lua5.3 协程实现(1)
介绍
复习下进程,线程,协程的概念。
- 进程:是操作系统分配资源的基本单位,代表了程序正在运行时的实例。操作系统为其分配独立的内存空间,包括堆栈,代码,数据等信息,进程之间相互独立,一般通过信号、共享内存、管道,网络等方式通讯,由操作系统负责调度执行。
- 线程:是进程内的执行单元。一个进程里可以有多个线程,线程之间共享进程里的资源,比如内存,文件句柄。线程之间可以直接通讯,线程之间有自己独立的栈空间,同样由操作系统调度,可以做到并发执行。
- 协程:是一种用户态的轻量级线程,协程之间的调度由用户自己控制。协程同样有自己的栈空间和局部变量,可以共享进程里的资源。一个线程里可以有多个协程,但和线程不同的是,它的调度和切换不由操作系统负责的,是由用户代码控制的。协程可以在用户代码中手动切换执行上下文,使得任务之间的切换更加高效。
在 lua 语言中,协程也被叫做线程,但和操作系统的线程无关,只是叫法而已。后面提到的线程如果不特指,均是表示 lua 协程。
lua 中的线程主要由数据栈和调用栈结合构成。数据栈存放在 lua_State.stack 中。调用栈用 CallInfo 结构体表示,存放在 lua_State.ci 中。
线程创建
lua 线程的创建分两种,一种是通过 coroutine.create,另一种是 coroutine.wrap,区别在于后者不是保护模式运行,如果发生任何错误,抛出这个错误。前者一般是搭配 coroutine.resume 调用,运行在保护模式下的,即使发生异常,在不加 pcall 的情况下,也不会影响后续的代码运行。接着,我们看看源码。
在 lcorolib.c 文件中,我们可以看到,coroutine.create 对应的 c 函数实现是 luaB_cocreate。
static int luaB_cocreate (lua_State *L) {
lua_State *NL;
luaL_checktype(L, 1, LUA_TFUNCTION);
NL = lua_newthread(L);
lua_pushvalue(L, 1); /* move function to top */
lua_xmove(L, NL, 1); /* move function from L to NL */
return 1;
}
LUA_API void lua_xmove (lua_State *from, lua_State *to, int n) {
int i;
if (from == to) return;
lua_lock(to);
api_checknelems(from, n);
api_check(from, G(from) == G(to), "moving among independent states");
api_check(from, to->ci->top - to->top >= n, "stack overflow");
from->top -= n;
for (i = 0; i < n; i++) {
setobj2s(to, to->top, from->top + i);
to->top++; /* stack already checked by previous 'api_check' */
}
lua_unlock(to);
}在 luaB_cocreate 函数中,主要做5件事。
- 检测参数是否是函数类型。
- 创建一个新的线程对象 NL,其实结构就是 lua_State,类型是 LUA_TTHREAD。
- 将新创建的线程对象 NL 压入当前线程 L 的栈中。
- 最后将函数转移到新线程 NL 的栈中。该函数做为 NL 新线程执行的入口。
- 返回新线程 NL 给用户。
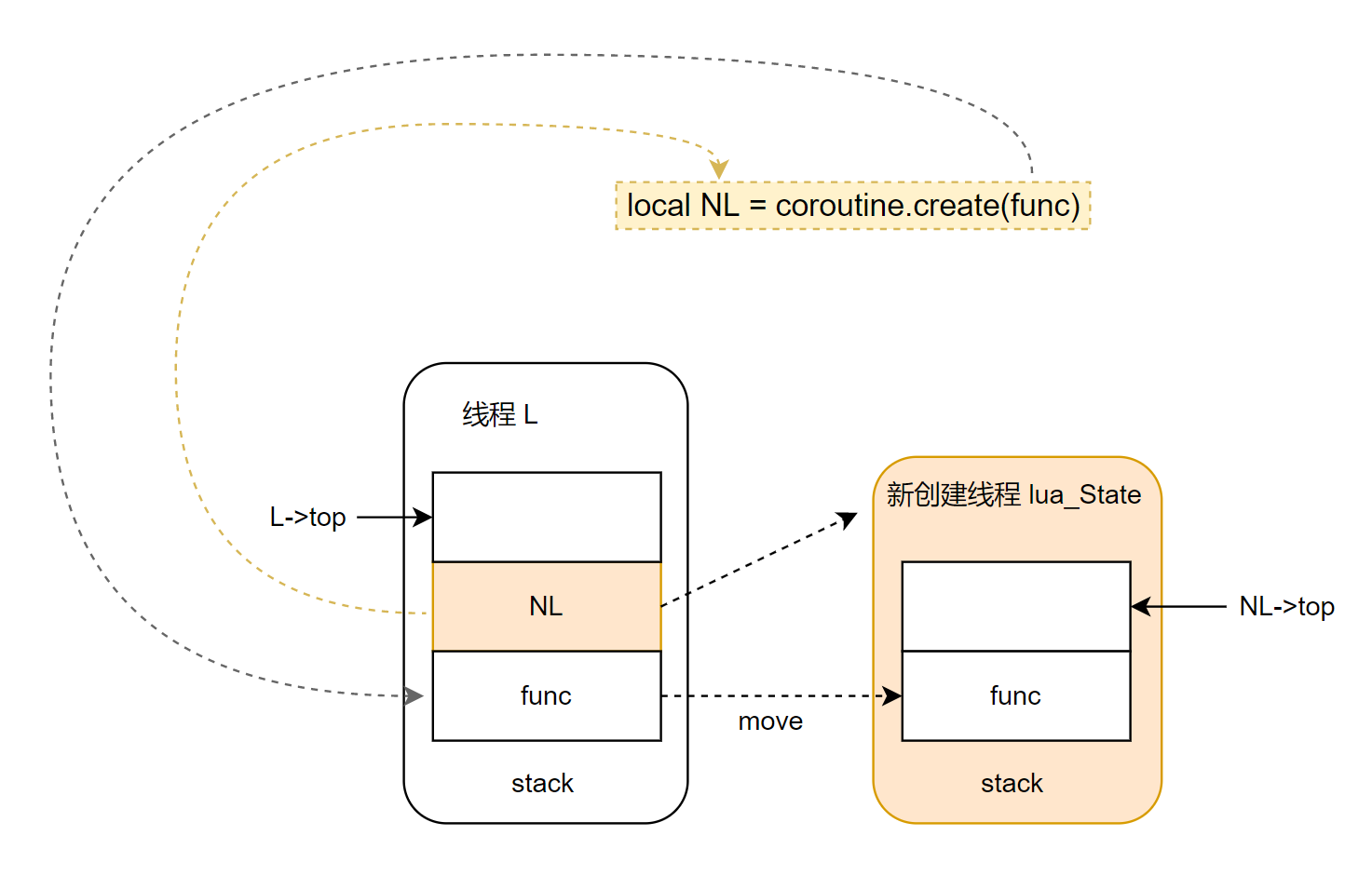
coroutine.create 调用时,对应的线程环境是 L,返回的是新线程 NL 对象,新线程和原线程公用同一个全局注册表,全局变量。注意,在 lua 中,我们不能直接访问线程里的字段,只能通过 coroutine.resume 去完成新线程 NL 的开启。
另一种线程的创建方式是 coroutine.wrap,在源码实现中,它返回的不是一个线程对象,而是一个函数闭包对象:
