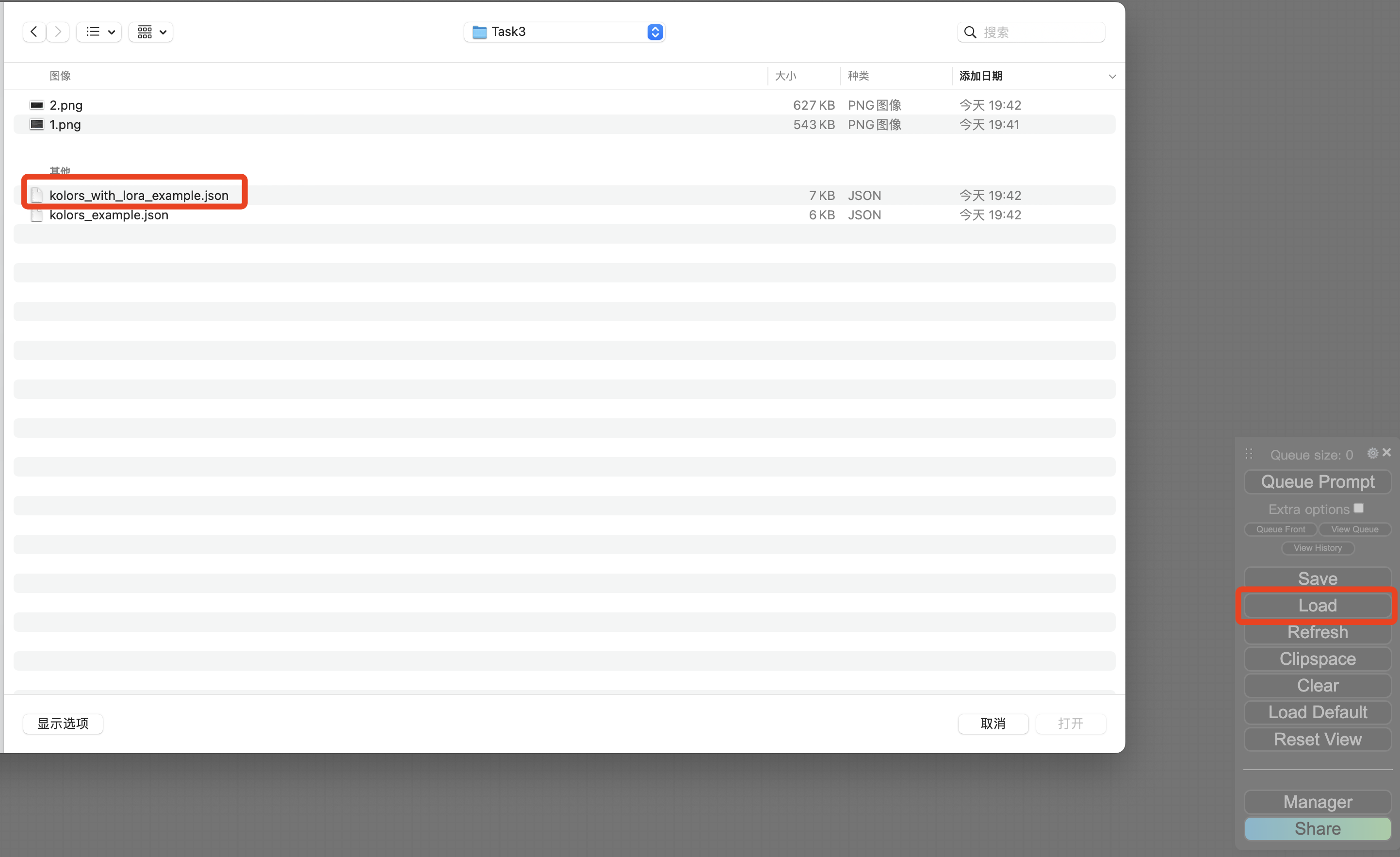
再选择lora模型权重文件的路径;
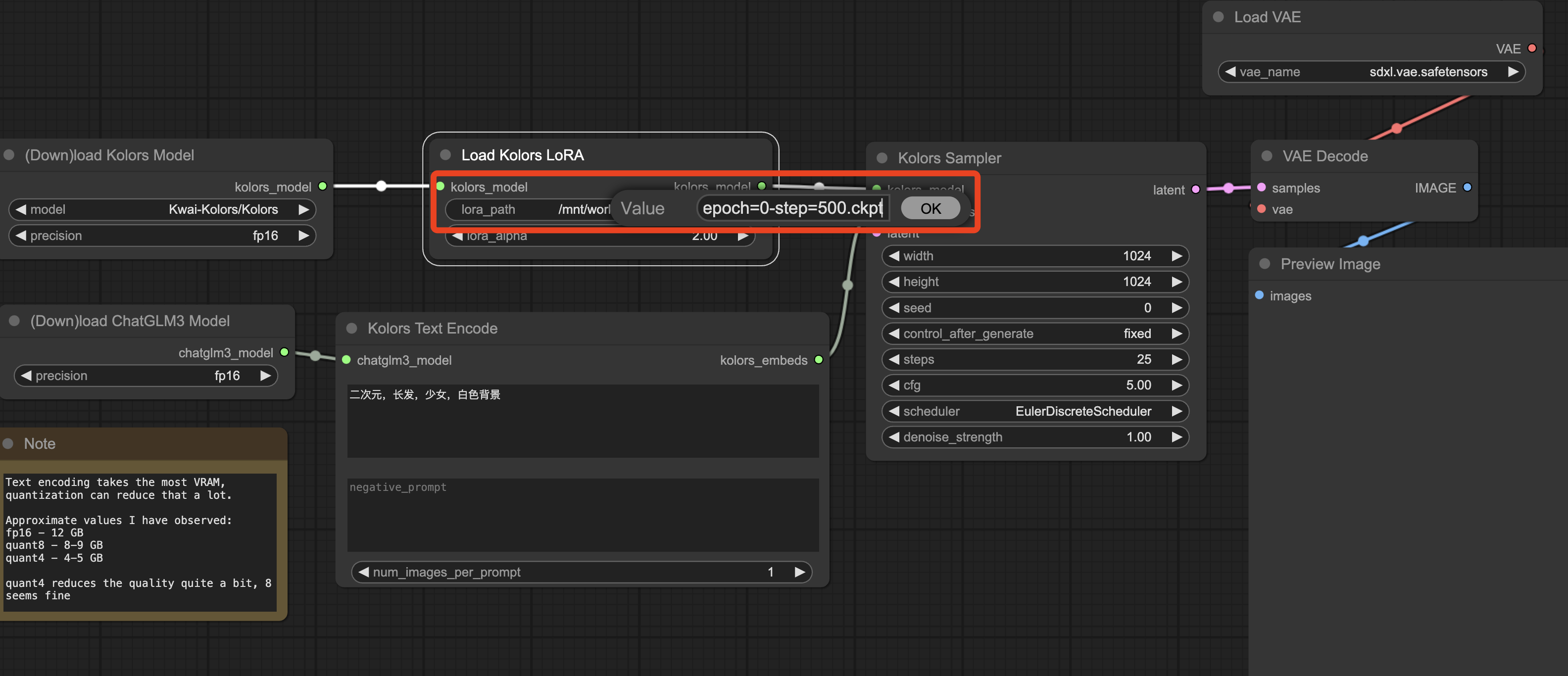
然后,在框中输入正向和负向提示词,点击“Queue Prompt”进行文生图。
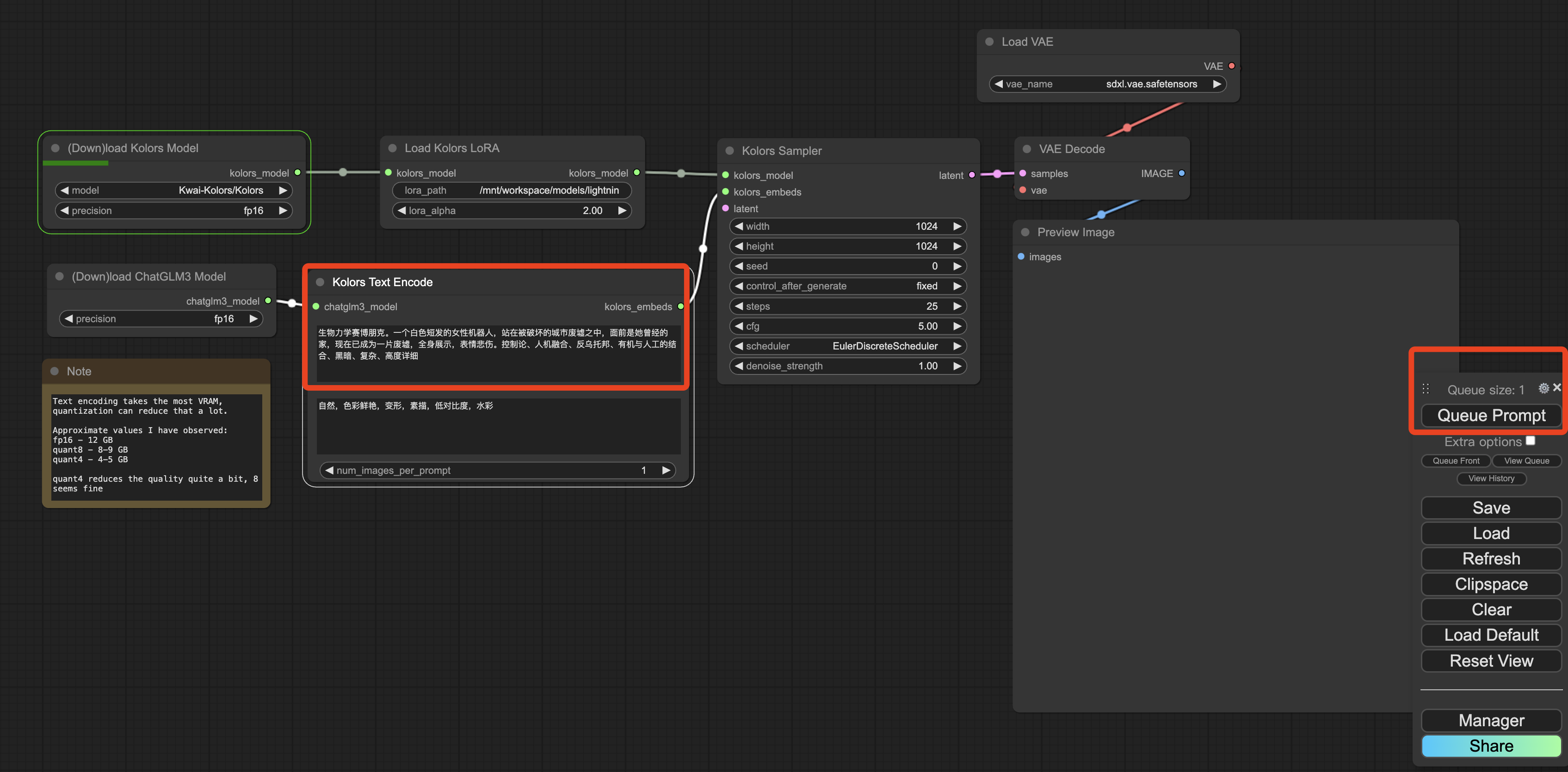
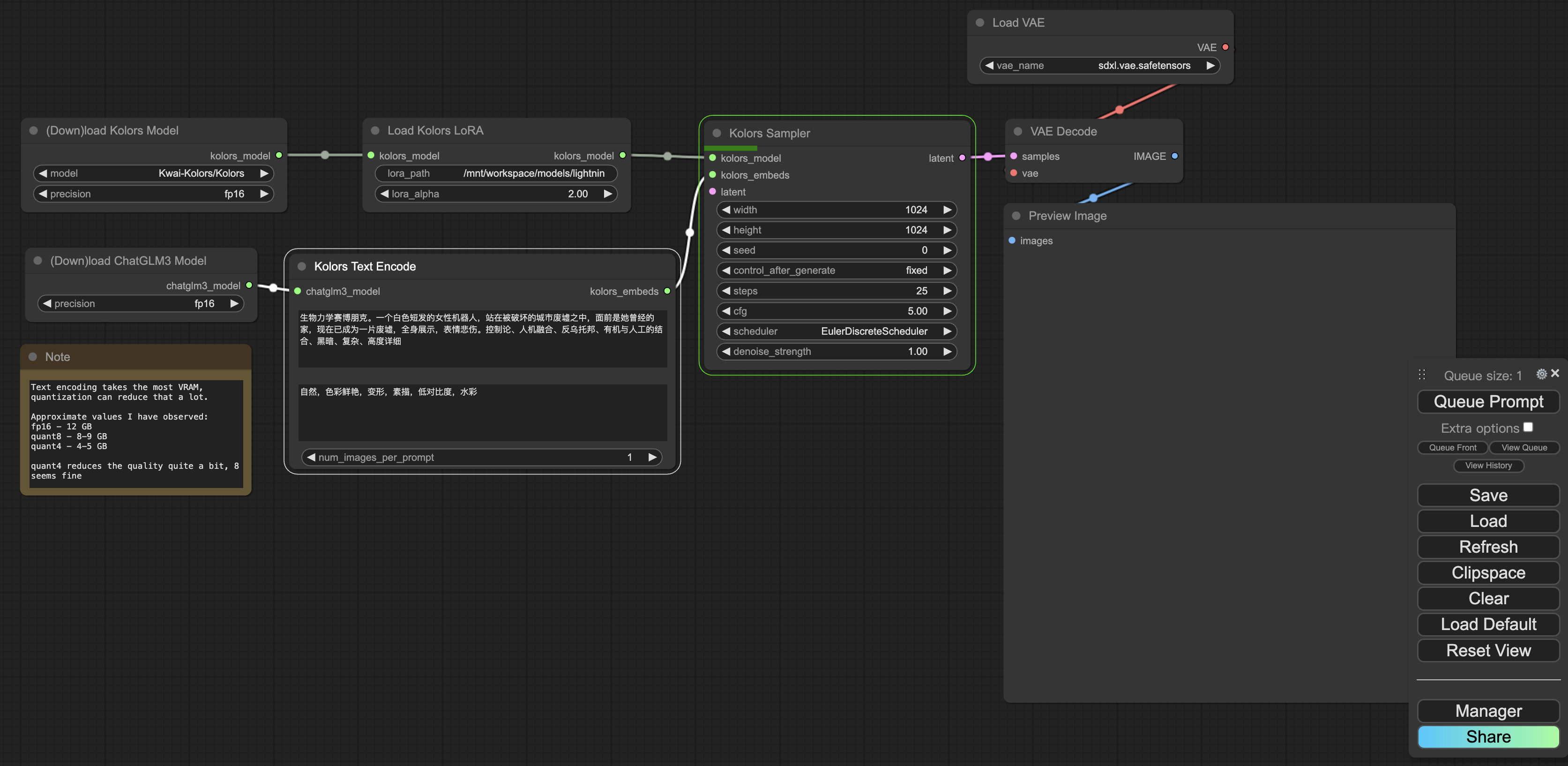
在生成过程中,正在运行的模块会由绿色线框进行标记。
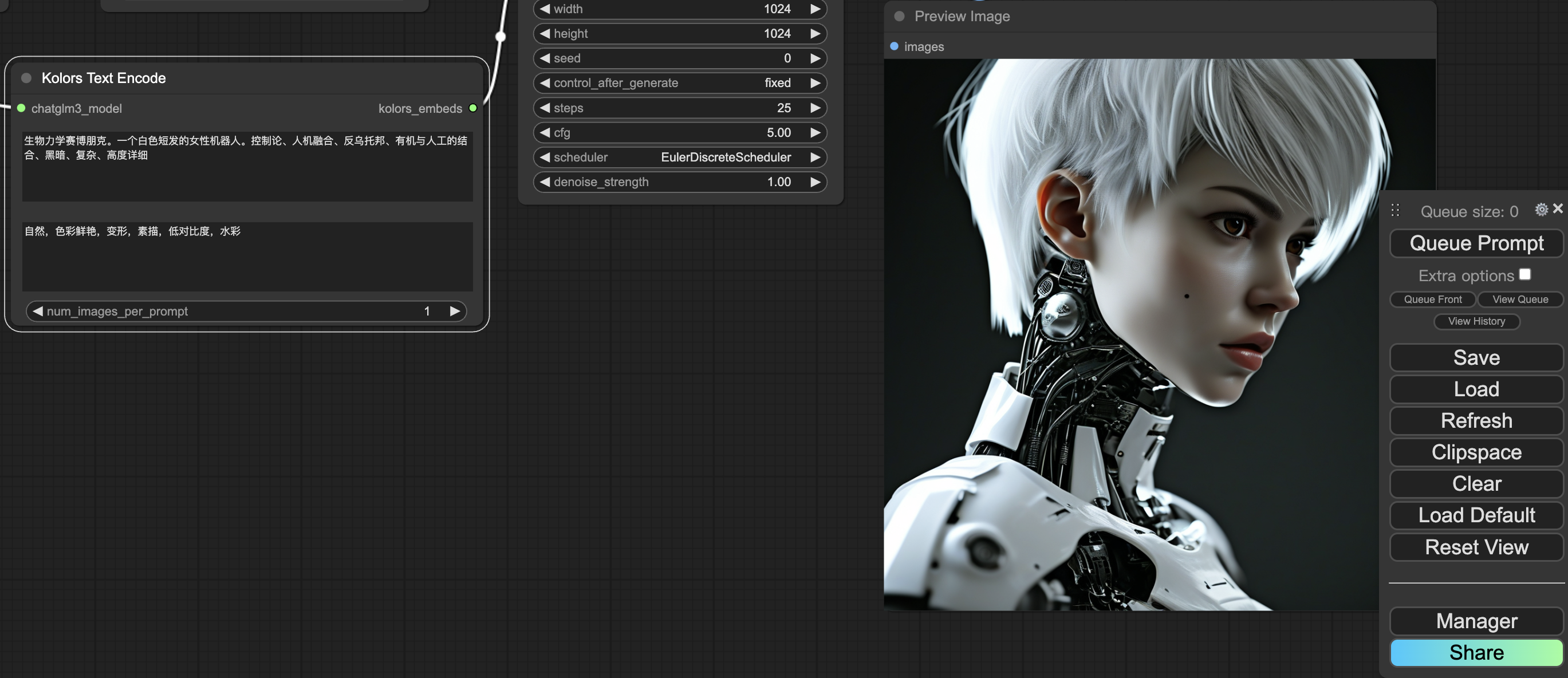
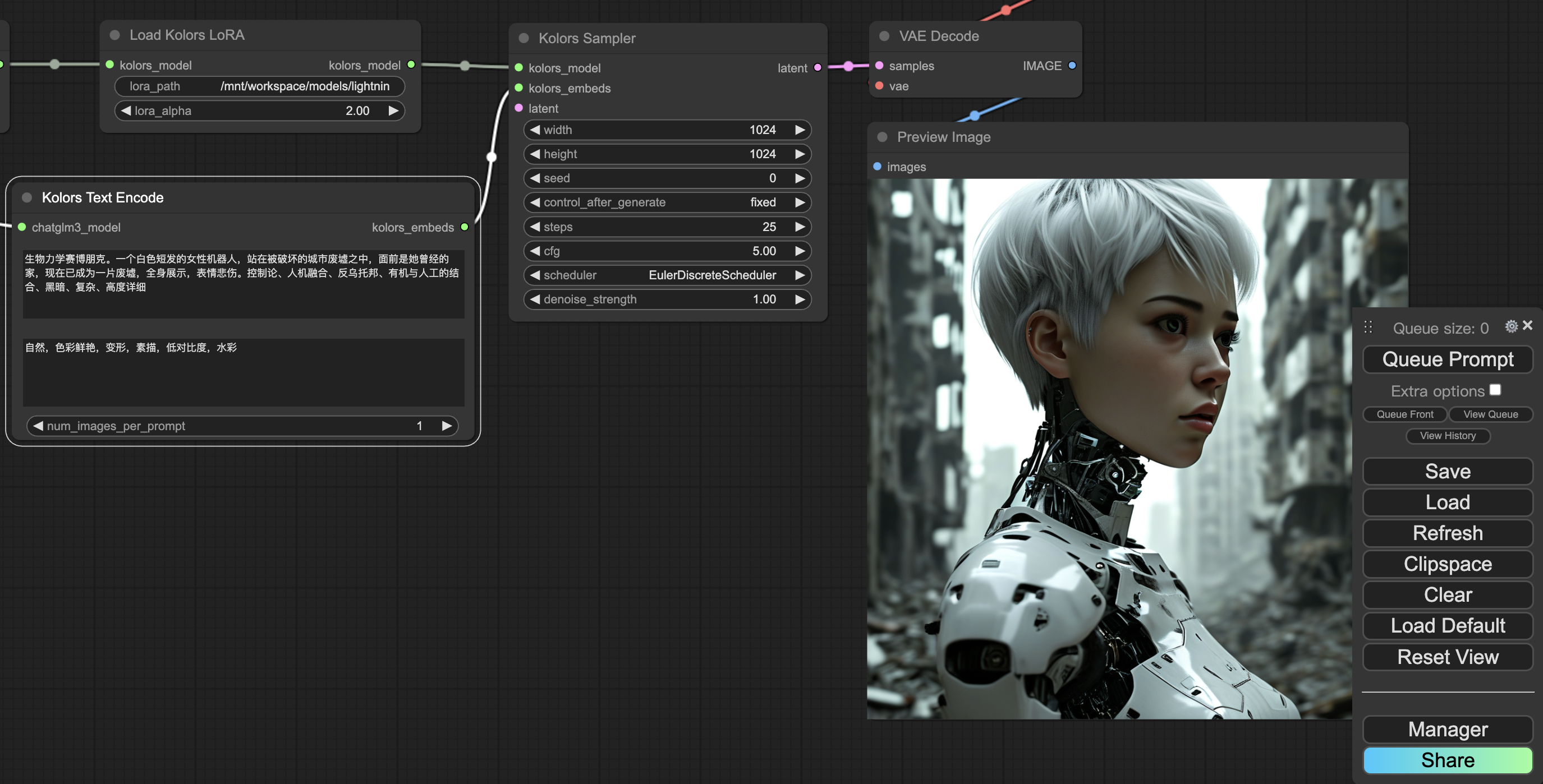
3、输入正向提示词和负向提示词,生成图像。这里还是采用Task02中的提示词。
4、json工作流脚本浅析
运行整个项目后不难发现,json格式的工作流脚本是最关键的,它决定了各个部件的属性和整个工作流程。
下面对本次Task中的 kolors_with_lora_example.json 脚本进行简要的解读:
观察代码后我认为最关键的是两部分:
第一部分是节点("nodes"),每个节点由"id"来唯一标记,每个节点中定义了其各种具体的属性,例如节点名称("type")、位置("pos")、尺寸("size")、输入("inputs")、输出("outputs")等;
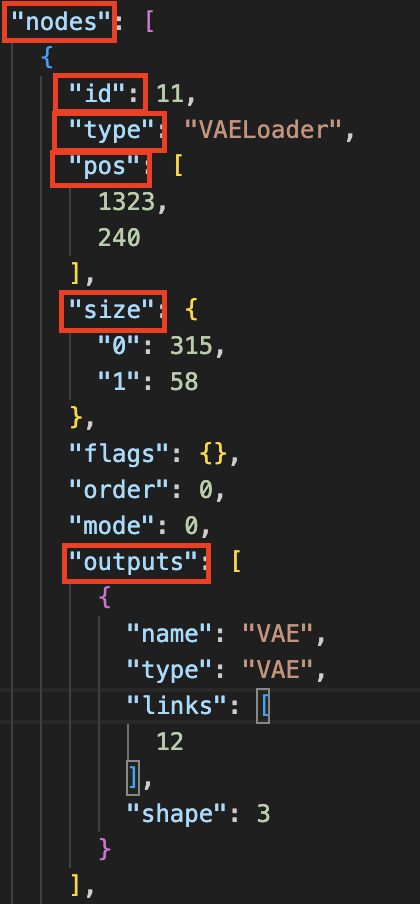
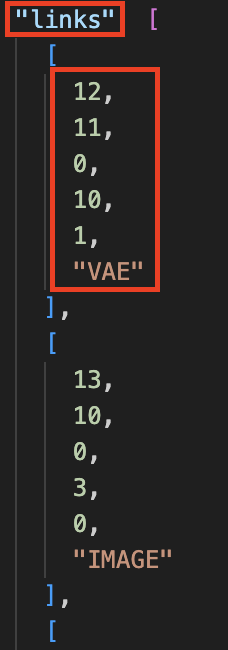
第二部分是节点间的连接关系("links"),即数据如何从一个处理节点流动到下一个处理节点,例如[12, 11, 0, 10, 1]这条连接,12表示该连接的id,11表示源节点id("VAELoader"),0表示该连接中源节点用到的输出槽index为0("VAE"),10表示目标节点id("VAEDecode"),1表示该连接中目标节点用到的输入槽index为1("vae")。
综上可以看出该连接的作用为:VAE模型从VAELoader节点输出后,作为输入传递给VAEDecode节点,用于解码生成的图像。
二、LoRA原理解读
原文链接:https://arxiv.org/abs/2106.09685
1、提出动机
深度神经网络由大量Dense层构成,而这些层的权重矩阵通常是满秩的。
相关工作表明,当针对一个特定的任务训练模型时,预训练的语言模型实际具有一个较低的“内在维度”,即使将其随机投射到一个较小的子空间中,模型仍然可以有效地学习。
LoRA作者假设,微调LLM时的参数增量矩阵ΔW也存在一个“内在低维度”,即该参数增量矩阵是低秩的。
那么,就可以用低秩分解来表示对LLM全参数微调的增量参数矩阵ΔW,从而起到降低训练开销的效果。
2、核心思想
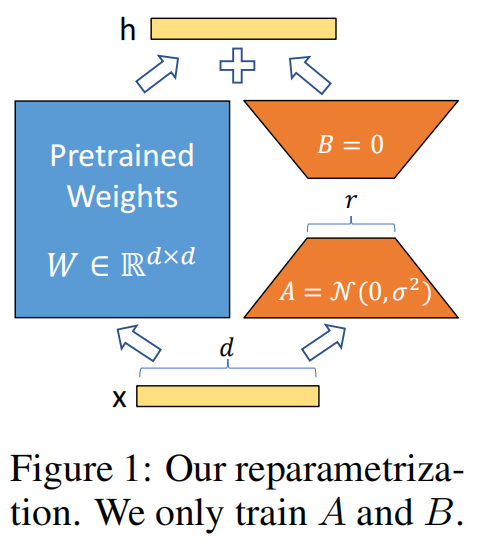
