
Datawhale X 魔搭 AI夏令营-第四期(AIGC方向)-Task01-可图Kolors-LoRA风格故事挑战赛
从零入门AI生图原理&实践 是 Datawhale 2024 年 AI 夏令营第四期的学习活动(“AIGC”方向),基于魔搭社区“可图Kolors-LoRA风格故事挑战赛”开展的实践学习。
下面将分六部分介绍我的学习&实践情况。
一、文生图的历程与基石
首先,通过社区提供的学习资料和PPT,对文生图的历程与基石进行了快速的了解,以下为梗概:
- 引言与定义
- 拟合数据分布、生成模型、传输方程
- 发展历程
- VAE、GAN、Flow-based Models、Diffusion Models
- 扩散模型
- 正向过程
- 逆向过程
- 最终学习目标
- SDE形式表示方式
- 条件扩散模型
- Classifier-guidance
- Classifier-free-guidance
- Stable Diffusion: 在使用VAE压缩后的latent空间进行建模
- 模型加速
- DPM-Solver
- Consistency Model
- Vision-Language Model(VLM)+文生图
- 利用VLM进行更详细的标注,以提升生成准确性
- 标注信息更细粒度
- 包含位置布局信息
ps:这其实是一个非常概括的框架,其实每个知识点都有相应的论文,值得深入学习。
二、文生图基础知识
- prompts (提示词)
提示词为模型生成图像提供引导,通常包含主体描述、细节描述、修饰词、艺术风格、艺术家等,在给出prompts的同时也可给出负向prompts。 - LoRA