static int luaB_cowrap (lua_State *L) {
luaB_cocreate(L);
lua_pushcclosure(L, luaB_auxwrap, 1);
return 1;
}我们看到,同样需要创建一个新线程 NL,只不过它做为 luaB_auxwrap 这个 c 函数的上值。返回的是这个 c 函数闭包。在使用时,我们是可以像函数调用那样,直接调用,将控制权转移到新线程去执行。比如:
local function f1(a, b)
print(a, b)
end
local func = coroutine.wrap(f1)
func(11, 22)在调用 func(11, 22) 时,其实就是在调用 luaB_auxwrap 函数。luaB_auxwrap内部会开启新线程调度。
线程启动
在coroutine.create创建新线程对象 co 后,我们通过coroutine.resume(co, ...) 方式启动线程执行,后面的 ... 表示由主线程传递参数给新线程主函数。 coroutine.resume对应的c代码实现是在 luaB_coresume 里头。
static int auxresume (lua_State *L, lua_State *co, int narg) {
int status;
if (!lua_checkstack(co, narg)) {
lua_pushliteral(L, "too many arguments to resume");
return -1; /* error flag */
}
if (lua_status(co) == LUA_OK && lua_gettop(co) == 0) {
lua_pushliteral(L, "cannot resume dead coroutine");
return -1; /* error flag */
}
// 主线程将参数转移到新线程的栈上
lua_xmove(L, co, narg);
// 保护模式下,执行新线程里的主函数部分逻辑
status = lua_resume(co, L, narg);
// 根据返回状态 status 判断主函数是否执行成功,执行成功或者中断情况下,将返回值列表 push 到主线程栈上。
if (status == LUA_OK || status == LUA_YIELD) {
int nres = lua_gettop(co);
if (!lua_checkstack(L, nres + 1)) {
lua_pop(co, nres); /* remove results anyway */
lua_pushliteral(L, "too many results to resume");
return -1; /* error flag */
}
lua_xmove(co, L, nres); /* move yielded values */
return nres;
}
else {
lua_xmove(co, L, 1); /* move error message 否则将失败信息返回给主线程 */
return -1; /* error flag */
}
}
static int luaB_coresume (lua_State *L) {
lua_State *co = getco(L);
int r;
r = auxresume(L, co, lua_gettop(L) - 1);
if (r < 0) {
lua_pushboolean(L, 0);
lua_insert(L, -2);
return 2; /* return false + error message */
}
else {
lua_pushboolean(L, 1);
lua_insert(L, -(r + 1));
return r + 1; /* return true + 'resume' returns */
}
}在 luaB_coresume里,先获取到 lua 传过来的线程对象。接着调用 auxresume 函数,我们看到,它主要完成3件事:
