
1.原理
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
2、api

3、性能评估
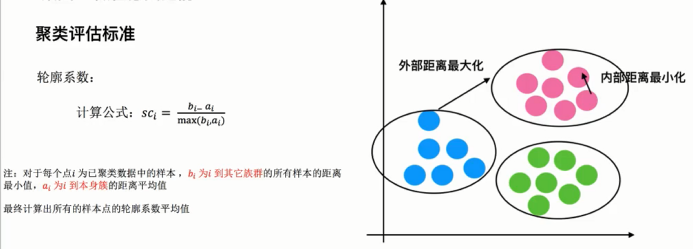

越接近1越好,一般不超过0.7
4、优缺点
优点
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
缺点
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 最终结果和初始点的选择有关,容易陷入局部最优。
5) 对噪音和异常点比较的敏感。
5、总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号