lua5.3 gc 清除阶段分析(7)
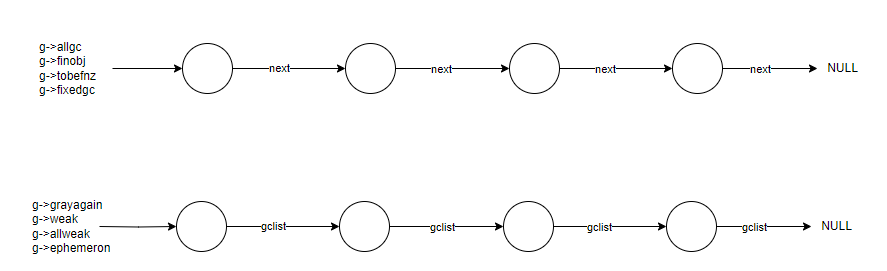
清除阶段主要是针对 g->allgc,g->finobj,g->tobefnz 这三个链表上的对象。g->allgc 链表是会存在死亡对象(没有再被引用着的对象),而 g->finobj,g->tobefnz 这两个链表,主要是存储带 __gc 元方法的对象,根据上一篇的介绍,我们知道 g->finobj,g->tobefnz 链表上是不存在死亡对象的,那清除阶段要对它们俩做些什么呢?答案是要把 g->finobj,g->tobefnz 链表上的对象重新标记为当前白色。如果标记阶段是 white0,那么清除阶段就要重置为 white1。
那么为啥其他的链表,比如 g->weak,g->grayagain 等这些链表不需要清除呢?答案是因为,这些链表其实只是标记阶段和原子阶段,辅助标记一些特殊对象,才临时存在的,用的是对象的 gclist 字段串连起来构成链表的,而且对象只会被其中的某个链表引用,因为 gclist 字段只有一个。新创建的可回收对象,仔细观察,会发现对象,只能在 g->allgc、g->fixedgc、g->finobj、g->tobefnz 这四个链表中的一处存在,通过 next 字段串连。
这里提到了一个新的链表 g->fixedgc,这个是针对短字符串的,比如一些不需要被回收到的短字符串,就会放到这个链表里头,目前只有lua的关键字(比如,字面量 "function","do","if" 等)。这个比较简单,可以直接全局搜索下源码就知道了,没啥太多可介绍的。
entersweep() 函数分析
在原子阶段结束 atomic() 执行完后,就会接着调用 entersweep(),进入清除阶段的开始。
lu_mem singlestep (lua_State *L) {
global_State *g = G(L);
switch (g->gcstate) {
...
case GCSatomic: {
lu_mem work;
propagateall(g); /* make sure gray list is empty */
work = atomic(L); /* work is what was traversed by 'atomic' */
entersweep(L);
g->GCestimate = gettotalbytes(g); /* first estimate */;
return work;
}
case GCSswpallgc: { /* sweep "regular" objects */
return sweepstep(L, g, GCSswpfinobj, &g->finobj);
}
case GCSswpfinobj: { /* sweep objects with finalizers */
return sweepstep(L, g, GCSswptobefnz, &g->tobefnz);
}
case GCSswptobefnz: { /* sweep objects to be finalized */
return sweepstep(L, g, GCSswpend, NULL);
}
case GCSswpend: { /* finish sweeps */
makewhite(g, g->mainthread); /* sweep main thread */
checkSizes(L, g);
g->gcstate = GCScallfin;
return 0;
}
case GCScallfin: { /* call remaining finalizers */
if (g->tobefnz && g->gckind != KGC_EMERGENCY) {
int n = runafewfinalizers(L);
return (n * GCFINALIZECOST);
}
else { /* emergency mode or no more finalizers */
g->gcstate = GCSpause; /* finish collection */
return 0;
}
}
default: lua_assert(0); return 0;
}
}
/*
** Enter first sweep phase.
** The call to 'sweeplist' tries to make pointer point to an object
** inside the list (instead of to the header), so that the real sweep do
** not need to skip objects created between "now" and the start of the
** real sweep.
*/
static void entersweep (lua_State *L) {
global_State *g = G(L);
g->gcstate = GCSswpallgc;
lua_assert(g->sweepgc == NULL);
g->sweepgc = sweeplist(L, &g->allgc, 1);
} entersweep() 的实现也很简单,进入 GCSswpallgc 清除阶段,并将 g->sweepgc 指向 g->allgc 链表。注释也说得很清楚了,g->sweepgc 尝试指向链表的内部,而不是指向头节点。不过也只是尝试而已,我们具体看下 sweeplist() 实现就知道了。
