
lua5.3 gc上值分析(5)
lua5.3的上值标记,涉及的内容有点多,就单独拿出来分析下,做下笔记。
我们知道,上值的引用者是闭包,其中包括了lua闭包,和c闭包,被引用者往往是栈上的对象。
c闭包上值 mark
先从简单的c闭包开始看起。
static lu_mem traverseCclosure (global_State *g, CClosure *cl) {
int i;
for (i = 0; i < cl->nupvalues; i++) /* mark its upvalues */
markvalue(g, &cl->upvalue[i]);
return sizeCclosure(cl->nupvalues);
}
/*
** traverse one gray object, turning it to black (except for threads,
** which are always gray).
*/
static void propagatemark (global_State *g) {
lu_mem size;
GCObject *o = g->gray;
lua_assert(isgray(o));
gray2black(o);
switch (o->tt) {
...
case LUA_TCCL: {
CClosure *cl = gco2ccl(o);
g->gray = cl->gclist; /* remove from 'gray' list */
size = traverseCclosure(g, cl);
break;
}
...
}对c闭包对象 mark black 后,调用 traverseCclosure() 遍历其所有的上值,进行 mark gray,加入到灰色链表,待下次处理。
lua闭包上值 mark
对于 lua闭包的上值,先看看代码实现部分。
static void propagatemark (global_State *g) {
lu_mem size;
GCObject *o = g->gray;
lua_assert(isgray(o));
gray2black(o);
switch (o->tt) {
case LUA_TLCL: {
LClosure *cl = gco2lcl(o);
g->gray = cl->gclist; /* remove from 'gray' list */
size = traverseLclosure(g, cl);
break;
}
...
}
/*
** open upvalues point to values in a thread, so those values should
** be marked when the thread is traversed except in the atomic phase
** (because then the value cannot be changed by the thread and the
** thread may not be traversed again)
*/
static lu_mem traverseLclosure (global_State *g, LClosure *cl) {
int i;
markobjectN(g, cl->p); /* mark its prototype */
for (i = 0; i < cl->nupvalues; i++) { /* mark its upvalues */
UpVal *uv = cl->upvals[i];
if (uv != NULL) {
if (upisopen(uv) && g->gcstate != GCSinsideatomic)
uv->u.open.touched = 1; /* can be marked in 'remarkupvals' */
else
markvalue(g, uv->v);
}
}
return sizeLclosure(cl->nupvalues);
}在 propagatemark() 函数中将 lua闭包 mark black 后,紧接着调 traverseLclosure() mark 其引用的函数原型 Proto,和上值 UpVal。
我们注意到,如果当前 gc 不处于 GCSinsideatomic 阶段,且引用的那个上值还在栈上的话,那就先将上值引用 UpVal 的 touched 字段置为1(这里 UpVal 的字段 v 才是指向栈上的那个具体对象)。如果是处于 GCSinsideatomic 阶段,也就是在执行原子阶段了,或者上值是关闭的,那么就会直接调用markvalue(g, uv->v); mark 上值。
UpVal 的 touched 字段置为1,说明处在 GCSpropagate 阶段,UpVal.v 引用的值在栈上可能会频繁发生改变,所以需要留到原子阶段再处理这个上值。
在查看 atomic() 调用 remarkupvals() 时,我发现不是简单的对 lua闭包引用的 UpVal(touched =1)进行 mark,我们先看看 remarkupvals() 实现。
