
【转】深入理解内存分配
相信大家在学习C语言的时候,malloc是最早遇到的几个方法之一,这里就来深入的了解下,macOS/iOS中用户空间的内存分配。
引言
首先,我们来看几个有意思的例子,以下几个在x86_64或者ARM64中的运行情况。
|
1
2
3
|
char *str = malloc(32);
free(str);
str[0] = 'a';
|
|
1
2
3
|
char *str = malloc(32);
free(str);
str[12] = 'a';
|
|
1
2
3
|
char *str = malloc(32);
free(str);
str[18] = 'a';
|
这里先说一下结果,之后再来分析为什么,看看你有没有猜对。
这里均不会在str[x] = 'a';这一行崩溃,而可能在下次内存分配的时候崩溃。
第一个会报malloc: *** error for object 0x60000003cfa0: Invalid pointer dequeued from free list。
第二个会触发BAD_ACCESS的错误。
第三个运行一切正常,不会崩溃。
内核内存申请
malloc方法并不止提供了向内核申请内存(syscall)的功能,它还提供了一整套用户态的内存管理。比如linux-2.3之后使用的ptmalloc,FreeBSD使用的jemalloc,以及macOS/iOS使用的malloc_zone及libmalloc。
向内核申请内存,触发系统调用,比较通用的接口有sbrk和mmap。在mac上,sbrk已经被废弃,而所有内存申请的内核调用最终都会转到
|
1
2
3
4
5
6
7
|
kern_return_t mach_vm_allocate
(
vm_map_t target,
mach_vm_address_t *address,
mach_vm_size_t size,
int flags
);
|
这个内核方法,我们可以通过vm_allocate去间接的调用它。
有人建议使用系统自带的malloc来构建自己的内存管理程序,这样就不用考虑不同平台的差异性;也有人认为在别人的管理系统上创建,不能达到更好的性能。这些还是具体情况具体分析吧,后面会简单介绍下如何构建自己的内存管理系统。
回到内核内存,内核内存都是按页管理的,你不可能向内核申请1byte的内存,所有的内存申请都需要经过round,否则会导致申请内存失败,其定义如下:
|
1
2
3
4
5
|
extern vm_size_t vm_page_size;
// These macros assume vm_page_size is a power-of-2.
|
用户态内存申请
用户态的内存管理方案实在太多了,这里主要说一下大家都比较通用的部分,以及libmalloc的实现。
由于系统提供的内存,最少是一页,那么程序如果申请小块内存,特别像Objc这种含有大量小内存的情况,我们总不可能为一个指针分配一页内存吧。
这里几乎所有的内存分配库都采用了相同的做法,即将内存分为不同大小来管理,某些地方称为size class,某些地方称为chunk,而mac中就是malloc_zone了。
mac中的malloc_zone大致分为以下几种:
- nano zone. <256
- tiny zone. <同nano
- small zone. <1024 bytes (64-bit), <512 bytes (32-bit)
- large zone.
申请不同大小的内存将会被派分到对应的zone,而各自的zone会采取不同的策略,比如nano, tiny, small是在内存页链表中寻找到一块拥有足够空闲空间的页,在这个页中分配该大小的内存;而large则是直接分配多个内存页,销毁的逻辑也完全不一样。
这里看到nano和tiny是重合的,他们之间有什么区别呢?这个问题放到下面多线程中去详细描述。
为什么需要将内存分配做这样的切分呢。由于我们平时使用到的内存大部分为小内存(这个在之后我会给一个统计结果),特别像是Objc这种语言,由于所有对象存在都是heap中的,所以基本都是以小指针对象,可能会导致大量小内存的申请和销毁,那么作为一个较为通用的内存分配器,那么肯定要考虑到优化小指针的分配效率。
这里再看一下Google的tcmalloc的划分策略。
The size-classes are spaced so that small sizes are separated by 8 bytes, larger sizes by 16 bytes, even larger sizes by 32 bytes, and so forth.
可以看到它对size-class的划分更为细致,而且它会在运行时根据具体情况具体可能会调整这个粒度,同时不会在同一页中分配任意size-class的内存,这样做是为了避免碎片。更高细粒度的划分会让程序在划分的时候更为简单,从而增加了效率,但这样也会增加缓冲内存的大小,个人觉得正是这个原因导致tcmalloc并没有考虑移动设备。
用户态内存销毁
以上说明了内存申请的方式,现在来看看如何销毁内存的。
如果是大块内存(large zone),那么视系统有没有指定内存页的缓存,否则就直接归还给系统。
那么如果是小内存(nano除外),在调用free之后
- 会先根据配置情况是否需要将内存重置为
0x55,正常情况下不会执行这一步。 - 由于最小内存为
2 * sizeof(void *),所以会将第一个指针位置更新成为一个token。 - 合并旁边的空闲内存。
- 将第二个指针位置更新为下一个空闲内存的地址或者NULL。
- 将当前空闲内存加入
free-list缓存,当下次申请新内存的时候,会优先在缓存中寻找是否有适合的空闲内存段,没有才会向系统申请新的内存页。
这里和我们的理解上有些偏差了,free并没有第一时间把我们的内存还给系统,也就是说free之后的内存其实还是在用户空间的,我们有可能还是可以任意读写该段内存的。这也就是引言中的例子。
但是如果我们修改了小内存的第一个指针位置,会导致我们的token失效,结果在复用该free-list中的缓存时候,会去校验当前缓存的token,导致Invalid pointer dequeued from free list错误。就如下所示:
|
1
2
3
4
|
typedef struct chained_block_s {
uintptr_t double_free_guard;
struct chained_block_s *next;
} *chained_block_t;
|
|
1
2
3
4
5
|
void free(nanozone_t *nanozone, void *ptr) {
// ...
((chained_block_t)ptr)->double_free_guard = (0xBADDC0DEDEADBEADULL ^ nanozone->cookie);
// ...
}
|
而如果我们修改的是第二个指针位置的数据,则会导致该指针非NULL,导致查询下一个空闲内存块的时候内存访问错误。
而如果我们去修改其他位置的数据,则不会有任何问题。
这里我们看到,一些非常奇怪的崩溃,有可能是由于这种写入释放后指针引起的。
tcmalloc
可以看到上面的free过程中,是会有空闲内存的合并问题,这些当然也就会产生内存碎片。
|
1
2
3
|
| 64 | 64 | |
| null | 64 | |
| 48 | null | 64 | v
|
如上图所示,中间的16byte可能就无法进行新的利用,好在我们的objc对象几乎都是几个指针的大小,加之malloc也会进行一次round,所以利用率还不错。
那么tcmalloc是怎么来进行优化的呢?由于tcmalloc在设计之初就不存在一个chunk中存在多个size-class的情况,所以一旦free,只需要将其丢进free-list中就可以了,在需要的时候再进行GC,将多余的空闲内存出让给别人或者还给系统。这样就避免了合并的性能开销。
多线程安全问题
现在的应用都是多线程的,按照我们上面所述的,均没有涉及到线程安全问题,那么最简单的方法就是对所有内存申请及销毁进行加锁。但是锁是一种相对比较耗资源的东西,普通锁可能会涉及到系统调用,spinlock又可能会导致优先级反转等问题,那么大家都是怎么解决这个问题的呢?