对于预训练权重矩阵W0∈Rdxk,LoRA将其全参数微调的增量参数矩阵 ΔW 表示为两个参数量更小的矩阵B和A的低秩近似,即:
W0 + ΔW = W0 + BA ,
其中,B∈Rdxr 和 A∈Rrxk为LoRA低秩分解的权重矩阵,且秩r远小于维度d和k ( r<<min(d, k) )。
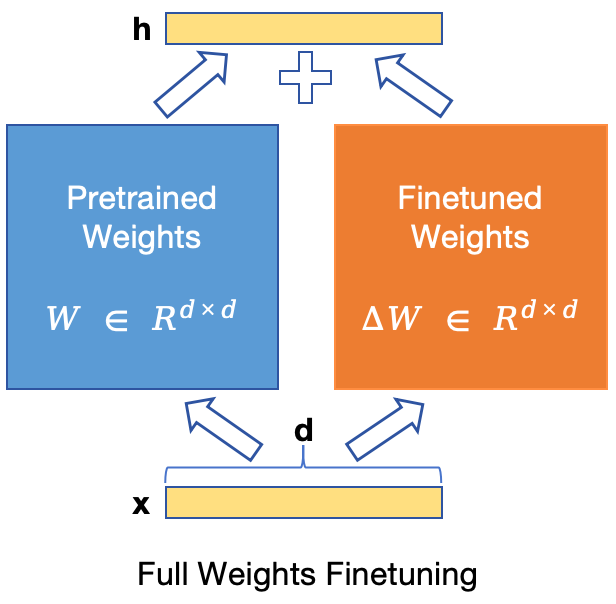
此时,由于预训练LLM的原参数权重 W0 是冻结的,模型微调的参数量从原来的 dxk,变为了 dxr+rxk,
在 r<<min(d, k) 的情况下,dxr+rxk << dxk,即模型微调的参数量大大降低了,如图所示:
 →
→ 
对于输出方程 h=w0x,引入LoRA微调后的形式为:
h = w0x + Δwx = w0x + BAx ,
实际实现时,Δw=BA 会乘以大小为 α/r 的缩放因子。r 和 α 分别对应前两个Task的LoRA微调代码中 --lora_rank 和 --lora_alpha 两个参数。
系数 α/r 越大,LoRA微调权重对整体模型参数的影响就越大。
3、LoRA优点
- 高效、灵活地切换下游任务,并降低存储和训练的开销。基于一个预训练模型,可以针对不同的下游任务来构建多个小型LoRA模块。通过冻结共享预训练模型的权重,仅替换矩阵 A 和 B,实现高效、灵活地切换不同任务,同时降低存储和训练的开销;
- 提高训练效率。因为LoRA不需要计算LLM的大部分参数梯度,相反地,只需优化分解的、规模较小的低秩矩阵;
- 不引入推理延迟。因为其线性相加的设计,LoRA在推理部署时将冻结权重与可训练矩阵合并,其构造与全微调模型相比不引入任何推理延迟。
- 适用性强。LoRA 可以应用于大部分预训练LLMs的微调训练。
三、了解文生图数据集
毫无疑问,想要训练一个性能理想的文生图模型,用于训练(或微调)的数据很重要。这决定了模型是否能学习更丰富的数据分布,拥有更强的泛化性能。
我对文生图的数据集准备一直没有相关实践经验,也借这次机会,对其中细节进行了解和学习。
这里,我主要体验了使用魔搭社区官方提供的文生图风格定制数据集(style_custom_dataset)。
该数据集中包含6种风格:watercolor(水墨画)、3D、anime(日漫)、flatillustration(平面插图)、oilpainting(油画)、sketch(素描)。
在官网中,也可以直接查看该数据集的标注文件( .csv ),其中包含了所有图像的文件名、提示词、风格。如下所示。(需注意的是,test集中的图像文件名均为空,只包含提示词和风格)

通过官方给出的代码,在Notebook中导入相关风格的子集进行查看。(注:风格名称的首字母需大写,否则会报错)
from modelscope.msdatasets import MsDataset ms_train_dataset = MsDataset.load('style_custom_dataset', namespace='damo', subset_name='Oilpainting', split='train', cache_dir="/mnt/workspace/kolors/data") print(next(iter(ms_train_dataset))) print(len(ms_train_dataset))