/*
** Mark all values stored in marked open upvalues from non-marked threads.
** (Values from marked threads were already marked when traversing the
** thread.) Remove from the list threads that no longer have upvalues and
** not-marked threads.
*/
static void remarkupvals (global_State *g) {
lua_State *thread;
lua_State **p = &g->twups;
while ((thread = *p) != NULL) {
lua_assert(!isblack(thread)); /* threads are never black */
if (isgray(thread) && thread->openupval != NULL)
p = &thread->twups; /* keep marked thread with upvalues in the list */
else { /* thread is not marked or without upvalues */
UpVal *uv;
*p = thread->twups; /* remove thread from the list */
thread->twups = thread; /* mark that it is out of list */
for (uv = thread->openupval; uv != NULL; uv = uv->u.open.next) {
if (uv->u.open.touched) {
markvalue(g, uv->v); /* remark upvalue's value */
uv->u.open.touched = 0;
}
}
}
}
}函数具体的实现,还是涉及到了线程 thread->openupval 和 thread->twups 链表。
- thread->openupval:存放上值,即那些上值是在栈上的,还是存活着的,是 open 状态,没有离开当前作用域。
- g->twups:存放线程,即那些使用了上值的线程。
这两个链表都是在创建 lua 闭包,顺带创建该闭包所需的引用 UpVal 时,调用的,具体可以看下 pushclosure()和 luaF_findupval() 函数实现。
接着回到 remarkupvals() 函数,这里有个宏定义 lua_assert(!isblack(thread));这是因为线程是不可能为黑色的,我们可以从 propagatemark() 对线程的处理就可以知道,被引用的线程只能是灰色的,所以只要不是白色的,清除阶段就不会被回收。
if (isgray(thread) && thread->openupval != NULL)这样有个 if 判断,为啥要区分灰色的线程且有上值链表,p 就跳过当前线程,指向下一个线程呢。我猜测,可能是因为当前线程 L 是灰色的,说明线程对象要么是在 g->gray 链表,要么在 g->grayagain 链表中,如果是在 g->gray 链表的话,稍后 atomic() 会调用 propagateall()遍历到线程栈,去 mark 栈,而 mark 栈的局部变量,就相对于 mark 这个线程当前的 openupval 的上值了,所以可以跳过。如果是在 g->grayagain 链表中,说明当前开放的 UpVal 所引用的栈对象,也已经被线程 mark 访问过了,所以,也可以直接跳过。
接着看下当前是白色的线程对象(可能是没有再被引用到的,又或者还没被 mark 的),和没有使用过上值的线程对象,是怎么处理的。
从 remarkupvals() 的 else 分支看,遍历 thread->twups 链表,如果没有上值的线程,直接跳过,对有上值的线程,遍历 openupval 链表,对处于 open 状态的上值进行 mark,touched 标记为0,表示已经 mark 过了,之后不会重复 mark。