- 将参数列表从当前线程堆栈转移到新线程堆栈中。
- 执行新线程里的主函数逻辑。
- 在调用完主函数后(有可能是中断,或者正常执行完),将返回值列表,转移到当前线程堆栈中。
在auxresume中,接着调用 lua_resume ,这个是实现线程调度的核心。它会以保护模式下运行 resume。
LUA_API int lua_resume (lua_State *L, lua_State *from, int nargs) {
int status;
...
status = luaD_rawrunprotected(L, resume, &nargs);
...
return status;
}
static void resume (lua_State *L, void *ud) {
int n = *(cast(int*, ud)); /* number of arguments */
StkId firstArg = L->top - n; /* first argument */
CallInfo *ci = L->ci;
if (L->status == LUA_OK) { /* starting a coroutine? */
if (!luaD_precall(L, firstArg - 1, LUA_MULTRET)) /* Lua function? */
luaV_execute(L); /* call it */
}
else { /* resuming from previous yield */
...
}
}在线程创建的时候, L->status 状态是 LUA_OK(preinit_thread 函数中设置)。 resume 会根据 L->status 的状态来做相应的处理,L->status 为 LUA_OK,表明要启动执行新线程里的主函数。luaD_precall和luaV_execute使新线程中的 Lua 函数开始解释执行。

线程中断
线程中断,或者说线程让出执行权,在 lua 中是通过调用 coroutine.yield(...) 接口,其实现是对应 c 接口函数是 luaB_yield,代码实现如下:
static int luaB_yield (lua_State *L) {
return lua_yield(L, lua_gettop(L));
}
#define lua_yield(L,n) lua_yieldk(L, (n), 0, NULL)
LUA_API int lua_yieldk (lua_State *L, int nresults, lua_KContext ctx,
lua_KFunction k) {
CallInfo *ci = L->ci;
...
// 在协程里的函数调用链中,如果使用了没有延续的 api 函数调用,那么不能执行 yiled,抛出异常
if (L->nny > 0) {
if (L != G(L)->mainthread)
luaG_runerror(L, "attempt to yield across a C-call boundary");
else
luaG_runerror(L, "attempt to yield from outside a coroutine");
}
L->status = LUA_YIELD; // 设置 status 状态为 yield
ci->extra = savestack(L, ci->func); /* save current 'func' 保存函数地址到 ci->extra 字段中 */
if (isLua(ci)) { /* inside a hook? */
...
}
else {
if ((ci->u.c.k = k) != NULL) /* is there a continuation? */
ci->u.c.ctx = ctx; /* save context */
ci->func = L->top - nresults - 1; /* protect stack below results */
luaD_throw(L, LUA_YIELD); // 通过 longjmp 机制,跳回到 lua_resume 中。
}
...
