
lua5.3 gc标记阶段分析(2)
对象创建
对于可回收的对象(TString,Table,Udata,Closure,Proto,lua_State),它们的创建流程基本相同,都是调用 luaC_newobj 接口的。举例,我们可以通过观察代码 table 的创建流程,可以得出,每个可回收的对象,都是由一个 GCObject 结构体拓展构成,有点像面向对象。在创建 table 时,我们需要指定 table 的大小 size,以及类型 tt(LUA_TTABLE),如果当前给到一个 GCObject 指针,我们就可以通过类型 tt,将 GCObject 转换成对应的可回收对象。
/*
** create a new collectable object (with given type and size) and link
** it to 'allgc' list.
*/
GCObject *luaC_newobj (lua_State *L, int tt, size_t sz) {
global_State *g = G(L);
GCObject *o = cast(GCObject *, luaM_newobject(L, novariant(tt), sz));
o->marked = luaC_white(g);
o->tt = tt;
o->next = g->allgc;
g->allgc = o;
return o;
}
// ltable.c
Table *luaH_new (lua_State *L) {
GCObject *o = luaC_newobj(L, LUA_TTABLE, sizeof(Table));
Table *t = gco2t(o);
t->metatable = NULL;
t->flags = cast_byte(~0);
t->array = NULL;
t->sizearray = 0;
setnodevector(L, t, 0);
return t;
}总结下创建对象做了哪些事:
- 通过 size 申请内存
- 将对象挂到 g->allgc 单向链表中
- 设置颜色为白色,既当前白(如果标记阶段是white0,那么清除阶段设置的就是 white1)
- 设置对象类型
lua gc 阶段状态
gc 总共有以下几种状态
/*
** Possible states of the Garbage Collector
*/
#define GCSpropagate 0
#define GCSatomic 1
#define GCSswpallgc 2
#define GCSswpfinobj 3
#define GCSswptobefnz 4
#define GCSswpend 5
#define GCScallfin 6
#define GCSpause 7GCSpause状态(不可中断,一步完成)
static lu_mem singlestep (lua_State *L) {
global_State *g = G(L);
switch (g->gcstate) {
case GCSpause: {
g->GCmemtrav = g->strt.size * sizeof(GCObject*);
restartcollection(g);
g->gcstate = GCSpropagate;
return g->GCmemtrav;
}
...
}
/*
** mark root set and reset all gray lists, to start a new collection
*/
static void restartcollection (global_State *g) {
g->gray = g->grayagain = NULL;
g->weak = g->allweak = g->ephemeron = NULL;
markobject(g, g->mainthread);
markvalue(g, &g->l_registry);
markmt(g);
// 有可能在清除阶段,执行了一次 full全量gc,导致之前的tobefnz链表上的节点没有被执行到
markbeingfnz(g); /* mark any finalizing object left from previous cycle */
}这是 lua gc 的开始阶段,主要是将 主线程,全局注册表,全局元表 标记为 gray,并加入到灰色链表中,markbeingfnz() 是对上一轮 g->tobefnz 链表还未执行 __gc 元方法存留下的对象,进行 mark gray,加入到灰色链表中,对于 tobefnz 链表后面再细说。
这个阶段完成后, gray 链表不为空,我们就可以遍历这个 gray 链表里的所有对象,mark 为 black,以及对象引用到的其他对象 mark 为 gray,并加入到 gray 链表。对于 gray 链表的遍历,是可以随时中断的,直到 gray 链表为空,才会进入下一个阶段。
在 lua 程序中,当前所有存活的对象,也就是有被引用到的对象,都是可以从主线程,全局注册表和全局元表出发搜索到的。被搜索到,意味着对象是可达的,活着的,最终会被标记为黑色,不可达的对象,就是白色,最后被回收。
接下来看看 markvalue(),和markobject() 实现。 markvalue 参数是一个 TValue 结构体,而 TValue 结构体中引用包含的 Value.GCObject 这样的一层关系。如果 TValue 的值存的是一个可回收的对象,那么就需要转成对应的 GCObject 对象,才能调用 reallymarkobject() 函数对其 mark gray,而 markobject 本身参数就是 GCObject,所以,直接调用 reallymarkobject() 函数对其 mark gray。