/*
** sweep at most 'count' elements from a list of GCObjects erasing dead
** objects, where a dead object is one marked with the old (non current)
** white; change all non-dead objects back to white, preparing for next
** collection cycle. Return where to continue the traversal or NULL if
** list is finished.
*/
static GCObject **sweeplist (lua_State *L, GCObject **p, lu_mem count) {
global_State *g = G(L);
int ow = otherwhite(g);
int white = luaC_white(g); /* current white */
while (*p != NULL && count-- > 0) {
GCObject *curr = *p;
int marked = curr->marked;
if (isdeadm(ow, marked)) { /* is 'curr' dead? */
*p = curr->next; /* remove 'curr' from list */
freeobj(L, curr); /* erase 'curr' */
}
else { /* change mark to 'white' */
curr->marked = cast_byte((marked & maskcolors) | white);
p = &curr->next; /* go to next element */
}
}
return (*p == NULL) ? NULL : p;
}参数 count 是控制循环次数,最多遍历多少次就中止。参数 p 是待扫描的可回收对象链表指针。函数内部的实现也比较简单,在遍历链表 p 的对象时,如果对象是死亡的,没有再被引用着的白色对象,就会调用 freeobj() 释放掉,而如果对象还被引用着的,可达的,就会被 mark 为当前白色。
这里的参数 p 采用的是二级指针,目的就是为了能改变一级指针的指向,也就是可以改变 g->allgc 指针的指向。比如,如果 g->allgc 指向的第一个对象,就是要 free 的话,二级指针 p 指向 g->allgc 一级指针的地址,就可以轻松的改变 g->allgc,让其指向下一个可达的对象。这里的返回值,则是当前中断遍历的那个对象的地址,以便下次再进入时,能从这个对象出发,继续往下遍历。
举个例子,理解下二级指针使用,加深印象:
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
typedef struct node
{
int val;
struct node *next;
} node;
void add(node **p, int val) {
node *n = malloc(sizeof(node));
n->val = val;
n->next = *p;
*p = n;
}
void delete(node **p, int val) {
while(*p != NULL) {
node *cur = *p; // 如果 p是 list地址,*cur就是指向第一个节点,否则,cur则是指向下一个节点,因为*p 等于 当前节点的next值
if (cur->val == val) {
*p = cur->next; // 如果是链表指针list,就将其指向下一个节点,否则,将当前元素的next值设置为下一个节点地址
} else {
p = &(cur->next); // 注意,这里的 p 存储的是当前节点next的地址,而不是指向 next下一个节点
}
}
}
int main(void) {
node *list = NULL;
add(&list, 100);
add(&list, 12);
add(&list, 100);
add(&list, 5);
add(&list, -9);
for(node *p = list; p; p = p->next) {
printf("%d\t", p->val);
}
printf("\n");
delete(&list, 100);
delete(&list, -9);
for(node *p = list; p; p = p->next) {
printf("%d\t", p->val);
}
printf("\n");
return 0;
}
/**
运行结果:
-9 5 100 12 100
5 12
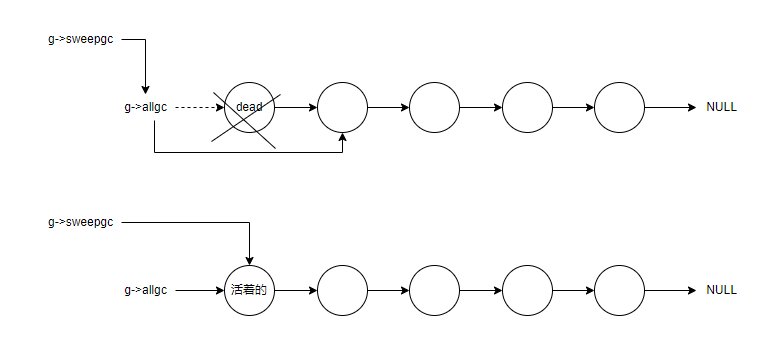
**/理解了二级指针,一级指针这些,再回过头看 entersweep() 里的 g->sweepgc = sweeplist(L, &g->allgc, 1); 这行代码,这里传给 sweeplist() 的 count 值为1, 表示只遍历一次,p 指向的是 g->allgc 一级指针的地址。那么 g->sweepgc 到底指向的是个什么地址呢?