libmalloc的解决方式比较传统,也就是加锁,但是在nano malloc中会有特别的优化。
- 每个CPU都会分配一个属于自己的分配器,也就是说每个CPU都有属于自己的内存缓存。
- 内存划分和
tcmalloc类似,一个slot(size-class)中只有一种大小的对象,这样就不存在内存合并的问题了。 - 在修改
free-list的时候采用的是原子操作,而不是传统意义的锁。 - 只在需要扩展堆,也就是增长空闲内存的时候,才使用真正的锁。
- 64位系统才开始支持,因为需要指针长度达到64位。
- 所有的指针均有相同的开头,比如
x86_64上一定是0x00006nnnnnnnnnnn,arm上这个值会不一样。 - 所有的slot(size-class)最大容量均为
0x20000大小,而里面存在的对象个数会不一样。 - 当申请对象个数超过对应slot的最大个数的时候(
slot_exhausted),会fall through进入scalable zone进行申请。
造成以上几个魔法数字的原因是nona分配器使用指针储存了部分free-list的信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
struct nano_blk_addr_s {
uint64_t
nano_offset:NANO_OFFSET_BITS, // locates the block
nano_slot:NANO_SLOT_BITS, // bucket of homogenous quanta-multiple blocks
nano_band:NANO_BAND_BITS,
nano_mag_index:NANO_MAG_BITS, // the core that allocated this block
nano_signature:NANO_SIGNATURE_BITS; // the address range devoted to us.
};
// 这个是指针,也是该内存对象的信息
typedef union {
uint64_t addr;
struct nano_blk_addr_s fields;
} nano_blk_addr_t;
|
可以说nano_malloc_zone是专门为了OC而优化的。
而tcmalloc和部分其他分配器(jemalloc),则是采取每一个线程上都独立拥有一个分配器,那么在该线程上进行free-list的操作时(申请内存的时候从缓存读取,及释放内存的时候直接加到缓存),就实现了无锁。当然,增长缓存以及GC等需要和其他线程交互的时候,还是需要锁的。这么做也会减少空闲内存的利用率。
思考
之前看到过如何解决一些主线程大量释放对象的问题,为了优化释放所消耗的时间,将所有释放工作都放到子线程中,这是否真的是一种好的方案呢?
内存分配优化
根据我们上面的分析,可以看到这些分配器都是通用型分配器,它考虑了各种长度大小的性能,但是没有考虑过一些对象的生命周期等。
在一些特殊的场景和应用中,比如音乐、视频、人工智能、游戏等,可能会出现大量特定长度的对象,也可能会出现一些常驻内存,而这些对象会导致通用内存分配器的性能降低,以及重复利用率降低。
如果我们要做到极致性能的内存管理,那么我们就需要进行分析应用的内存分配情况,以及性能。然后根据需要自定义内存管理模块,并与通用管理进行对比。
替换系统默认内存分配方式
替换默认malloc的方法很多,如果是使用的C++,替换new的方式也比较常见,鉴于默认new都是基于malloc实现的,这里只看替换malloc的方法。
define
|
1
|
|
这种方法很傻瓜,只能替换可以被宏替换的地方,在部分场景替换还是很方便。
alias
|
1
2
|
void my_malloc () { /* Do something. */; }
void malloc () __attribute__ ((alias ("my_malloc")));
|
利用编译器进行符号的替换,这样可以替换本身以及静态库中的malloc。得益于MachO文件的二级命名空间,并不会替换动态库中的方法。
符号覆盖
|
1
2
3
|
void *malloc(size) {
dlsym(RTLD_NEXT, "malloc");
}
|
在项目内可以直接定义新的malloc方法,链接器会将自身和静态库的malloc链接到自己的方法,如果需要调用原本的方法,可以使用dlsym(RTLD_NEXT, "malloc")。同样无法替换动态库的malloc。
mac上可行
|
1
|
__attribute__ ((section("__DATA, __interpose")))
|
iOS上被禁用的特性。
动态库符号链接替换
fish_hook提供了一种修改动态库符号链接的方法,前提是替换的被替换的对象需要在动态库中,也是只能替换映射到自身的malloc,无法替换动态库的方法。
但是这种方式比较灵活,可以根据情况动态的打开关闭。
malloc_zone
影响面最大的就是替换malloc_default_zone了,这样动态库的malloc也会使用新的内存管理。
系统并没有公开方法给我们替换default_zone的方法,其实私有方法也没有替换的方法,这里就用到了一个技巧,malloc_zone_unregister的时候,会将unregister_zone和zone列表最后一个zone交换来填补zone数组,所以就可以用以下方式来替换。
|
1
2
3
4
|
malloc_zone_register(my_zone);
malloc_zone_t *default_zone = malloc_default_zone()
malloc_zone_unregister(default_zone);
malloc_zone_register(default_zone);
|
替换完以后必须把unregister的注册回去,不然可能会导致某些对象释放时找不到对应的zone。
同时这些方法之间无法保证线程安全,由于内部的锁并未公开,所以这里需要在程序运行之前,也就是main函数开始时,或是更早进行替换。
这样我们就得到了一个完全属于自己的内存管理方案。
应用内内存使用分析
在进行替换之前,我们需要去分析当前内存使用状况,以及性能状态,从而才可以得知我们替换的内存管理方案有效。
为了做这个脚手架,也耗费了我相当长的时间。这里来看看如何去实现收集内存使用状况。这里就不能使用task_info,host_statistics和sysctl这样粗略的统计方法了。
由于性能以及Objc对象无法完全摆脱malloc_zone(会导致统计的死循环),所以这里使用C++来实现统计分析。
线程安全
首先,需要考虑到的是线程安全,这里可以使用锁来简单的解决这个问题,但是这样同时也会大大影响性能,甚至可能会影响统计结果,所以这里采用ThreadLocal的方案。
每一个线程都有自己独立统计数据存放池,这样在新增数据等操作的时候就不需要加锁了,也尽量避免对性能有太大的影响。
malloc死循环
我们统计malloc,在生成统计数据的时候依然可能会调用到malloc,这样我们就可能形成了一个死循环,那么我们需要解决这种循环有两种方法。
- 在统计过程中修改标志位,统计结束重置该标志位,在这之间的malloc不进入统计。如果上面选择使用的是锁,那么这里也要加锁,如果上面选择的是
ThreadLocal,那么这里每个线程也需要一个独立的标志。 - 修改内存申请方式,不用malloc,使用系统底层实现
vm_allocate。
这里,我选用第2中方案,为此需要C++的Allocator:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
template <class _Tp>
class VMAllocator : public std::allocator<_Tp> {
public:
typedef typename std::allocator<_Tp>::pointer pointer;
typedef typename std::allocator<_Tp>::size_type size_type;
pointer allocate(size_type __n, std::allocator<void>::const_pointer = 0)
{
size_type n = round_page(__n * sizeof(_Tp));
vm_address_t addr;
kern_return_t rt = vm_allocate(mach_task_self(), &addr, n, VM_FLAGS_ANYWHERE);
if (rt != KERN_SUCCESS) {
throw std::bad_alloc();
}
vm_protect(mach_task_self(), addr, n, true, VM_PROT_READ|VM_PROT_WRITE);
return reinterpret_cast<pointer>(addr);
}
void deallocate(pointer __p, size_type __n) noexcept
{
size_type n = round_page(__n);
kern_return_t rt = vm_deallocate(mach_task_self(), reinterpret_cast<vm_address_t>(__p), n);
if (rt != KERN_SUCCESS) {
}
}
};
|
获取每一个内存申请数据
那么我们如何去获取这样详细的统计数据呢?只能去hook malloc的方法了,这里我们需要去hook malloc_zone->malloc的方法。
我们如何才能获得malloc_zone的真正对象呢,其实这些对象都是有全局的名字的。
|
1
2
|
extern "C" malloc_zone_t **malloc_zones;
extern "C" int32_t malloc_num_zones;
|
其中malloc_zones[0]就是default_zone。
由于malloc_zone是readonly状态,我们需要先修改权限才能继续hook。同时由上面所说的,这些都是非线程安全的操作,所以需要在启动的时候就完成,并且运行过程中不能修改。
|
1
2
3
|
mprotect(orig_zone_ptr_, sizeof(malloc_zone_t), PROT_READ|PROT_WRITE);
orig_zone_ptr_->malloc = Wrap::malloc;
mprotect(orig_zone_ptr_, sizeof(malloc_zone_t), PROT_READ);
|
logger
其实系统也开放了两个钩子对象,分别给我们统计系统调用和malloc调用的情况:
|
1
2
3
4
5
6
7
8
9
|
// For logging VM allocation and deallocation, arg1 here
// is the mach_port_name_t of the target task in which the
// alloc or dealloc is occurring. For example, for mmap()
// that would be mach_task_self(), but for a cross-task-capable
// call such as mach_vm_map(), it is the target task.