return 0; /* return to 'luaD_hook' */
}我们看到,执行让出的逻辑,主要在 lua_yieldk 中实现。说明,在 lua 实现中,线程的挂起,不管是 lua, 还是 c 发起,最终一定走到 lua_yieldk 。
它是利用 c 语言标准库 api longjmp 实现,有关介绍可以百度下。在 lua_yieldk函数中,会先去判断 L->nny 字段是否大于 0,如果大于 0,表明在线程执行的函数调用链中,使用了没有延续点的 api 函数调用,那么就不能执行 yiled 中断处理,因为在 c 函数调用链中,如果出现中断,那么是恢复不了堆栈信息的。比如,有这么一个 c 调用链f1 -> pcall -> f2 -> f3 -> yiled,在 yiled 后,回到 pcall 函数继续执行后,想再恢复 f2,f3 执行后续代码是不可能的了,因为 longjmp 长跳转会把 f2,f3 堆栈破坏了。
延续点函数
如果一个 c 函数位于 resume 到 yield 的调用路径中间,那么 lua 无法保存 c 函数的状态以便在下次 resume 时恢复状态。lua 的做法是,让用户指定一个延续函数做为 yield 后能继续执行的替代品。比如 f2,f3 可以指定一个延续函数 f2_k,f3_k。在 yield 后,后续我们就用 f2_k,f3_k 替代 f2,f3 继续执行 yield 中断后半部分的代码逻辑。
你可以在lua_pcallk或者lua_callk中传入一个函数 k,也就是续点函数,当你的调用中某个 yield 被 resume 唤醒的时候,由于并不能够回到这个 c 函数中继续执行,但是它回调到用户提供的函数 k,让你有个能续上 c 函数中断后,继续执行下半部分代码的契机,这就是续点函数作用。
我们知道,在 lua 调用 c 函数时,都会创建一个新的 CallInfo 调用栈,coroutine.yield(...)对应的 CallInfo 关联的函数是luaB_yield,为了能在中断后,恢复函数执行环境,需要保存当前 CallInfo.func 指向栈中的函数地址偏移,如果有设置延续点函数,还需要保存延续点函数地址,以及延续点上下文状态 ctx。通常,lua 调用的 coroutine.yield(),也就是 luaB_yield,是不需要延续函数的,因为luaB_yield只需要能做到接受来自主线程传递过来的参数列表就可以了,luaB_yield 的使命就算完成了,接着回退到上一个 CallInfo,也就是 lua 的 CallInfo,取出之前剩余未执行的 lua 指令继续跑。顺便提下,lua 代码都是会解析成指令码的,自身就存储了调用栈信息,以及数据栈信息,天然具备中断后,能延续恢复的特征。延续函数也是针对用户 c 函数而言的。
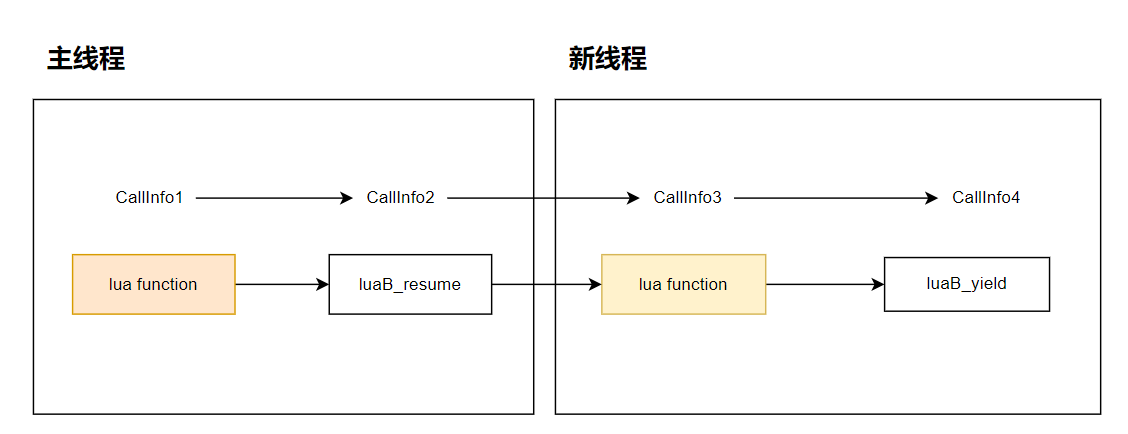
紧接着,ci->func = L->top - nresults - 1;这行代码的作用是保存返回值列表中的第一个值地址到 ci->func 位置中,后面会根据这个地址,把 ci->func 到 L->top 的所有返回值 push 到 主线程的栈中。
最后,luaD_throw(L, LUA_YIELD);完成新线程的中断处理,根据longjmp 机制会退回到lua_resume函数中的 status = luaD_rawrunprotected(L, resume, &nargs);这行代码,拿到 LUA_YIELD 状态返回,再由 auxresume 将新线程的返回值列表转移到主线程的栈中。完成了 执行权限 由新线程到主线程的转移过程,并将返回值列表通过 lua_xmove进行了转移。

线程恢复
线程在挂起,或者中断后,想要再次恢复执行,lua 提供的 API 接口是 coroutine.resume(co, ...),没错,和线程启动的调用方式一样。也就是说线程的启动和恢复都是调用同一个接口,这样简化了 API 接口设计,同时,我们也可以猜测到,线程的启动和恢复,会有一部分逻辑是相同的。
在 luaB_coresume 到 auxresume 之间,线程启动和恢复前期要做的事情都差不多。把参数转移到新线程的栈中。然后执行新线程相关逻辑。具体看 resume 函数实现:
static void resume (lua_State *L, void *ud) {
int n = *(cast(int*, ud)); /* number of arguments */
StkId firstArg = L->top - n; /* first argument */
CallInfo *ci = L->ci;
if (L->status == LUA_OK) { /* starting a coroutine? */
...