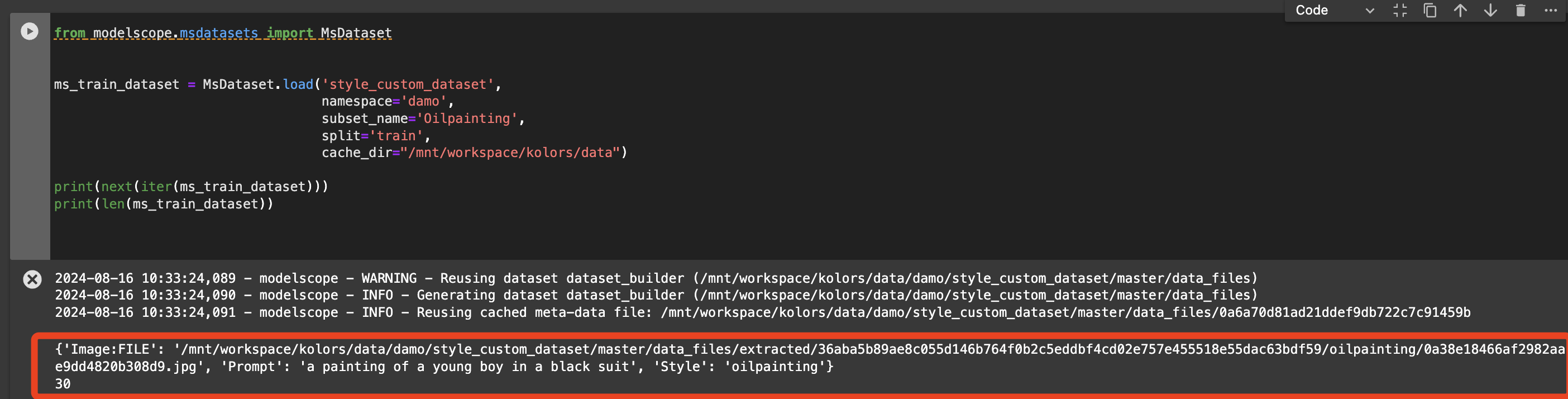
如下图,代码输出了第一张图片的相关信息(dict形式),包含三部分:Image:FILE(路径/文件名)、Prompt(提示词)、Style(风格)。
以及数据集中该子集包含的图像数量:'Oilpainting'的'train'子集有30张图像。与上面 .csv 文件中的信息一致。
根据给出的路径,可以在Notebook的文件目录中查看到数据集中的图像,附上它的生成提示词如下图。
这里我们另外加了一张'Watercolor'的'train'子集中的图片,用上述同样操作可以获得。


"a painting of a young boy in a black suit" "a watercolor painting of a child with blue hair"
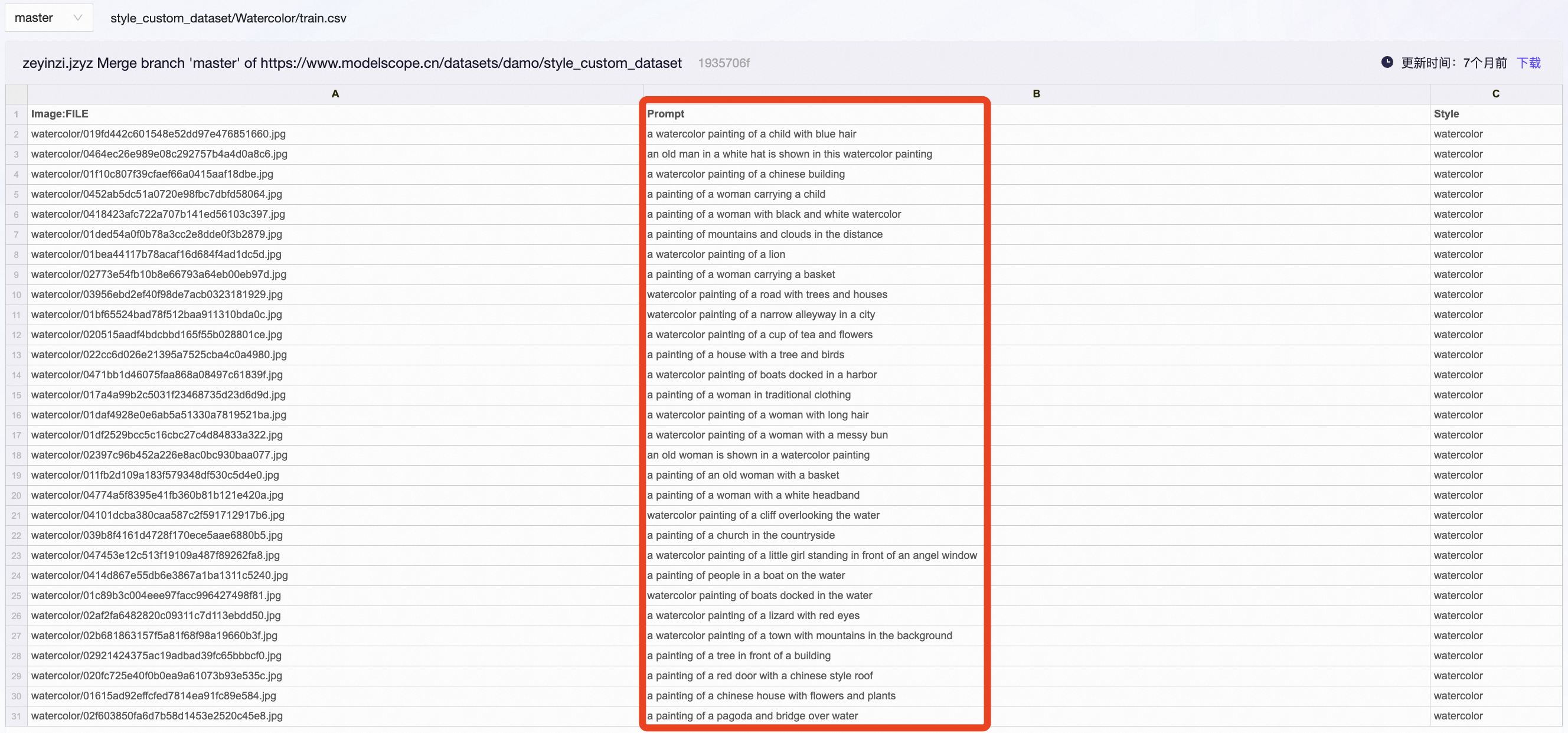
另外,还有一个有意思的点是:对于同一个数据集子集,官网提供了两个版本的标注.csv文件。
两个标注文件的区别在于:一个 train.csv 提供正常的提示词,另一个 train_short.csv 则提供简短的提示词。如下图所示。
例如,对于上述第二幅水彩画, train.csv 提供的正常提示词为"a watercolor painting of a child with blue hair",而 train_short.csv 提供的简短提示词为"A child with blue hair"。
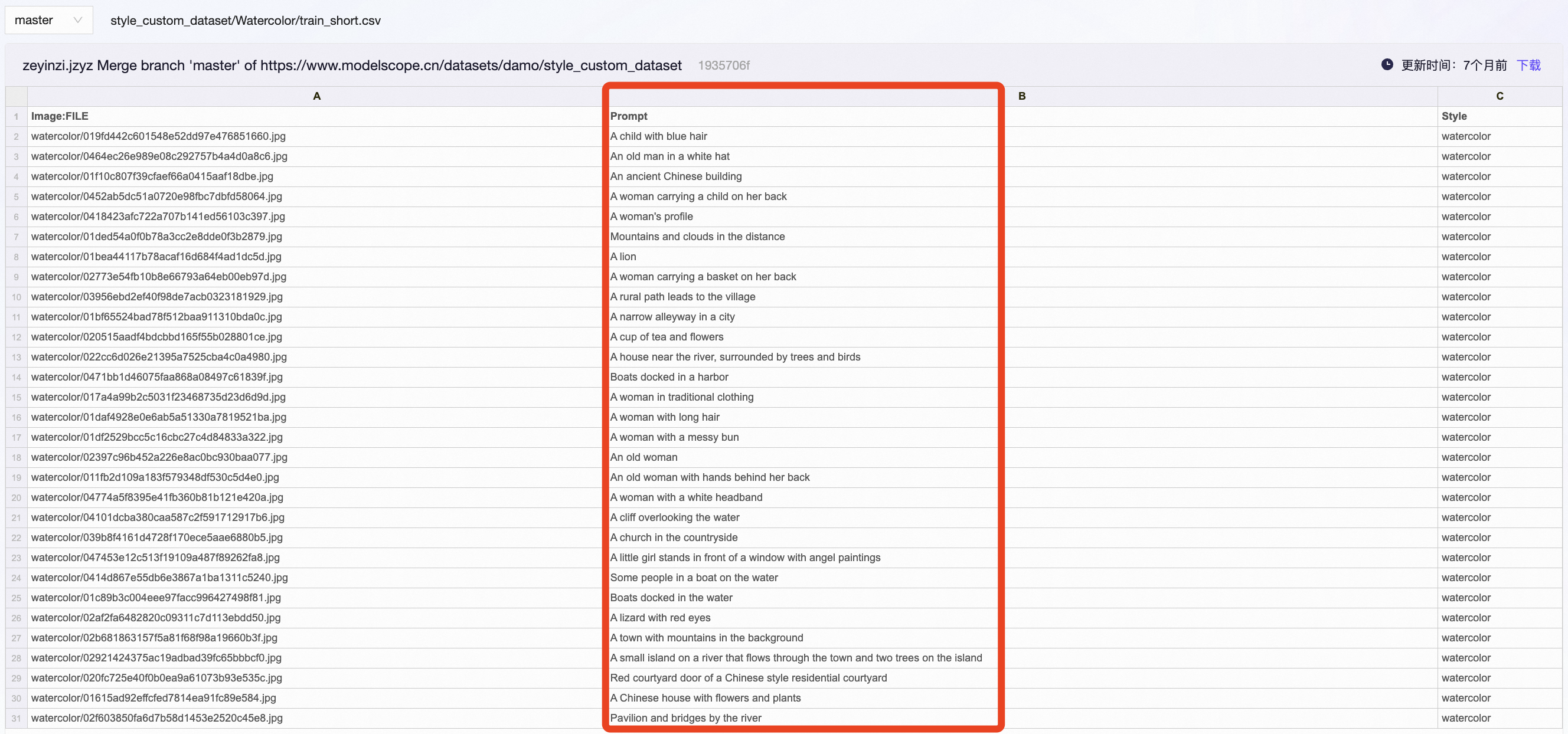
train.csv train_short.csv
四、一些小实验
基于上述的文生图风格定制数据集,可以设计一些实验,用于验证数据集的改动对于模型生成性能的影响。这里只用了'Watercolor'子集。
评价指标:由于该文生图任务的测试集中不存在原图像,无法使用FID等评价原图像与生成图像相似度的指标,故只使用美学评分对生成结果进行评价(代码见Task02)。
1、是否微调对生成效果的影响
(1) 实验说明:
对于不进行微调的实验:在Task01的代码中,lora微调是基于SDXL(Stable Diffusion XL)模型进行的,故这里采取SDXL模型用作baseline。
调用SDXL进行text-to-image任务的代码如下,这里附上了通义千问给出的注释:(参考了DiffSynth-Studio官网文档给出的示例)
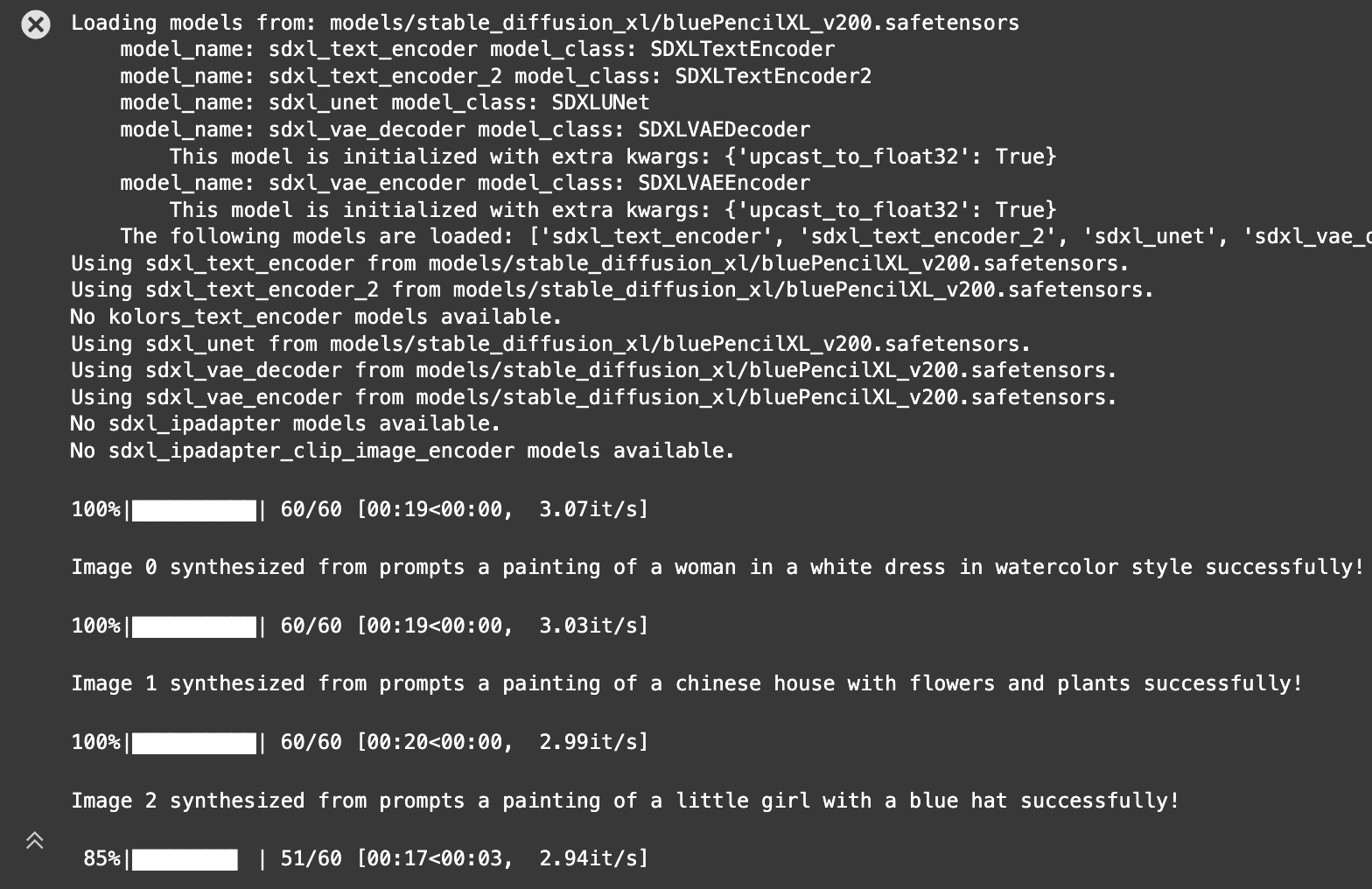
