
【FATE实战】纵向联邦学习FATE框架下实战的过程解释(2)
在上一篇随笔中介绍了FATE框架学习初期的一些学习过程,这里我将介绍我用了一段时间这个框架之后的心得和更方便的用法。
在上一篇中,我们需要做些什么呢?
1、上传docker中/fate/examples/data的数据文件到experiment中。写的json文件是/fate/examples/dsl/v1/upload_data_guest.json:
{ "file": "/fate/examples/data/tag_value_1000_140.csv", "head": 1, "partition": 16, "work_mode": 0, "table_name": "tag_value_1000_140", "namespace": "experiment" }
其中只要改"file"后面的.csv之前的文件名并且使"table_name"后面的名称与之一致,就可以了,然而我们之前用的上传代码是:
python ${your_install_path}/fate_flow/fate_flow_client.py -f upload -c ${upload_data_json_path}
在我的容器里面代码大概是:
python /fate/python/fate_flow/fate_flow_client.py -f upload -c /fate/examples/dsl/v1/upload_data_guest.json
但是代码也太丑了。。。而且根本记不住这么长的代码啊。。。于是我们可以这么搞:
首先,data的数据文件都在/fate/examples/data中,那么为什么不把upload_data_guest.json也放到其中,那么我们操作的时候只用在/fate/examples/data文件下执行上传操作就可以了。
cp /fate/examples/dsl/v1/upload_data_guest.json /fate/examples/data/upload_data.json
我们就把upload_data_guest.json复制到/fate/examples/data并命名为upload_data.json了
其次,python命令行命令太丑了而且容易出错,那么我们可以改进一下上传命令。
cd /fate/examples/data
flow data upload -c upload_data.json

上传成功。
如果想要查看我们上传的数据文件在experiment的情况,可以使用命令:
flow table info -n experiment -t UCI_Credit_Card_hetero_guest
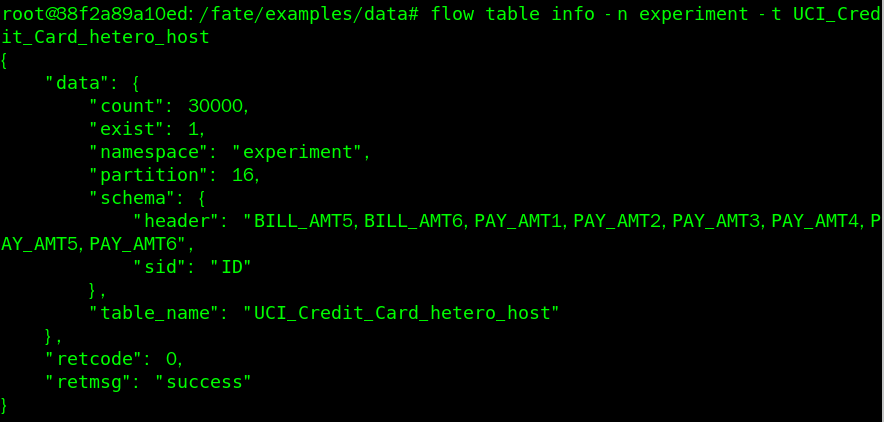
如果上传错误可以删除:
flow table delete -n experiment -t UCI_Credit_Card_hetero_guest
重新上传。
一般情况下我们的数据文件要在我们的windows进行一些处理,再把数据文件复制到VMware虚拟机上。
或者允许VMware虚拟机共享文件,然后把共享文件挂载在虚拟机上,可以使得挂载文件夹与主机内容同步,还是很方便的。
2、一般我们需要上传dsl和conf文件,可是我在后来用pipeline上传的时候发现其实后面用不着自行制作dsl和conf文件,大家可以通过执行/fate/examples/pipeline里面文件夹里面的pipeline文件来看看怎么运行的,截取其中一段代码看一下:
def main(config="../../config.yaml", namespace=""): # obtain config if isinstance(config, str): config = load_job_config(config) parties = config.parties guest = parties.guest[0] host = parties.host[0] arbiter = parties.arbiter[0] backend = config.backend work_mode = config.work_mode guest_train_data = {"name": "breast_hetero_guest", "namespace": f"experiment{namespace}"} host_train_data = {"name": "breast_hetero_host", "namespace": f"experiment{namespace}"} pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter) reader_0 = Reader(name="reader_0") reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_train_data) reader_0.get_party_instance(role='host', party_id=host).component_param(table=host_train_data) dataio_0 = DataIO(name="dataio_0") dataio_0.get_party_instance(role='guest', party_id=guest).component_param(with_label=True, missing_fill=True, outlier_replace=True) dataio_0.get_party_instance(role='host', party_id=host).component_param(with_label=False, missing_fill=True, outlier_replace=True) intersection_0 = Intersection(name="intersection_0") federated_sample_0 = FederatedSample(name="federated_sample_0", mode="stratified", method="upsample", fractions=[[0, 1.5], [1, 2.0]]) feature_scale_0 = FeatureScale(name="feature_scale_0") hetero_feature_binning_0 = HeteroFeatureBinning(name="hetero_feature_binning_0") one_hot_0 = OneHotEncoder(name="one_hot_0") hetero_lr_0 = HeteroLR(name="hetero_lr_0", penalty="L2", optimizer="rmsprop", tol=1e-5, init_param={"init_method": "random_uniform"}, alpha=0.01, max_iter=10, early_stop="diff", batch_size=320, learning_rate=0.15) hetero_lr_1 = HeteroLR(name="hetero_lr_1", penalty="L2", optimizer="rmsprop", tol=1e-5, init_param={"init_method": "random_uniform"}, alpha=0.01, max_iter=10, early_stop="diff", batch_size=320, learning_rate=0.15, cv_param={"n_splits": 5, "shuffle": True, "random_seed": 103, "need_cv": True}) hetero_secureboost_0 = HeteroSecureBoost(name="hetero_secureboost_0", num_trees=5, cv_param={"shuffle": False, "need_cv": True}) hetero_secureboost_1 = HeteroSecureBoost(name="hetero_secureboost_1", num_trees=5) evaluation_0 = Evaluation(name="evaluation_0") evaluation_1 = Evaluation(name="evaluation_1") pipeline.add_component(reader_0) pipeline.add_component(dataio_0, data=Data(data=reader_0.output.data)) pipeline.add_component(intersection_0, data=Data(data=dataio_0.output.data)) pipeline.add_component(federated_sample_0, data=Data(data=intersection_0.output.data)) pipeline.add_component(feature_scale_0, data=Data(data=federated_sample_0.output.data)) pipeline.add_component(hetero_feature_binning_0, data=Data(data=feature_scale_0.output.data)) pipeline.add_component(one_hot_0, data=Data(data=hetero_feature_binning_0.output.data)) pipeline.add_component(hetero_lr_0, data=Data(train_data=one_hot_0.output.data)) pipeline.add_component(hetero_lr_1, data=Data(train_data=one_hot_0.output.data)) pipeline.add_component(hetero_secureboost_0, data=Data(train_data=one_hot_0.output.data)) pipeline.add_component(hetero_secureboost_1, data=Data(train_data=one_hot_0.output.data)) pipeline.add_component(evaluation_0, data=Data(data=hetero_lr_0.output.data)) pipeline.add_component(evaluation_1, data=Data(data=hetero_secureboost_1.output.data)) pipeline.compile() job_parameters = JobParameters(backend=backend, work_mode=work_mode) pipeline.fit(job_parameters) print(pipeline.get_component("evaluation_0").get_summary())
其实dsl就简化为了

conf简化成了
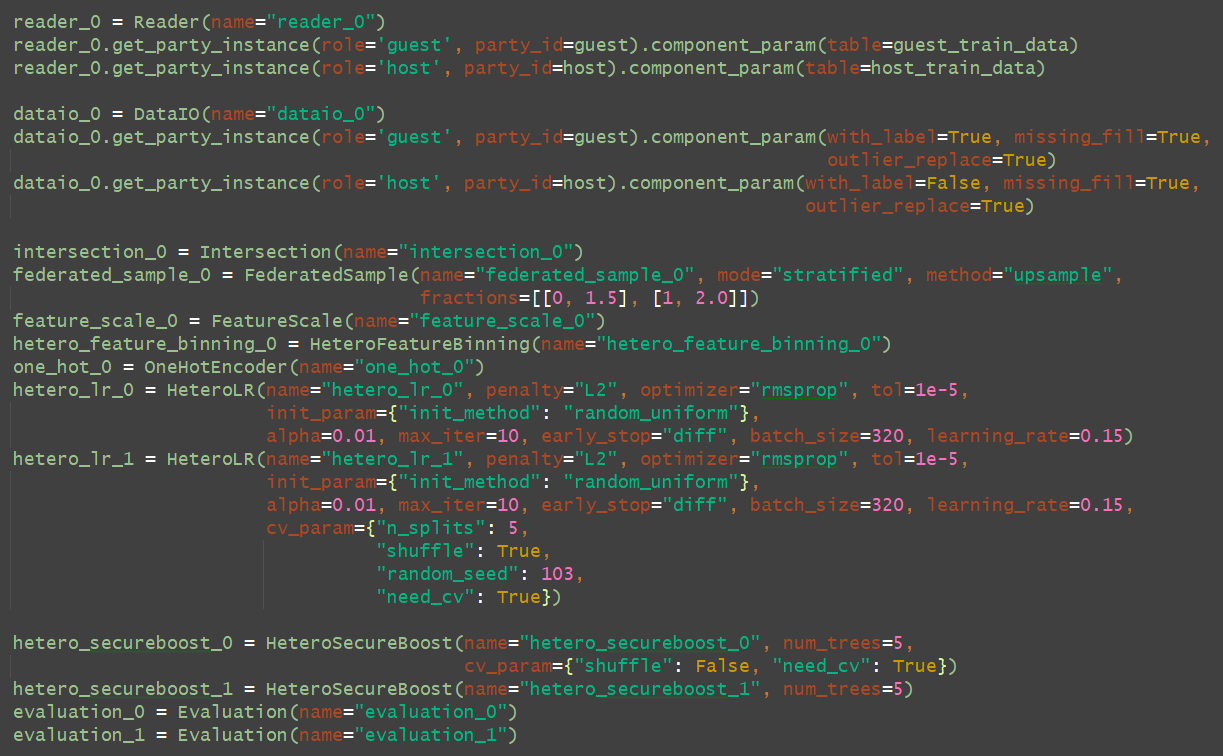
只需要执行python文件就可以了。
python /fate/examples/pipeline/multi_model/pipeline-multi-model.py
再在浏览器输入:localhost:8080/查看运行情况。
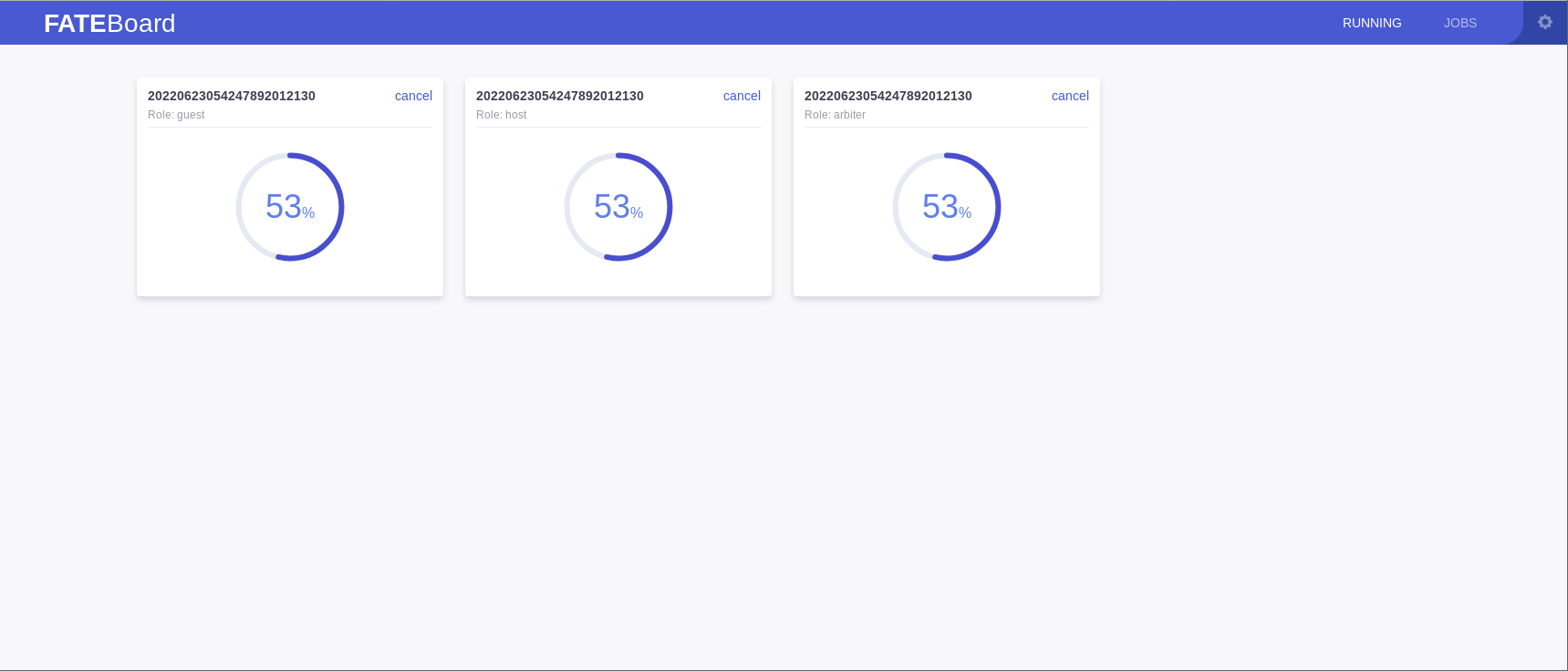

 浙公网安备 33010602011771号
浙公网安备 33010602011771号