}
else { /* resuming from previous yield */
// 恢复执行 yield 中断后的逻辑,L->status 状态一定是挂起的
lua_assert(L->status == LUA_YIELD);
L->status = LUA_OK; /* mark that it is running (again) */
ci->func = restorestack(L, ci->extra);
...
else { /* 'common' yield */
...
// 退出 luaB_yield 这个 ci,回到上一级调 yield 那个 lua ci 中,并将主线程的传递过来的参数做为新线程的返回值
luaD_poscall(L, ci, firstArg, n); /* finish 'luaD_precall' */
}
// 继续执行 yield 中断的后续 lua 代码
unroll(L, NULL); /* run continuation */
}
}
static void unroll (lua_State *L, void *ud) {
...
else { /* Lua function */
luaV_finishOp(L); /* finish interrupted instruction */
luaV_execute(L); /* execute down to higher C 'boundary' */
}
}
}在第4行,获取当前的 ci(关联luaB_yield函数)。然后调用 luaD_poscall,完成 yield 参数传递,然后返回到上一层 ci,即调用 coroutine.yield的那个 lua 函数,最后调用 unroll 函数继续执行 lua 函数剩余代码。

我们在 unroll 函数中看到,在执行 luaV_execute 之前,会先调用 luaV_finishOp来完成被中断的指令处理。我们之前讨论过,luaD_throw(L, LUA_YIELD);中断调用后,luaV_execute执行的指令也会被中断了。这个luaV_finishOp函数目的就是把中断的指令逻辑补完。
比如下面一段代码,在线程里面执行执行整数与元表的加法操作:
local t = setmetatable({}, {__add = function (num1, self)
local num0 = 1
coroutine.yield()
return num0 + num1
end})
local co = coroutine.create(function ()
local a = 12 + t
print("a:", a)
end)
coroutine.resume(co)
coroutine.resume(co)在执行第 8 行代码时,local a = 12 + t 触发 t 的元表 __add 元方法调用,接着执行 coroutine.yield(),中断当前线程执行。也就是说,local a = 12 + t 会被 yield 打断。一个加法指令的实现,本质上是在调用 c 函数,我们再深入分析加法指令中包含元表的实现部分:
void luaV_execute (lua_State *L) {
...
vmcase(OP_ADD) {
TValue *rb = RKB(i);
TValue *rc = RKC(i);
...
else { Protect(luaT_trybinTM(L, rb, rc, ra, TM_ADD)); }
vmbreak;
}
...
}
void luaT_trybinTM (lua_State *L, const TValue *p1, const TValue *p2,
StkId res, TMS event) {
if (!luaT_callbinTM(L, p1, p2, res, event)) {
...