#define markvalue(g,o) { checkconsistency(o); \
if (valiswhite(o)) reallymarkobject(g,gcvalue(o)); }
#define markobject(g,t) { if (iswhite(t)) reallymarkobject(g, obj2gco(t)); }
/*
** mark an object. Userdata, strings, and closed upvalues are visited
** and turned black here. Other objects are marked gray and added
** to appropriate list to be visited (and turned black) later. (Open
** upvalues are already linked in 'headuv' list.)
*/
static void reallymarkobject (global_State *g, GCObject *o) {
reentry:
white2gray(o);
switch (o->tt) {
case LUA_TSHRSTR: {
gray2black(o);
g->GCmemtrav += sizelstring(gco2ts(o)->shrlen);
break;
}
case LUA_TLNGSTR: {
gray2black(o);
g->GCmemtrav += sizelstring(gco2ts(o)->u.lnglen);
break;
}
case LUA_TUSERDATA: {
TValue uvalue;
markobjectN(g, gco2u(o)->metatable); /* mark its metatable */
gray2black(o);
g->GCmemtrav += sizeudata(gco2u(o));
getuservalue(g->mainthread, gco2u(o), &uvalue);
if (valiswhite(&uvalue)) { /* markvalue(g, &uvalue); */
o = gcvalue(&uvalue);
goto reentry;
}
break;
}
case LUA_TLCL: {
linkgclist(gco2lcl(o), g->gray);
break;
}
case LUA_TCCL: {
linkgclist(gco2ccl(o), g->gray);
break;
}
case LUA_TTABLE: {
linkgclist(gco2t(o), g->gray);
break;
}
case LUA_TTHREAD: {
linkgclist(gco2th(o), g->gray);
break;
}
case LUA_TPROTO: {
linkgclist(gco2p(o), g->gray);
break;
}
default: lua_assert(0); break;
}
}对于类型为 lua 闭包,c闭包,表,线程,函数原型的对象操作比较简单,直接 mark gray,然后加入到 g->gray 灰色链表头部中。而对于字符串,不管是长字符串还是短字符串,因为它们不可能会引用到其他对象,所以是一步到位,直接标记为黑色。这也说明,只有对象引用着其他的对象,被引用的对象需要加入到灰色链表中。
GCSpropagate状态(可中断,多步完成)
static lu_mem singlestep (lua_State *L) {
global_State *g = G(L);
switch (g->gcstate) {
case GCSpropagate: {
g->GCmemtrav = 0;
lua_assert(g->gray);
propagatemark(g);
if (g->gray == NULL) /* no more gray objects? */
g->gcstate = GCSatomic; /* finish propagate phase */
return g->GCmemtrav; /* memory traversed in this step */
}
...