Low-Rank Adaptation (LoRA),即低秩适应。在Stable Diffusion这一文本到图像合成模型的框架下,Lora被用于对预训练好的大模型进行针对性微调,以实现对特定主题、风格或任务的精细化控制。
论文链接:https://arxiv.org/abs/2106.09685 - ComfyUI
一个工作流工具。通过直观的界面和集成的功能,用户可以轻松地进行模型微调、数据预处理、图像生成等任务,从而提高工作效率和生成效果。
链接:https://github.com/comfyanonymous/ComfyUI - ControlNet
一种可附加到预训练的扩散模型(如Stable Diffusion模型)上的可训练神经网络模块,通过引入额外的空间条件控制(例如边缘图、人体骨架、分割图、深度图等),来实现更细粒度的空间控制。
论文链接:https://arxiv.org/abs/2302.05543
三、零基础实践
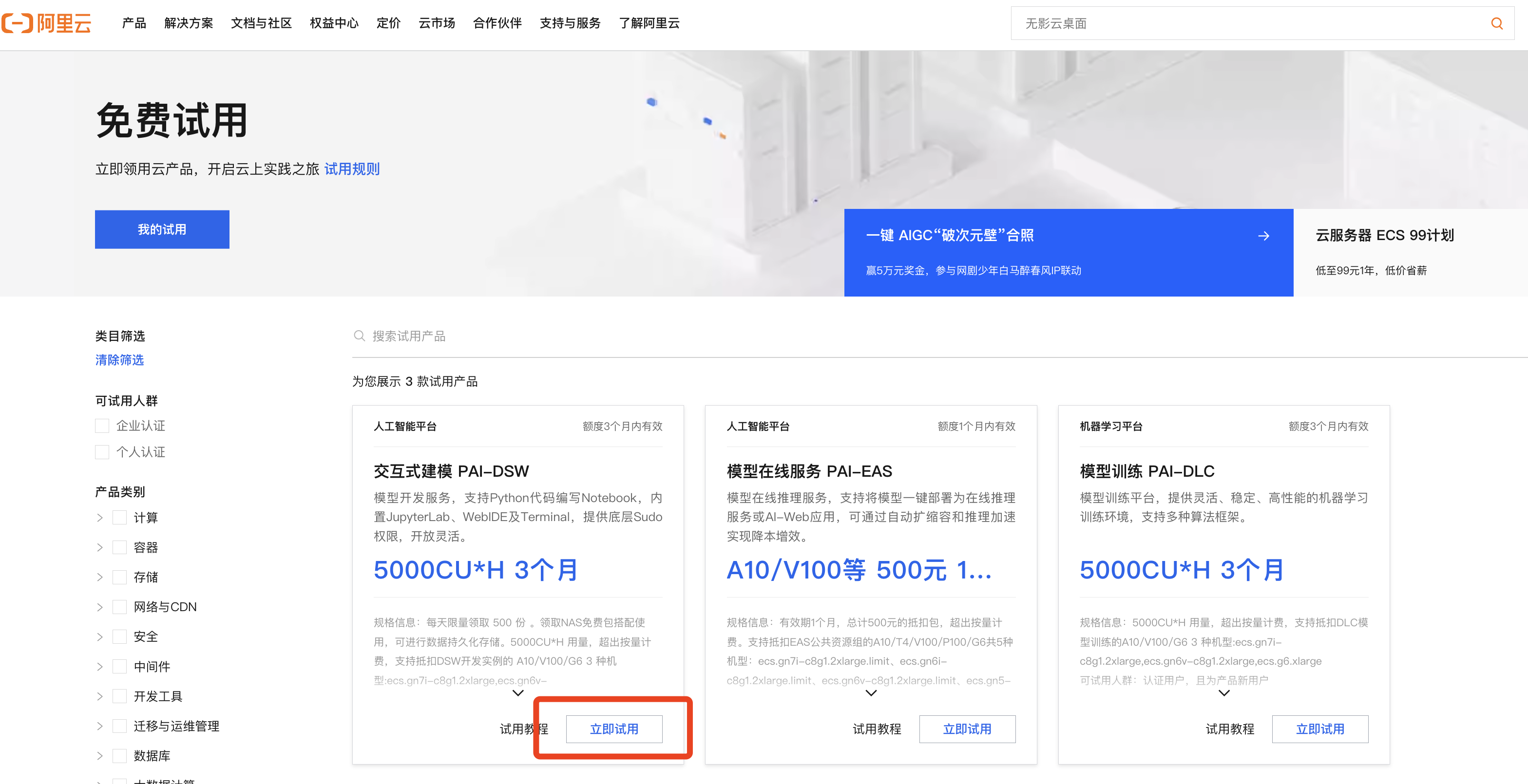
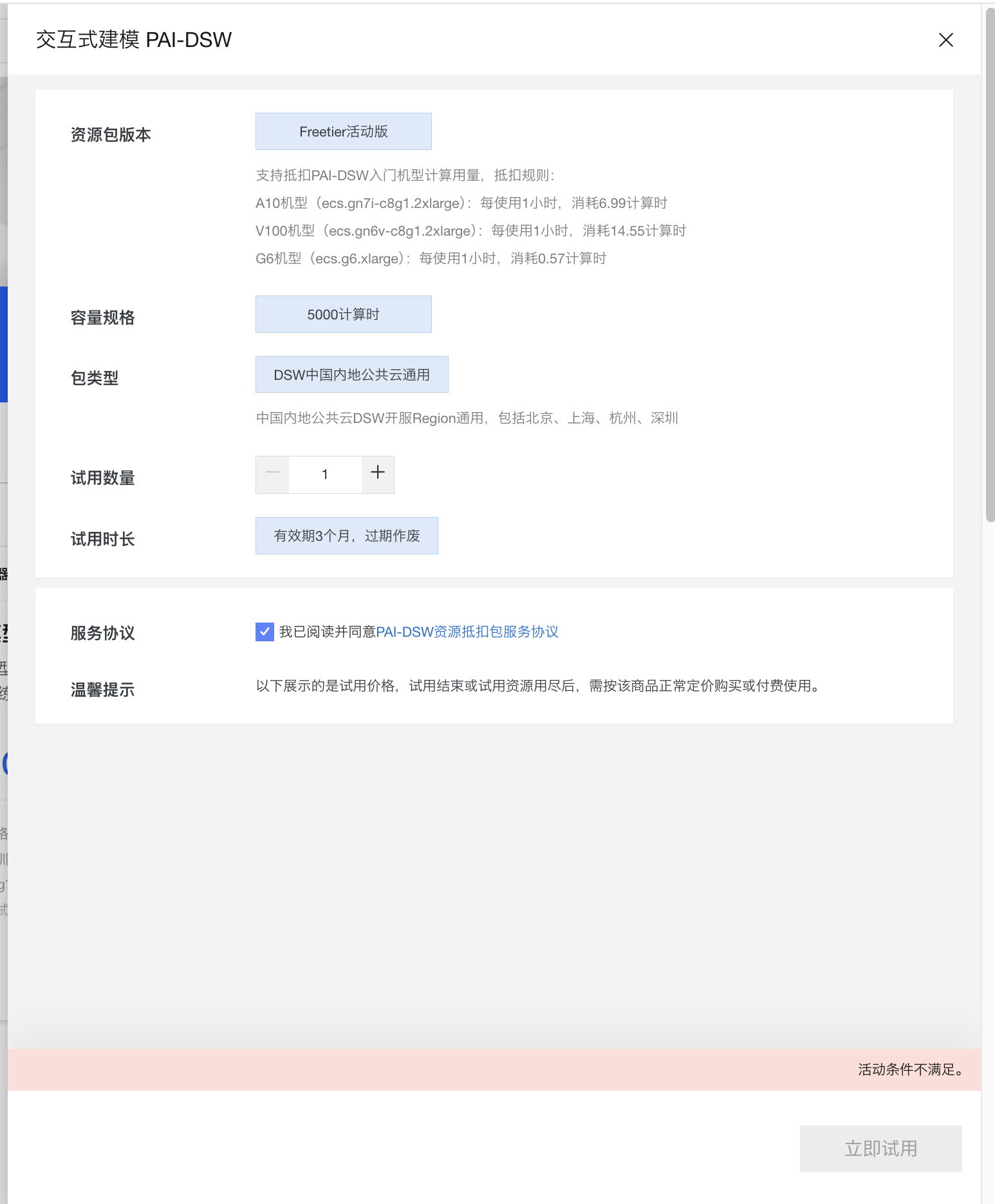
- Step0:开通阿里云PAI-DSW试用
- “阿里云”开通免费试用
https://free.aliyun.com/?productCode=learn
![image]()
![image]()
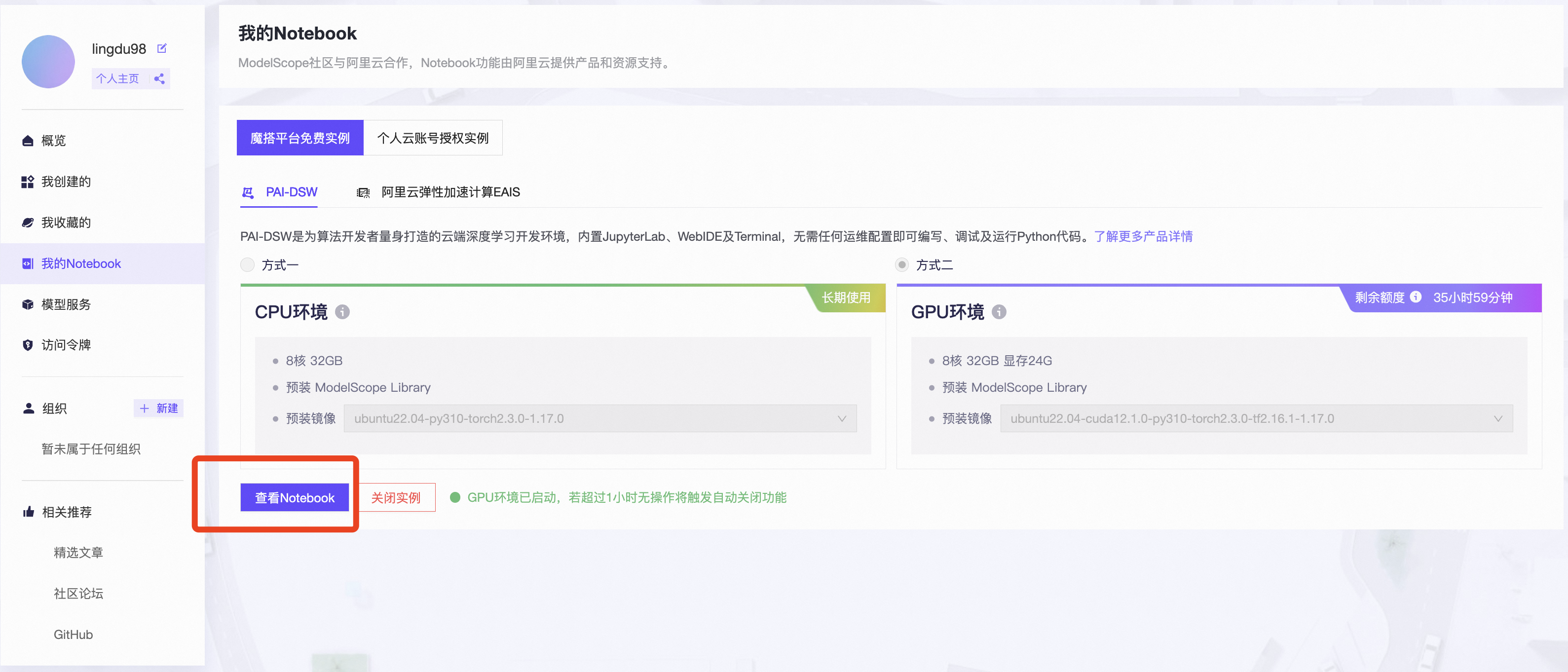
发现“活动条件不满足”,并且我已经完成个人认证了,应该是试用有效期已经过了。 - 直接用魔搭的资源
