
实验五
实验结论
实验任务1

实验任务2

由于段的最小分配空间为 16 个字节,所以凡是不满 16 个字节的都按 16 个字节来算。
实验任务3

实验任务4

原因:将 start 去掉之后 CPU 会认为从头开始所有的指令都算做代码,也就是说数据段也会被认为是代码段中的内容,因此会产生错误,而第三题的代码段恰好是在文件的开始,所以可以正确执行。
实验任务5
程序如下,编写 code 段中的代码,将 a 段和 b 段中的数据依次相加,将结果存到 c 段中。
assume cs:code
a segment
db 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8
a ends
b segment
db 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8
b ends
c segment
db 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0
c ends
code segment
start:
?
code ends
end start
(1)汇编程序源代码
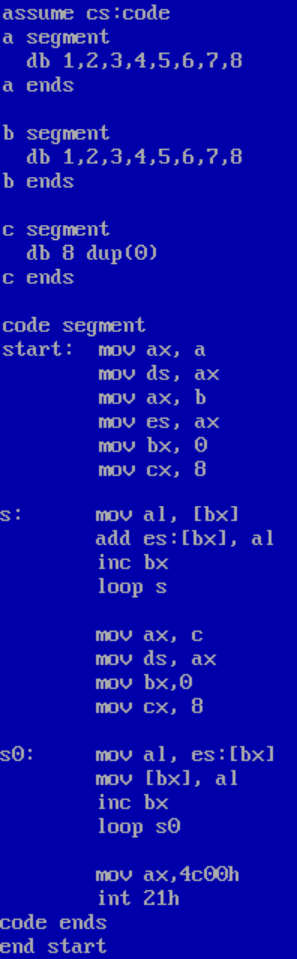
(2)在debug中调试程序截图
① 在实现数据相加前,逻辑段c的8个字节
![]()
② 执行完实现加运算的代码后,逻辑段c的8个字节
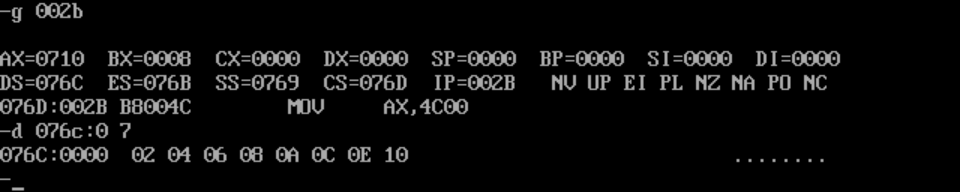
(3)根据①和②的调试,显然正确地实现了数据相加。
实验任务6
程序如下,编写 code 段中的代码,用 push 指令将 a 段中的前 8 个字型数据,逆序存储到 b 段中。
assume cs:code
a segment
dw 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 0ah , 0bh , 0ch , 0dh , 0eh , 0fh , 0ffh
a ends
b segment
dw 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0
b ends
code segment
start:
?
code ends
end start
(1) 汇编程序源代码
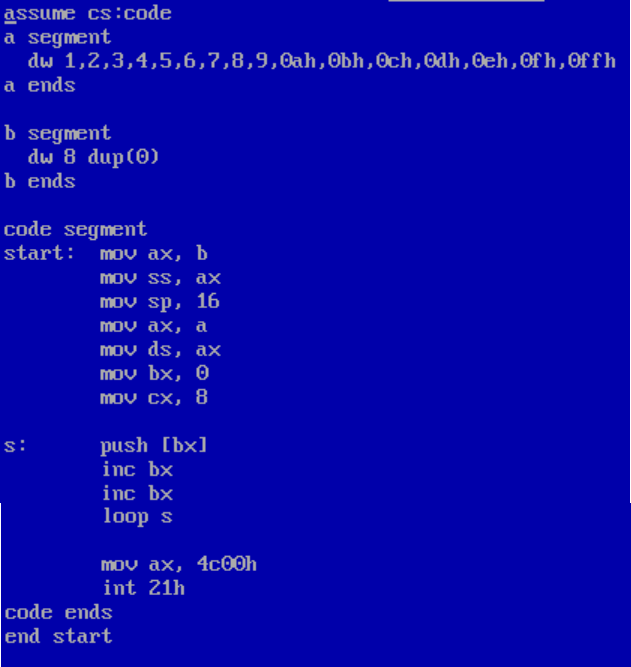
(2) 在debug中调试程序截图
① 在push操作执行前,查看逻辑段b的8个字单元信息截图
![]()
② 执行 push操作,然后再次查看逻辑段b的8个子单元信息截图
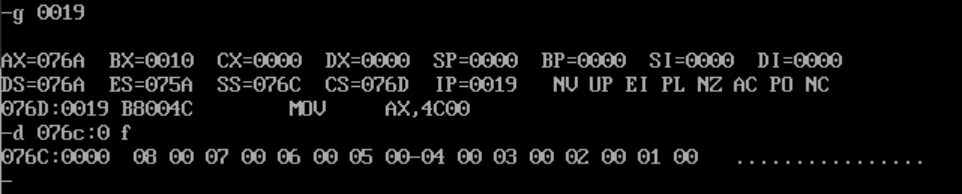
(3) 根据①和②的调试,显然前 8 个字单元已实现逆序存放。
总结与体会
(1)在实验任务 5 中,一开始我不知道怎么查看逻辑段 c 中的内容,但是后来发现这个查看的实现与实验任务 1~3 有关,在实验任务 1~3 中,可以看到由于各个段是顺序定义的,也就是说在内存中的地址空间是连续存放的,所以可以根据代码段的段地址来推断出前几个段的段地址,也就可以实现查看逻辑段 c 中内容这个功能了。
(2)在实验任务 3 中我存在一个疑问,为什么 data 段的段地址与 code 段的段地址相差是 3 而不是 1,这之间到底是如何计算的?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号