从 sweeplist() 函数分析:
如果 g->allgc 指向的第一个对象 curr 是 dead 的,就会被 free,且还会执行 *p = curr->next; ,这时的 p 指向的是 g->allgc 地址,而 *p 则是相对于 g->allgc,这行代码的意思也就相对于 g->allgc = curr->next; g->allgc 指向下一个对象。返回的 p 地址也就是 g->allgc 的地址, entersweep() 中,得出 g->sweepgc 最终指向的是 g->allgc 指针的地址。
如果 g->allgc 指向的第一个对象 curr 不是 dead 对象的话,就将局部变量 p 指向当前第一个对象 curr 的 next 地址,注意这里不是指向下一个对象地址。如果我们是 p = curr->next 这么写,才是指向下一个对象地址。p = &curr->next; 则只是指向 第一个对象 curr 的 next 地址而已。而我们仔细观察的话,会发现 next 的地址和 curr 地址其实是一样的,因为可以从 GCObject 结构体的定义中看出来,next 是第一个字段,自然 next 和 curr 的地址是一样的了,起始地址一样。
typedef struct GCObject GCObject;
/*
** Common Header for all collectable objects (in macro form, to be
** included in other objects)
*/
#define CommonHeader GCObject *next; lu_byte tt; lu_byte marked
/*
** Common type has only the common header
*/
struct GCObject {
CommonHeader;
}; 所以,在entersweep() 中,得出 g->sweepgc 最终指向如下图:
在 entersweep() 函数中,为什么,不直接让 g->sweepgc 直接指向 g->allgc 地址,又或者直接指向 g->allgc指向的第一个对象地址呢?
如果不管三七二一, g->sweepgc 直接指向 g->allgc 地址会怎么样呢,我们知道清除节点也是可以分步执行的,可中断的,那么再不断创建新的对象后,g->allgc 所指向的链表就会不断的加长,且这些新增的对象都是不可回收的, g->sweepgc 遍历这些新增对象,做无用功,会有一点开销。所以,如果链表头的第一个对象不是 dead 的话,我们可以直接就指向这个头对象,而 g->allgc 在前面插入新的对象,也不会影响到对 g->sweepgc 指向的部分遍历,感觉这也算是一个小优化点吧。
如果啥也不管, g->sweepgc 直接就指向链表的第一个对象,那也不行,因为如果第一个对象是死的呢,g->sweepgc 和 g->allgc 同时指向这个对象,在 GCSswpallgc 阶段调用 sweepstep() 就会把第一个对象给 free 掉了,那 g->allgc 就指向一个死亡的对象了,就会有问题。
所以,在 entersweep() 函数中 g->sweepgc = sweeplist(L, &g->allgc, 1);这个写法感觉还是很巧妙。
GCSswpend 阶段
在 GCSswpend 阶段,主要调用了 checkSizes(L, g);对短字符串缓存表 g->strt 尝试缩容。如果当前缓存的字符串个数比表总个数/4 还少,说明当前不需要那么大的缓存表了,就要进行缩容,减为原先大小的一半。
/*
** If possible, shrink string table
*/
static void checkSizes (lua_State *L, global_State *g) {
if (g->gckind != KGC_EMERGENCY) {
l_mem olddebt = g->GCdebt;
if (g->strt.nuse < g->strt.size / 4) /* string table too big? */
luaS_resize(L, g->strt.size / 2); /* shrink it a little */
g->GCestimate += g->GCdebt - olddebt; /* update estimate */
}
}小结,lua gc 会对内部使用到的短字符串内部化hash表进行一次缩容 luaS_resize,同时,也会对清除字符串一级缓存表 luaS_clearcache(g)。
清除阶段总结
接着我们在 singlestep() 看到,在 g->sweepgc 遍历完 g->allgc 链表后,就进入 GCSswpfinobj, GCSswptobefnz 阶段,对 g->finobj,g->tobefnz 链表上的对象 mark 为当前白色,这些都可以分步执行的,不需要一次执行完,最后,就是对 g->tobefnz 链表上存在 __gc 元方法的对象进行调用,清除阶段就算大功告成了。最后,将 g->gcstate 设置为 GCSpause 状态,等待下一轮 gc 开始。
其实,我们从代码中不能发现,清除阶段主要还是清除 g->allgc 链表上的对象,以及缩容字符串缓存表 g->strt,从几个链表来说,只有 g->allgc 链表才有机会 free 释放内存,而 g->finobj,g->tobefnz 链表都只是做漂白工作而已。下面用一个图来概括下 gc 各个状态。

参考:
对 luaC_fullgc 全量gc的介绍 Lua5.3 GC源码阅读(5) | 重归混沌的BLOG (gotocoding.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号