会不会有人产生疑惑,如果上值还在栈上,处于 open 状态,为啥不通过线程对象去 mark 栈就好了,这样上值也能被间接标记上了呀,为啥还要单独去写一个函数 remarkupvals 去遍历有上值的所有线程,去 mark 处于 open 状态的对象呢。
原因是,这个线程有可能是处于不可达的状态了,即它是白色的对象,需要被回收。此时,就没有机会放到 gray 链表了,那么也就没法 mark 栈上的对象,但栈上的对象又可能被其他地方引用着,所以,为了处理这种情况,我们只能在生成闭包函数时,检测闭包是否有上值引用,如果有,就需要把这个闭包所在的线程统一存到一个地方(g->twups 链表),避免线程对象是死的,但栈上还有变量被其他地方引用着。所以,才需要在原子阶段 remarkupvals 统一处理上值的 mark。那么有什么例子是能具体体现这个情况呢。
如下面的例子:
local co = coroutine.create(function ()
local x = {name = "aaa"}
local cco = coroutine.create(function ()
collectgarbage()
print("name:", x.name)
end)
coroutine.yield(cco)
-- 后续其他代码...
local a = 12
...
end)
local ok, cco = coroutine.resume(co)
co = nil
coroutine.resume(cco)
--[[
运行结果:
name: aaa
]]在 co 线程里,变量 x 被子线程 cco 引用着,在调用coroutine.yield(cco) 时,把子线程 cco 传递给主线程,此时,co 线程栈还是处于开放状态的,我们本可以通过 coroutine.resume(co) 去恢复 co 线程继续执行 11 行的后续代码,但我们在 16 行代码中,把 co 置为 nil 了,在第 17 行启动执行 cco 子线程,发现能正常打印 x.name 的值。我们从 gc 的角度去分析这段代码,x 变量是在 co 线程栈上创建的,但我们又在 cco 线程中引用着,此时,我们在主线程里,偷偷的把 co 置为 nil,那么此时,co 并不知道自己已经处于 dead 状态了,所以,在第 5 行执行全量 gc,gc 在整个标记阶段,都不会将其放到 gray 链表中,也就没有机会对栈上的 gc 可回收对象进行 mark。那么解决办法就是上面说的,把这些有用做上值引用的线程,统统存到一个地方 g->twups,在合适的实际(原子阶段)统一处理。
或许你又有可能会问,如果不统一通过线程来 mark 开放状态的上值,而是通过 闭包对象引用的那个上值对象来 mark,岂不是更简单。比如下图,thread1 线程置为 nil,标记阶段不能访问到这个对象了,但我们还是可以通过 thread2 的闭包 f1 引用的上值对象去间接 mark 线程1栈中的变量 a 指向的那个表对象。这样也就不需要用到 g->twups 链表了把。我之前也有想过这个问题,后面我仔细想了下,可能的原因是:
首先,原子阶段,我们能通过 gray 或者 grayagain 链表访问到的闭包对象是有限的,如果某个闭包 func2 在 GCSpropagate 标记阶段,就被访问过了,那么在原子阶段是不会再被访问的,那 func2 在 GCSpropagate 阶段,又不可能对开放的所有上值都进行 mark 操作,因为 GCSpropagate 阶段的上值指向是易变的,可能频繁变动,这一点,大家能赞同理解把。所以,如果想在原子阶段,通过闭包来 mark 上值,那么我们就要把当前环境下所有的闭包函数都收集起来,统一遍历 mark upvalue,才能保证无遗漏。这么一设计,是不是觉得把开放状态的线程收集起来,统一 mark upvalue 会效率更高一些呢。而且多个闭包大多数情况下,会引用同一个 upvalue,那么通过闭包来直接 mark upvalue,就会有重复 mark 同一个 upvalue 的可能,性能更差。
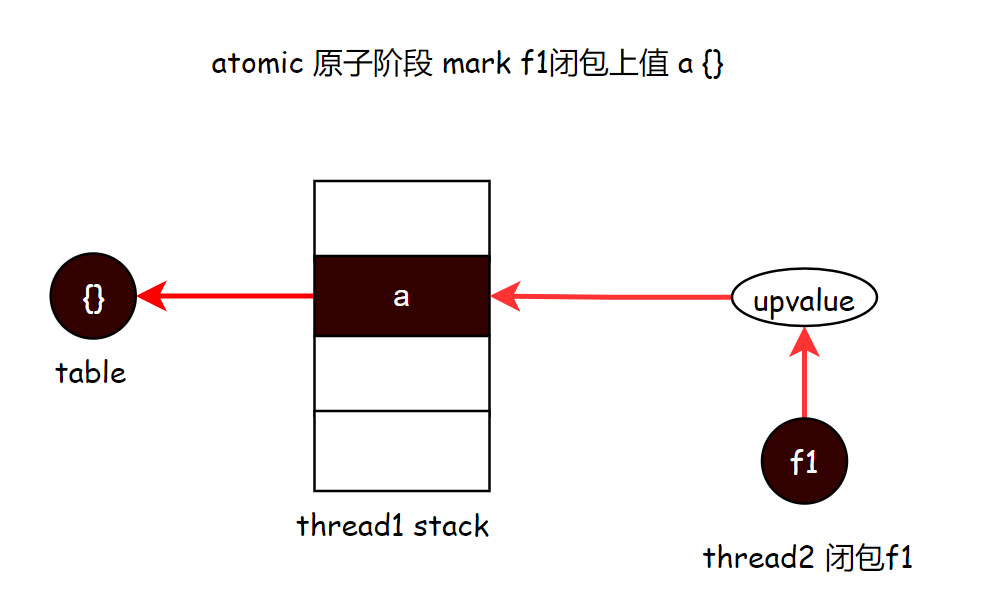
所以作者最终使用的是下图的方式,在原子阶段来 mark 所有处于开放状态的上值。当然,这也是我个人的猜测和思考,也不一定都对。

最近再仔细看 lgc.c 源码,我发现有一个比较有意思的现象,当然只是针对 lua5.3 的版本,lua.5.4 后的版本,上值引用变成一个可回收的对象了,就不存在这个现象。