}
}
int luaT_callbinTM (lua_State *L, const TValue *p1, const TValue *p2,
StkId res, TMS event) {
const TValue *tm = luaT_gettmbyobj(L, p1, event); /* try first operand */
...
luaT_callTM(L, tm, p1, p2, res, 1);
return 1;
}
void luaT_callTM (lua_State *L, const TValue *f, const TValue *p1,
const TValue *p2, TValue *p3, int hasres) {
ptrdiff_t result = savestack(L, p3);
StkId func = L->top;
setobj2s(L, func, f); /* push function (assume EXTRA_STACK) */
setobj2s(L, func + 1, p1); /* 1st argument */
setobj2s(L, func + 2, p2); /* 2nd argument */
L->top += 3;
if (!hasres) /* no result? 'p3' is third argument */
setobj2s(L, L->top++, p3); /* 3rd argument */
/* metamethod may yield only when called from Lua code */
if (isLua(L->ci))
luaD_call(L, func, hasres); // 如果里面由 yield 中断调用,那么下面的代码是无法执行了,返回值放在栈顶中
else
luaD_callnoyield(L, func, hasres);
// 如果需要有返回值,则将栈顶的值赋值给 p3 所指向的那个位置
if (hasres) { /* if has result, move it to its place */
p3 = restorestack(L, result);
setobjs2s(L, p3, --L->top);
}
}通过跟踪函数调用链,我们发现,函数 luaT_callTM 是实现 __add = function (num1, self) ... end元方法的入口,代码中的 p1 指向参数 12(num1),p2 指向 t(self),p3 是指向 12 + t 返回值要放在栈上的位置。如果 __add 元方法是指向一个 lua 函数,那么会调用 40 行代码luaD_call(L, func, hasres);。如果元方法里,没有 yield 调用,那么在 return num0 + num1调用后,也就是值 13,会 push 到线程的栈顶,最后赋值给局部变量 a,最终完成 local a = 12 + t 加法指令。但如果在元方法里,发生 yield 中断,那么后面第 47 行,对 p3 赋值的代码是没办法再继续执行了,也就是说,无法完成最终对变量 a 赋值。
想要在 yield 中断之后,还能恢复对变量 a 赋值,lua 采用的方法是在每次进入 luaV_execute 之前,先检测下前一条指令,是否有需要补全的,如果有就补全指令剩余逻辑,对应的代码实现是在luaV_finishOp中。
我们就对上面元表加法的例子,如何在 yield 中断后,还能对变量 a 赋值进行分析。
/*
** finish execution of an opcode interrupted by an yield
*/
void luaV_finishOp (lua_State *L) {
CallInfo *ci = L->ci;
StkId base = ci->u.l.base;
Instruction inst = *(ci->u.l.savedpc - 1); /* interrupted instruction */
OpCode op = GET_OPCODE(inst);
switch (op) { /* finish its execution */
// 完成加法指令,将栈顶值,也就是加法结果,赋值给 base + ra 寄存器
case OP_ADD: {
setobjs2s(L, base + GETARG_A(inst), --L->top);
break;
}
...
}代码中的 base + GETARG_A(inst)对应 a 变量在栈中的偏移位置,L->top 减一取出栈顶值(也就是 12+t 的结果值13),setobjs2s执行赋值操作,相当于 执行了 a = 13。其他指令补完逻辑实现就不在一一讲解,有兴趣的可以试验下。
unroll 在完成中断的指令后,接着调用 luaV_execute 继续执行 lua 函数。这个过程比较复杂,要多调试下源码,才好理解。
错误处理
在之前有说过,新线程的创建有两种方式,它们对错误的处理方式不同。一种是 coroutine.create 返回新线程对象,遇到错误时,会把错误码返回给主线程,不会导致主线程中断代码执行。另一种是 coroutine.wrap返回闭包函数,可以直接调用函数来唤醒线程执行,但在出现错误时,会抛出异常,主函数如果不使用保护模式 pcall 的话,则会中断代码执行,退出程序。
如果大家细心,会发现 coroutine.create 和 coroutine.wrap 最终都会走到 lua_resume 这个函数,而 lua_resume 是保护模式下执行 resume 的。也就是说,新线程发生错误时,lua_resume 都会捕获异常。所以,最终关键还是在于 coroutine.create 和 coroutine.wrap 对 lua_resume 返回值的处理方式不同。
static int luaB_coresume (lua_State *L) {
lua_State *co = getco(L);
int r;
r = auxresume(L, co, lua_gettop(L) - 1);
// 根据新线程返回状态,判断新线程执行过程中是否发生错误,如果发生错误,会先返回一个 false 标记,外加错误信息
if (r < 0) {
lua_pushboolean(L, 0);
lua_insert(L, -2);
return 2; /* return false + error message */
}
else {
// 如果执行成功,则先返回一个 true 标记,外加新线程传递给主线程的 返回值列表
lua_pushboolean(L, 1);
lua_insert(L, -(r + 1));
