
【FATE实战】纵向联邦学习FATE框架下实战的过程解释(1)
在使用FATE进行联邦学习研究的时候,网上的教程通常只是说教我们怎么上传FATE框架自带的数据去测试整个框架在本机上有没有问题。
下面一个过程就是我们怎么去理解我们在使用FATE进行联邦学习的时候使用到的几个配置文件的作用。
首先我是从【联邦学习】FATE框架:纵向联邦学习练习——波士顿房价找到FATE框架练习:实现横向逻辑回归任务的训练及预测和二、 FATE实战:实现横向逻辑回归任务的训练及预测
这三个链接可以帮助我们去学习FATE框架的实战。这里我用自己的理解上传自己想要上传的数据,使用自己想要的结构去建立模型。
#################################################################################################################################################################
首先,我们需要做的是上传文件。
上传文件需要确定的第一步是你已经进入了fate容器
如果fate没有启动过,就cd到docker_standalone_fate_1.6.0文件夹
执行install_standalone_docker.sh
cd docker_standalone_fate_1.6.0 bash install_standalone_docker.sh
install_standalone_docker.sh文件长这样

docker run -d就是守护方式打开容器,--name就是把容器命名为fate,-p就是将容器的端口暴露给宿主机端口 格式:host_port:container_port 或者 host_ip:host_port:container_port,后面的fate:latest就是镜像的名字。
docker ps -a就是把所有运行着的和运行过的(但是没有删除,还可以重新运行的)容器显示出来。结果如下:
如果启动成功就可以看到

我们也可以通过docker ps看我们正在运行的容器

当然,还有一种情况就是fate运行过,但是关闭了(docker stop),没有删除(docker rm)。就可能会报错
这个时候我们使用
docker restart fate
即可。
然后问题解决我们就可以进入fate容器内部:
docker exec -it fate /bin/bash

然后就可以愉快地进入我们的上传文件了~
上传文件需要的python脚本是
python ${your_install_path}/fate_flow/fate_flow_client.py -f upload -c ${upload_data_json_path}
用自己的路径就是
python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_host.json python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_guest.json # 下面这条upload_data_test.json 是上传测试数据,仅仅在作evaluation时需要上传,执行普通的train_job可以不用上传 python python/fate_flow/fate_flow_client.py -f upload -c examples/dsl/v1/homo_logistic_regression/upload_data_test.json
这里的-f和-c啊,和前面的docker -d,docker ps -a啥参数啊,完全不一样,不是一个出处的!我们如何去理解这列的参数呢?
这里的参数就和python/fate_flow/fate_flow_client.py里的fate_flow_client.py文件有关,文件里面关于参数的部分长这样:

-f是要传函数参数,我们传的upload函数在
DATA_FUNC + MODEL_FUNC + JOB_FUNC + JOB_OPERATE_FUNC + TASK_OPERATE_FUNC + TABLE_FUNC +
TRACKING_FUNC + PERMISSION_FUNC
里面。其中各个函数集合里面有:

upload是DATA_FUNC里面的函数,然后我们再去看DATA_FUNC:

其中没啥有用的,就是一个上传文件的代码,主要是可以让我们熟悉这个fate_flow_client.py的代码。
然后是fate_flow_client.py 的-c参数,上图可以知道-c是要上传config一个配置文件upload_data_host.json,这个文件长这样:
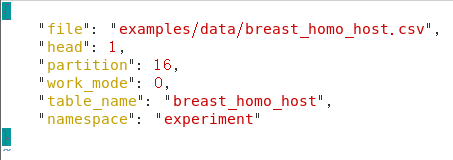
其中"file"就是我们要上传文件的绝对路径,一般都是在容器内部,其中容器内部的数据文件都有哪些呢?

一般自己上传数据文件的话,可以自己在容器自己创建一个文件夹,再用cp指令从虚拟机(我用的VMware centos7)传到容器里面。在修改conf.json文件里面的file绝对路径和
table_name的表格标签,再放到自己定义的一个namespace里面,一般测试用的放experiment里面,也可以自己想一个namespace名字放里面。这个主要是后面的训练conf.json文件需要。
upload_data_guest.json和test文件都差不多。可以自己用
vim /fate/examples/dsl/v1/homo_logistic_regression/upload_data_guest.json
vim /fate/examples/dsl/v1/homo_logistic_regression/upload_data_test.json
查看。如果容器没有下载vim可以docker容器中安装vim。
#################################################################################################################################################################
其次,我们需要在v1文件夹下选择示例dsl和conf进行训练:(也可以用v2文件夹的dsl和conf文件进行训练,我喜欢v2,具体看二、 FATE实战:实现横向逻辑回归任务的训练及预测第四部分)
命令为:
python python/fate_flow/fate_flow_client.py -f submit_job -d examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_dsl.json -c examples/dsl/v1/homo_logistic_regression/test_homolr_train_job_conf.json
啊,这个.py我们之前看过,这个-f 后面的函数是submit_job在里面也有,在.py文件里的内容为:

-c后面传的是conf.json和-d后面是dsl.json文件,其中test_homolr_train_job_conf.json长这样:
{
"initiator": {
"role": "guest",
"party_id": 10000
},
"job_parameters": {
"work_mode": 0
},
"role": {
"guest": [
10000
],
"host": [
10000
],
"arbiter": [
10000
]
},
"role_parameters": {
"guest": {
"args": {
"data": {
"train_data": [
{
"name": "breast_homo_guest",
"namespace": "experiment"
}
]
}
}
},
"host": {
"args": {
"data": {
"train_data": [
{
"name": "breast_homo_host",
"namespace": "experiment"
}
]
}
},
"evaluation_0": {
"need_run": [
false
]
}
}
},
"algorithm_parameters": {
"dataio_0": {
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"optimizer": "rmsprop",
"tol": 1e-05,
"alpha": 0.01,
"max_iter": 30,
"early_stop": "diff",
"batch_size": -1,
"learning_rate": 0.15,
"decay": 1,
"decay_sqrt": true,
"init_param": {
"init_method": "zeros"
},
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
}
}
}
}
conf.json文件需要确保name 和namespace与前面的upload文件的一致。
dsl文件test_homolr_train_job_dsl.json长这样:
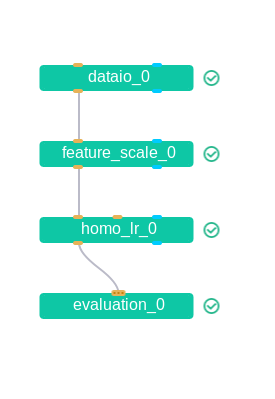
{ "components" : { "dataio_0": { "module": "DataIO", "input": { "data": { "data": [ "args.train_data" ] } }, "output": { "data": ["train"], "model": ["dataio"] } }, "feature_scale_0": { "module": "FeatureScale", "input": { "data": { "data": [ "dataio_0.train" ] } }, "output": { "data": ["train"], "model": ["feature_scale"] } }, "homo_lr_0": { "module": "HomoLR", "input": { "data": { "train_data": [ "feature_scale_0.train" ] } }, "output": { "data": ["train"], "model": ["homolr"] } }, "evaluation_0": { "module": "Evaluation", "input": { "data": { "data": [ "homo_lr_0.train" ] } } } } }
dsl是模型结构,结构是长这样:
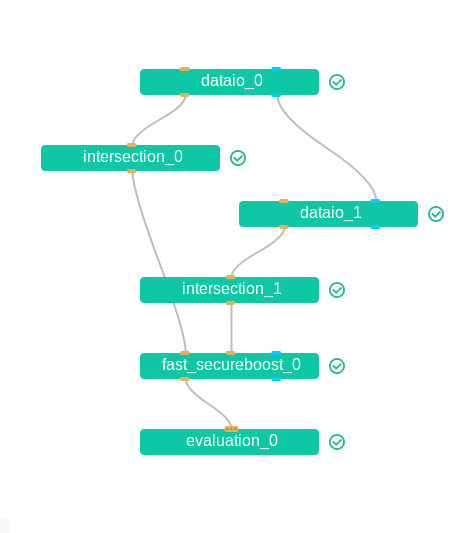
像是另一个fast_secureboost的dsl:
{ "components": { "dataio_0": { "module": "DataIO", "input": { "data": { "data": [ "args.train_data" ] } }, "output": { "data": ["train"], "model": ["dataio"] } }, "dataio_1": { "module": "DataIO", "input": { "data": { "data": [ "args.eval_data" ] }, "model": [ "dataio_0.dataio" ] }, "output": { "data": ["eval"], "model": ["dataio"] }, "need_deploy": false }, "intersection_0": { "module": "Intersection", "input": { "data": { "data": [ "dataio_0.train" ] } }, "output": { "data": ["train"] } }, "intersection_1": { "module": "Intersection", "input": { "data": { "data": [ "dataio_1.eval" ] } }, "output": { "data": ["eval"] }, "need_deploy": false }, "fast_secureboost_0": { "module": "HeteroFastSecureBoost", "input": { "data": { "train_data": [ "intersection_0.train" ], "eval_data": [ "intersection_1.eval" ] } }, "output": { "data": ["train"], "model": ["train"] } }, "evaluation_0": { "module": "Evaluation", "input": { "data": { "data": [ "fast_secureboost_0.train" ] } } } } }
结果长这样:
之后看进展再写吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号