typedef void (malloc_logger_t)(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t arg3, uintptr_t result, uint32_t num_hot_frames_to_skip);
extern malloc_logger_t *__syscall_logger;
|
|
1
2
3
4
5
6
7
8
9
|
// We set malloc_logger to NULL to disable logging, if we encounter errors
// during file writing
typedef void(malloc_logger_t)(uint32_t type,
uintptr_t arg1,
uintptr_t arg2,
uintptr_t arg3,
uintptr_t result,
uint32_t num_hot_frames_to_skip);
extern malloc_logger_t *malloc_logger;
|
由于这里我们不需要统计malloc的数据(我们更关心OC对象),但是我们还是希望了解系统调用发生的次数(系统调用是一种比较慢的操作)。
启动
这里我做了一个不完整的工具放在github,欢迎大家进行补充。只需要将动态库导入,并在程序开始的时候配置就可以了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
int main(int argc, char * argv[]) {
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(1 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
malloc_detector_show_inspector();
});
malloc_detector_attach_zone(true);
malloc_detector_start();
@autoreleasepool {
return UIApplicationMain(argc, argv, NSStringFromClass([Application class]), NSStringFromClass([AppDelegate class]));
}
}
|
统计结果
下面就来看看我在我们app里面统计得到的结果。
设备iPhone 7。在此期间系统调用12898次。
这里是内存申请大小之和按照时间顺序的情况,其中size作log2处理。
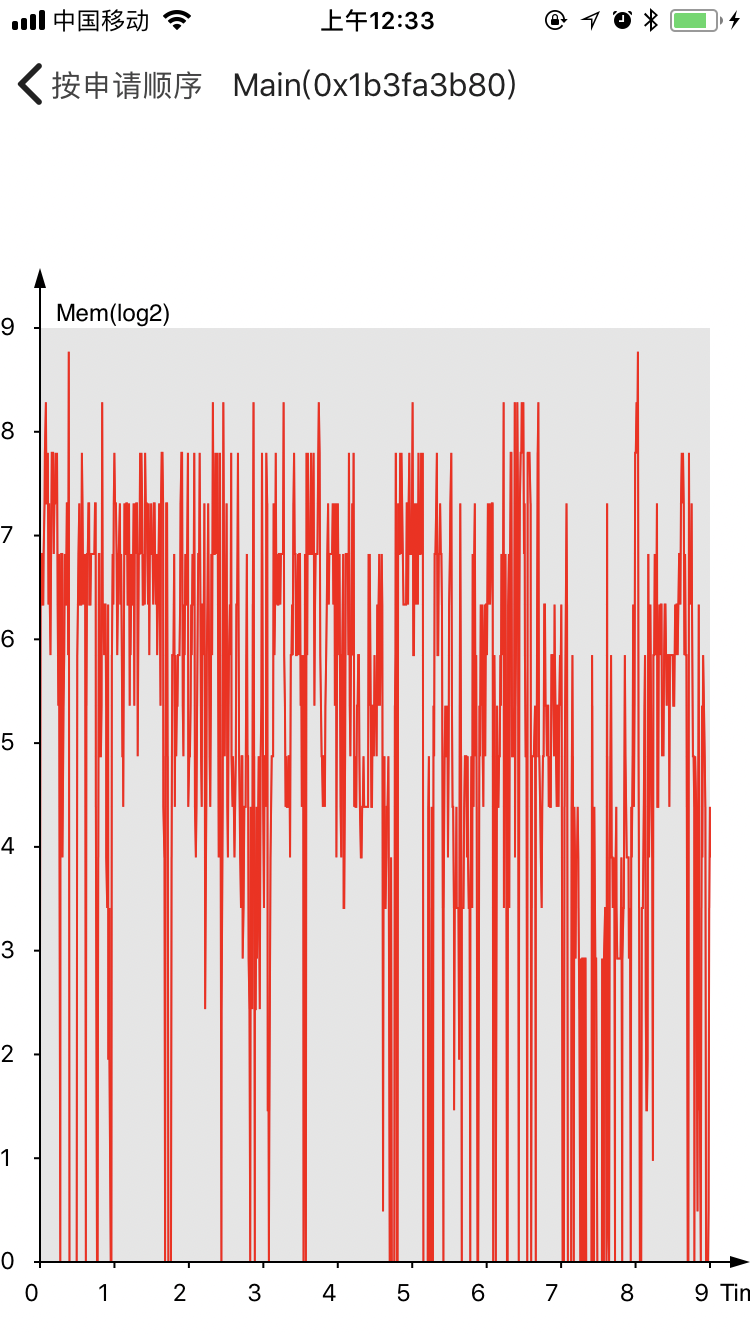
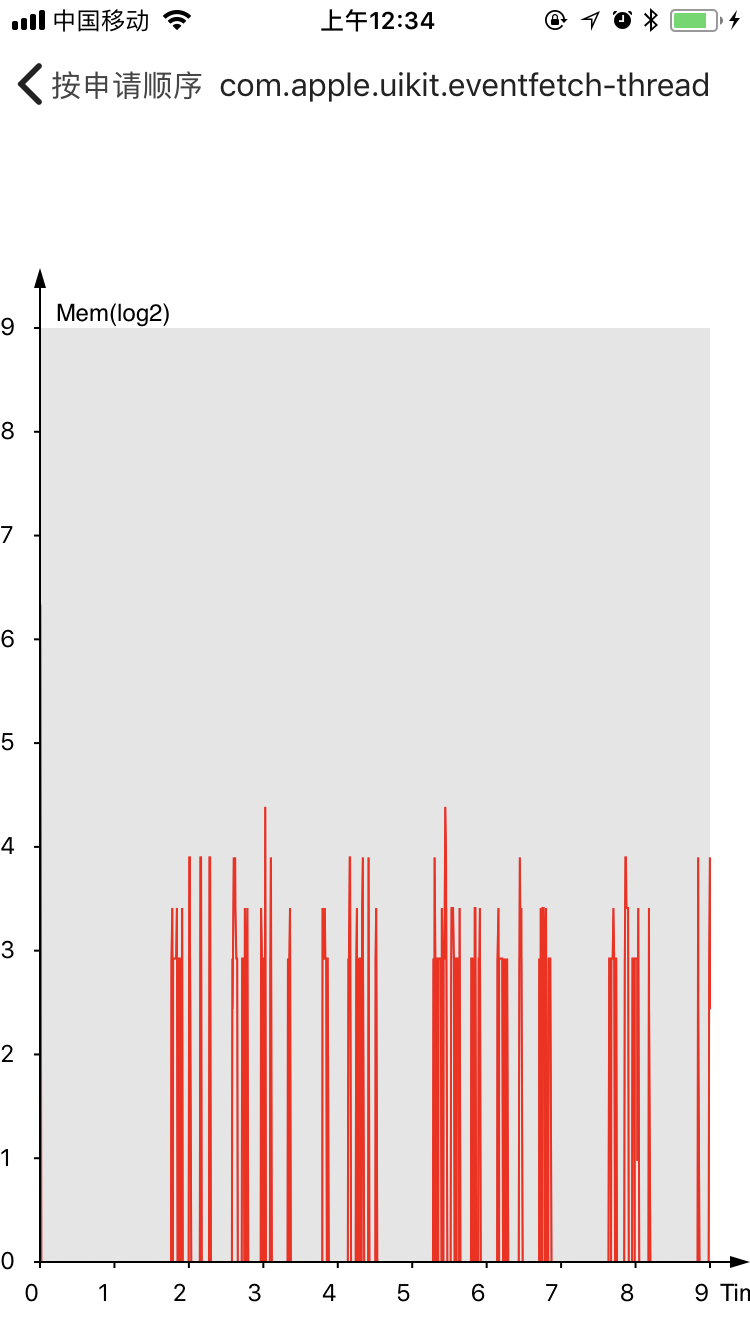
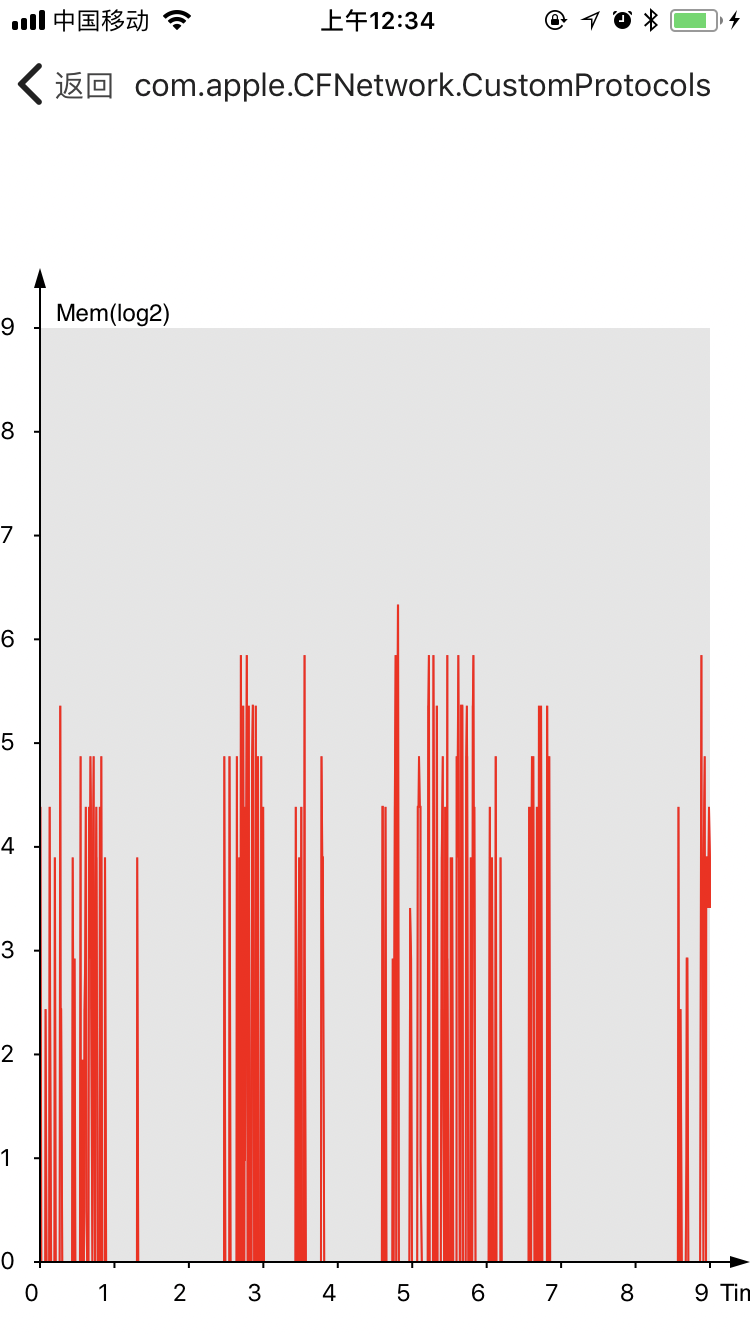
可以看到主线程都比较平稳,而ui线程则是和用户行为相关,网络更是和网络请求密切相关。
下面是内存size-class的分布,这里粒度比较低(2^n),个数(/1000)
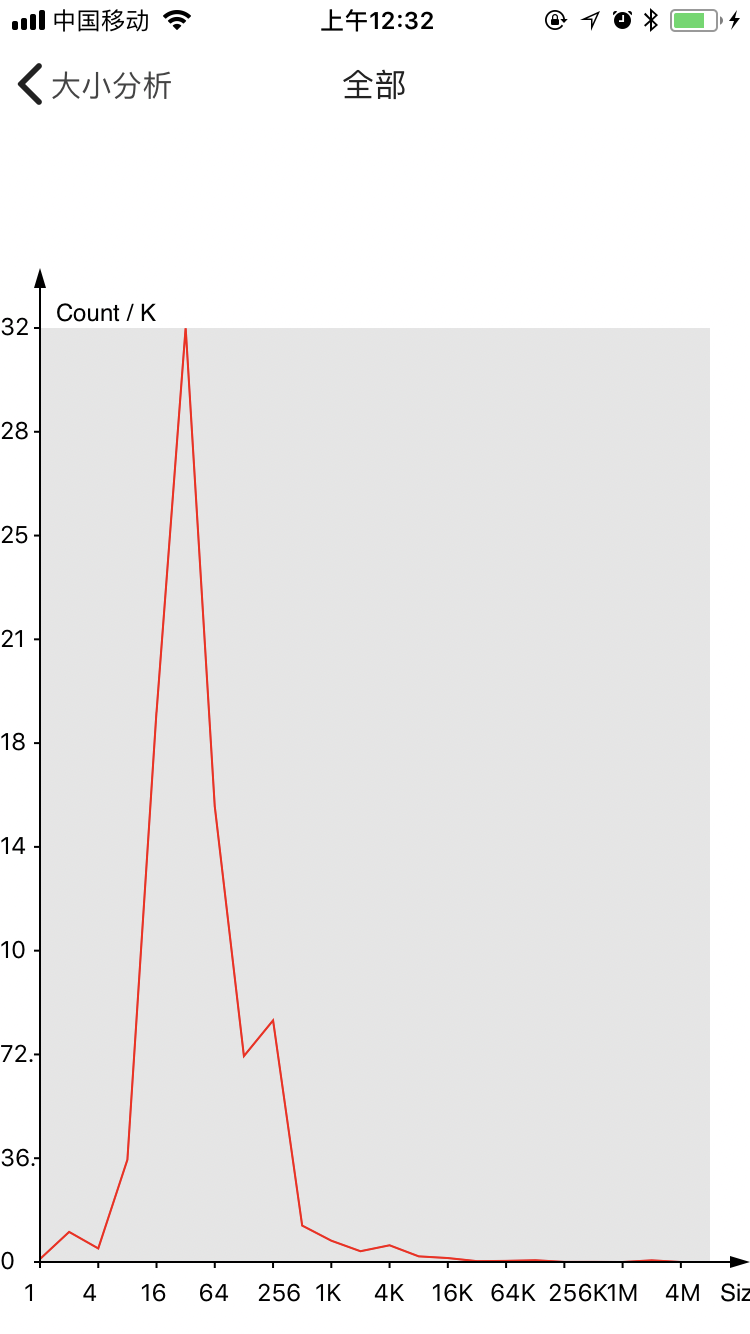
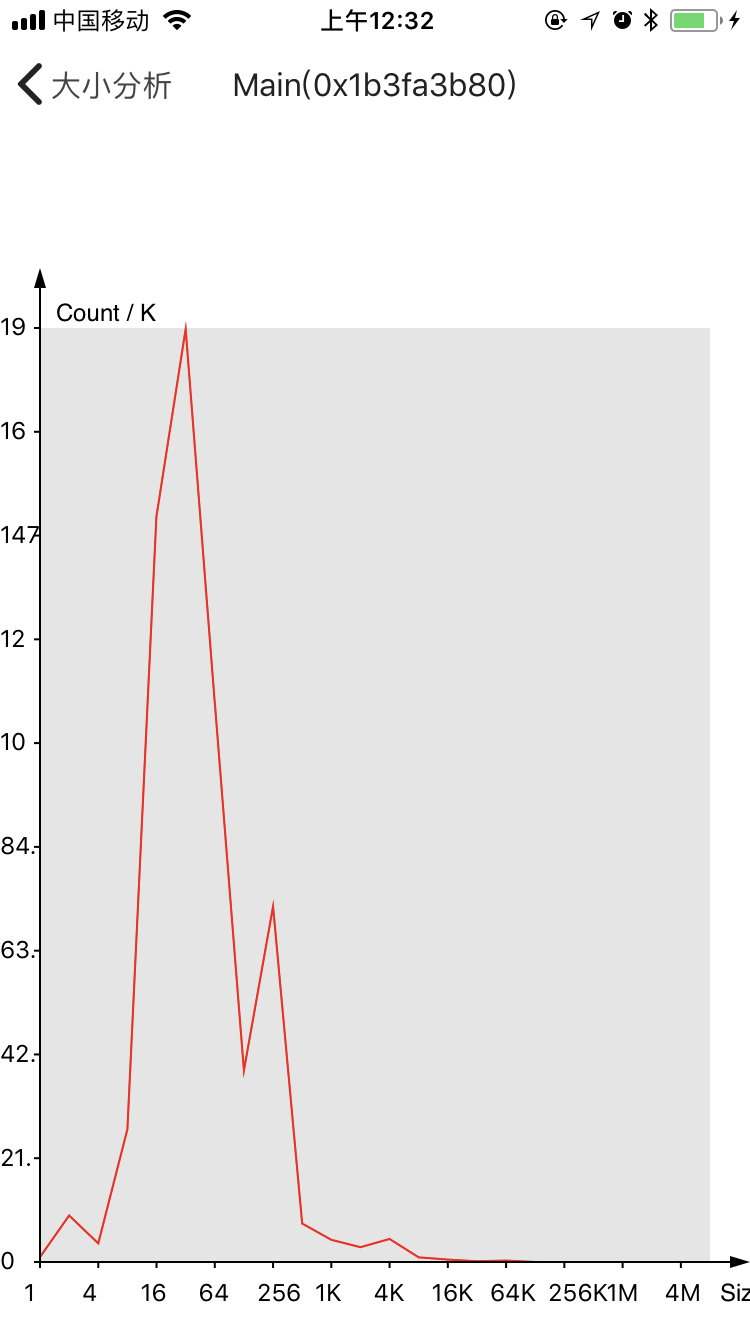
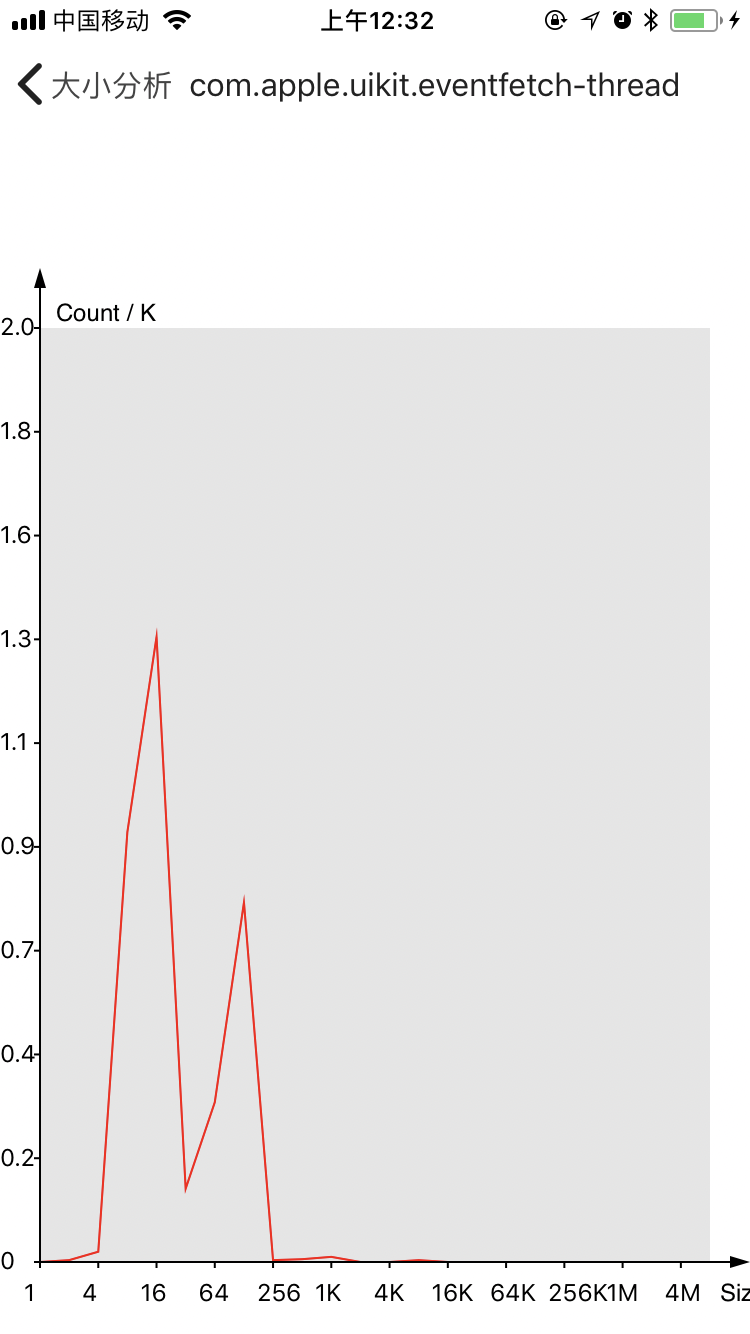
