
入门篇
学习地址 http://www.cnblogs.com/chuxiuhong/p/5885073.html
. 字符在正则表达式中可以代表任何一个字符(包括它本身),所以呢 要用转义字符,让.字符就是.字符而不会代表其它任何东西
转义符是很有用的 \

findall返回的是所有符合要求的元素列表,就算只有一个元素,仍然会返回一个列表

re.search 目前作用并不是很明白,只知道可以查找到指定的内容

+ 的作用是将前面一个字符或一个子表达式重复一遍或者多遍
ab+ 能匹配到 abbbbbbb 但是不能匹配到 a 这种写法是必须要带个b的
*字符跟在其他符号后面表达可以匹配到它0次或者多次
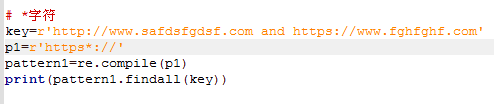
[]字符代表匹配里面的字符中的任意一个(范围性的匹配)

[^]字符则是范围性的排除

|
正则表达式 |
代表的匹配字符 |
|
[0-9] |
0123456789任意之一 |
|
[a-z] |
小写字母任意之一 |
|
[A-Z] |
大写字母任意之一 |
|
\d |
等同于[0-9] |
|
\D |
等同于[^0-9]匹配非数字 |
|
\w |
等同于[a-z0-9A-Z_]匹配大小写字母、数字和下划线 |
|
\W |
等同于[^a-z0-9A-Z_]等同于上一条取非 |
?字符的作用
有时一段内容中有多个相同的标识,但是只想提取第一个


{}字符的作用
{a,b} 代表a<=匹配次数<=b,也就是匹配次数大于等于a次小于等于b次(还是只小于而不等于b此呢???)