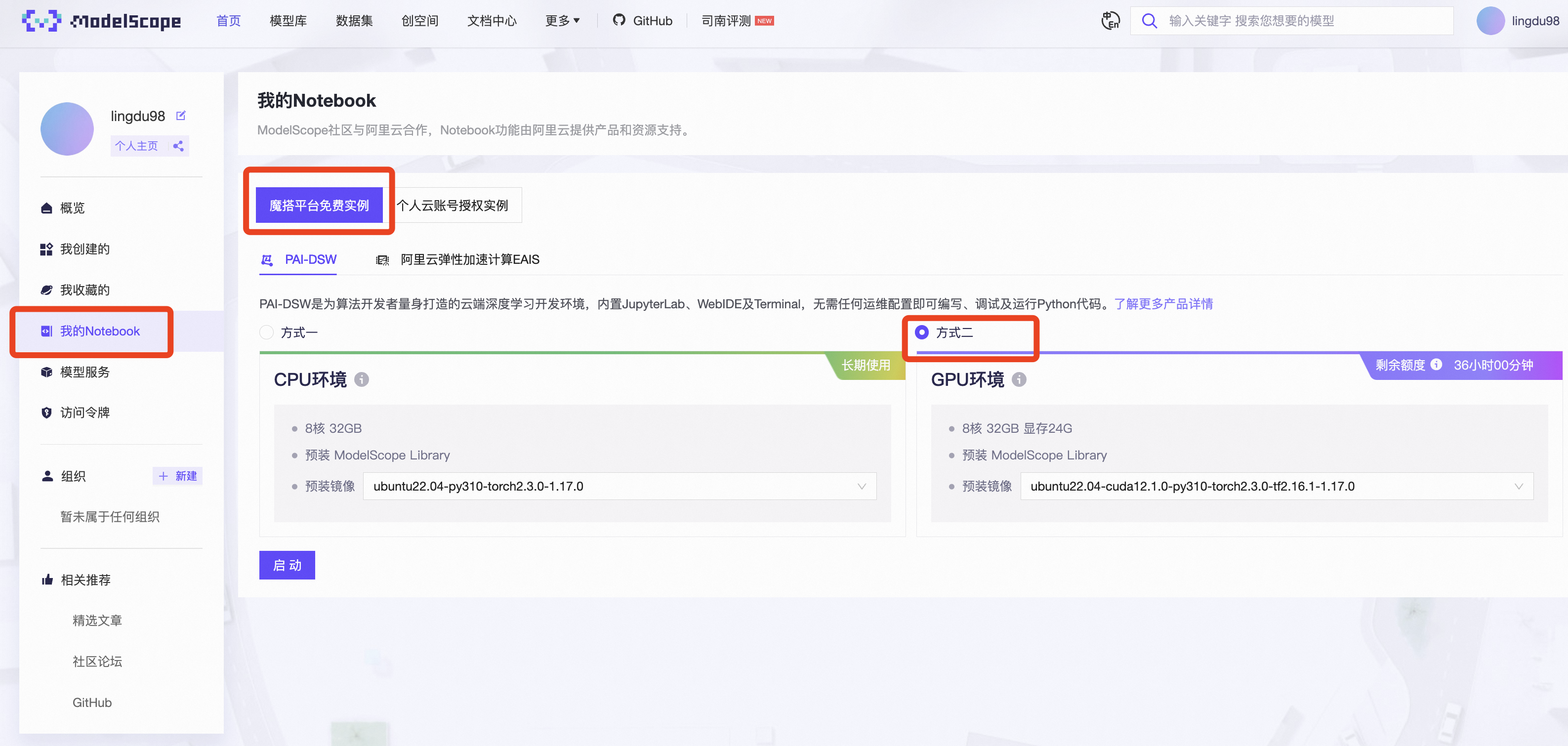
https://www.modelscope.cn/my/mynotebook/preset
![image]()
![image]()
选好配置后,“启动”。
![image]()
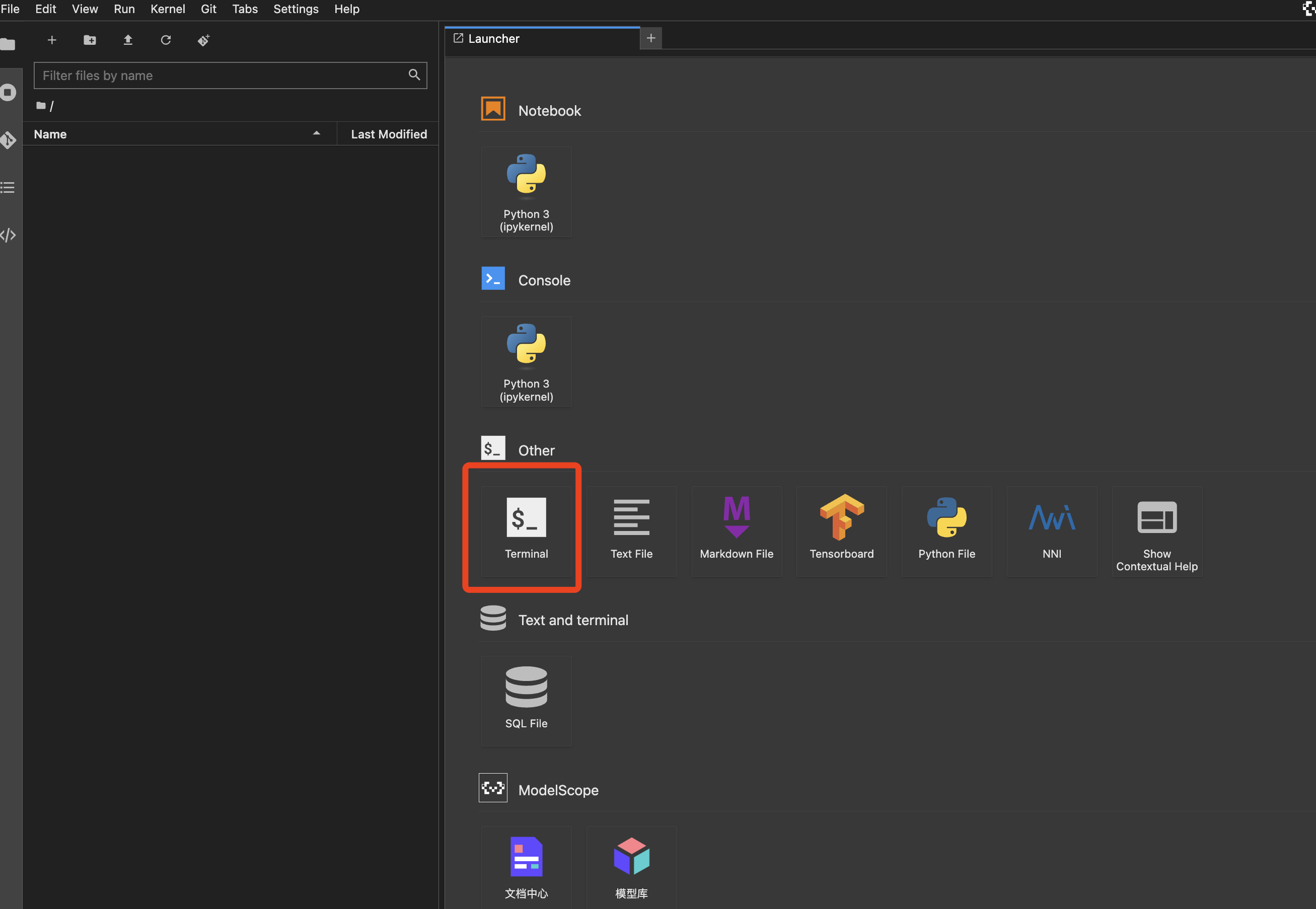
点击进入Notebook。
ps:因为直接使用了魔搭的资源,所以下面跳到Step3,直接来运行baseline。
- “阿里云”开通免费试用
- Step3: 体验一站式 baseline
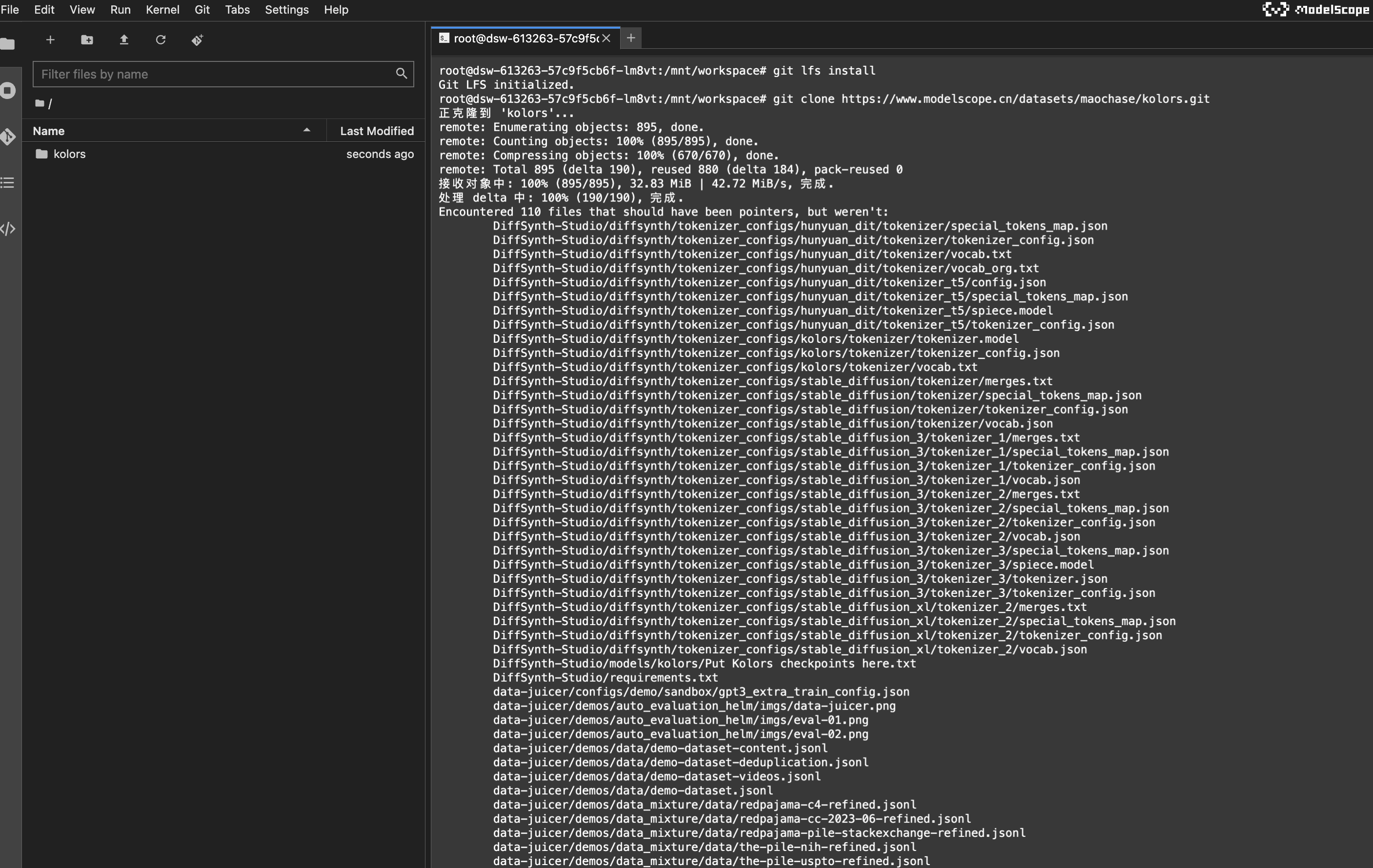
- 下载baseline文件
打开终端Terminal。git lfs install git clone https://www.modelscope.cn/datasets/maochase/kolors.git
![image]()
输入指令。
![image]()
- 进入文件夹,打开baseline.ipynb文件。
![image]()
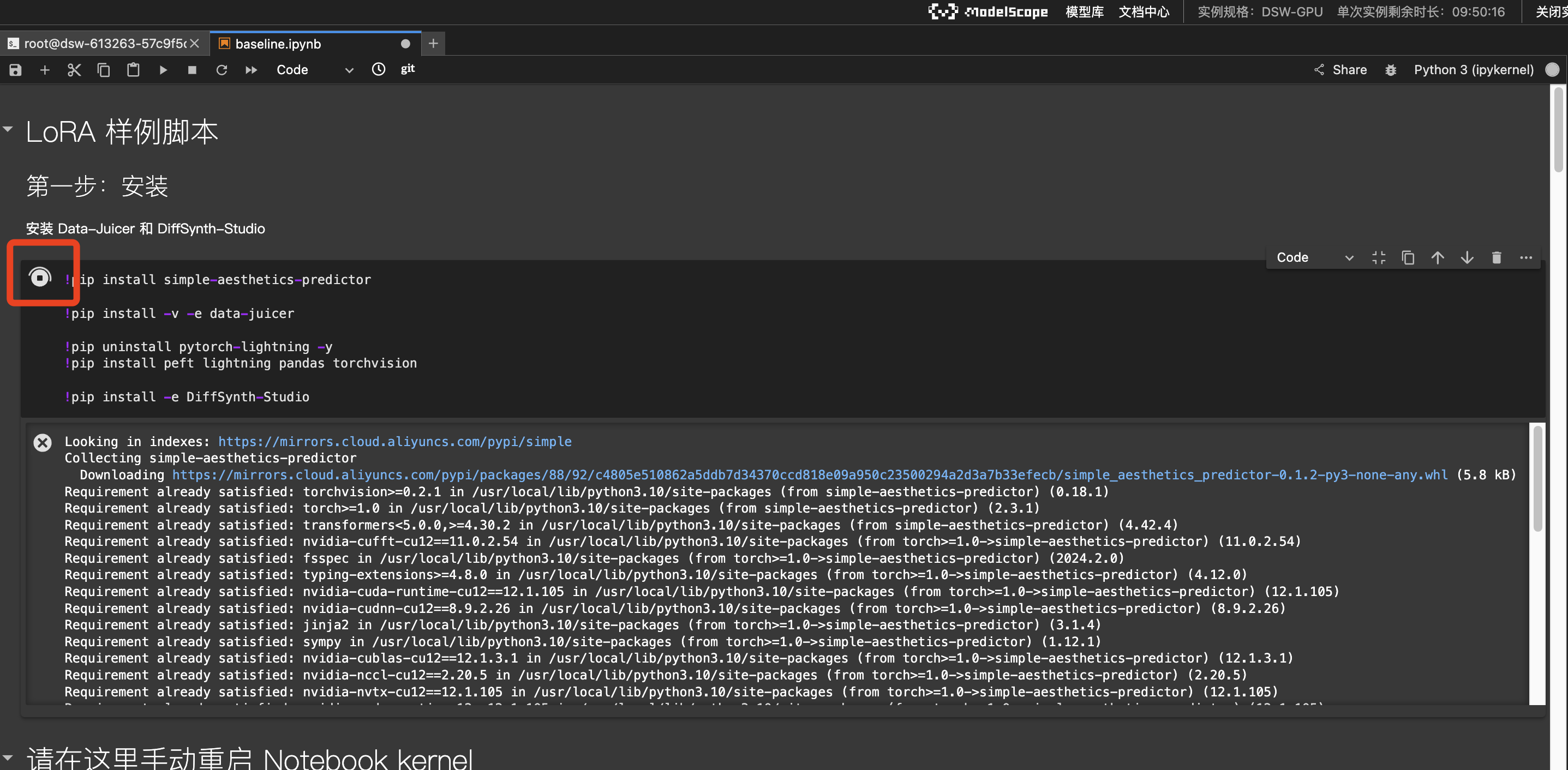
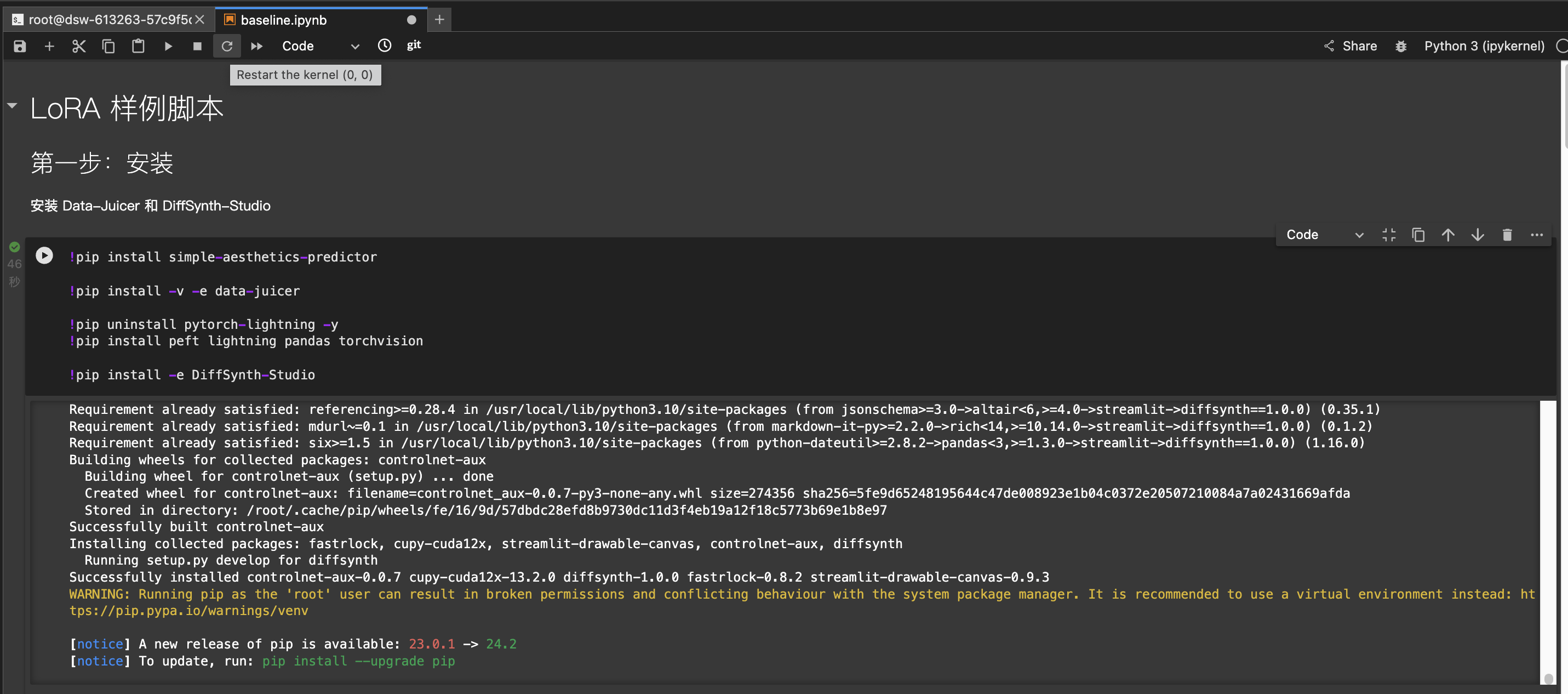
- 点击执行第一个代码块,通过
pip install安装相关环境包。# 安装 Data-Juicer 和 DiffSynth-Studio # Data-Juicer:数据处理和转换工具,旨在简化数据的提取、转换和加载过程 # DiffSynth-Studio:高效微调训练大模型工具![image]()