}
/*
** traverse one gray object, turning it to black (except for threads,
** which are always gray).
*/
static void propagatemark (global_State *g) {
lu_mem size;
GCObject *o = g->gray;
lua_assert(isgray(o));
gray2black(o);
switch (o->tt) {
case LUA_TTABLE: {
Table *h = gco2t(o);
g->gray = h->gclist; /* remove from 'gray' list */
size = traversetable(g, h);
break;
}
case LUA_TLCL: {
LClosure *cl = gco2lcl(o);
g->gray = cl->gclist; /* remove from 'gray' list */
size = traverseLclosure(g, cl);
break;
}
case LUA_TCCL: {
CClosure *cl = gco2ccl(o);
g->gray = cl->gclist; /* remove from 'gray' list */
size = traverseCclosure(g, cl);
break;
}
case LUA_TTHREAD: {
lua_State *th = gco2th(o);
g->gray = th->gclist; /* remove from 'gray' list */
linkgclist(th, g->grayagain); /* insert into 'grayagain' list */
black2gray(o);
size = traversethread(g, th);
break;
}
case LUA_TPROTO: {
Proto *p = gco2p(o);
g->gray = p->gclist; /* remove from 'gray' list */
size = traverseproto(g, p);
break;
}
default: lua_assert(0); return;
}
g->GCmemtrav += size;
}该阶段,主要是遍历 gray 灰色链表,逐步将灰色对象标记为黑色,并遍历其所引用到的其他对象,将它们都加入到灰色链表中,这样凡是还存活的对象,随着时间的推移,最后都会被遍历访问到,并且 mark black。这个过程是可以被打断的,分多次执行,不需要一步到位。比如 gc mark 一部分对象后,会切出,继续执行 lua 代码,等到内存涨到某个阀值时(这个阀值,后面在细说),又会触发 gc 操作,继续 mark 灰色链表剩余的对象。
举例:
local aa = {}
bb = {}
local m1, m2 = {}, {}
m1 = nil
m2 = nil就这两行代码,我们得出,变量 aa 所引用的表是放在栈中的,变量 bb 是放在全局环境 _ENV 中,而全局环境 _ENV 又是放在全局注册表中,m1 和 m2 创建后,就置为 nil,没有再被其他地方引用。我们可以通过画图来看下他们 gc 标记流程。
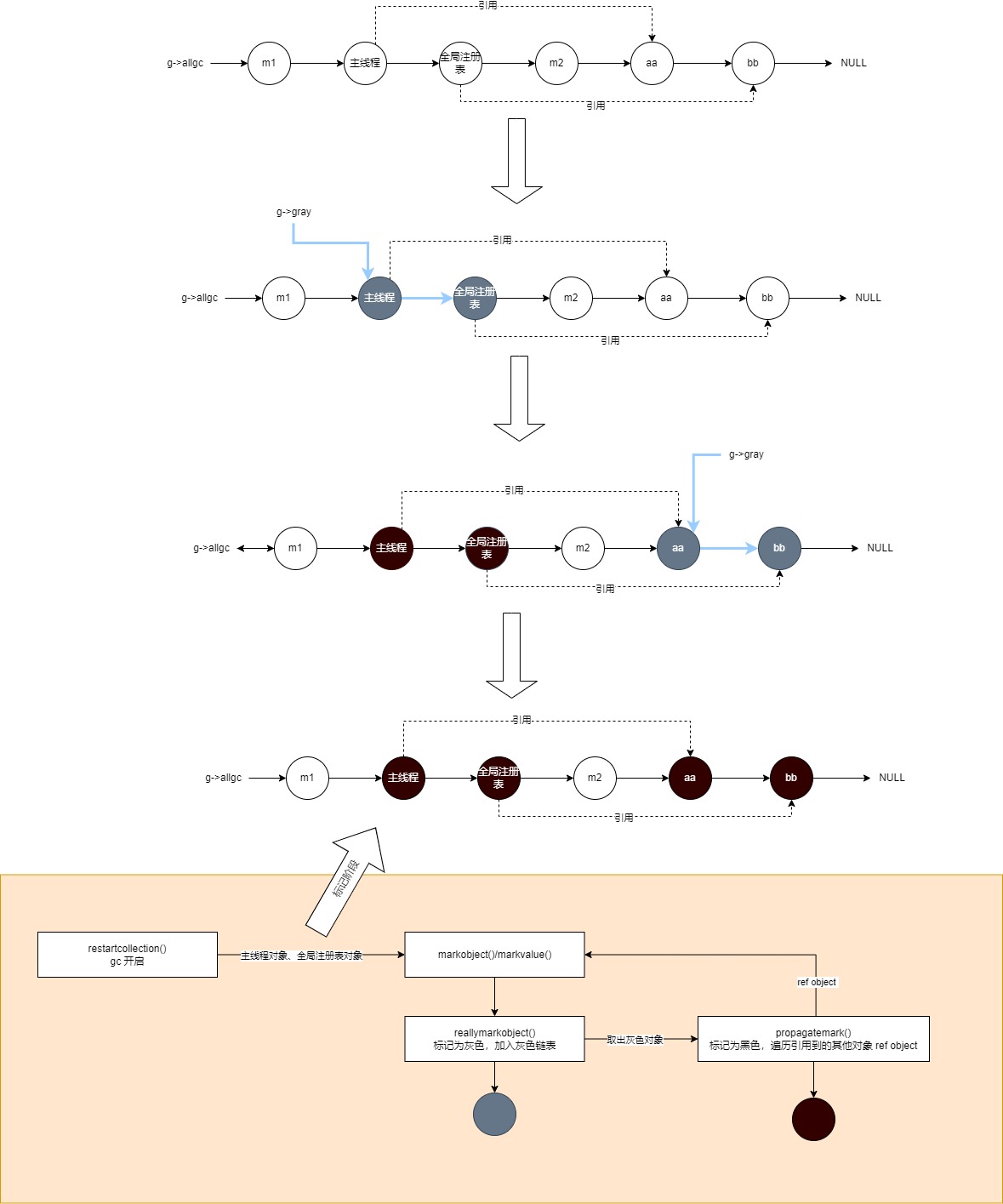
一开始,先将 主线程 mainthread,全局注册表 l_registry 对象加入到灰色链表,并 mark gray。进入 GCSpropagate 阶段后,就是对 主线程,全局注册表所引用的对象不断遍历,最终等所有的对象都标记为 black, g->gray 链表为空(表示所有被被引用的对象都遍历完了),就可以进入下一个阶段。
接下来再仔细看看,每种类型对象在标记为黑色后,怎么遍历其所引用到其他的对象。
c闭包和函数原型遍历
traverseCclosure() c闭包遍历比较简单,将其关联的 upvalue 数组进行 mark gray,加入灰色链表就可以了,然后返回 c闭包内存占用大小。
traverseproto() 函数原型同样需要对其所引用到的常量字符串、函数关联的上值名字、内部函数原型对象、以及局部变量名 mark gray,加入灰色链表,结果同样是返回函数原型遍历到的总大小。从这里也可以看出, 函数原型 Proto 如果没有被引用到,是会被释放回收的。比如,我们平时写的 lua 代码,如果这个函数没有谁去引用着,最终结果是会被回收的。