# 导入MsDataset类,用于加载数据集 from modelscope.msdatasets import MsDataset # 加载名为'style_custom_dataset'的数据集中的'Watercolor'子集,并指定测试集分割,缓存目录为'/mnt/workspace/kolors/data' ms_test_dataset = MsDataset.load('style_custom_dataset', namespace='damo', subset_name='Watercolor', split='test', cache_dir="/mnt/workspace/kolors/data") # 导入diffsynth库中的ModelManager, SDXLImagePipeline, download_models模块 from diffsynth import ModelManager, SDXLImagePipeline, download_models import torch # 导入PyTorch库 # 下载模型(自动进行) download_models(["Kolors", "SDXL-vae-fp16-fix"]) # 下载指定的模型 import os # 导入操作系统相关的功能 # 加载模型 model_manager = ModelManager(torch_dtype=torch.float16, device="cuda", # 创建模型管理器,设置数据类型为半精度浮点数,并使用GPU设备 file_path_list=[ # 指定模型文件路径列表 "models/kolors/Kolors/text_encoder", "models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors", "models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors" ]) pipe = SDXLImagePipeline.from_model_manager(model_manager) # 从模型管理器创建图像生成管道 torch.manual_seed(0) # 设置随机种子以获得可复现的结果 # 遍历数据集中的每个项目 for i, item in enumerate(ms_test_dataset): image = pipe( # 生成图像 prompt=item['Prompt'], # 使用数据集中每个项目的提示词 cfg_scale=6, # 条件缩放因子,用于控制提示词的影响程度 height=1024, width=1024, # 输出图像的高度和宽度 num_inference_steps=50, # 推理步骤的数量 ) # 保存生成的图像到指定文件夹 image.save(os.path.join('test-results', ('Watercolor-test-' + str(i) + '.jpg'))) # 打印成功合成图像的信息 print('Image {} synthesized from prompts {} successfully!'.format(i, item['Prompt']))
代码运行效果如图:
