
一、机器学习算法分类

二、开发流程
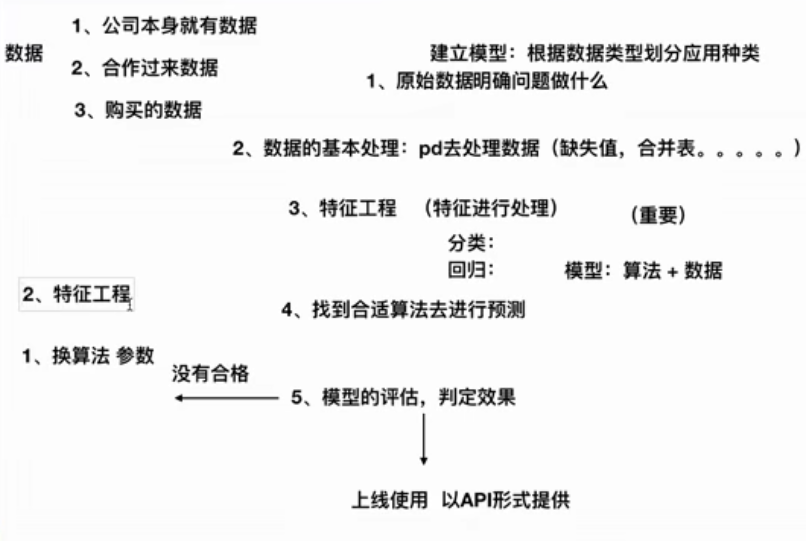
三、scikit-learn操作数据
1、数据集


2、数据分割

代码:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split li = load_iris() # test_size=0.25:将数据集分为75%和25%,25%为测试集 x_train, x_test, y_train, y_test = train_test_split(li.data,li.target,test_size=0.25) print("训练集的特征值和目标值",x_train,y_train) print("测试集的特征值和目标值",x_test,y_test)
3、估计器


四、模型评估指标
准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
准确率是相对所有分类结果;精确率、召回率、F1-score是相对于某一个分类的预测评估标准。
详细介绍见:https://blog.csdn.net/u012879957/article/details/80564148 、
https://blog.csdn.net/houyanhua1/article/details/87968953?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
api:

代码:
#精准率和召回率 print("精准率和召回率:",classification_report(y_test,y_predict,target_names=news.target_names))
五、模型保存



 浙公网安备 33010602011771号
浙公网安备 33010602011771号