lua闭包遍历
/*
** open upvalues point to values in a thread, so those values should
** be marked when the thread is traversed except in the atomic phase
** (because then the value cannot be changed by the thread and the
** thread may not be traversed again)
*/
static lu_mem traverseLclosure (global_State *g, LClosure *cl) {
int i;
markobjectN(g, cl->p); /* mark its prototype */
for (i = 0; i < cl->nupvalues; i++) { /* mark its upvalues */
UpVal *uv = cl->upvals[i];
if (uv != NULL) {
// printf("traverseLclosure uv: %s, upisopen: %d, gcstate: %d\n", upvalname(cl->p, i), upisopen(uv), g->gcstate);
if (upisopen(uv) && g->gcstate != GCSinsideatomic)
uv->u.open.touched = 1; /* can be marked in 'remarkupvals' */
else
markvalue(g, uv->v);
}
}
return sizeLclosure(cl->nupvalues);
}lua闭包,主要是遍历其所引用到的上值,这些上值是在创建闭包时,就会生成的,是运行时的产物。一个上值可能会被多个闭包所引用,lua5.3 是通过引用计算来管理闭包上值的生命周期。比如,有两个函数f1,f2 引用到一个上值 aa,那么在创建一个函数闭包 f1 的同时,也会创建一个上值对象 UpVal (aa),引用计数为1,当第2个函数闭包 f2 创建时,则不会创建新的上值对象,而是将上值对象 aa 的引用计数器加1,变成2,这样两个闭包公用同一个上值对象,在 f1 改变上值 aa 时,f2 读取到的 aa 值也跟着改变,因为他们都是指向同一个上值对象。当第一个闭包 f1 没有再被引用时,会把 aa 的计数器减1,如果闭包 f2 也没有再被引用时,aa 计数器再减1,减到为0,且发现不是在栈上时(在栈上的话,是由线程对象去管理释放的),就会去释放这个上值对象。
如果当前不是处于原子阶段(GCSinsideatomic),即处于 GCSpropagate 阶段时,且上值还是在栈中的,就等到下一个原子阶段才去统一 mark,因为处于 GCSpropagate 阶段,是分多步完成的,中间可能会导致上值发生多次变化,在进入清除阶段前,必须知道它的最终引用状态,不然的话,很有可能在进入清除阶段时,upval 又指向了一个新对象,而这个新对象如果没有被 mark 的话,就可能会被回收掉了,导致异常。所以,处于 open 状态的上值,需要待到原子阶段(GCSinsideatomic),统一 mark。如果不处于栈中,就需要 markvalue了,因为上值被闭包引用着。
线程遍历
static void propagatemark (global_State *g) {
lu_mem size;
GCObject *o = g->gray;
lua_assert(isgray(o));
gray2black(o);
switch (o->tt) {
case LUA_TTHREAD: {
lua_State *th = gco2th(o);
g->gray = th->gclist; /* remove from 'gray' list */
linkgclist(th, g->grayagain); /* insert into 'grayagain' list */
black2gray(o);
size = traversethread(g, th);
break;
}
...