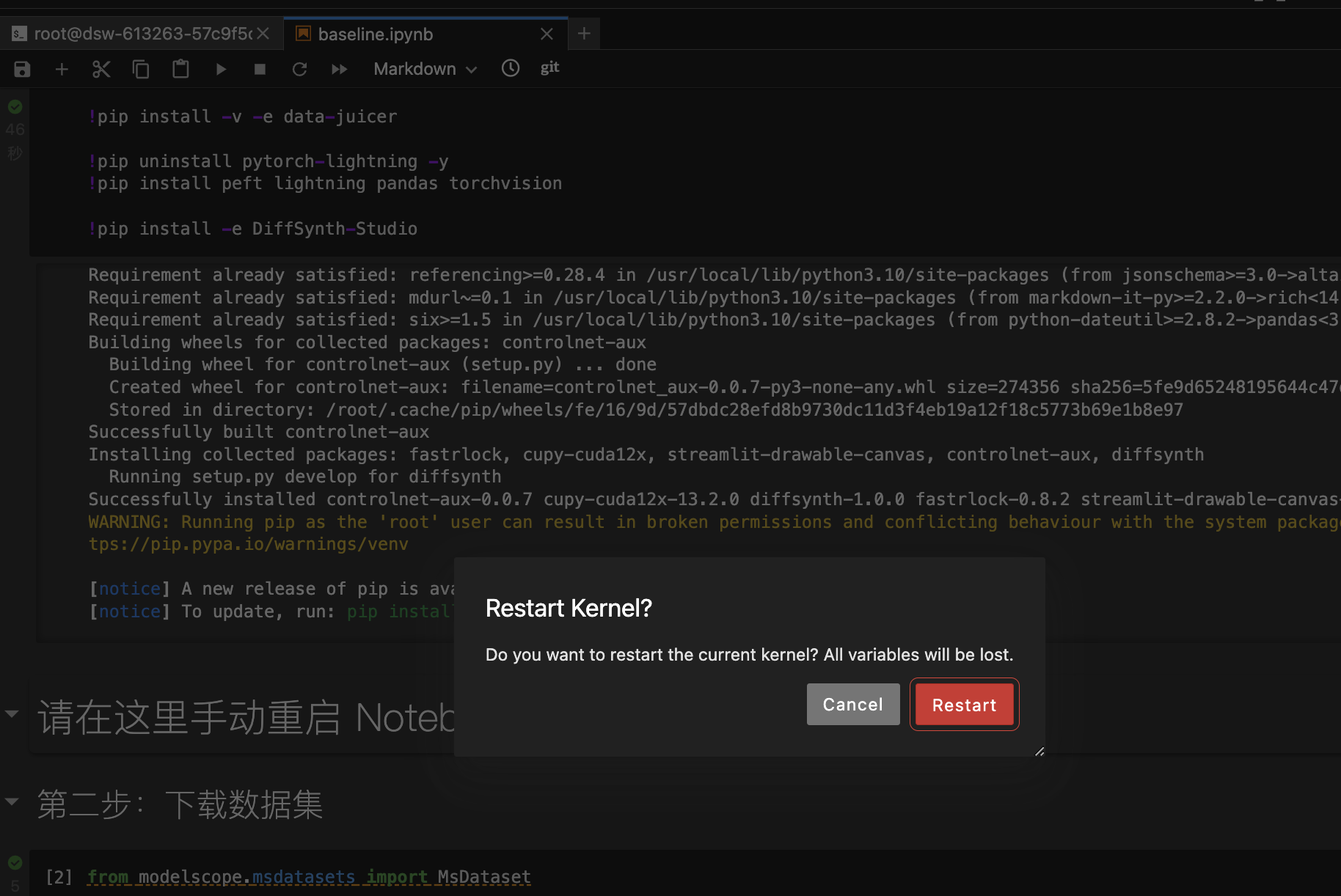
- 显示安装完成后,点击“Restart Kernel”重启核。
![image]()
![image]()
- 首先保留原有prompt,点击一键执行,查看效果。
![image]()
- 其中最耗时的是模型微调部分,总耗时9分多。
![image]()
- 初次执行(未修改prompts)的效果如下,与赛题给出的效果基本一致:
![image]()
- 下载baseline文件
- Step4: 调整prompts,查看效果:
这里首先对小女孩的外观、环境做了一些调整,
提示词改为:
文生图的生成效果如下:prompt="二次元,一个绿色长发小女孩,在海滩上坐着,双手托着腮,很无聊,全身,白色连衣裙", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",
![image]()
再尝试一下生成男生,提示词为:
文生图的生成效果如下:prompt="二次元,一个棕色短发帅气男孩,在草地上站着,双手叉着腰,全身是汗,全身,足球服", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",
![image]()




四、部分代码解读
- 数据处理
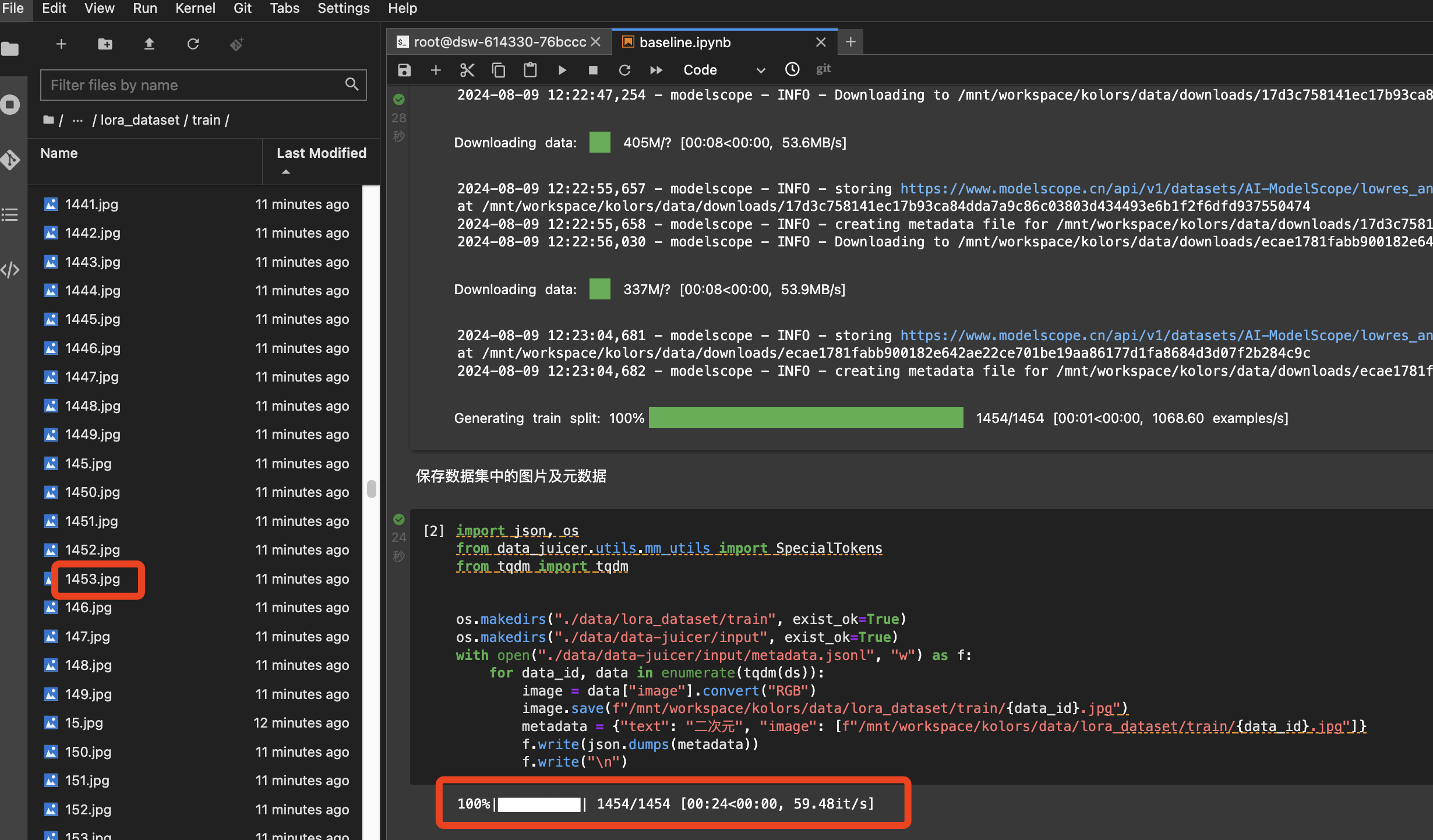
在下载数据、处理数据的过程中,我们会发现:
运行到[2]代码块后,下载并保存的原始数据集路径下(/mnt/workspace/kolors/data/lora_dataset/train/),包含1400+张的训练图片;
![image]()
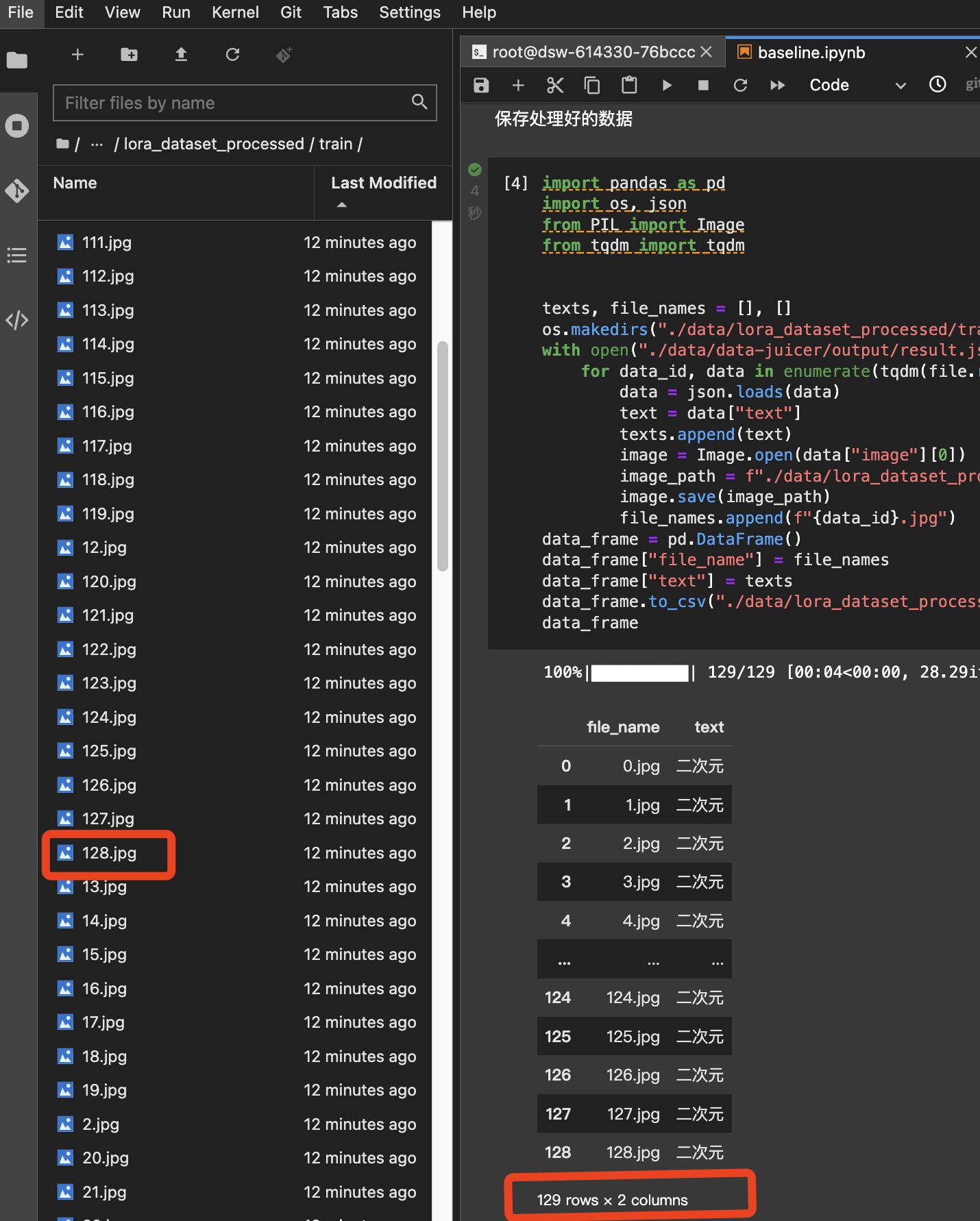
而运行到[4]代码块后,处理后保存的数据集路径下(./data/lora_dataset_processed/train/),包含的训练图片只剩120+张;
![image]()
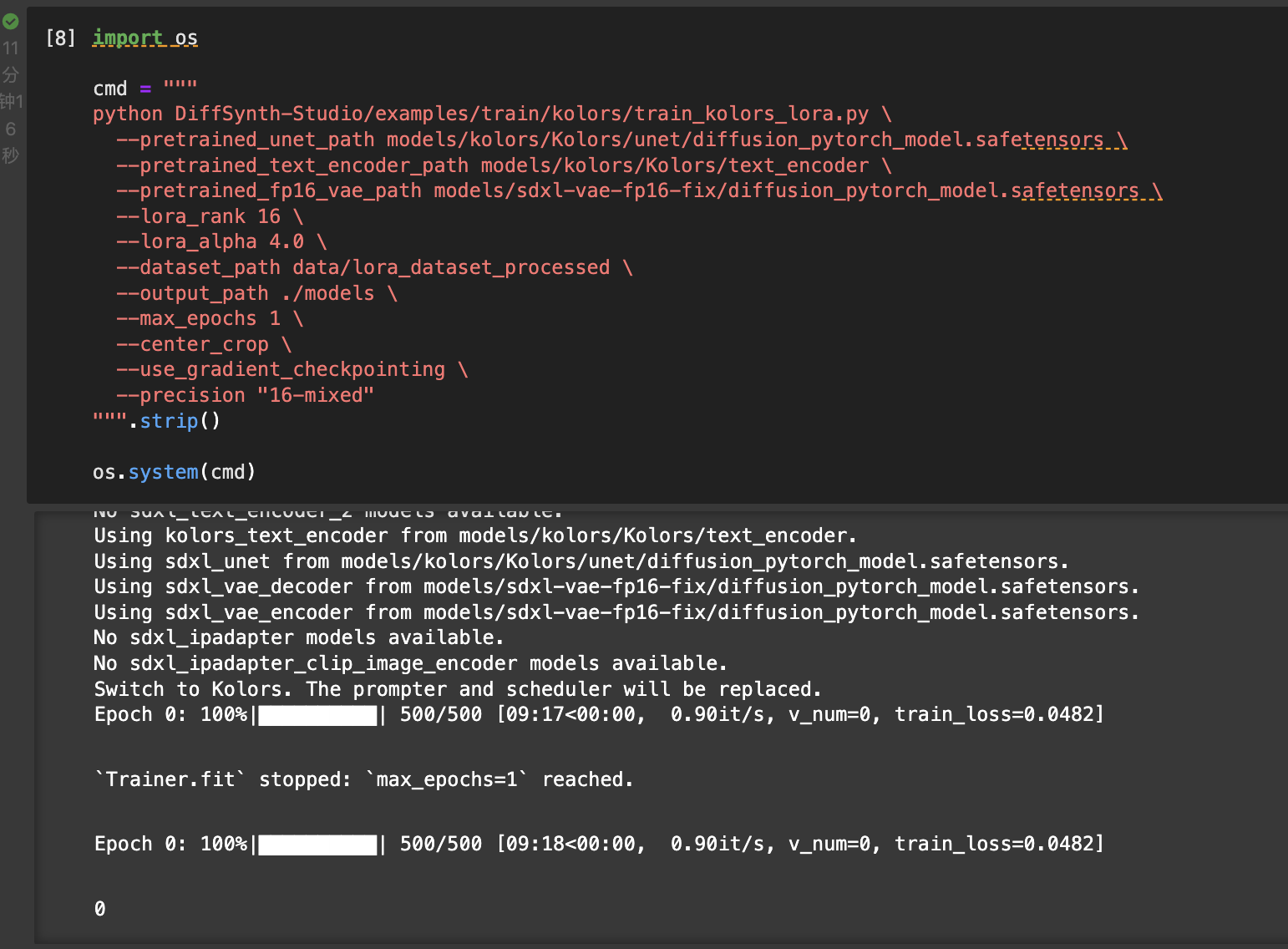
这是因为在数据处理过程中,筛去了大部分图片。这一筛选过程是通过data-juicer工具实现的。具体见[3]代码块中的代码。
可以看到,筛选过滤的条件写在data_juicer_config = """ # global parameters project_name: 'data-process' dataset_path: './data/data-juicer/input/metadata.jsonl' # path to your dataset directory or file np: 4 # number of subprocess to process your dataset text_keys: 'text' image_key: 'image' image_special_token: '<__dj__image>' export_path: './data/data-juicer/output/result.jsonl' # process schedule # a list of several