
微服服务跟踪
服务追踪系统实现
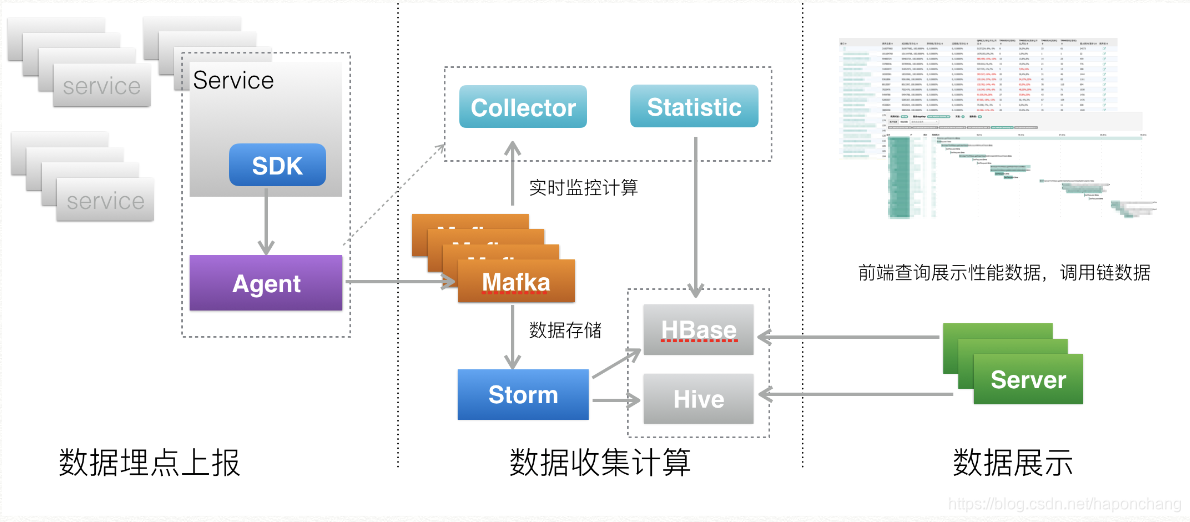
上面是服务追踪系统架构图,你可以看到一个服务追踪系统可以分为三层。
数据采集层,负责数据埋点并上报。
数据处理层,负责数据的存储与计算。
数据展示层,负责数据的图形化展示
服务追踪的作用
第一,优化系统瓶颈。
通过记录调用经过的每一条链路上的耗时,我们能快速定位整个系统的瓶颈点在哪里。比如你访问微博首页发现很慢,肯定是由于某种原因造成的,有可能是运营商网络延迟,有可能是网关系统异常,有可能是某个服务异常,还有可能是缓存或者数据库异常。通过服务追踪,可以从全局视角上去观察,找出整个系统的瓶颈点所在,然后做出针对性的优化。
第二,优化链路调用。
通过服务追踪可以分析调用所经过的路径,然后评估是否合理。比如一个服务调用下游依赖了多个服务,通过调用链分析,可以评估是否每个依赖都是必要的,是否可以通过业务优化来减少服务依赖。
此外,一般业务都会在多个数据中心都部署服务,以实现异地容灾,这个时候经常会出现一种状况就是服务 A 调用了另外一个数据中心的服务 B,而没有调用同处于一个数据中心的服务 B。跨数据中心的调用视距离远近都会有一定的网络延迟,像北京和广州这种几千公里距离的网络延迟可能达到 30ms 以上,这对于有些业务几乎是不可接受的。通过对调用链路进行分析,可以找出跨数据中心的服务调用,从而进行优化,尽量规避这种情况出现。
第三,生成网络拓扑。
通过服务追踪系统中记录的链路信息,可以生成一张系统的网络调用拓扑图,它可以反映系统都依赖了哪些服务,以及服务之间的调用关系是什么样的,可以一目了然。除此之外,在网络拓扑图上还可以把服务调用的详细信息也标出来,也能起到服务监控的作用。
第四,透明传输数据。
除了服务追踪,业务上经常有一种需求,期望能把一些用户数据,从调用的开始一直往下传递,以便系统中的各个服务都能获取到这个信息。比如业务想做一些 A/B 测试,这时候就想通过服务追踪系统,把 A/B 测试的开关逻辑一直往下传递,经过的每一层服务都能获取到这个开关值,就能够统一进行 A/B 测试。
服务追踪系统原理
它的核心理念就是调用链:通过一个全局唯一的 ID 将分布在各个服务节点上的同一次请求串联起来,从而还原原有的调用关系,可以追踪系统问题、分析调用数据并统计各种系统指标。
可以说后面的诞生各种服务追踪系统都是基于 Dapper 衍生出来的,比较有名的有 Twitter 的Zipkin、阿里的鹰眼、美团的MTrace等。(服务追踪系统的鼻祖:Google 发布的一篇的论文Dapper, a Large-Scale Distributed Systems Tracing Infrastructure,里面详细讲解了服务追踪系统的实现原理。)
要理解服务追踪的原理,首先必须搞懂一些基本概念:traceId、spanId、annonation 等。Dapper 这篇论文讲得比较清楚,但对初学者来说理解起来可能有点困难,美团的 MTrace 的原理介绍理解起来相对容易一些,下面我就以 MTrace 为例,给你详细讲述服务追踪系统的实现原理。虽然原理有些晦涩,但却是你必须掌握的,只有理解了服务追踪的基本概念,才能更好地将其实现出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号