我发现的现象就是 lua5.3 的 upvalue 引用的对象(就是处于 close 状态的上值对象),没有再被引用了,有可能会在下一轮 gc 才被回收,而不是在本轮回收,我们可以通过一个例子分析下就知道了。
local co = coroutine.create(function ()
local x = {} -- 在 luaF_findupval() 的时候就将 touched = 1,会在remarkupvals()中mark这个上值,导致下一轮gc才会被回收
local f1 = function ()
x.c = "aaa"
print("f1 x:", x)
end
print("======", x, f1)
local cco = coroutine.create(function ()
print("----------------------------- gc start")
collectgarbage()
print("----------------------------- gc end")
end)
coroutine.yield(cco)
end)
local ok, cco = coroutine.resume(co)
co = nil
ok = coroutine.resume(cco)
print("main end...", ok, cco)
--[[
运行结果:
====== table: 0000000000749ba0 function: 0000000000749960
----------------------------- gc start
----------------------------- gc end
main end... true thread: 000000000074e008
]]我们先创建一个协程 co(之前在c层,我是称作线程 thread,是同一个意思,大家知道下就行了)。在协程里面又创建了一个新的协程 cco,那么当前程序就存在两个协程。之后,我们调用一次 co ,获取到第2个协程的引用 cco 后,就将 co 置为nil,让当前环境只有一个协程 cco。然后,在执行协程 cco 里头,执行一次全量 gc,虽然,从程序表明上看不出什么来,实际上,在第一个协程 co 里头,创建的局部变量 x,经过全量 gc 后,并没有释放,而是要等到下一轮 gc 后,才会被释放的。
我们可以在 lgc.c 文件的释放接口 freeobj() 中加个日志打印,就更直观的看出来了。 freeobj() 和 luaC_upvdeccount() 函数加 printf 打印如下:
void luaC_upvdeccount (lua_State *L, UpVal *uv) {
lua_assert(uv->refcount > 0);
uv->refcount--;
if (ttype(uv->v) == LUA_TTABLE) {
printf("luaC_upvdeccount uv->refcount: %lld, uv->v: %p, isclose: %d\n", uv->refcount, hvalue(uv->v), !upisopen(uv));
}
if (uv->refcount == 0 && !upisopen(uv))
luaM_free(L, uv);
}
static void freeobj (lua_State *L, GCObject *o) {
switch (o->tt) {
case LUA_TPROTO: luaF_freeproto(L, gco2p(o)); break;
case LUA_TLCL: {
printf("free LClosure: %p\n", gco2lcl(o));
freeLclosure(L, gco2lcl(o));
break;
}
...
case LUA_TTABLE: {
printf("free table: %p\n", gco2t(o));
luaH_free(L, gco2t(o)); break;
}
...
}重新编译后,再次运行上面的 lua 程序,输出如下:
--[[
====== table: 0000000000729b40 function: 0000000000729d00