}我们再看一下 propagatemark() 对线程类型对象的操作,线程对象从 g->gray 链表中摘下来后,又放到了一个 g->grayagain 单向链表中,重新标记为灰色,然后才去遍历该线程所引用到的其他对象。这里提到了 g->grayagain 链表,这个链表的作用是将一些经常容易改动到的对象收集起来,比如 mark 一个表后,这个表如果在标记为黑色后,还引用到其他白色对象,那么也会存到 grayagain 链表中,还有就是线程栈是最容易被改动到的,即使标记为黑色,也很容易出现栈中的对象又指向新的白色对象,mark black 就是无用功了。所以,需要把一些经常容易发生变动引用的对象,统统收集起来放到 grayagain 链表中,然后再下一个阶段(即原子阶段),一次性,不中断,统一 mark 处理。
static lu_mem traversethread (global_State *g, lua_State *th) {
StkId o = th->stack;
if (o == NULL)
return 1; /* stack not completely built yet */
lua_assert(g->gcstate == GCSinsideatomic ||
th->openupval == NULL || isintwups(th));
for (; o < th->top; o++) /* mark live elements in the stack */
markvalue(g, o);
if (g->gcstate == GCSinsideatomic) { /* final traversal? */
StkId lim = th->stack + th->stacksize; /* real end of stack */
for (; o < lim; o++) /* clear not-marked stack slice */
setnilvalue(o);
/* 'remarkupvals' may have removed thread from 'twups' list */
if (!isintwups(th) && th->openupval != NULL) {
th->twups = g->twups; /* link it back to the list */
g->twups = th;
}
}
else if (g->gckind != KGC_EMERGENCY)
luaD_shrinkstack(th); /* do not change stack in emergency cycle */
return (sizeof(lua_State) + sizeof(TValue) * th->stacksize +
sizeof(CallInfo) * th->nci);
}遍历线程,主要是针对栈 stack 中的对象进行 mark gray,并加入灰色链表操作。如果当前是在原子阶段(GCSinsideatomic)遍历线程的话,并且线程存在开放上值的引用,需要把线程存到 g->twups 链表中,这个后面对上值是如何 mark 的再细说把。如果不是处于原子阶段,并且不是 KGC_EMERGENCY 状态,就尝试去缩减栈大小。KGC_EMERGENCY 是内存分配失败时,执行一次全量 gc 的状态,即从标记到清除都是不可中断的执行,为了尽快执行完一次全量 gc,在一些检查是否要缩减内存的地方都会直接跳过,具体可以看下 lgc.c 代码。最后 traversethread() 返回遍历到的线程结构体大小,遍历的栈大小,以及栈帧大小。
table遍历
static lu_mem traversetable (global_State *g, Table *h) {
const char *weakkey, *weakvalue;
const TValue *mode = gfasttm(g, h->metatable, TM_MODE);
markobjectN(g, h->metatable);
if (mode && ttisstring(mode) && /* is there a weak mode? */
((weakkey = strchr(svalue(mode), 'k')),
(weakvalue = strchr(svalue(mode), 'v')),
(weakkey || weakvalue))) { /* is really weak? */
black2gray(h); /* keep table gray */
if (!weakkey) /* strong keys? */
traverseweakvalue(g, h);
else if (!weakvalue) /* strong values? */
traverseephemeron(g, h);
else /* all weak */
linkgclist(h, g->allweak); /* nothing to traverse now */
}
else /* not weak */
traversestrongtable(g, h);
return sizeof(Table) + sizeof(TValue) * h->sizearray +
sizeof(Node) * cast(size_t, allocsizenode(h));