return r + 1; /* return true + 'resume' returns */
}
}
static int luaB_auxwrap (lua_State *L) {
lua_State *co = lua_tothread(L, lua_upvalueindex(1));
int r = auxresume(L, co, lua_gettop(L));
if (r < 0) { // 发生错误了
if (lua_type(L, -1) == LUA_TSTRING) { /* error object is a string? */
luaL_where(L, 1); /* add extra info */
lua_insert(L, -2);
lua_concat(L, 2);
}
// 如果出现错误,主线程继续抛出异常
return lua_error(L); /* propagate error */
}
return r; // 新线程 return 返回值列表个数;返回值列表则是已放在栈上
}可以看到,对于 coroutine.resume(新线程对象co, ...)返回结果,是先判断状态有没有发生错误,有的话,会返回一个 false + 错误信息。如果调用成功,则返回一个 true + 新线程返回值列表。
而对于 coroutine.wrap方式调用函数的返回结果,则和普通函数调用一样,有错误,会继续抛出异常,等待上层捕获。如果外围的所有函数都没有进行捕获,那么就会中断代码执行,退出程序。如果调用成功,则返回新线程 return 后面的值,不会像 coroutine.resume 那样返回值中带上 true 标记。
看两个 lua 例子:
local co = coroutine.create(function ()
local a = 1 + num
end)
local status, err = coroutine.resume(co)
print("msg:", status, err)
print("run end")
--[[
运行结果:
msg: false aaa.lua:2: attempt to perform arithmetic on a nil value (global 'num')
run end
]]local wrap = coroutine.wrap(function()
print("error test")
coroutine.yield(a.b)
end)
wrap()
print("run end")
--[[
运行结果:
error test
lua: aaa.lua:6: aaa.lua:3: attempt to index a nil value (global 'a')
stack traceback:
[C]: in local 'wrap'
aaa.lua:6: in main chunk
[C]: in ?
]]可以看到,使用 coroutine.wrap 函数调用方式,发生错误时,最后的 "run end" 没有打印,程序就结束了。而 coroutine.resume 方式的线程调用出错时,则还能继续执行程序后面的代码。
不过,还有一个有意思的地方需要再分析下,那就是 lua_resume函数对发生错误时的处理。
LUA_API int lua_resume (lua_State *L, lua_State *from, int nargs) {
...
status = luaD_rawrunprotected(L, resume, &nargs);
...
else { /* continue running after recoverable errors */
while (errorstatus(status) && recover(L, status)) {
/* unroll continuation */
status = luaD_rawrunprotected(L, unroll, &status);
}
if (errorstatus(status)) { /* unrecoverable error? */
L->status = cast_byte(status); /* mark thread as 'dead' */
seterrorobj(L, status, L->top); /* push error message */
L->ci->top = L->top;
}
...
return status;
}luaD_rawrunprotected 返回的 status 状态码有如下几种:
#define errorstatus(s) ((s) > LUA_YIELD)
/* thread status */
#define LUA_OK 0
#define LUA_YIELD 1
#define LUA_ERRRUN 2
#define LUA_ERRSYNTAX 3
#define LUA_ERRMEM 4
#define LUA_ERRGCMM 5
#define LUA_ERRERR 6在 luaD_rawrunprotected 返回的 status > LUA_YIELD 时,表明 lua 代码运行时发生错误了,需要对错误进行处理。
它的做法是,先查询发生错误的函数调用链中,有没有使用过保护模式 pcall 。如果有,那么就将错误信息,传递到这个 pcall 调用点,同时,接着执行 pcall 后面的代码。
例如下面代码,在调用 func 函数里抛出异常 error 后,回退到第 7 行 pcall,接着执行后面代码,打印变量 a。
local function func()
coroutine.yield("ok")
error("err")
end
local function man()
pcall(func)
local a = 1
print("a:", a)
end
local co = coroutine.create(man)
print(coroutine.resume(co)) -- true ok
print(coroutine.resume(co)) -- true
--[[
运行结果:
true ok
a: 1
true
]]在新线程内执行 pcall 和在主线程内执行 pcall 的实现是不一样的。
在 lua 代码中调用的 pcall 对应在 C 代码里面就是调用 luaB_pcall,如果是在协程内调用,最终会走到下面这段代码:
LUA_API int lua_pcallk (lua_State *L, int nargs, int nresults, int errfunc,
lua_KContext ctx, lua_KFunction k) {
...