对于进行lora微调的实验:具体参照前两个Task的代码操作。
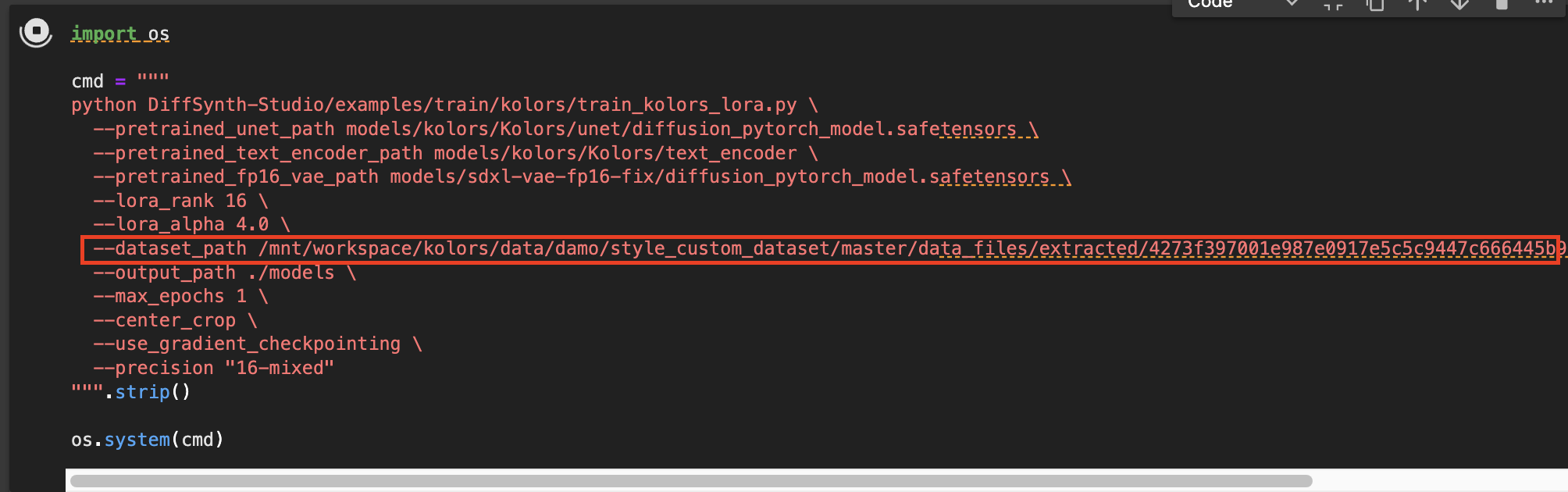
这里需要注意的有两点:
第一,lora训练时的数据集路径参数 --dataset_path ,替换为实例中'Watercolor'的'train'子集的路径;
第二,光更换数据集路径还不够,魔搭提供的数据集、与DiffSynth-Studio设定的数据集,在组织细节上有一点出入,如果直接导入数据集会报错。
具体地,体现在 kolors/DiffSynth-Studio/diffsynth/data/simple_text_image.py 文件中的 TextImageDataset 类:
class TextImageDataset(torch.utils.data.Dataset): def __init__(self, dataset_path, steps_per_epoch=10000, height=1024, width=1024, center_crop=True, random_flip=False): self.steps_per_epoch = steps_per_epoch metadata = pd.read_csv(os.path.join(dataset_path, "train/metadata.csv")) self.path = [os.path.join(dataset_path, "train", file_name) for file_name in metadata["file_name"]] self.text = metadata["text"].to_list() self.image_processor = transforms.Compose( [ transforms.Resize(max(height, width), interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop((height, width)) if center_crop else transforms.RandomCrop((height, width)), transforms.RandomHorizontalFlip() if random_flip else transforms.Lambda(lambda x: x), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ] )
# 后续代码省略
可以看到,导入数据集时的 .csv 标注文件的名称,以及图像文件名、提示词所对应的key,都不一致。调整后的 TextImageDataset 类代码如下:
class TextImageDataset(torch.utils.data.Dataset): def __init__(self, dataset_path, steps_per_epoch=10000, height=1024, width=1024, center_crop=True, random_flip=False): self.steps_per_epoch = steps_per_epoch metadata = pd.read_csv(os.path.join(dataset_path, "watercolor", "train.csv")) self.path = [os.path.join(dataset_path, file_name) for file_name in metadata["Image:FILE"]] self.text = metadata["Prompt"].to_list() self.image_processor = transforms.Compose( [ transforms.Resize(max(height, width), interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop((height, width)) if center_crop else transforms.RandomCrop((height, width)), transforms.RandomHorizontalFlip() if random_flip else transforms.Lambda(lambda x: x), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ] )
# 后续代码省略
在执行安装DiffSynth-Studio这个库 ( pip install -e DiffSynth-Studio ) 之前,先更改 kolors/DiffSynth-Studio/diffsynth/data/simple_text_image.py 中的代码。
(2) 实验结果:
定性对比:
| 序号 | 提示词 | 无lora微调 (美学评分) | lora微调 (美学评分) |
| 0 | a painting of a woman in a white dress in watercolor style |  |
 |
| 6.89 | 6.27 | ||
| 1 | a painting of a chinese house with flowers and plants |  |
 |
| 6.89 | 7.06 | ||
| 2 | a painting of a little girl with a blue hat |  |
 |
| 7.79 | 7.51 | ||
| 3 | a painting of two boys standing on a hill |  |
 |
| 6.99 | 6.62 | ||