}如果没有弱表的存在,其实对 table 里的键值 mark 还是比较简单的。先看下 traversestrongtable() 的实现,先对数组部分的值进行 mark,因为数组部分的 key 都是数字,不是可回收对象,所以不需要 mark。接着就是对 table 的哈希表进行 mark。如果哈希表中值不为 nil,就 mark key 和 value(值不为空,键也是肯定存在的,所以可以直接 mark key)。如果值为 nil,则调用 removeentry() 函数,对 key 标记为死亡,而不是把 key 也置为 nil,因为像 for ... pairs() 这种遍历 table 时,key 突然被置为 nil,就有可能会导致遍历异常,所以仅仅是对 key 打个状态标记而已。对于弱表的 gc 流程后面再具体总结下把。
GCSatomic状态
在执行完 GCSpropagate 状态时(依据是此时的灰色链表为空 g->gray == NULL,没有再需要遍历的灰色对象了),会将 g->gcstate 设置为 GCSatomic,然后返回到 lua 脚本层继续执行,等到内存涨到某个阈值时,才会再次进入 gc 操作,而根据此时的 gcstate 状态为 GCSatomic,会进行一次原子操作,即不可中断的去 mark 对象。
static lu_mem singlestep (lua_State *L) {
global_State *g = G(L);
switch (g->gcstate) {
...
case GCSpropagate: {
g->GCmemtrav = 0;
lua_assert(g->gray);
propagatemark(g);
if (g->gray == NULL) /* no more gray objects? */
g->gcstate = GCSatomic; /* finish propagate phase */
return g->GCmemtrav; /* memory traversed in this step */
}
case GCSatomic: {
lu_mem work;
propagateall(g); /* make sure gray list is empty */
work = atomic(L); /* work is what was traversed by 'atomic' */
entersweep(L);
g->GCestimate = gettotalbytes(g); /* first estimate */;
return work;
}
...
}在进入 atomic(L)原子操作时,会先执行一次 propagateall(g) 操作,确保灰色链表为空,为什么呢,通过源码的注释,我们也可以猜到,在 GCSpropagate 状态切到 GCSatomic 状态时,是会返回到 lua 脚本层,这个时候有可能会创建新的对象,而这些对象是有可能被插入到 gray 灰色链表中的。比如,一个函数原型 Proto 对象被标记为黑色了,但它又引用了一个新的白色字符串对象,此时,会把字符串对象标记为灰色,并插入到 灰色链表,这样灰色链表就不为空了,所以,在进入 GCSatomic 的时候,需要再 mark 一次灰色链表里的对象,确保 gray 链表为空。
接下来,看看 atomic 函数实现:
static l_mem atomic (lua_State *L) {
global_State *g = G(L);
l_mem work;
GCObject *origweak, *origall;
GCObject *grayagain = g->grayagain; /* 标记1 save original list */
lua_assert(g->ephemeron == NULL && g->weak == NULL);
lua_assert(!iswhite(g->mainthread));
g->gcstate = GCSinsideatomic;
g->GCmemtrav = 0; /* start counting work */
markobject(g, L); /* mark running thread */
/* registry and global metatables may be changed by API */
markvalue(g, &g->l_registry);
markmt(g); /* mark global metatables */
/* remark occasional upvalues of (maybe) dead threads */
remarkupvals(g);
propagateall(g); /* propagate changes */
work = g->GCmemtrav; /* stop counting (do not recount 'grayagain') */
g->gray = grayagain; /* 标记2 */
propagateall(g); /* traverse 'grayagain' list */
g->GCmemtrav = 0; /* restart counting */
convergeephemerons(g);
/* at this point, all strongly accessible objects are marked. */
/* Clear values from weak tables, before checking finalizers */
clearvalues(g, g->weak, NULL);