else { /* prepare continuation (call is already protected by 'resume') */
CallInfo *ci = L->ci;
ci->u.c.k = k; /* save continuation */
ci->u.c.ctx = ctx; /* save context */
/* save information for error recovery */
ci->extra = savestack(L, c.func);
ci->u.c.old_errfunc = L->errfunc;
L->errfunc = func;
setoah(ci->callstatus, L->allowhook); /* save value of 'allowhook' */
ci->callstatus |= CIST_YPCALL; /* function can do error recovery */
luaD_call(L, c.func, nresults); /* do the call */
ci->callstatus &= ~CIST_YPCALL;
L->errfunc = ci->u.c.old_errfunc;
status = LUA_OK; /* if it is here, there were no errors */
}
...
return status;
}我们可以看到,这时的 pcall 没用 longjmp 保护模式执行函数,而是使用 luaD_call执行 func 函数。因为如果 pcall 也使用 longjmp 保护模式执行 func,那么在正常情况下, coroutine.yield()就会跳到这个 pcall 调用点,而不是跳回到 coroutine.resume 调用点了。所以,必须保证在新线程内,只有 lua_resume 是在使用 longjmp 保护机制,其函数内的调用链中,不应该再使用到 longjmp 。虽然 lua 层的 API 能保证这一点,但如果我们是在写 c 库时, lua 就不能保证了,因为可以直接调用 lua_pcallk 函数,不传延续函数 k 时,就会走 longjmp 机制的,这就取决于用户自己选择了。
那么 lua 层的 API 是如何保证协程内的函数调用链是没有走 longjmp 的呢,核心在于 lua 状态机有一个叫 nny 的字段,当进入 resume 线程调用时,L->nny 置为 0,当调用 lua_pcallk 时,发现 L->nny 为 0 且存在延续函数时,就上面第 4 行 else 分支,给当前 ci 加上 CIST_YPCALL 标记,调用 luaD_call,以非保护模式下执行 func 函数,这样,在 pcall 里coroutine.yield()中断跳转也是先回到 lua_resume 函数里了。
但如果 pcall(func) 没有使用 longjmp 机制,那么 func 内部出错了,我们看到的现象是,它会退回到 pcall 那个调用点,而不是退回到 coroutine.resume,这又是做到的呢。我们在回顾看下 lua_resume else 部分代码:
LUA_API int lua_resume (lua_State *L, lua_State *from, int nargs) {
...
status = luaD_rawrunprotected(L, resume, &nargs);
...
else { /* continue running after recoverable errors */
while (errorstatus(status) && recover(L, status)) {
/* unroll continuation */
status = luaD_rawrunprotected(L, unroll, &status);
}
...
}
// 尝试查找一个 pcall 调用点的 CallInfo 调用栈,判断依据是 callstatus 带有 CIST_YPCALL 标记
static CallInfo *findpcall (lua_State *L) {
CallInfo *ci;
for (ci = L->ci; ci != NULL; ci = ci->previous) { /* search for a pcall */
if (ci->callstatus & CIST_YPCALL)
return ci;
}
return NULL; /* no pending pcall */
}
static int recover (lua_State *L, int status) {
StkId oldtop;
CallInfo *ci = findpcall(L);
if (ci == NULL) return 0; /* no recovery point */
/* "finish" luaD_pcall */
// 恢复到 pcall 那时的栈顶,和 close 掉旧栈之上的 upvalue
oldtop = restorestack(L, ci->extra);
luaF_close(L, oldtop);
seterrorobj(L, status, oldtop);
L->ci = ci;
L->allowhook = getoah(ci->callstatus); /* restore original 'allowhook' */
L->nny = 0; /* should be zero to be yieldable */
luaD_shrinkstack(L);
L->errfunc = ci->u.c.old_errfunc;
return 1; /* continue running the coroutine */
}我们可以看到,凡是在新线程里的 pcall 调用,都会被标记上 CIST_YPCALL,这里 findpcall函数就是为了按顺序查找最近带有 CIST_YPCALL 标记的一个 pcall 调用点,然后 L->ci 指向它,表示当前要执行的 ci,在保护模式下 unroll 回滚执行 pcall 续点函数 finishpcall,最后通过 luaD_poscall 返回错误信息给 pcall 的调用者 f2,接着继续执行 f2 pcall 后续的代码(包括了 unroll -> finishCcall -> luaD_poscall 将错误信息返回给 pcall 的调用者 f2)。

参考:
深入Lua:协程的实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号