结果为 [‘sas’,’saas’]
|
中级篇
学习地址 http://www.cnblogs.com/chuxiuhong/p/5885073.html
子表达式
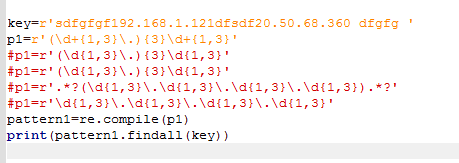
无非就是用小括号括住,然后把这个小括号当做一个元素,想要多少个这个元素就{n}
向前向后查找
表达式 (?<=<h1>).+?(?=<h1>) 中
(?<=<h1>)的 ?<= 表示在被匹配字符前必须得有<h1>
(?=<h1>)的 ?= 表示被匹配字符后必须有<h1>
简单说,就是要匹配的字符是xx,但必须满足形式是AXXB这样的字符串,简易示例如下:
P=r’(?<=A)XX(?=B)’
这样匹配到的字符串就是XX,其中的XX可以是任何内容,可以是单个的字符(如字符串形式的3也可以是a),也可以是一个字符串(如hello)
并且向前查找向后查找不需要必须同时出现,可以只写满足一个条件
不必要非记清楚哪个是向前查找,哪个是向后查找,只要记住 ?<= 后面跟着的是前缀要求 ?= 后面跟着的是后缀要求
其实向前查找和向后查找也是匹配整个字符串,即AXXB,但返回时仅仅返回一个xx,也就是说,如果愿意的话,完全可以不用这种方式,直接匹配带有前后缀的字符串,然后做字符切片处理即可
回溯引用
如果想要匹配<h1></h1>之间的内容,但是这个HTML有多级标题,想把每级的内容都提取出来
首先想到的方式可能是
<h[1-6]>.*?</h[1-6]>
但是这样的话,如果这个HTML中的标题全都正确,那还好说,如果出现一个错误的,例如<h1><h3>,那也能获取到,但是这个标题本身是不正常的,所以要用比较精准的方法来获取
<h[1-6]>.*?<h\1>
其中的h\1的意思是,如果h[1-6]匹配到的是h1那么h\1就是h1,如果h[1-6]匹配到的是h2那么h\1就是h2
表达式查询
学习地址https://www.cnblogs.com/jason-lv/p/8251904.html
|
|
表达式 |
说明 |
|
字 符 匹 配
|
[0-9] |
匹配0-9之间的任意1个数字。 |
|
[a-z] |
表示某个范围内的字符。与指定区间内的任何字符匹配。例如,"[a-z]"匹配"a"与"z"之间的 |
|
|
[A-Z] |
表示某个范围内的字符。与指定区间内的任何字符匹配。例如,"[A-Z]"匹配"A"与"Z" |
|
|
元 字 符 匹 配
|
. |
匹配换行符以外的任何字符 |
|
\w(小写的w) |
与任何单词字符匹配,包括下划线。等价于"[A-Za-z0-9_]"。 |
|
|
\s(小写s) |
与任何白字符匹配,包括空格、制表符、分页符等。等价于"[\f\n\r\t\v]"。 |
|
|
\d |
与一个数字字符匹配。等价于[0-9]。 |
|
|
\n |
与换行符字符匹配。 |
|
|
\t |
与制表符匹配。 |
|
|
\b |
与单词的边界匹配,即单词与空格之间的位置。例如,"er\b"与"never"中的"er"匹配 |
|
|
^ |
匹配输入的开始位置。 |
|
|
$ |
匹配输入的结尾。 |
|
|
\W(大写的W) |
与任何非单词字符匹配。等价于"[^A-Za-z0-9_]"。 |
|
|
\D |
与非数字的字符匹配。等价于[^0-9]。 |
|
|
\S |
与任何非空白的字符匹配。等价于"[^\f\n\r\t\v]"。 |
|
|
x|y |
匹配x或y。例如"z|food"可匹配"z"或"food"。"(z|f)ood"匹配"zood"或"food"。 |
|
|
() |
群组,与模式匹配并记住匹配。匹配的子字符串可以从作为结果的Matches集合中使用Item[0]... [n]取得。如果要匹配括号字符(和),可使用"\("或"\)"。 |
|
|
[xyz] |
一个字符集。与括号中字符的其中之一匹配。例如,"[abc]"匹配"plain"中的"a" |
|
|
[^xyz] |
一个否定的字符集。匹配不在此括号中的任何字符。例如,"[^abc]"可以匹配"plain |
|
|
量 词
|
* |
匹配前一个字符零次或几次。例如,"zo*"可以匹配"z"、"zoo"。 |
|
+ |
匹配前一个字符一次或多次。例如,"zo+"可以匹配"zoo",但不匹配"z"。 |
|
|
? |
匹配前一个字符零次或一次。例如,"a?ve?"可以匹配"never"中的"ve"。 |
|
|
{n} |
n为非负的整数。匹配恰好n次。例如,"o{2}"不能与"Bob中的"o"匹配,但是可以与"foooood"中的前两个 |
|
|
{n,} |
n为非负的整数。匹配至少n次。例如,"o{2,}"不匹配"Bob"中的"o",但是匹配"foooood"中所有的o。"o{1,}"等价于"o+"。"o{0,}"等价于"o*"。 |
|
|
{n,m} |
m和n为非负的整数。匹配至少n次,至多m次。例如,"o{1,3}"匹配"fooooood"中前三个o。"o{0,1}"等价于"o?"。 |
表达式的应用区别
|
正则 |
待匹配字符 |
匹配 |
说明 |
|
李.? |
李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符
|
|
李.* |
李杰和李莲英和李二棍子 |
李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
|
李.+ |
李杰和李莲英和李二棍子 |