clearvalues(g, g->allweak, NULL);
origweak = g->weak; origall = g->allweak;
work += g->GCmemtrav; /* stop counting (objects being finalized) */
separatetobefnz(g, 0); /* separate objects to be finalized */
g->gcfinnum = 1; /* there may be objects to be finalized */
markbeingfnz(g); /* mark objects that will be finalized */
propagateall(g); /* remark, to propagate 'resurrection' */
g->GCmemtrav = 0; /* restart counting */
convergeephemerons(g);
/* at this point, all resurrected objects are marked. */
/* remove dead objects from weak tables */
clearkeys(g, g->ephemeron, NULL); /* clear keys from all ephemeron tables */
clearkeys(g, g->allweak, NULL); /* clear keys from all 'allweak' tables */
/* clear values from resurrected weak tables */
clearvalues(g, g->weak, origweak);
clearvalues(g, g->allweak, origall);
luaS_clearcache(g);
g->currentwhite = cast_byte(otherwhite(g)); /* flip current white */
work += g->GCmemtrav; /* complete counting */
return work; /* estimate of memory marked by 'atomic' */
}为什么需要有原子状态?假如没有原子状态,那么对于一些会反复变更引用的对象要怎么处理呢,没有个标准,就没法进入清除阶段了。所以,干脆来个原子阶段。在这个阶段里,会一次性把所有可能还没有被标记的白色对象都遍历一次,这个过程是不可中断,这样保证当前所有正在被引用到的对象都能顺利 mark black。
原子阶段,主要是针对哪些对象呢?我个人理解是,类似 table 表,线程,栈,上值,这些会导致引用变更比较频繁的对象,才需要在原子操作统一处理一次,做最后的保证,让有引用的对象都会被 mark black。
在 atomic(L) 这里会把 gcstate 状态设置为 GCSinsideatomic,主要是为了在标记时,做一些特殊处理。比如,在遍历 lua 闭包时,会直接 mark 对象,不再管对象是在栈上的还是不在栈上的,在只要是被引用到的,都统统 mark。
值得关注的地方,GCObject *grayagain = g->grayagain;(标记1) 这行代码,用了一个局部变量 grayagain 来存储 g->grayagain 指针指向的对象。后面再用 g->gray = grayagain; propagateall(g); (标记2)只处理了之前局部变量 grayagain 指向的部分对象,而不是指向头部的 g->grayagain 指针赋值给 g->gray。在标记1到标记2之间,我们知道,会 mark 线程,上值,注册表等,这个过程 g->grayagain 是有可能插入新的对象的,但作者在标记2处的代码,并不是使用 g->gray = g->grayagain,从 g->grayagain 链表头出发,我猜测是为了尽可能快的结束 atomic 原子函数调用,不占用过多时间。且这部分新插入的对象是灰色的,不会再被标记为黑色,同时也意味着本轮 gc 是不会释放的,只会把这些灰色对象重新 mark 回白色(这些对象同时还是在 g->allgc 链表中的,清除阶段,遍历 g->allgc 时,就会被重新 mark 回白色,等到下一轮 gc 再去检查是否有引用,是否需要释放)。
所以,在标记2处的代码,即使不去从头遍历 g->grayagain,也不会有什么副作用影响。如果标记1到标记2之间,g->grayagain 加入了少量的对象,那么可以暂时不用处理,等到下一轮 gc 再去专门处理这些少量的对象,如果是加入了很多对象,几百个上千个以上,那就更不需要处理了,处理的话,反而增加了 atomic(L) 函数的执行时间,得不偿失。
还有个地方,需要注意的就是在 atomic(L) 的最后调用了 luaS_clearcache(g); ,把字符串缓存池清除了。这个缓存池存存的字符串对象,是不分长短类型的。这也就意味着,每轮 gc 都会清空一次 g->strcache 缓存。
最后切换当前使用的白色为另一种白色,比如扫描阶段是 white0,那么 atomic(L) 调用完后,创建的对象就是 white1,在后面的清除阶段,也只会清除 white0 的对象。对清除阶段创建的 white1 对象,会留到下轮 gc 再处理。
标记阶段先介绍到这。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号