
彻头彻尾理解 HashMap
https://blog.csdn.net/justloveyou_/article/details/52464440
HashMap是我们非常常用的数据结构,由数组和链表组合构成的数据结构。
数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。
因为他本身所有的位置都为null,在put插入的时候会根据key的hash去计算一个index值。
比如我put(”老虎“,520),我插入了为”老虎“的元素,这个时候我们会通过哈希函数计算出插入的位置,计算出来index是2。
我们都知道数组长度是有限的,在有限的长度里面我们使用哈希,哈希本身就存在概率性,就是”老虎“和”狮子“我们都去hash有一定的概率会一样,就像我再次哈希”狮子“极端情况也会hash到一个值上,那就形成了链表
这里是Node源码

java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是,在java8之后,都是所用尾部插入了。
那为什么用尾插法呢?
首先我们看下HashMap的扩容机制:
数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize。
什么时候resize呢?
有两个因素:
-
Capacity:HashMap当前长度。
-
LoadFactor:负载因子,默认值0.75f。
就比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
扩容分为两步
-
扩容:创建一个新的Entry空数组,长度是原数组的2倍。
-
ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,直接复制过去不好么?
是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式---> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
再回来看尾插法
我先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了
现在我们要在容量为2的容器里面用不同线程插入A,B,C,假如我们在resize之前打个段点,那意味着数据都插入了但是还没resize那扩容前可能是这样的

我们可以看到链表的指向A->B->C
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,B的下一个指针指向了A
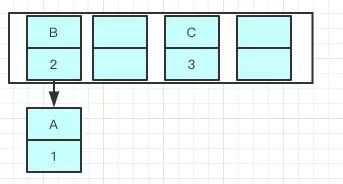
一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,悲剧就出现了——Infinite Loop
接下来看尾插法是怎么样:
因为java8之后链表有红黑树的部分,大家可以看到代码已经多了很多if else的逻辑判断了,红黑树的引入巧妙的将原本O(n)的时间复杂度降低到了O(logn)。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B
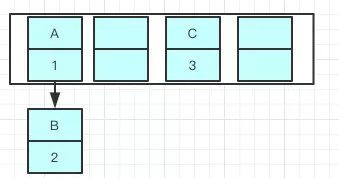
Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那是不是意味着Java8就可以把HashMap用在多线程中呢?
即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
HashMap的默认初始化长度为什么是16?
在JDK1.8的 236 行有1<<4就是16,为啥用位运算呢?直接写16不好么?
在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,而且最好是2的幂
这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。
Hashmap中的链表大小超过八个时会自动转化为红黑树,当删除小于六时重新变为链表,为啥呢?
根据泊松分布,在负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才进行转换,小于等于6的时候就化为链表。
所有的key我们都会拿到他的hash,但是我们怎么尽可能的得到一个均匀分布的hash呢?
我们通过Key的HashCode值去做位运算。
index的计算公式:index = HashCode(Key) & (Length- 1)(具体去百度吧)
之所以用位与运算效果与取模一样,性能也提高了不少
那为啥用16不用别的呢?
因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。
HashMap线程是不安全的,那怎么处理HashMap在线程安全的场景呢?
在这样的场景,我们一般都会使用HashTable或者CurrentHashMap,但是因为前者的并发度的原因基本上没啥使用场景了,所以存在线程不安全的场景我们都使用的是CorruentHashMap。
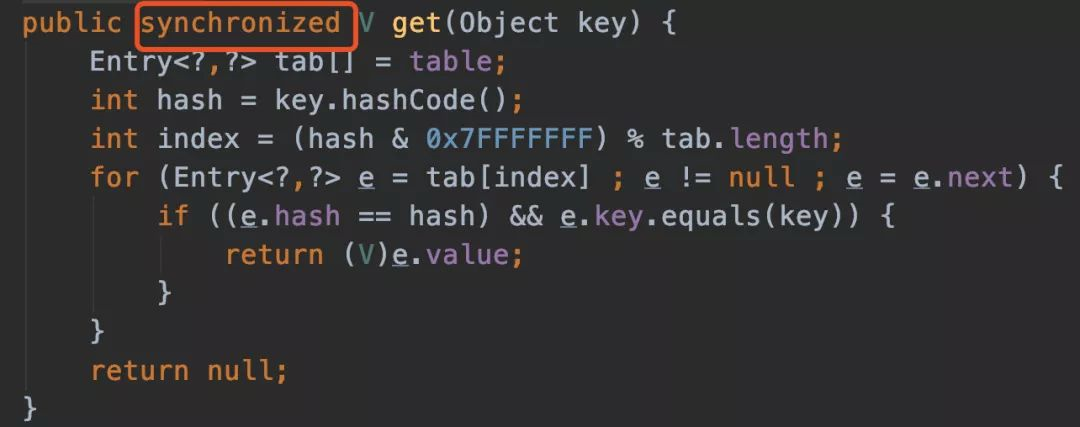
HashTable的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问
HashMap常见面试题:
-
HashMap的底层数据结构?
-
HashMap的存取原理?
-
Java7和Java8的区别?
-
为啥会线程不安全?
-
有什么线程安全的类代替么?
-
默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
-
HashMap的扩容方式?负载因子是多少?为什是这么多?
-
HashMap的主要参数都有哪些?
-
HashMap是怎么处理hash碰撞的?
-
hash的计算规则?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号