----------------------------- gc start
free LClosure: 0000000000729d00
luaC_upvdeccount uv->refcount: 0, uv->v: 0000000000729b40, isclose: 0
luaC_upvdeccount uv->refcount: 3, uv->v: 0000000000721820, isclose: 1
free LClosure: 000000000072eab0
luaC_upvdeccount uv->refcount: 2, uv->v: 0000000000721820, isclose: 1
free table: 0000000000729c00
----------------------------- gc end
main end... true thread: 000000000072dfd8
free table: 0000000000727590
free LClosure: 000000000072ed80
luaC_upvdeccount uv->refcount: 1, uv->v: 0000000000721820, isclose: 1
free table: 0000000000729b40
free LClosure: 000000000072c690
luaC_upvdeccount uv->refcount: 0, uv->v: 0000000000721820, isclose: 1
]]在 lua 程序执行全量 gc 前,先打印了表 x 的地址,以及函数闭包 f1 的地址,在打印的 gc start 到 gc end 之间,我们发现,并没有释放掉表 x(0000000000729b40),但闭包 f1(0000000000729d00) 却有被释放了,我之前没仔细看源码的时候,也以为 f1 引用着的表 x 会随着 f1 的释放而释放,因为表 x 除了 f1 引用着外,再没有被其他对象引用了。但实际上,我们看到的是,在 lua 程序运行结束时,才释放表 x(lua程序运行结束,会自动释放所有对象)。
原因,我们可以仔细看下 luaC_upvdeccount() 的实现,要满足两个条件,一个是 refcount 减为0,也就是这个上值没有再被任何一个闭包引用了,另一个条件是这个上值不在栈上。
我们可以通过打印,很明显的发现表 t(0000000000729b40)做为上值引用计数器减为0了,但它还是处于 open 状态的,所以就导致了它没有被回收。
为什么表 x 是处于 open 状态的呢,那是因为我们执行协程 co 的时候,创建了 f1 闭包,而在闭包的同时,也会在 luaF_findupval() 中创建一个与表 x 对应的 UpVal 引用对象,并将 touched 设置为1 。一开始就将 touched = 1,这可能是想表明 UpVal 在创建的时候,就是 open 状态了,然后挂到 L->openupval 链表中,且这个协程 co 也会被挂到 g->twups 链表中,最后又因为在原子阶段调用了 remarkupvals(),检查到引用表 x 的 UpVal.touched 等于1,导致表 x 被 mark 了,本轮 gc 自然也就没法回收这个表 x 了。
说的再具体点,我们知道闭包 f1 是通过 UpVal 这个对象去引用表 x 的,那么 f1 被回收了,UpVal 这个对象也是需要回收掉的,只是 UpVal 指向的表 x 这个对象没有被回收而已,得等下一轮 gc 才会被回收。因为 gc 只会处理 GCObject 类型的可回收对象,其他对象基本都是依附于可回收对象身上的(比如,UpVal 就是依附于lua闭包对象),UpVal 并没有设计成 GCObject。所以,我们在清除阶段,释放协程 co 时,会调用luaF_close(),里头就有因 refcount 减为 0 而回收 UpVal 对象,在没有引用 f1 时,就会回收 f1 闭包对象。
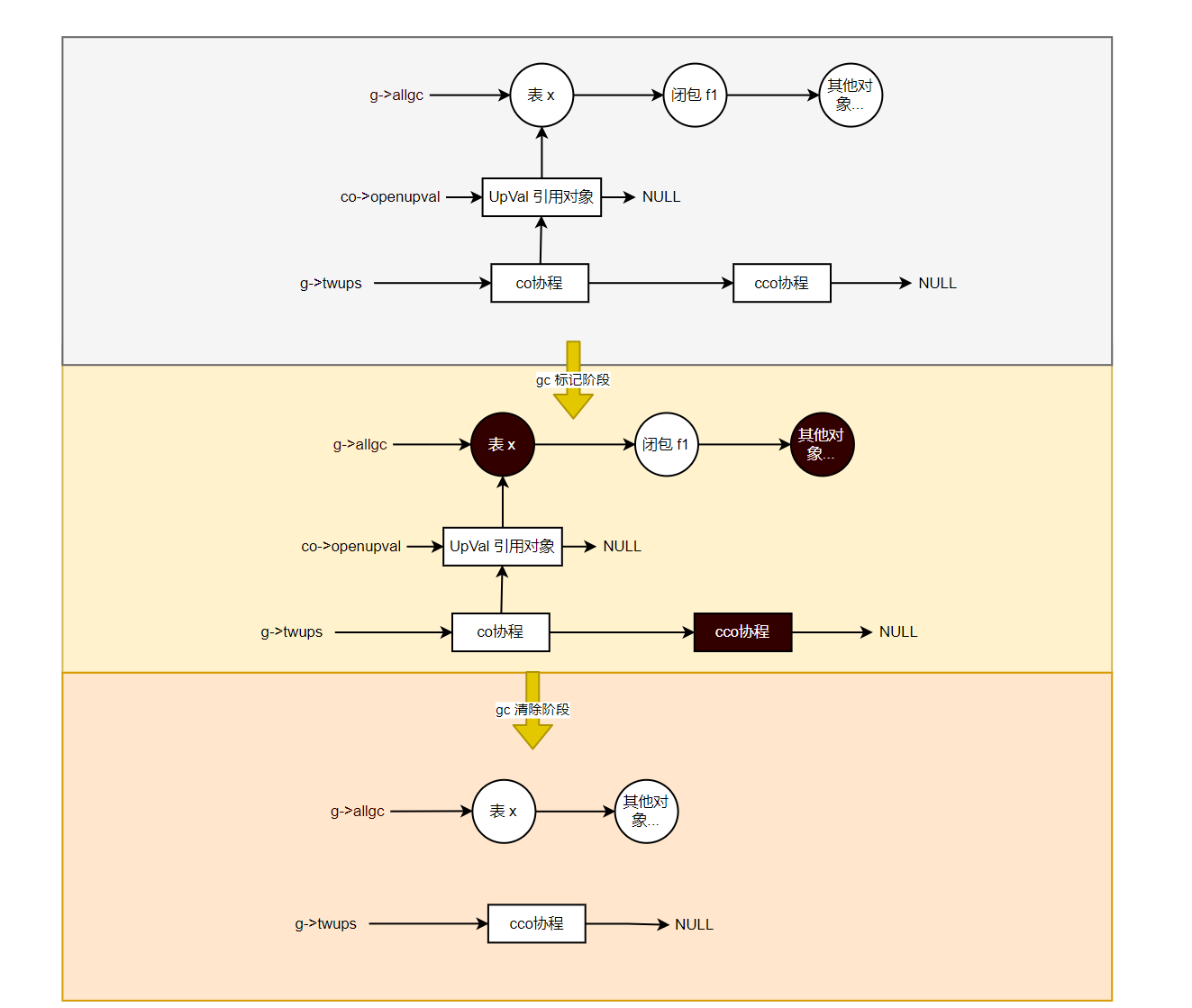
说的可能有点绕,总的来说,就是闭包 f 和 引用对象 UpVal 会本轮被回收,上值表 x 会在下一轮 gc 才被回收,如上图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号