| 4 | a painting of an old man smiling |  |
 |
| 7.69 | 7.31 | ||
| 5 | a painting of a house in a field with flowers |  |
 |
| 6.91 | 6.89 | ||
| 6 | a painting of a house with a yellow tree |
|
 |
| 6.62 | 5.87 | ||
| 7 | a painting of a bridge over a river |  |
 |
| 6.67 | 6.69 | ||
| 8 | a painting of a woman with her eyes closed |  |
 |
| 7.59 | 7.13 | ||
| 9 | a painting of a farm in the mountains |  |
 |
| 7.14 | 6.86 |

定量对比:
| 设置 | 模型 | 训练 (数据量) | 测试 (数据量) | 美学评分 |
| 1 | SDXL | N/A (0) | Watercolor-test (10) | 7.12 |
| 2 | Watercolor-train (30) | Watercolor-test (10) | 6.82 |
(3) 实验分析:
在定性对比中,可以观察到经过lora微调的模型生成结果与未经lora微调的有细微区别,例如图1中的花更茂盛、图3中的山丘远处没有人、图6中的细节不清晰等等,结合美学评分来看,得分结果总体与我的主观评判一致;
另外,在定量对比中,对于生成结果的美学评分,经过lora微调的模型生成结果反而略低于未经lora微调的模型,与我的预想"经过lora微调的模型生成结果优于未经lora微调的模型"不一致。
2、训练集与测试集风格一致性对生成效果的影响
(1) 实验说明:使用一种风格(Anime)的文生图数据对SDXL模型进行lora微调,再用另一种风格(Watercolor)的提示词测试模型的生成效果,将该结果对比训练集与测试集风格一致的设置。
(2) 实验结果:
| 设置 | 模型 | 训练 (数据量) | 测试 (数据量) | 美学评分 |
| 1 | SDXL | Watercolor-train (30) | Watercolor-test (10) | 6.82 |
| 2 | Anime-train (30) | Watercolor-test (10) | 6.87 |
(3) 实验分析:
从美学评分来看,对于"Watercolor"风格的测试提示词来说,使用"Anime"风格数据进行微调后的模型生成效果略优于使用"Watercolor"风格数据微调的模型生成效果。
这一结果与我"训练集数据的风格与测试提示词风格一致,能够提高文生图模型的生成效果"的预想不一致。
3、提示词Prompts的长度对生成效果的影响