process operators with their arguments process: - image_shape_filter: min_width: 1024 min_height: 1024 any_or_all: any - image_aspect_ratio_filter: min_ratio: 0.5 max_ratio: 2.0 any_or_all: any """ with open("data/data-juicer/data_juicer_config.yaml", "w") as file: file.write(data_juicer_config.strip()) !dj-process --config data/data-juicer/data_juicer_config.yamlimage_shape_filter和image_aspect_ratio_filter中:对于图像尺寸,筛选长或宽大于1024的图像;对于图像长宽比,筛选长宽比处于[0.5, 2.0]的图像。
ps:因为没时间仔细查阅data-juicer工具的文档,所以只能大致解读代码实现的功能。但这已经很能说明data-juicer这个工具在数据处理上的便捷性。
五、8图故事生成
-
一
prompt="二次元,动漫电影效果,一个棕色短发小女孩魔法师,身穿黑紫色魔法师长袍,在家中的魔法实验室里,四周摆满了药瓶和魔法书,她正专心地翻阅一本古老的魔法书籍", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",![image]()
-
二
prompt="二次元,动漫电影效果,人物侧面,一个棕色短发的魔法师小女孩,穿着黑紫色魔法师长袍,背着背包,戴着黑色魔法帽,走在通往森林的小径上,背景是茂盛的树木和飘动的蝴蝶,她脸上带着期待的微笑表情", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",![image]()
-
三
prompt="二次元,动漫电影效果,一个棕色短发的可爱小女孩魔法师,身着紫黑色的魔法长袍,手持木质魔杖,坐在森林中一个草地上,周围是光彩照人的魔法植物,她正专心地向一只坐在石头上的老魔法狐狸学习如何施展光明魔法", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度,色情擦边,手指尖锐",![image]()
-
四
prompt="二次元,动漫电影效果,人物侧面,一个充满神秘雾气的森林湖泊边,棕色短发的小女孩魔法师站在岸边,穿着紫黑色的魔法长袍,望向湖面,她正向一群水元素学习控水魔法,湖面波光粼粼,她嘴巴微张、表情略带惊奇", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度,扭曲的手指,多余的手指",![image]()
-
五
prompt="二次元,动漫电影效果,森林中的一个幽暗洞穴,棕色短发的小女孩魔法师穿着紫色星星点缀的黑色长袍,正蹲下身来向一条巨大的红龙学习火焰魔法,小女孩的眼中反射着火焰的光芒,小女孩张开手掌,她的手中升起一小团火焰", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",![image]()