李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
|
李.{1,2} |
李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符 |
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,在一个量词后面加?号使其变成惰性匹配
|
正则 |
待匹配字符 |
匹配 |
说明 |
|
李.*? |
李杰和李莲英和李二棍子 |
李 |
惰性匹配 |
字符集[][^]
|
正则 |
待匹配字符 |
匹配 |
说明 |
|
李[杰莲英二棍子]* |
李杰和李莲英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次
|
|
李[^和]* |
李杰和李莲英和李二棍子 |
李杰 |
表示匹配一个不是"和"的字符任意次 |
|
[\d] |
456bdha3 |
4 |
表示匹配任意一个数字,匹配到4个结果 |
|
[\d]+ |
456bdha3 |
456 |
表示匹配任意个数字,匹配到2个结果 |
转义符
|
正则 |
待匹配字符 |
匹配 |
说明 |
|
\d |
\d |
False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配 |
|
\\d |
\d |
True |
转义\之后变成\\,即可匹配 |
|
"\\\\d" |
'\\d' |
True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
|
r'\\d' |
r'\d' |
True |
在字符串之前加r,让整个字符串不转义 |
贪婪匹配
|
正则 |
待匹配字符 |
匹配 |
说明 |
|
<.*> |
<script>...<script> |
<script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串 |
|
<.*?> |
r'\d' |
<script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
几个常用的非贪婪匹配模式
*? 重复任意次,但尽可能少重复+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法 (注意,最前面有个点( . ))
. 是任意字符* 是取 0 至 无限长度 (注意,最前面有个点( . ))
? 是非贪婪模式。
合在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.*?x (注意,最前面有个点( . ))
就是取前面任意长度的字符,直到一个x出现
RE模块
Re函数方法总结
|
方法名称 |
格式 |
说明 |
|
findall |
re.findall(表达式,字符串) |
返回所有满足匹配条件的结果,放在列表里 |
|
search |
re.search(表达式,字符串).groups() |
函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 |
|
match |
re.match(表达式,字符串).groups() |
同search,不过尽在字符串开始处进行匹配 |
|
split |
re.split(表达式,字符串) |
按表达式对字符串分割,返回列表 |
|
sub |
re.sub(表达式,替换字符,字符串,count) |
按表达式类型替换成新的字符,返回字符串 |
|
subn |
re.subn(表达式,替换字符,字符串,count) |
按表达式类型替换成新的字符串,返回一个元组,存放这替换结果和替换次数 |
|
compile |
re.compile(表达式) |
将正则表达式编译成为一个 正则表达式对象 |
|
finditer |
re.finditer(表达式,字符串) |
finditer返回一个存放匹配结果的迭代器 |
re常用方法实例
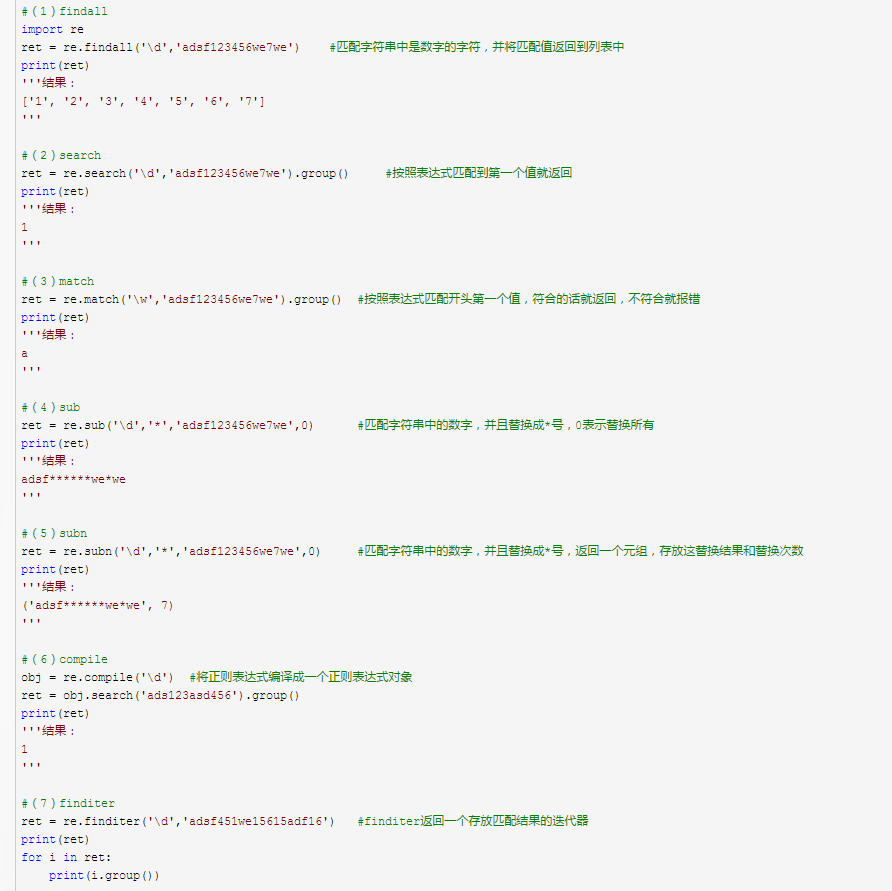
python中正则常用的匹配模式
\w 匹配字母数字及下划线
\W 匹配f非字母数字下划线
\s 匹配任意空白字符,等价于[\t\n\r\f]
\S 匹配任意非空字符
\d 匹配任意数字
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果存在换行,只匹配换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符^ 匹配字符串的开头
$ 匹配字符串的末尾
. 匹配任意字符,除了换行符,re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符
[....] 用来表示一组字符,单独列出:[amk]匹配a,m或k
[^...] 不在[]中的字符:[^abc]匹配除了a,b,c之外的字符* 匹配0个或多个的表达式+ 匹配1个或者多个的表达式
? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n} 精确匹配n前面的表示
{m,m} 匹配n到m次由前面的正则表达式定义片段,贪婪模式
a|b 匹配a或者b
() 匹配括号内的表达式,也表示一个组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号