(1) 实验说明: 分别探究训练集提示词和测试集提示词的长度对模型生成效果的影响。这里还是采用"Watercolor"风格的子集,train/test表示正常长度提示词,train_short/test_short表示简短提示词。
(2) 实验结果:
| 设置 | 模型 |
训练提示词长度 (train / train_short) |
测试提示词长度 (test / test_short) |
美学评分 |
| 1 | SDXL | train | test | 6.82 |
| 2 | train | test_short | 6.46 |
|
| 3 | train_short | test | 6.94 | |
| 4 | train_short | test_short | 6.61 |
(3) 实验分析:
从上述定量对比结果可以看出:
第一,使用同样长度提示词的训练集来微调模型,测试时使用较长提示词的生成效果优于使用较短提示词的生成效果。具体来说,设置1比设置2得到的美学评分高、设置3比设置4得到的美学评分高。这可能是因为长提示词对应更准确的特征,能够引导模型进行更精准的生成;
第二,对于同样长度的测试提示词,使用较短提示词训练集的模型生成效果优于使用较长提示词训练集的模型生成效果。具体来说,设置3比设置1得到的美学评分高、设置4比设置2得到的美学评分高。这可能是因为短提示词对应更广的文本特征空间,在模型训练阶段使用短提示词有助于加强模型的泛化性,从而提升模型在测试时的生成效果。
4、实验总结
上面进行了三个实验,从实验结果来看,只有实验3符合我预想的结论,实验1、2的结果均与我预想的实验结论相悖。
虽然要尊重客观结果,但我想实验结果主要受到四个方面的影响,从而难以体现统计规律:
第一,用于微调的训练数据量太小(30张图像),导致微调的效果微乎其微、无法体现;
第二,因为时间原因只跑了一次实验,结果具有偶然性(有条件的可以换不同随机种子跑多遍,然后取平均值);
第三,未进行模型调参,没有考虑模型训练中的一些超参数 (如LoRA的r、α )对于生成效果的影响;
第三,这里只使用了美学评分作为生成结果的评价标准,评价维度较为片面、单一,无法全面、客观地反映生成结果的质量。
五、Task03总结
1、使用了ComfyUI可视化LoRA的工作流程,图形化的方式能更直观地体现LLM的工作流程,便于LLM的训练、调试和部署使用等,另外对工作流脚本进行了解读,对ComfyUI对工作流配置有了更深入的了解;
2、通过原始论文,学习了LoRA的动机、核心思想以及优势,有助于后续深入探索LoRA的进阶使用;
3、在文生图数据集部分,学习到了文生图数据集通常包含图像数据、提示词等核心部分,提示词也有短提示词和长提示词的区别;
4、通过一些控制变量的对比实验,试图探究在文生图中,是否微调、训练集与测试集相关性、训练数据Prompts的长度等因素对于模型生成效果的影响。抛开不谈得到的实验结果是否具有统计意义,至少对于文生图数据集的训练导入等细节有了更深入的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号