-
六
prompt="二次元,动漫电影效果,棕色短发小女孩魔法师,她身穿黑紫色魔法师长袍,挥手与森林中的魔法小动物们告别,在森林中的一群魔法小动物围在小女孩身边,抬头望向小女孩", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",![image]()
-
七
prompt="二次元,动漫电影效果,棕色短发的魔法师小女孩在一片热闹的市集中,身穿黑紫色长袍,准备参加魔法师大会,她四周是各路魔法师和炫目的魔法商品", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",![image]()
-
八
prompt="二次元,动漫电影效果,棕色短发的小女孩魔法师在魔法师大会的舞台上展示她的最强魔法,她面带微笑,正用木质魔杖引导着一场壮观的魔法元素风暴,她的黑紫色长袍在魔法光芒中闪耀,观众席上的其他魔法师们露出赞叹的表情", negative_prompt="丑陋、变形、嘈杂、模糊、低对比度、手指模糊",![image]()








六、改进方向
- Prompt工程:通过更细粒度的prompts,进一步提升模型生成效果;
- 高质量训练数据:通过质量更高、数量更多、风格种类更多的训练数据对模型进行微调,使得模型生成效果更为丰富多样;
- 模型微调:通过微调技巧,提高模型微调效果(目前暂不明确,需要进一步研读Lora论文)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号