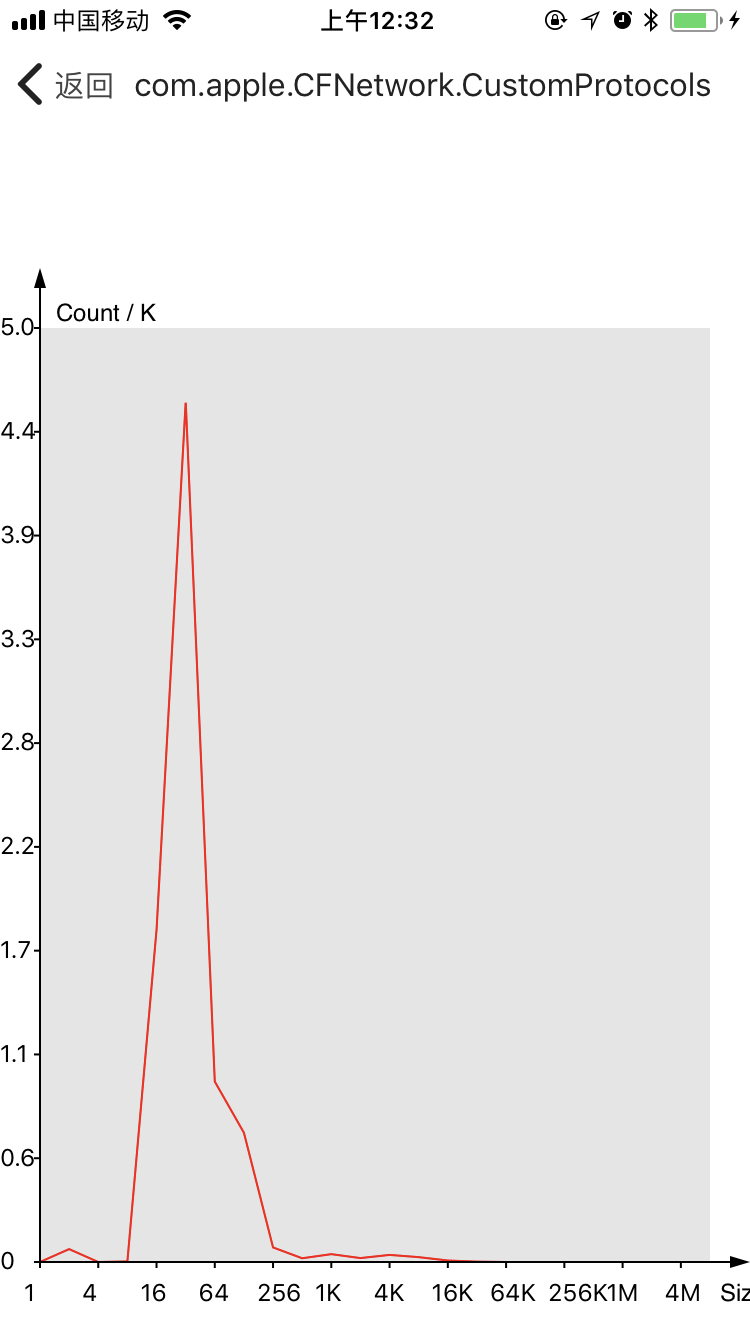
可以看出来,我们对于256 bytes以下的对象占有绝对的比例,其中32 - 64 bytes最多。每个线程的分布也不一致,说明特定的业务场景会拥有不同的内存需求。
下面是不同大小耗费时间的分布,时间的单位为time_t。
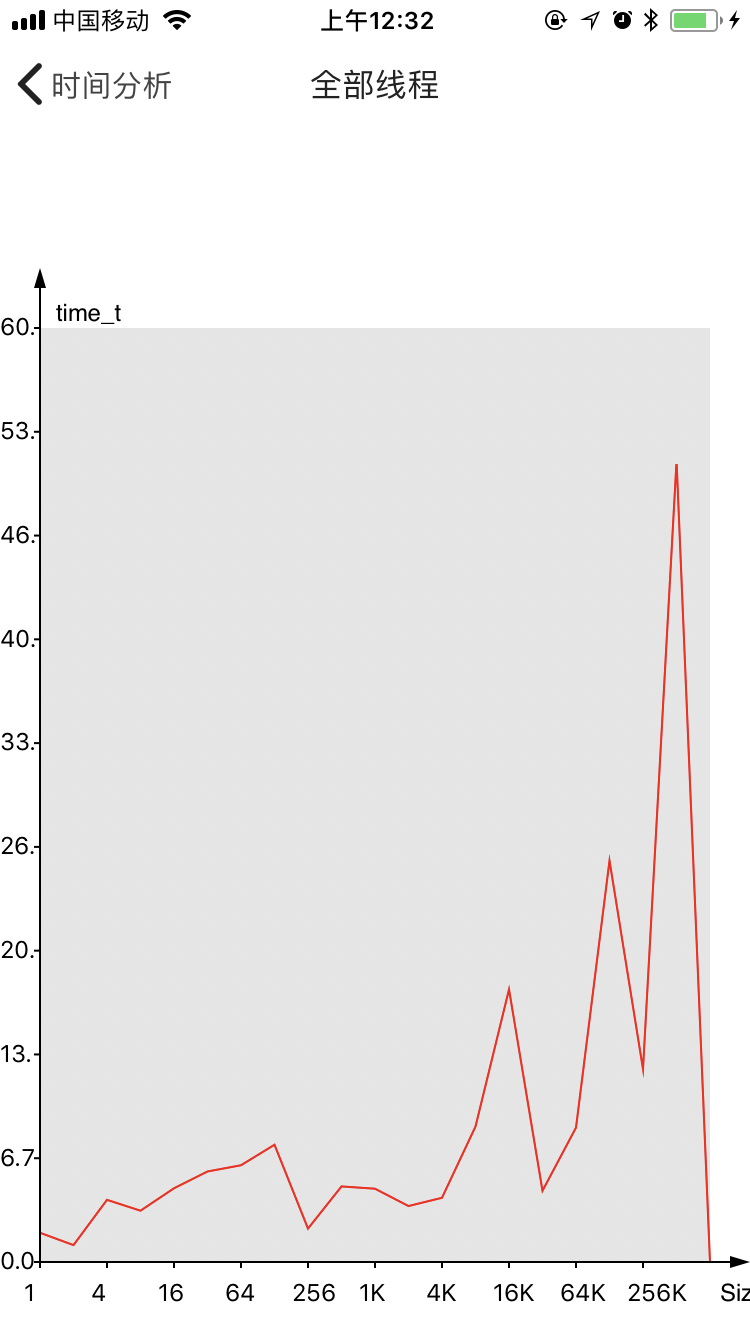
可以看出来256 bytes一下的时间消耗具有优势。
以上统计结果可能并不能代表所有,统计的样本也不够多,但也能代表部分真实状况。
替换default_zone
本来想替换为tcmalloc,但是它没有支持iOS系统,所以这里转而替换为jemalloc,由于时间有限,我也没有成功移植到arm上,所以这里看看模拟器的情况:
其中左边为苹果默认的分配器,右边为jemalloc。
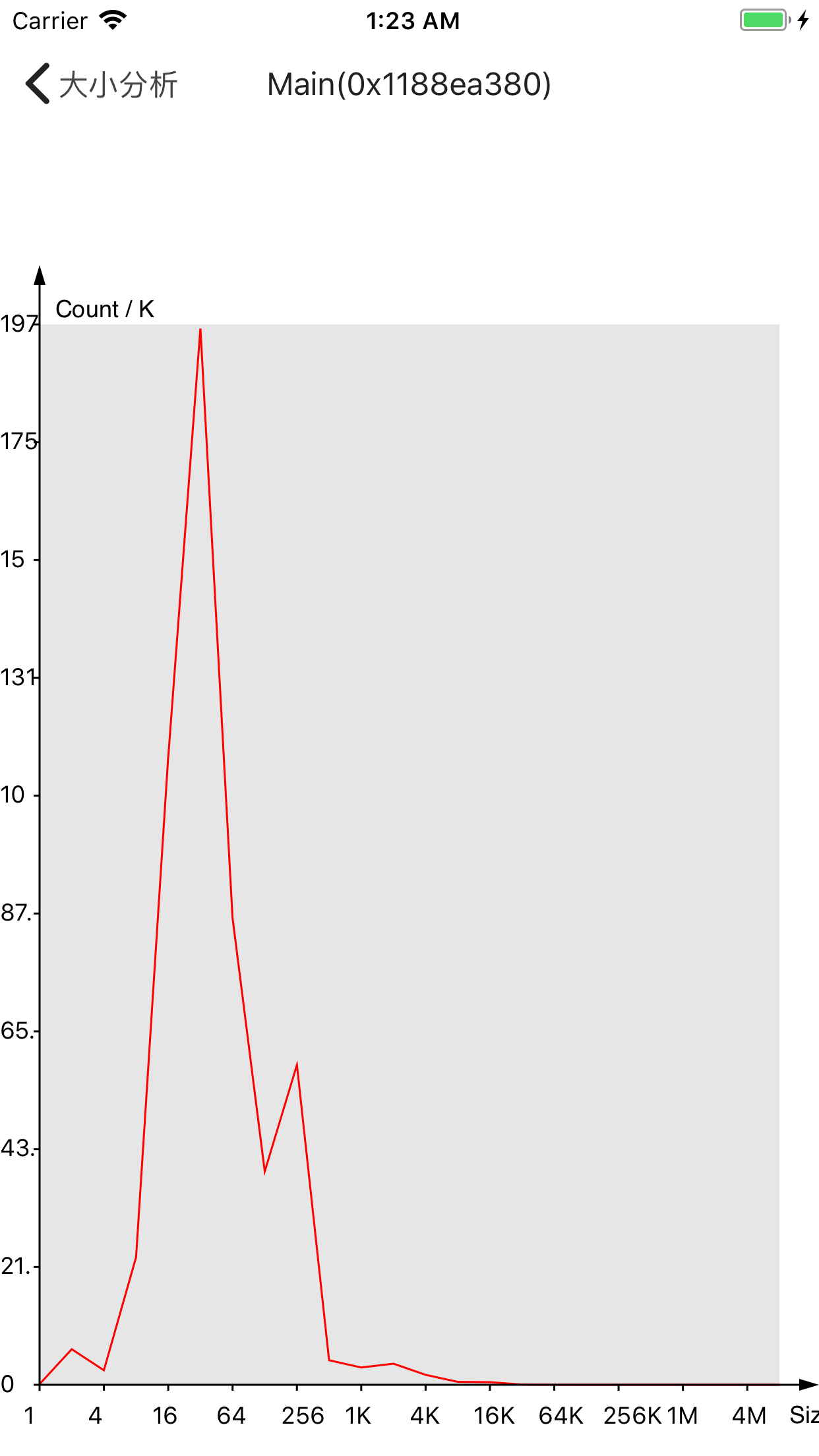
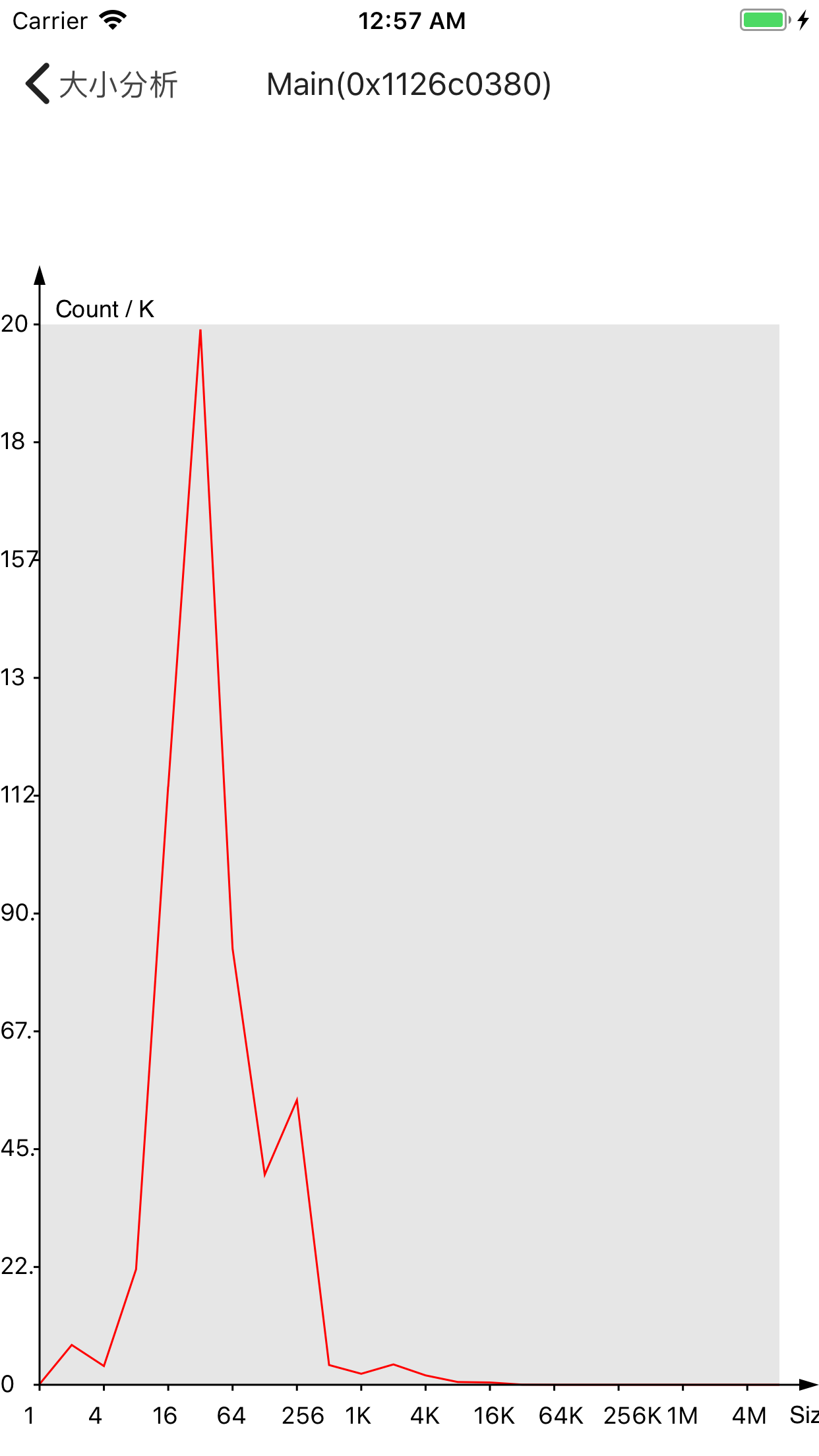
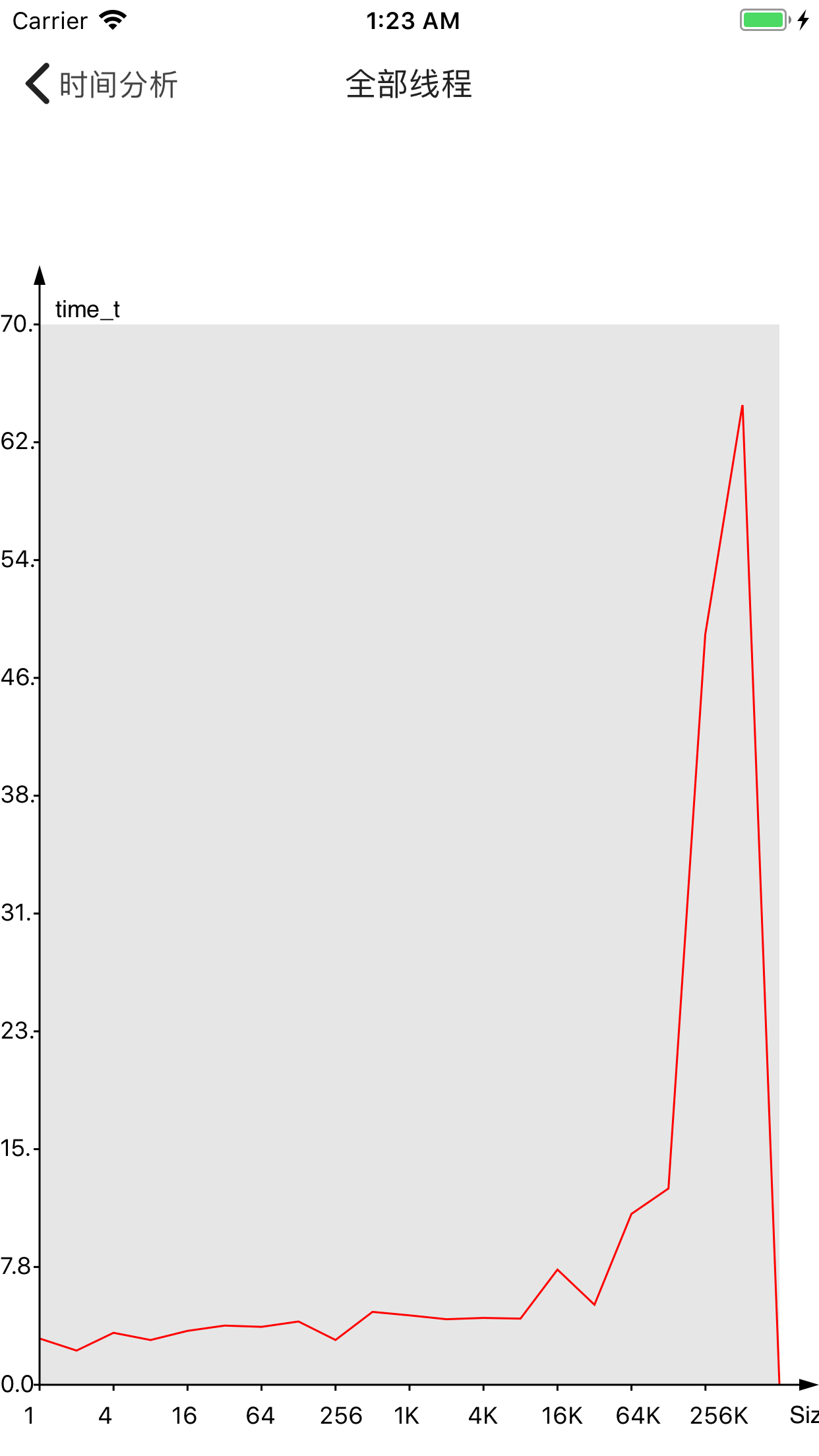
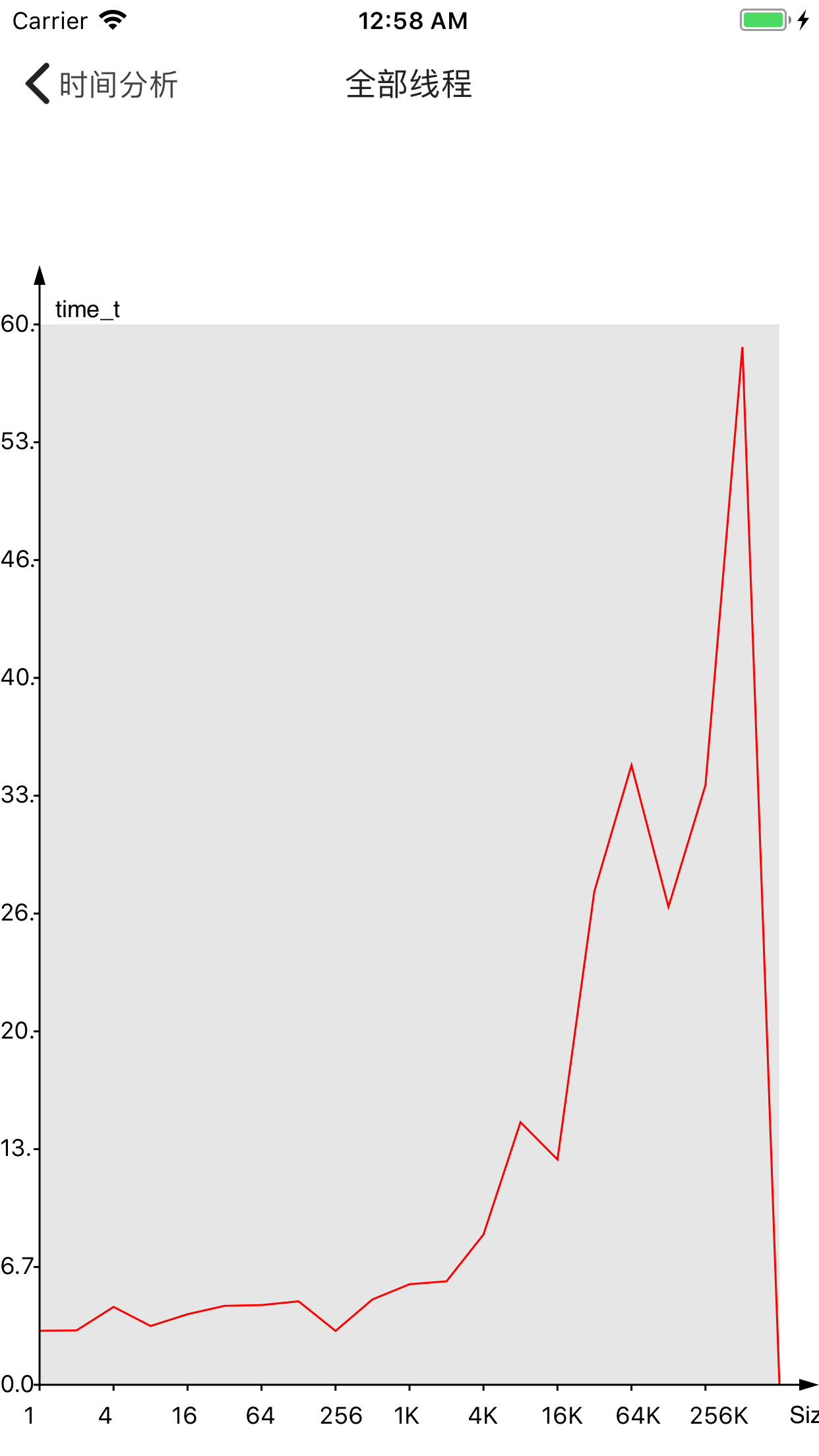
在内存分布相近的情况,jemalloc看似略微好于苹果默认分配器,但这种差距似乎很小,可能在误差之内。
最后
在移动应用中,内存的管理似乎并没有起到非常重要的地位,也不可能出现服务器那样的长时间运行,所以目前没有人做过这方面的优化处理。但是从这些点可以了解内存分配的一些情况,给我们一些不同的视角,具体情况下可以做一些特殊的优化。

